오늘 뭘 했니?
- 피쳐엔지니어링 실습
실습파일: 0707-house-prices-feature_engineering-
뭘 배웠니?(new)
import sklearn
sklearn.metrics.SCORERS.keys()
Feature Engineering
- 피쳐 엔지니어링이란 Feature를 조작하여 사용하기 유용하게 바꾸는 것
- 데이터 분석의 일반적인 순서
데이터수집 → 데이터 전처리 → EDA → 피쳐 엔지니어링(특성공학)
피쳐 엔지니어링의 분류
- 특성 선택 (Feature Selection)
- 특성 추출 (Feature Extraction)
- 범위 변환 (Scaling)
- 변수의 분산과 편차를 바꾸고 싶은 경우
- 변수 간 규모 차이가 커서 한 변수가 지나치게 모델에 영향을 미치는 경우
- 변형 (Transform)
- 범주화 (Binning)
- 숫자화 (Dummy)
피쳐의 종류
- Categorical
- Nominal : 순서가 없는 범주형 변수
- Ordinal : 순서가 있는 범주형 변수
- Numerical
- Discrete : 유한하거나 개수를 셀 수 있는 숫자형 변수
- Continuous : 무한하거나 개수를 셀 수 없는 숫자형 변수
EDA
#모든 컬럼 출력
pd.set_option('display.max_columns', None)기술통계
#백그라운드에 컬러넣어서 보기
train.describe().style.background_gradient()결측치
- 결측치는 Null, (공백), “-” 등 다양한 값으로 존재
- “ “(공백)이나 “-”등 DataFrame은 결측치라고 판단하지 않지만 실제론 결측치인 경우가 존재
- 이런 경우를 잘 따져서 결측치를 탐색
pd.concat([train.isnull().sum(), train.isnull().mean()*100], axis=1).T이상치
- 이상치(Outlier)는 Feature에서 일반적인 값 분포에서 벗어나는 경우를 의미
- 이상치는 결측치처럼 1.잘못 생겨났을 수도 있고, 2.예외적으로 수치가 뛰어오르는 경우
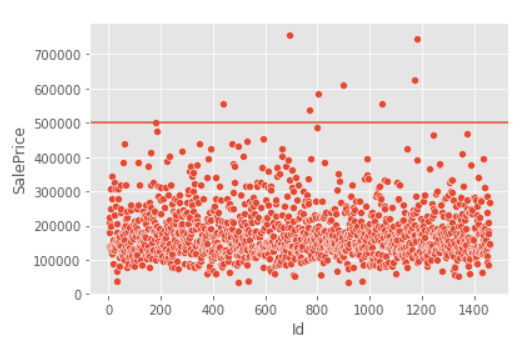
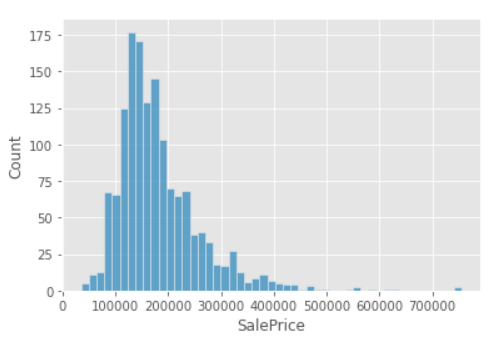
```python sns.scatterplot(data=train, x=train.index, y="SalePrice") plt.axhline(500000) sns.histplot(data=train, x="SalePrice") ```
희소값
- 빈도가 너무 낮은 값
- 희소값들을 병합(combine)함으로써, One-Hot-Encoding에서 Feature 수를 줄여주기도 한다.
