CS
1.[ CS / Network ] 프로토콜 & API

컴퓨터 간의 정보를 주고 받을 때의 통신 방법에 대한 규칙정보기기 간의 정보 교환이 필요한 경우 이를 원활하게 하기 위해 정한 여러가지 통신 규칙과 방법에 대한 약속상호 간의 접속이나 전달 방식, 통신 방식, 주고 받을 자료의 형식, 오류 검출 방식, 코드 변환 방식,
2.[ CS / Network ] 동기식 ( Synchronous Transmission) & 비동기식 통신 (Asynchronous Transmission)
미리 정해진 수 만큼의 문자열을 한 블록으로 만들어 일시에 전송하는 방식데이터 블럭의 전후에 특정한 제어 정보를 삽입하며, 데이터 블럭과 전후의 제어 정보를 합쳐 프레임이라고 부름\-> 프리엠블(Preamble) : 앞부분의 제어 정보\-> 포스트엠블(Postamble
3.[ CS / OS ] 교착상태 ( DeadLock )
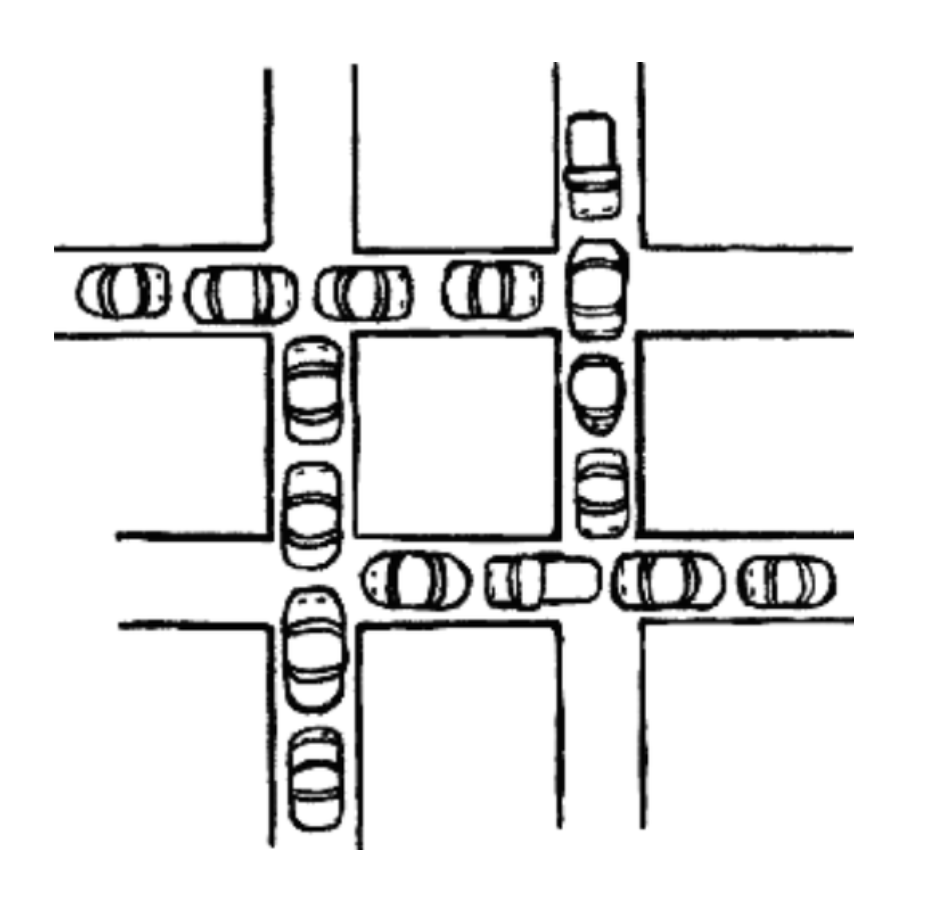
교착 상태란 두 개 이상의 작업이 서로 상대방의 작업이 끝나기 만을 기다리고 있기 때문에 결과적으로 아무것도 완료되지 못하는 상태를 가리킨다.1971년 E.G.코프만 교수는 교착 상태가 일어나려면 다음과 같은 4가지 필요 조건이 충족해야 함을 보였다.프로세스들이 필요로
4.[ CS / OS ] 프로세스 (Process) & 쓰레드 (Thread)
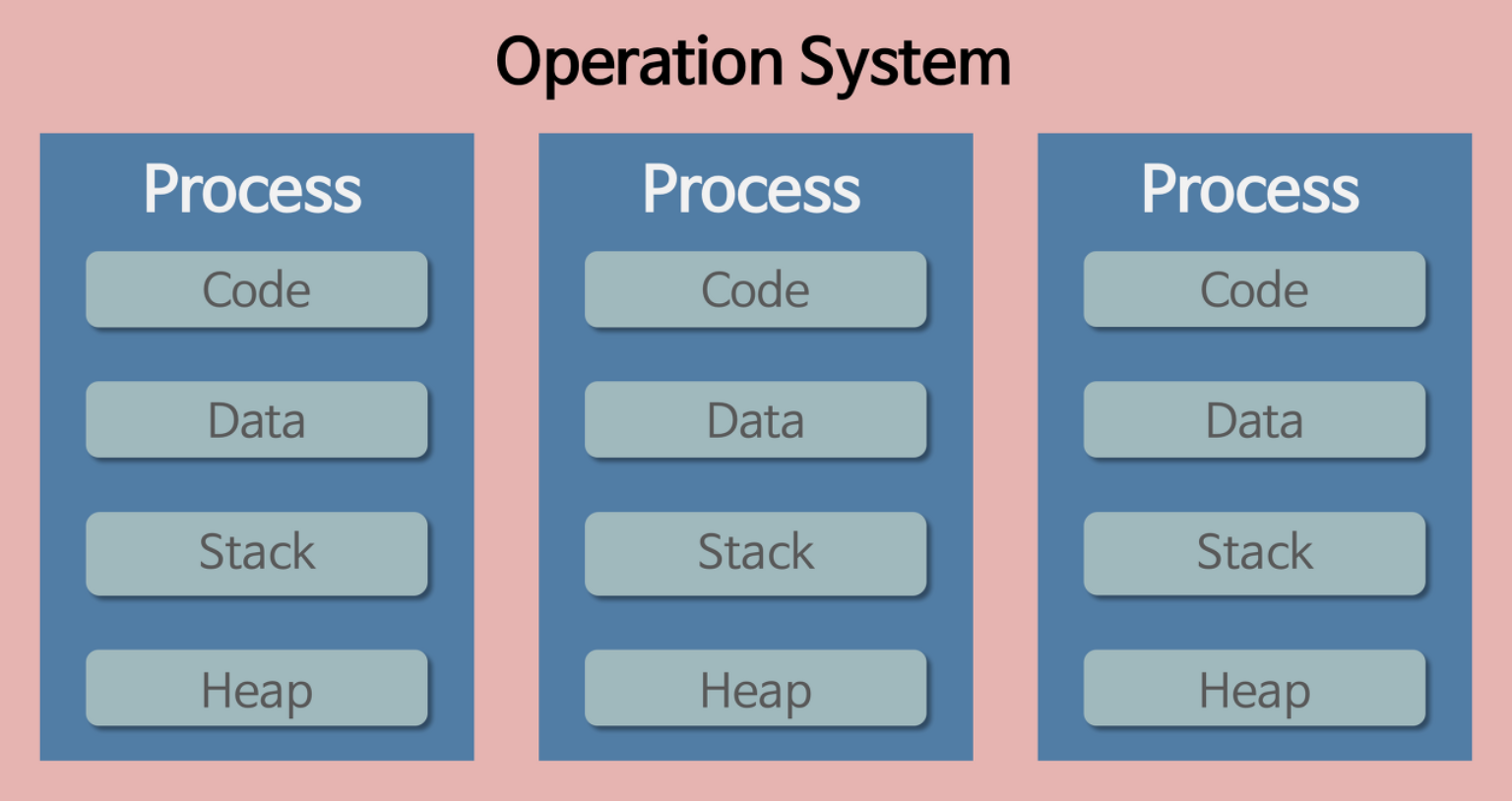
파일이 저장 장치에 저장되어 있지만 메모리에는 올라가 있지 않은 정적인 상태를 의미한다.OS로부터 자원을 할당받은 작업의 단위컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램메모리에 올라와 실행되고 있는 프로그램의 인스턴스OS 관점에서 최소 작업 단위실행 중인 프로그
5.[ CS / DataStructure] Array vs Linked List
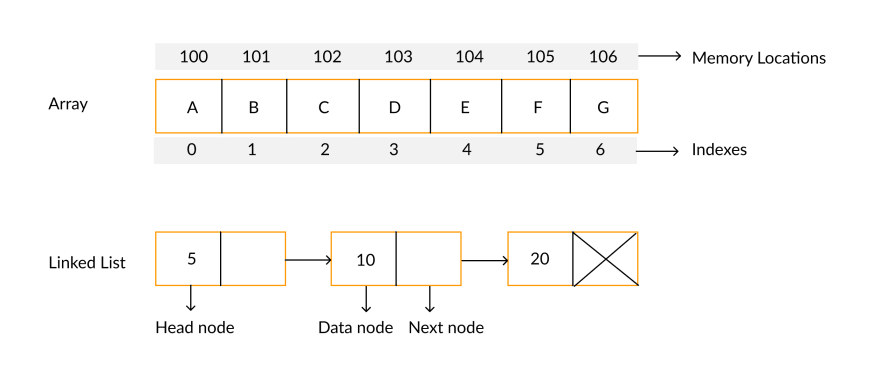
