오늘 뭘 했니?
- 캐글 benz 데이터로 GBT, XGBoost, lightgbm, catboost를 적용하고 제출
실습파일: (코랩으로 실습) 0803-Benz-tree-model-input.ipynb - 캐글 credit card faud detection 의 데이터로 불균형한 데이터를 다뤄보고 분류측정지표에 대해 배움
실습파일: 0804-credit_card_SMOTE-input
뭘 배웠니?(new)
불균형 데이터: SMOTE 와 분류 측정지표
정확도 외에 다른 측정지표가 필요한 이유: 희소한 데이터를 정확하게 예측하는 것이, 전체 데이터에 대한 정확도보다 중요할 경우가 있음
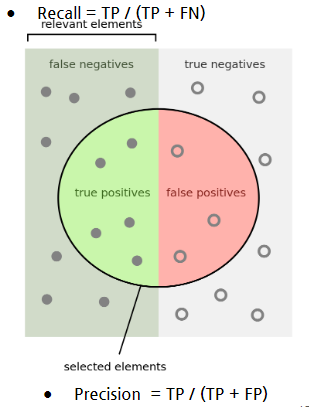
이진분류의 평가
Confusion Matrix(혼동 행렬)

- 정밀도 recision
- 재현율 recall
- 1종 오류(거짓양성)와 2종 오류(거짓음성)는 tradeoff 관계 → 한쪽 오류를 강제로 줄이면, 다른 오류가 늘어난다
precision(정밀도)와 recall(재현율)
Precision = TP / (TP + FP)
- ex) 스팸 메일 검출의 경우
- 스팸 메일이면 참, 스팸 메일이 아니면 거짓이라고 할 때
- 스팸 메일이 아닌데 스팸 메일로 판단해서 차단해버리면
- 중요한 메일을 받지 못할 수 있음
- Precision 이 낮다.
- => 참이 아닌데도 참이라고 한 것이 많다.
- Precision이 지나치게 높다.
- => 참으로 예측한 경우가 필요 이상으로 적다.
- 아주 확실한 경우에만 참으로 예측하고 나머지를 전부 거짓으로
- FP = 0, Precision = 1
- ex)전체 데이터가 10,000,000개, 참이 5,000,000개 인데
- 확실한 1개만 참으로 예측
- Recall = TP / (TP + FN)
- ex) 암 검출의 경우
- 암이 검출되면 참, 검출되지 않으면 거짓이라고 할 때
- 실제로 암에 걸렸는데, 걸리지 않았다고 판단하는 경우가 가장 위험
- ex) 지진
- 지진이 안 났으나 대피명령을 한 것은 생명과는 지장이 없지만
- 지진이 났는데 대피명령이 없다면 생명에 위험
- Recall 이 낮다.
- => 참인데 못 찾은 것이 많다.
- Recall이 지나치게 높다.
- => 참으로 예측한 경우가 필요 이상으로 많다.
