B-Tree vs Hash
이전에 B-Tree와 Hash Index 간의 차이를 정리한 글을 작성한 적이 있다. 조금 더 간단하게 요약해서 정리를 한번 더 해보려고 한다.
Index의 사용 이유
data의 검색이 필요할 경우에 Index를 통해 범위를 제한하게 되고, 이로 인해 검색의 속도가 매우 빨라진다.
Index의 검색 범위 제한의 방법은 Index의 종류마다 다르다.
B-Tree
먼저 B-Tree Index에 대해 알아보자.
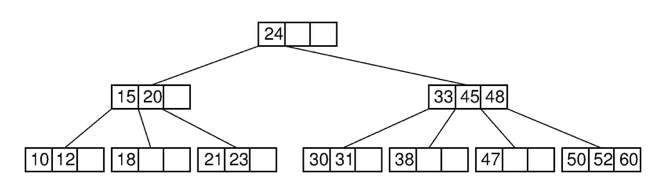
- Binary Tree가 아닌 Balanced Tree
- Binary Tree를 확장하여 자식의 수가 2개를 넘을 수 있음
- 모든 Leaf Node는 같은 Level에 존재
- Index 탐색 시 중위 순회
- Node의 값은 오름차순을 유지 (항상 정렬된 상태)
- 입력 data 중복 허용 X
위와 같은 특징들을 가지고 있다. B-Tree의 특징을 보면 항상 오름차순을 유지하는 것을 볼 수 있다. 이를 검색에 이용하게 되는데 이를 이용하여 범위를 정하게 되는 것이다.
B-Tree 방식에서는 WHERE절에 =, <=, >=, <, >, BETWEEN 연산자를 사용하여 범위를 지정할 수 있고, LIKE 인수가 와일드카드 문자로 시작하지 않는 상수 문자열인 경우 LIKE 비교에 사용할 수 있다.
SELECT * FROM Nation WHERE key_col LIKE 'Abcd%';
SELECT * FROM Nation WHERE key_col LIKE 'Ab%_fk%';첫번째 SELECT문은 Abcd<=key_col<Abce에 대하여 범위를 제한하게 되고, 두번째 SELECT문은 Ab<=key_col<Ac에 대하여 범위를 제한하게 되는 것이다.
항상 오름차순으로 정렬되기 때문에 data의 삽입이나 수정/삭제가 발생하였을 때 그때그때 정렬된다.
B-Tree의 매우 큰 장점이지만, 그때그때 정렬하기 때문에 이에 대한 overhead가 발생하게 된다는 단점이 있다.
Hash
Hash Index는 다음과 같은 특징을 가진다.
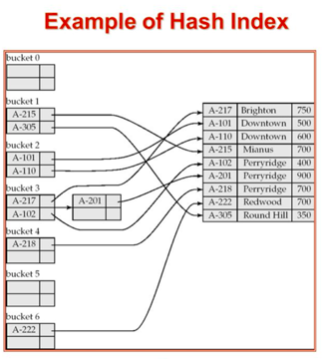
- Single Level Index
- Hash table과 같은 형태
- 정렬되지 않음
Hash 방식의 경우에는 정렬을 하지 않는다는 특징이 있다. 이는 data 삽입, 수정/삭제 시에 별다른 overhead 없이 바로바로 수행된다는 의미이기도 하다. 또한 Hash table과 같은 형태를 가지기 때문에 균등비교에 매우 빠른 성능을 보인다.
WHERE절에 =, <=, >= 연산자만을 사용하는 균등비교에만 사용된다. 균등비교만 가능하지만, 속도가 매우 빠르다.
사용되는 Case
B-Tree와 Hash는 각각 어떤 경우에 사용되는지 알아보자.
B-Tree
B-Tree는 대부분의 DBMS에 기본적으로 사용된다. 정렬된 상태를 유지한다는 장점 덕에 범위를 제한한 검색에 매우 유용하다.
Hash
Hash는 디스크 기반의 테이블보다는 메모리 기반의 테이블에 주로 사용된다. 디스크 기반의 대용량 테이블에서는 정렬된 결과를 가져올 수 없기 때문에 사용하지 않는다.
B-Tree & RedBlack-Tree
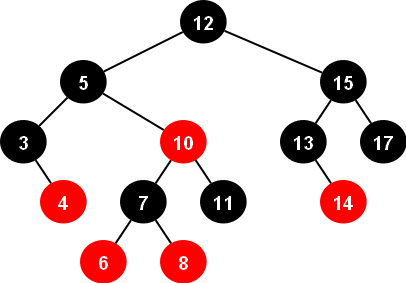
B-Tree를 DB의 Index 방식으로 채택한 이유는 Balanced Tree라는 점과 자동 정렬이 된다는 점에 있다. 그렇다면 이와 같은 특징을 가진 RedBlack-Tree는 왜 채택되지 않았을까?
B-Tree는 하나의 Node에 여러 data가 함께 저장될 수 있다. 반면에 RedBlack-Tree는 하나의 Node에 하나의 data가 저장된다.
B-Tree는 하나의 Node에 배열 형태로 data들을 저장하기 때문에 같은 Node에 있는 data들 간에는 Index로 접근할 수 있다. RedBlack-Tree는 하나의 Node에 하나의 data만 존재하기 때문에 다른 data에 접근하기 위해 무조건 자식 Node의 참조 포인터 값으로 접근해야 한다.
이 방식에서 성능의 차이가 발생하게 될 것이고, 이로 인해 B-Tree를 채택한 것으로 보인다. 보통의 data 규모로는 크게 차이가 나지 않을 수 있지만, data의 규모가 점점 커져간다면 성능의 차이가 보이게 될 것이다.