가장 기본적인 자료구조인 Array 자료구조는 논리적 저장 순서와 물리적 저장 순서가 일치한다. 따라서 인덱스로 해당 원소에 접근할 수 있다. 이는 인덱스만 알고 있다면 O(1) 시간에 해당 원소에 접근할 수 있음을 의미한다. (Random access가 가능)그러나
6.[ CS / DataStructure ] Stack & Queue
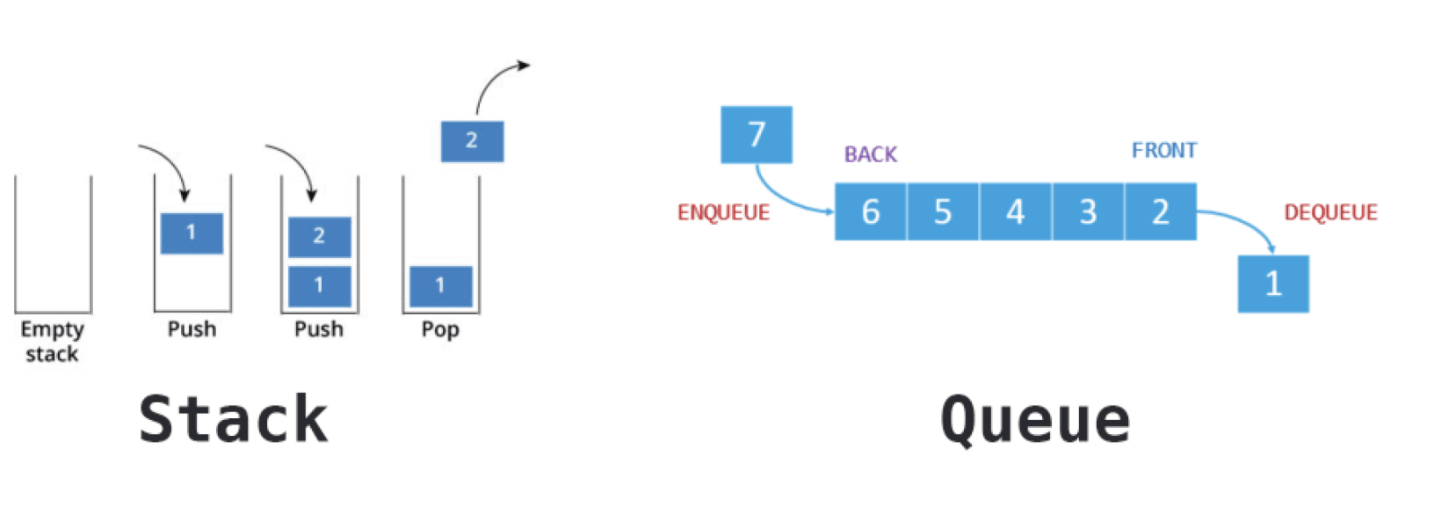
스택과 큐는 흔히 LIFO, FIFO로 알려져있는 자료구조이다. 선형 자료구조의 일종으로 LIFO(Last In First Out)의 구조를 가진다. 이는 나중에 들어간 원소가 가장 먼저 나온다는 의미이다. 이것이 스택의 가장 큰 특징이다. 차곡차곡 쌓이는 구조로 먼저
7.[ CS / DataStructure ] Binary Heap
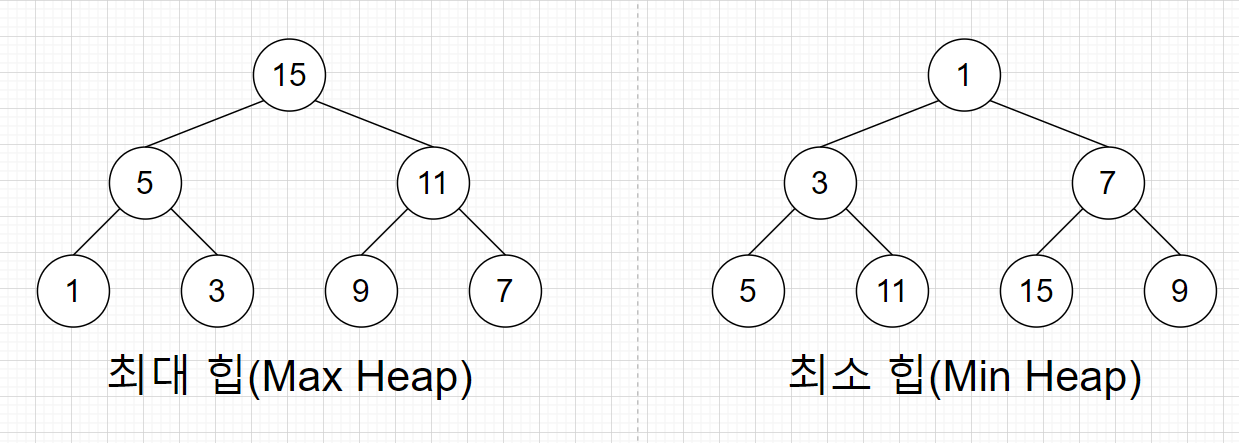
Binary Heap은 자료구조의 일종으로 Tree의 형식을 띄고 있다. Tree 중에서도 배열에 기반한 Complete Binary Tree이다. 배열에 트리의 값들을 넣어줄 때에 0번째는 건너 뛰고 index 1부터 루트 노드가 시작된다. 이는 노드의 고유번호 값과
8.[ CS / DataStructure ] Red Black Tree

Red Black Tree는 RBT라고도 불린다. RBT는 BST(Binary Search Tree)를 기반으로하는 트리 형식의 자료구조이다. BST의 삽입, 삭제 연산 과정에서 발생할 수 있는 문제점을 해결하기 위해 등장하였다.RBT의 삽입, 삭제, 검색 연산은 모두
9.[ CS / DataStructure ] Hash Table
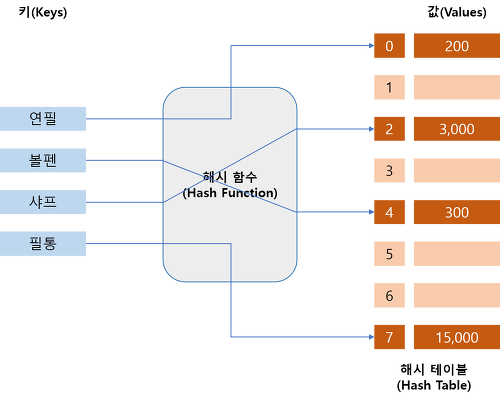
hash는 내부적으로 배열을 사용하기 때문에 데이터를 검색할 때에 빠른 속도를 갖는다. 특정한 값을 검색할 때에는 데이터 고유의 인덱스로 접근하게 되기 때문에 average case에 대해 시간 복잡도는 O(1)이다. hash에서의 문제는 key값이 불규칙하다는 것이다
10.[ CS / DataStructure ] Graph
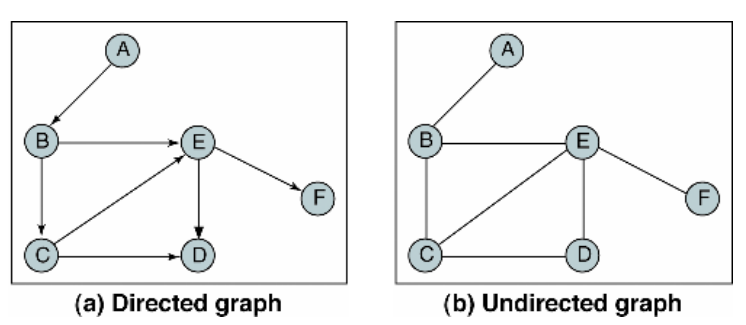