- 모든 예측을 참으로 하면 FN = 0, Recall = 1
- 예측 성능과 상관 없이 Recall이 높게 나올 수 있음
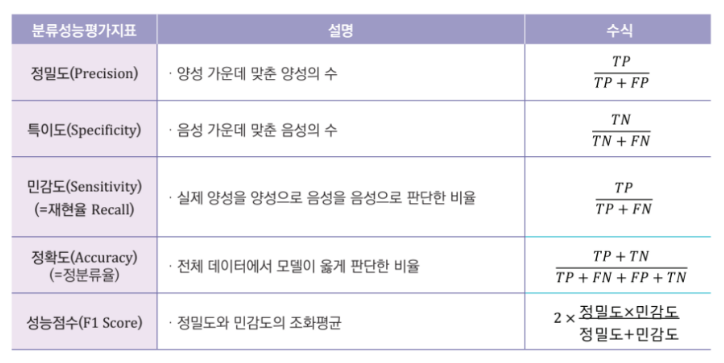
분류 성능 평가 지표
F1-score

- 정밀도와 재현율(민감도)의 조화평균
- 참으로 예측하는 수를 줄이면 정밀도가 올라가고 반대로 참으로 예측하는 수를 높이면 재현율이 올라간다. 따라서 한쪽만 채용하기에는 평가지표로 불완전하다
- F1스코어는 정밀도와 재현율 둘 다 높아야 높은 점수 가넝
ex)Precision이 0.5, Recall이 0.5인 경우 F1 점수는 0.5
Precision이 0.3, Recall이 0.7인 경우 F1 점수는 0.42
Precision-Recall Tradeoff
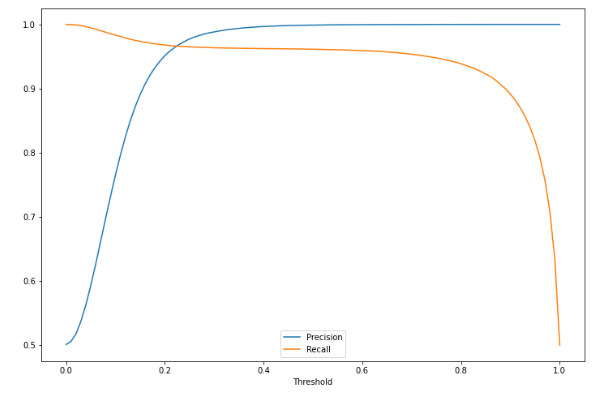
- 정밀도와 재현율은 상호보완적인 관계이기 때문에 적절한 밸련스를 맞춰야함
- 위와 같은 경우 precision과 recall이 교차하는 0.2~0.3 사이의 threshold가 적당
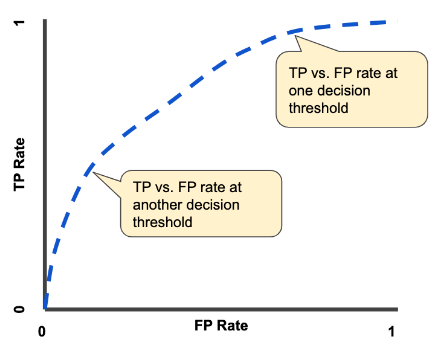
ROC curve
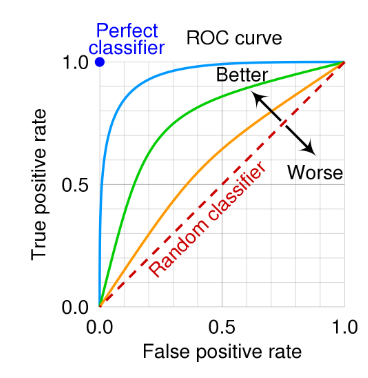
- receiver operating characteristic curve
- 예측값이 확률인 분류 문제에 사용
- threshold에 따라서 달라지는 TP rate와 FP rate를 표시한 그래프
- 이진 분류에서 완전히 랜덤하게 예측할 경우, FP rate가 올라갈수록 TP rate도 정비례하여 올라감
- 모두 참으로 예측할 경우, FP rate도 1, TP rate도 1
- FP rate를 0, TP rate를 1로 만들면 완벽한 분류기입니다.