# nunique의 값이 클수록 희소값 있을 확률 높음
# object type nunique
train.select_dtypes(include="object").nunique()
# countplot
sns.countplot(data=train, y="Neighborhood",
order=train["Neighborhood"].value_counts().index)- 희소값 냅두면 오버피팅 될 수 있음
변수 스케일링
💡 정보 균일도를 기반으로 되어 있기 때문에 트리기반 모델은 피처 스케일링이 필요 없습니다. 트리기반 모델은 데이터의 절대적인 크기보다 상대적인 크기에 영향을 받기 때문에 스케일링을 해도 상대적 크기 관계는 같게 됩니다. 경사하강법(Gradient Descent)뿐만 아니라 KNN, Clustering와 같은 거리 기반 알고리즘에서 더 빨리 작동합니다.- 변수 스케일링(Feature Scaling)이란 Feature의 범위를 조정하여 정규화하는 것을 의미
- 일반적으로 Feature의 분산과 표준편차를 조정하여 정규분포 형태를 띄게 하는 것이 목표
- 스케일링 기법 3가지
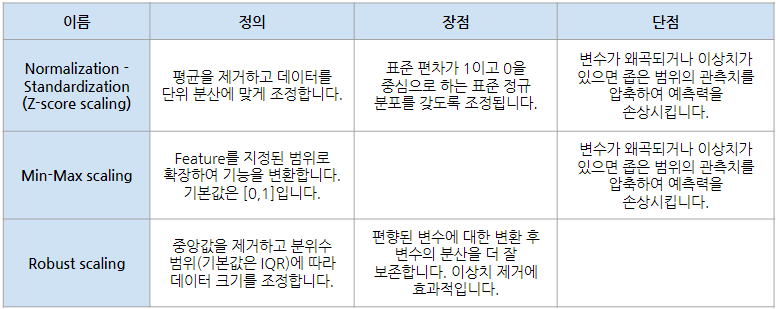
- Normalization-Standardization
z = (x - u) / s - Min-Max scaling
- Robust scaling
boxplot과 유사함
 • mean: 산술평균, std: 표준편차, max: 최대값, min: 최소값, median: 중간값
• mean: 산술평균, std: 표준편차, max: 최대값, min: 최소값, median: 중간값
- Normalization-Standardization
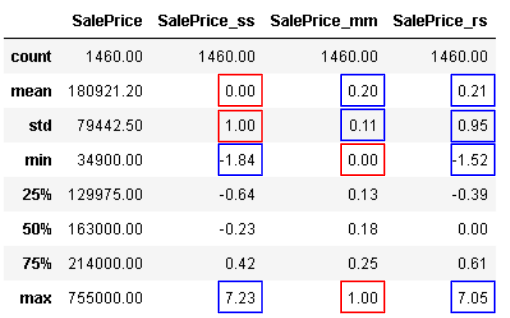
- Scaling 특성을 나타내는 값은 빨간색 박스로 표시했습니다.
- Standard Scaler는 평균이 0, 표준편차가 1인 모습을 확인할 수 있습니다.
- MinMax Scaler는 최소값이 0, 최대값이 1인 모습을 확인할 수 있습니다.
- Robust Scaler는 평균, 표준편차, 최소값, 최대값에서 눈에 띄는 특성은 없습니다.
- 그러나 IQR을 기준으로 scaling 하기 때문에 Standard Scaler보다 더 큰 최소값, 더 작은 최대값을 갖는 모습입니다.부족한 것
정규분포가??
로그함수의 반대개념이 지수함수(exp)다
로그를 씌우면 큰 값이 완만하게 증가
로그 취해준 값에 exp 하면 다시 원래 값 가넝
정답값에 로그를 취해주었습니다. 모델을 평가하는 측정공식이 Root Mean Squared Logarithmic Error (RMSLE)라고 할 때 아래에서 Metric 을 고른다면 무엇이 가장 적당할까요?
neg_root_mean_squared_error
이미 정답에 Log 가 적용되어있기 때문에 RMSE 로 평가하면 RMSLE 로 평가하게 됩니다.
3F
사실(Fact) : 피쳐엔지니어링에 대해 배웠다.
느낌(Feeling) : EDA 하는 게 이렇게 반가울 줄이야…
교훈(Finding) : 신호와 소음 구분을 잘해야 한다.

데린이여요