그래프는 간단하게 말하면 정점과 간선의 집합이다. 이전에 알아보았던 트리 또한 그래프의 일종이다. 그러나 트리는 사이클의 형성을 허용하지 않는다.Vertex는 정점을 의미한다. 정점에는 값들이 들어간다.Edge는 간선을 의미한다. 간선은 정점과 정점을 연결한다.말 그대
11.[ CS / DataBase ] DataBase
데이터베이스가 등장하기 이전에는 모든 데이터를 파일 시스템으로 관리하였다. 파일 시스템은 데이터를 파일 단위로 저장하고 처리하기 때문에 데이터의 변경이나 삽입, 삭제와 같은 과정에서 데이터 종속성, 중복성, 무결성 침해와 같은 문제가 발생하기 쉽다. 데이터 베이스는 데
12.[ CS / DataBase ] Index
.png)
인덱스는 말 그대로 책에서의 색인이라고 할 수 있다. 이 비유대로 설명하면 데이터는 책의 내용이고, 인덱스는 데이터가 저장된 레코드의 주소가 된다. 만약 DBMS가 원하는 데이터를 가져오기 위해 데이터베이스 테이블의 모든 데이터를 조회하게 된다면 오랜 시간이 걸릴 것이
13.[ CS / DataStructure ] Tree
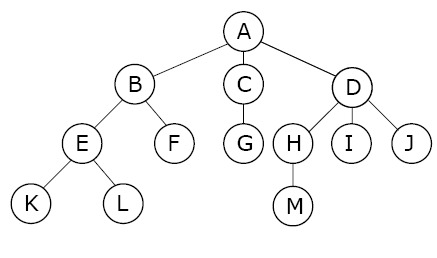
트리는 스택이나 큐와 같은 선형 구조가 아닌 비선형 구조이다. 트리는 계층적 관계를 표현하는 자료구조로 표현에 집중한다. 무엇인가를 저장하고 꺼내야 한다는 사고에서 벗어나 트리라는 자료구조를 바라보는 것이 좋다.트리에서는 각 층별로 숫자를 매겨 이를 트리의 Level(
14.[ CS / DataBase ] 정규화
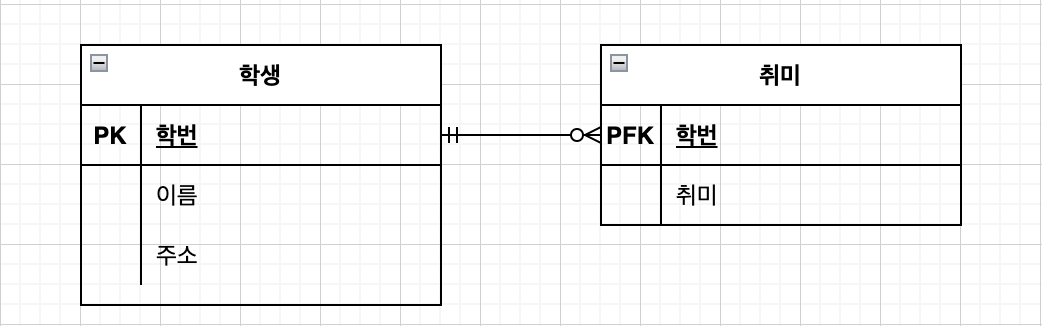
정규화란 관계형 데이터베이스에서 데이터의 중복을 최소화하기 위해 데이터를 구조화 하는 작업을 의미한다. 데이터의 중복을 최소화하여 데이터 무결성을 유지하고 DataBase의 저장 용량 또한 효율적으로 사용할 수 있게 된다. 정규화가 아예 적용되지 않은 경우(데이터 중복
15.[ CS / DataBase ] Transaction
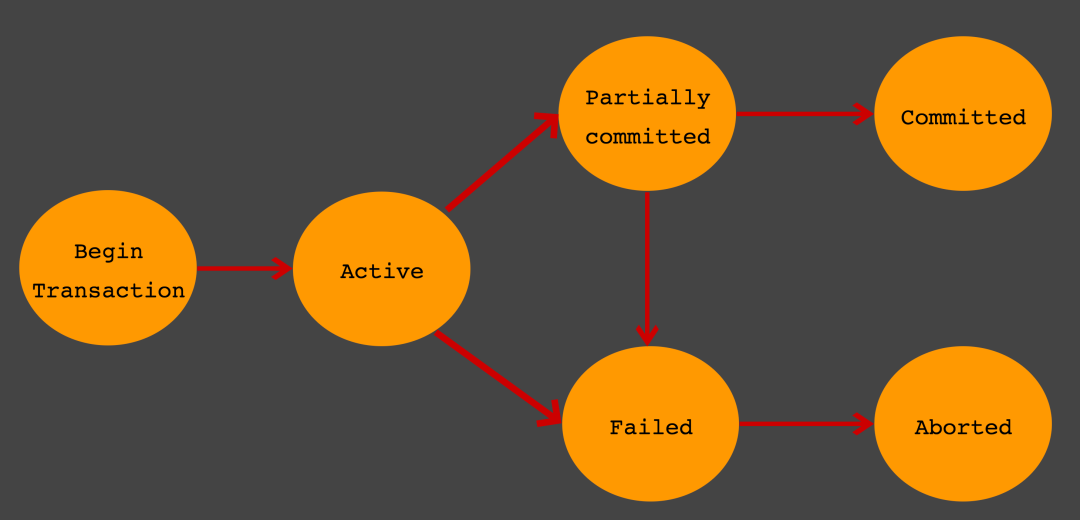