- 그러나 현실적으로 불가능하기 때문에 FP rate를 최대한 적게, TP rate를 높게
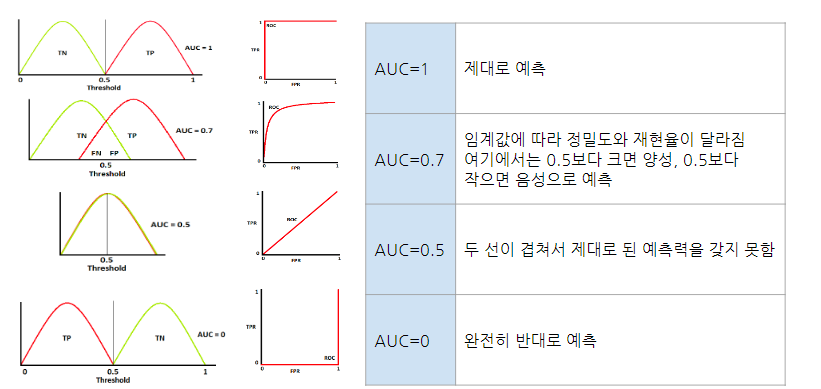
AUC Curve
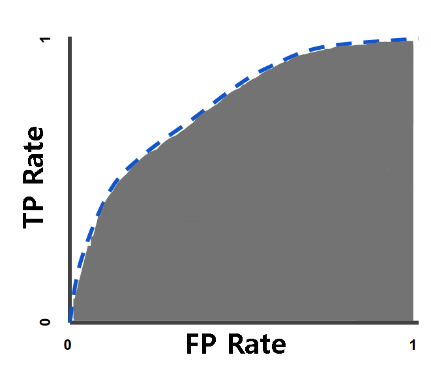
- AUC(area under curve)는 ROC 커브 아래의 곡면의 넓이를 의미
- AUC가 넓을수록 더 좋은 모델
TPR과 FPR
-
True Positive Rate(TPR)과 False Positive Rate(FPR)
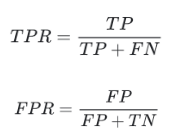
-
TPR = TP / (TP + FN)
- 실제 양성 샘플 중에 양성으로 예측된 것의 비율
- TP와 FN은 어떻게 예측되었든 상관없이 모두 실제로는 양성 샘플임
- TP가 많고 FN이 적을수록 TPR은 1에 가까워짐
-
FPR = FP / (FP+TN)
- FPR은 실제 음성 샘플 중에 양성으로 잘못 예측된 것의 비율
- FP가 적고 TN이 많을수록 FPR은 0에 가까워짐
- TPR은 1에 가까울 수록 좋고, FPR은 0에 가까울 수록 좋음
SMOTE
- SMOTE는 Synthetic Minority Over-sampling Technique의 약자로 합성 소수자 오버샘플링 기법
- 실제데이터는 5:5로 딱 떨어지는 것이 아닌 불균형함 ex)암 확률
따라서 불균형한 데이터는 전체 데이터에서 샘플링하는 방식을 달리함
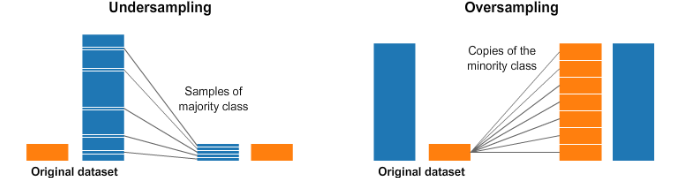
under-sampling과 over-sampling
-
under sampling
- 더 값이 많은 쪽에서 일부만 샘플링하여 비율을 맞춰주는 방법
- 구현이 쉽지만 전체 데이터가 줄어 머신러닝 모델 성능이 떨어질 우려
-
over sampling
- 더 값이 적은 쪽에서 값을 늘려 비율을 맞춰준 방법
- 어떻게 없던 값을 만들어야 하는지에 대한 어려움
-
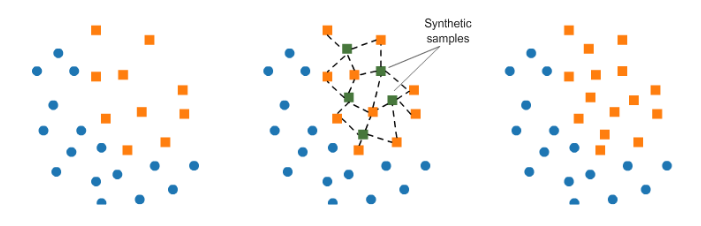
SMOTE
-
적은 값을 늘릴 때, k-근접 이웃의 값을 이용하여 합성된 새로운 값을 추가
-
새로 생성된 값은 좌표평면으로 나타냈을 때, k-근접 이웃의 중간에 위치
-
부족한 것
1-4시 ㅠㅠㅠㅠ
14 ML 불균형 데이터 SMOTE 와 분류 측정지표 - Google Slides
3F

데린이여요