트랜잭션은 여러 개의 수행이 일련의 처리 단위로 묶여 작업의 완전성을 보장해주는 것이다. 만약에 하나의 작업을 위해 3개의 작은 작업들이 돌아가야 한다면 트랜잭션은 이 3개의 작은 작업이 모두 성공적으로 완료되어야만 큰 하나의 작업을 끝낼 수 있도록 해준다. 만약 작은
16.[ CS / DataBase ] Statement vs PreparedStatement

SQL 구문을 실행하는 역할을 한다.스스로는 SQL 구문을 이해하지 못한다. 단지 전달 역할만 한다.SQL 관리는 하지만 연결 정보는 관리하지 않는다.executeQuery()나 executeUpdate()를 실행하는 시점에 파라미터로 SQL문을 전달하게 된다. 이때
17.[ CS / DataBase ] NoSQL
NoSQL은 관계형 데이터베이스(RDBS)보다 덜 제한적인 일관성 모델(비관계형)을 이용하는 데이터 저장 및 검색을 위한 매커니즘을 제공한다. NoSQL은 단순 검색, 추가 작업을 위한 최적화된 키 값 저장 공간으로 시간과 처리율에서 성능 이익을 내는 것이 목적이다.
18.[ CS / Development Common Sense ] Object Oriented Programming
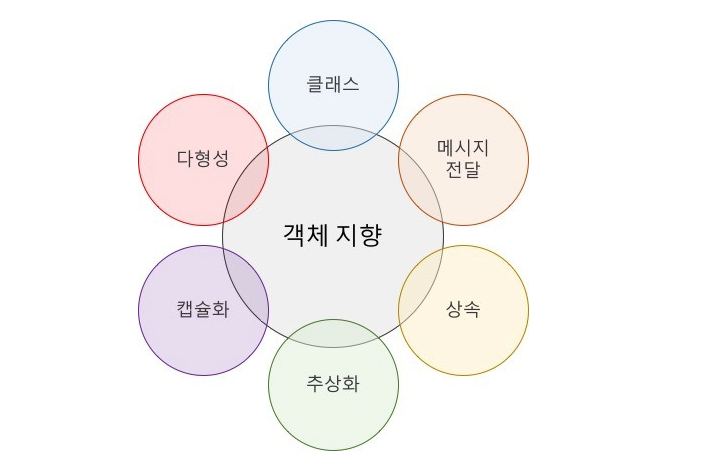
하나의 포스트로 내용을 정리하기에는 너무나 방대하지만 면접에서 사용할 수 있을 정도로만 정리해 보았다.객체 지향 프로그래밍 이전의 프로그래밍 패러다임을 살펴보면 컴퓨터를 중심으로 프로그래밍 하였다. 컴퓨터의 눈높이에서 컴퓨터의 방식대로 프로그래밍하는 것이다. 그러나 객
19.[ CS / Development Common Sense ] RESTful API

RESTful API는 월드 와이드 웹(www)과 같은 분산 하이퍼미디어 시스템을 위한 소프트웨어 아키텍처의 한 형식으로 자원을 정의하고 자원에 대한 주소를 지정하는 방법 전반에 대한 패턴이라고 정의되어 있다.여기서 REST란 REpresentational State
20.[ CS / Development Common Sense ] TDD (Test-Driven Development)
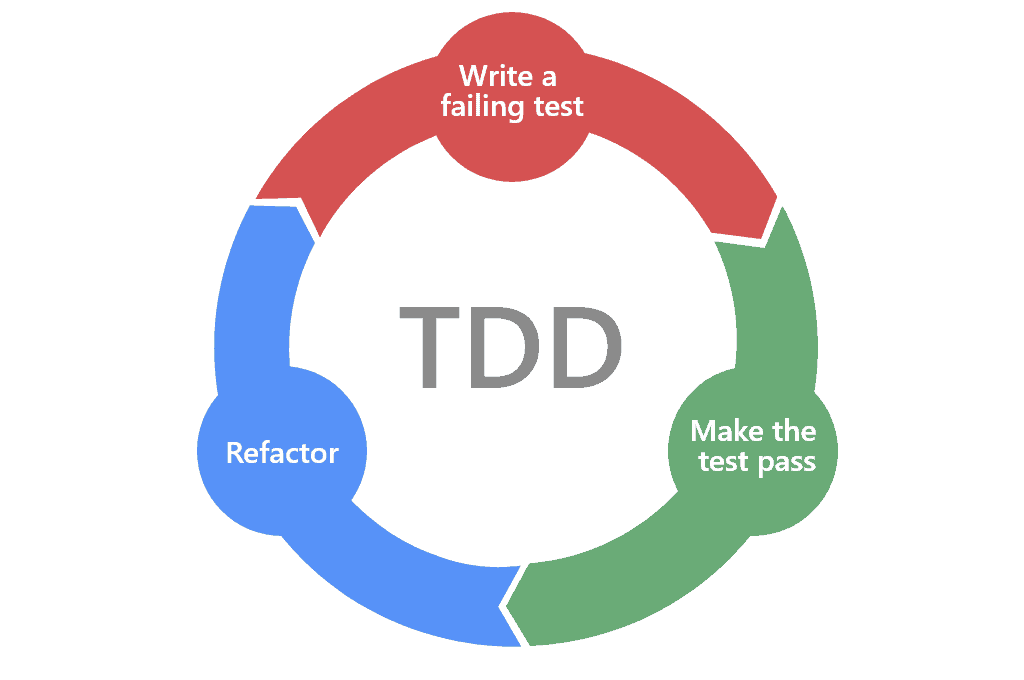
TDD는 매우 짧은 개발 사이클의 반복에 의존하는 소프트웨어 개발 프로세스 중 하나이다. 우선 개발자는 요구되는 새로운 기능에 대한 자동화된 테스트 케이스를 작성하고 해당 테스트를 통과하는 가장 간단한 코드를 작성한다. 우선적으로 테스트를 통과 시킨 후에 코드를 리팩토
21.[ CS / Network ] HTTP의 GET vs POST
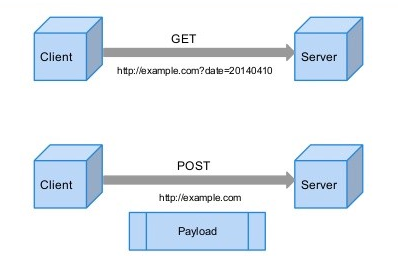
요청하는 데이터가 HTTP Request Message의 Header부분에 URL이 담겨 전송된다.\-> URL 상으로 ? 뒤에 데이터가 붙어 request를 보내게 된다.URL 공간에 데이터가 담겨서 전송되기 때문에 데이터의 크기가 제한적이다.URL 공간에 데이터가
22.[ CS / Network ] TCP 3-way Handshake
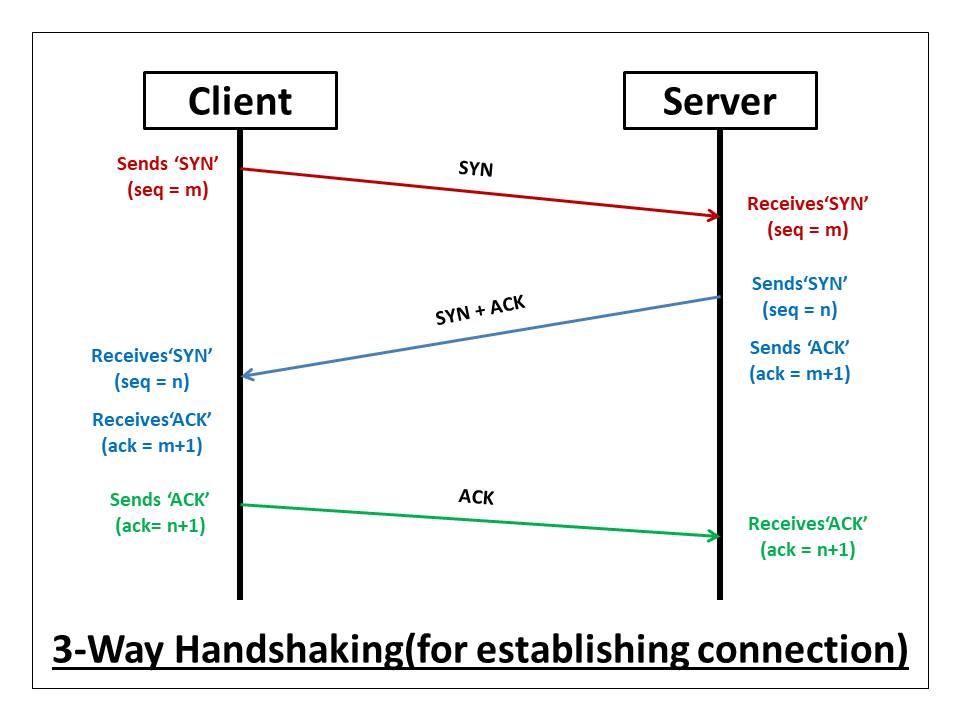
컴퓨터가 다른 컴퓨터와 통신을 하기 위한 규약(프로토콜)의 일종이다. OSI 모형에서 4번째 계층인 전송 계층(Transport Layer)에서 사용하는 규약으로 보통 하위 계층에서 사용하는 IP와 엮어서 TCP/IP로 표현하는 경우가 많다. 동일 계층에서 사용하는 또
23.[ CS / Network ] TCP & UDP
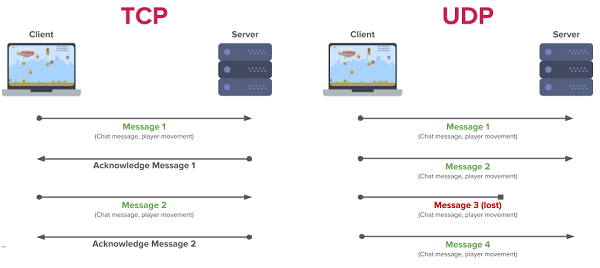
UDP(User Datagram Protocol)는 비연결성 프로토콜이다. IP 데이터그램을 캡슐화해서 보내는 방법과 연결 설정을 하지 않고 보내는 방법을 제공한다. UDP는 흐름제어, 오류제어 또는 손상된 세그먼트의 수신에 대한 재전송을 보장하지 않는다. UDP가 행
24.[ CS / Network ] HTTP & HTTPS

HTTP는 평문 통신이기 때문에 도청이 가능하다.통신 상대를 확인하지 않기 때문에 위장이 가능하다.완전성을 증명할 수 없기 때문에 변조가 가능하다.이 문제점들은 암호화하지 않은 다른 프로토콜에서도 공통적으로 발생하는 문제점이다.TCP/IP 구조의 통신은 전부 통신 경로
25.[ CS / Network ] DNS Round Robin
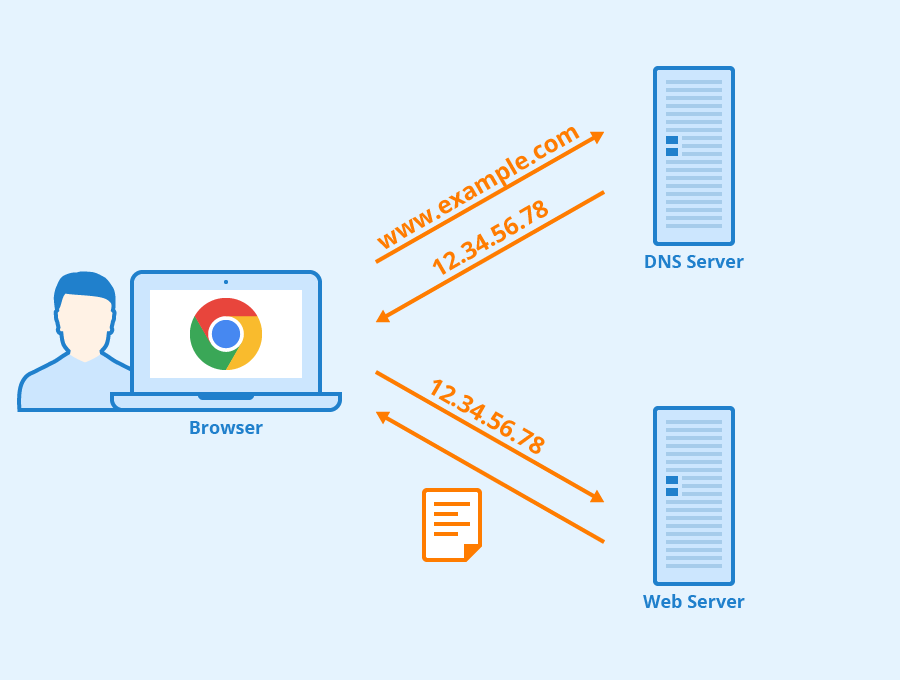
DNS Round Robin에 대해 알아보기 이전에 먼저 DNS가 무엇인지 간단하게 짚고 넘어갈 필요가 있다. DNS란 Domain Name System의 약자로 IP 네트워크에서 사용하는 시스템이다. URL 상에서 영문을 사용해 원하는 사이트에 접속하게 되는데 이때
26.[ CS / Network ] 웹 통신의 흐름
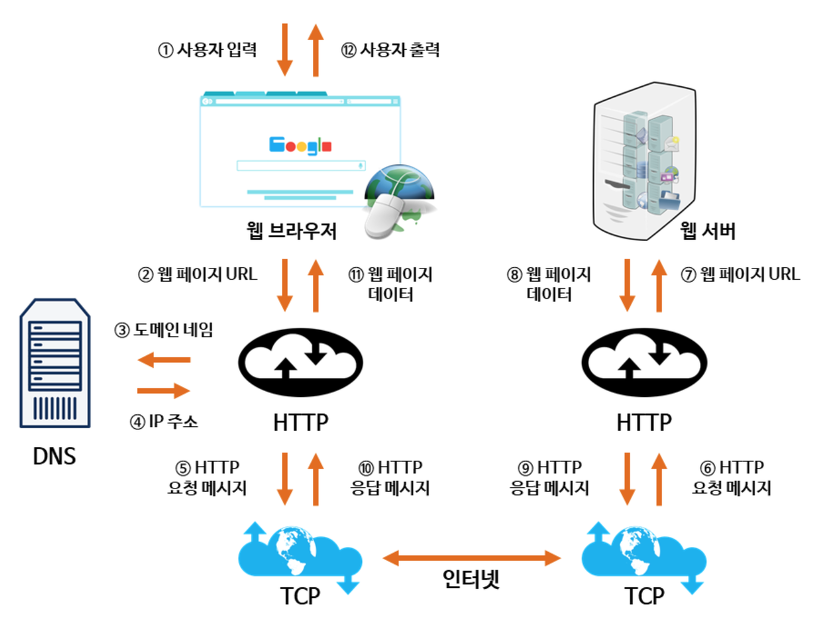
Chrome을 실행시켜 주소창에 특정 URL을 입력한다고 가정한다.1\. URL에 입력된 값을 브라우저 내부에서 결정된 규칙에 따라 그 의미를 조사한다.2\. 조사된 의미에 따라 HTTP Request 메세지를 만든다.3\. 만들어진 메세지를 웹 서버로 전송한다.이때
27.[ CS / OS ] Process & Thread
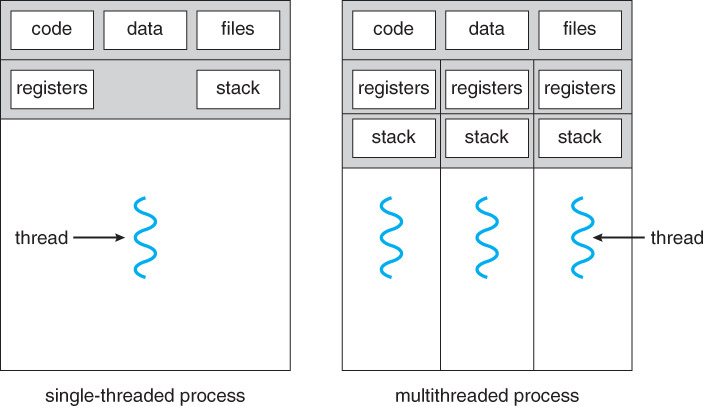
Process & Thread Program 프로그램은 어떤 작업을 위해 실행할 수 있는 파일 Process 프로세스는 컴퓨터에서 연속적으로 실행 중인 프로그램 디스크로부터 메모리에 적재되어 CPU를 할당받아 실행(독립적인 개체) OS로부터 시스템 자원(주소공간, 파일
28.[ CS / OS ] Multi-Process & Multi-Thread
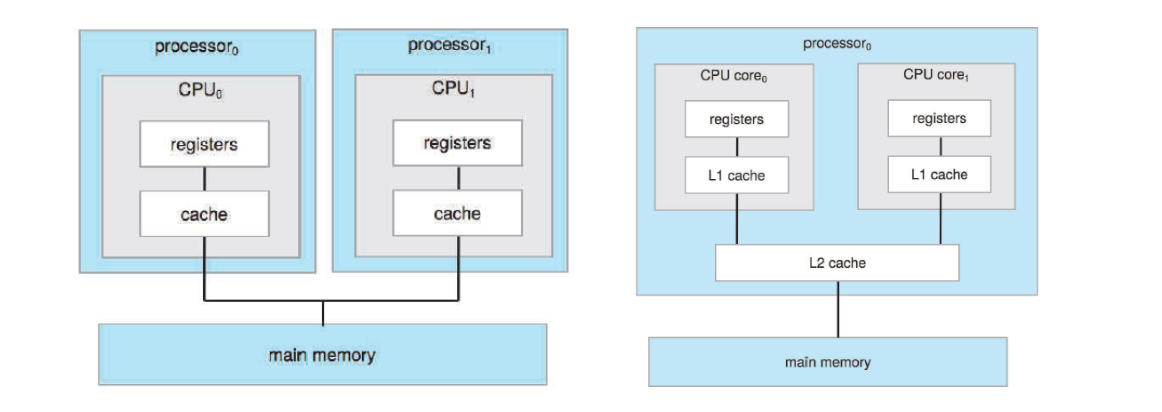
멀티 프로세스는 하나의 응용 프로그램을 여러 개의 프로세스로 구성하여 각 프로세스가 하나의 작업을 처리하도록 하는 것이다.프로세스의 독립적인 성격 덕분에 작업을 처리하던 중에 하나의 프로세스에서 문제가 발생하더라도 다른 프로세스에는 영향을 주지 않는다. Context
29.[ CS / OS ] Scheduler
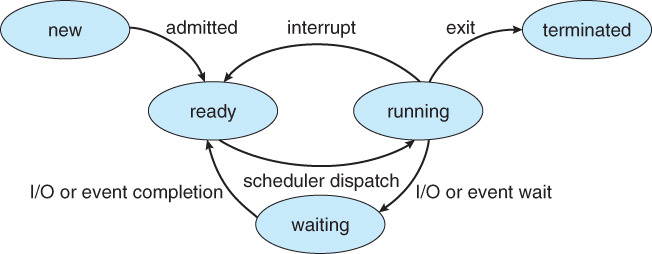
프로세스 스케줄링이란 프로세스가 생성되어 실행될 때 필요한 시스템의 여러 자원을 해당 프로세스에게 할당하는 작업을 의미한다. 대기 시간은 최소화하고 최대한 공평하게 처리하는 것을 목적으로 한다.스케줄러를 살펴보기 전에 프로세스의 상태를 간단하게 알아보았다.new: 새로
30.[ CS / OS ] CPU Scheduler
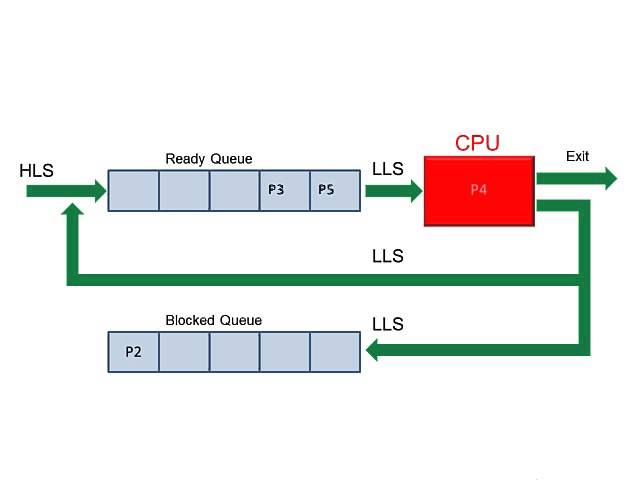
스케줄링의 대상은 Ready Queue에 있는 프로세스들이다. 즉 CPU의 할당에 대한 스케줄링을 진행한다.하나의 프로세스가 다른 프로세스 대신에 CPU를 차지할 수 있다. 즉, 이전에 CPU를 할당받아 사용 중인 프로세스가 존재하더라도 특정 조건에 충족한다면 다른 프
31.[ CS / OS ] Synchronous & Asynchronous
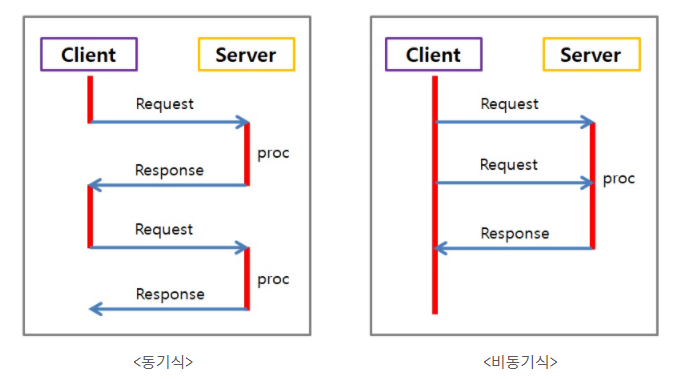
일반적으로 동기와 비동기의 차이는 메소드를 실행시킴과 동시에 반환 값이 기대되는 경우를 동기라고 표현하고, 그렇지 않은 경우를 비동기라고 표현한다. 메소드를 실행시킴과 동시에 반환 값을 기대한다는 의미는 실행되었을 때 값이 반환되기 전까지 blocking되어 있는다는
32.[ CS / OS ] 프로세스 동기화
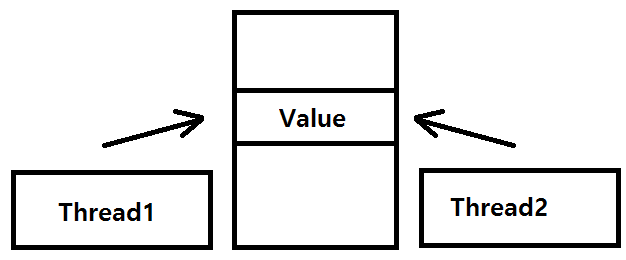
멀티 스레딩의 문제점에서 나오듯, 동일한 자원을 동시에 접근하는 작업을 실행하는 코드 영역을 Critical section이라고 한다. 즉, 여러 개의 프로세스가 동시에 접근할 때 문제가 발생할 수 있는 영역이다.프로세스들이 임계 영역을 함께 사용할 수 있는 프로토콜을
33.[ CS / OS ] 메모리 관리 전략
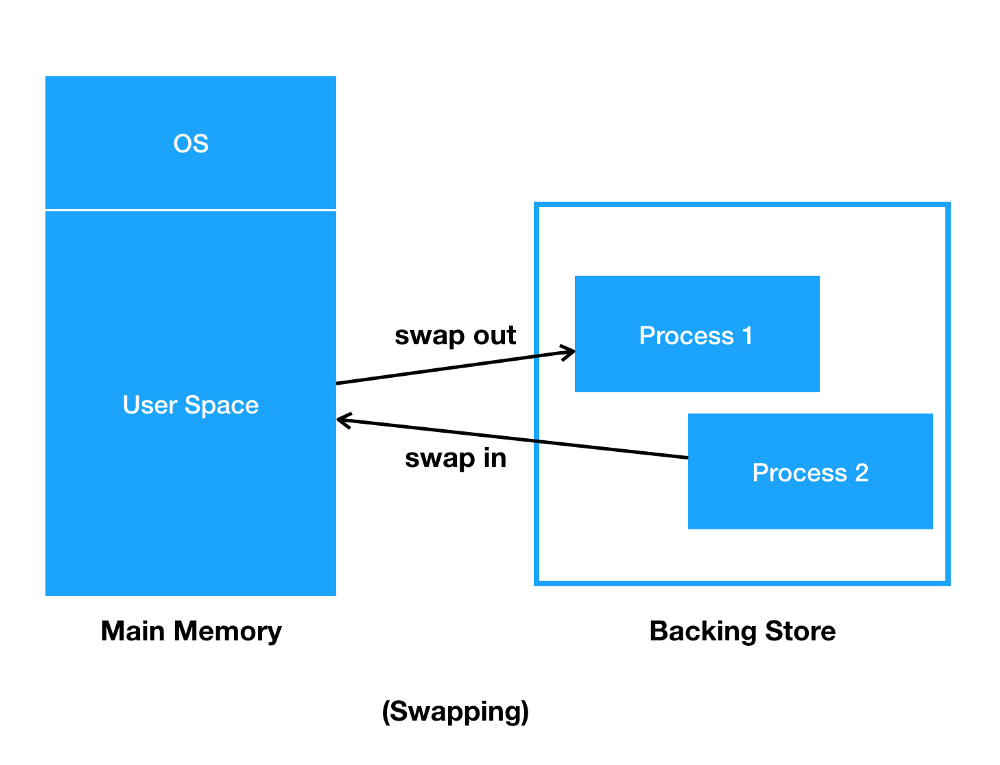
각각의 프로세스는 독립된 메모리 공간을 가지고, 운영체제 혹은 다른 프로세스의 메모리 공간에 접근할 수 없다. 오직 운영체제만이 운영체제의 메모리 영역과 사용자 메모리 영역에 모두 접근할 수 있다.메모리의 관리를 위해 사용되는 기법으로 Round-Robin과 같은 스케
34.[ CS / OS ] 가상 메모리 (Virtual Memory)
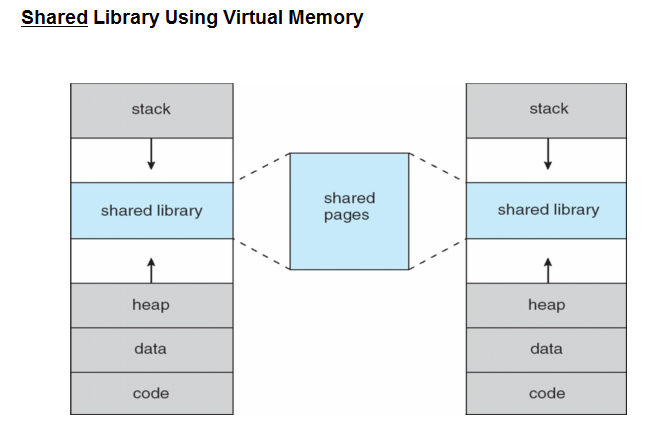
다중 프로그래밍을 실현하기 위해서는 많은 프로세스들을 동시에 메모리에 올려두어야 한다. 가상 메모리는 프로세스 전체가 메모리 내에 올라오지 않더라도 실행이 가능하도록 하는 기법이며, 프로그램이 물리 메모리보다 커도 된다는 주요 장점이 있다.과거에는 실행되는 코드의 전부
35.[ CS / OS ] 캐시의 지역성
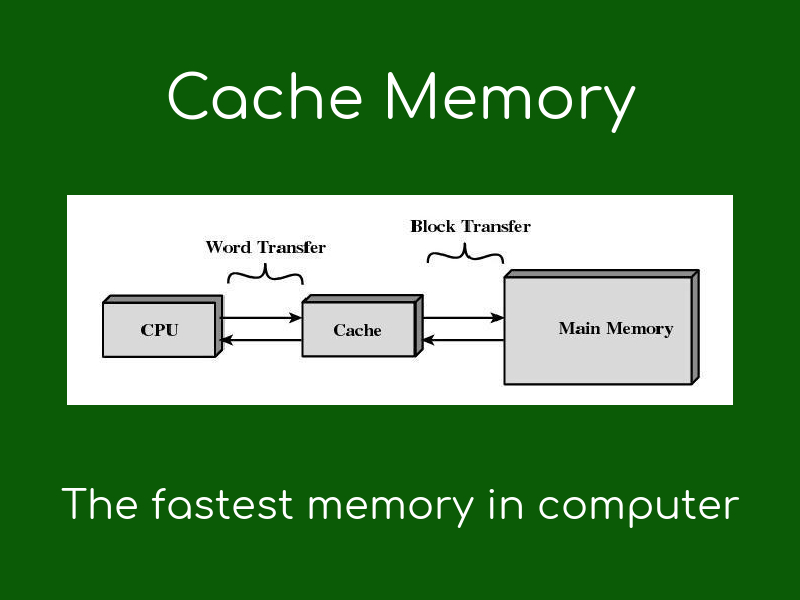
캐시 메모리는 속도가 빠른 장치와 느린 장치 간의 속도차에 따른 병목 현상을 줄이기 위한 범용 메모리이다. 이러한 역할을 수행하기 위해서는 CPU가 어떤 데이터를 원하는지 어느정도 예측할 수 있어야 한다. 캐시의 성능은 작은 용량의 캐시 메모리에 CPU가 이후에 참조할
36.[ CS / DataBase ] B-Tree vs Hash
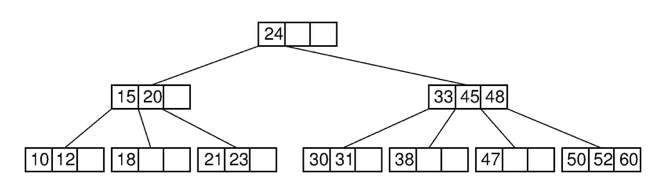
이전에 B-Tree와 Hash Index 간의 차이를 정리한 글을 작성한 적이 있다. 조금 더 간단하게 요약해서 정리를 한번 더 해보려고 한다.data의 검색이 필요할 경우에 Index를 통해 범위를 제한하게 되고, 이로 인해 검색의 속도가 매우 빨라진다.Index의
37.[ CS / Network ] OSI 7 Layer
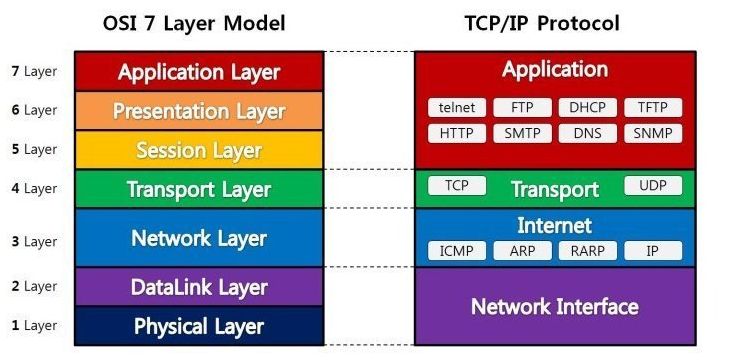
국제표준화기구(ISO)에서 제안한 모델로, 컴퓨터 네트워크 프로토콜 디자인과 통신을 계층으로 나누어 설명한다. 각 계층은 하위 계층의 기능을 이용하여 상위 계층에 기능을 제공한다.계층을 나눔으로써 각 기능을 독립적으로 수행할 수 있게 되고, 문제가 발생했을 때 어디서
38.[ CS / Network ] HTTP
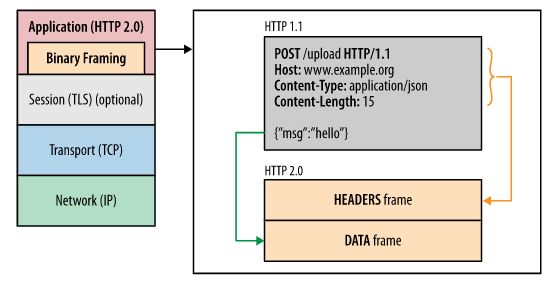
HTTP는 Hyper Text Transfer Protocol의 약자로, W3 상에서 정보를 주고 받을 수 있는 프로토콜이다. 주로 TCP를 사용하고, HTTP/3부터는 UDP를 사용하며, 80번 포트를 사용한다.클라이언트와 서버 사이에 이뤄지는 요청/응답 프로토콜이라
39.[ CS / Network ] 웹 브라우저에 google.com을 입력하면 일어나는 일
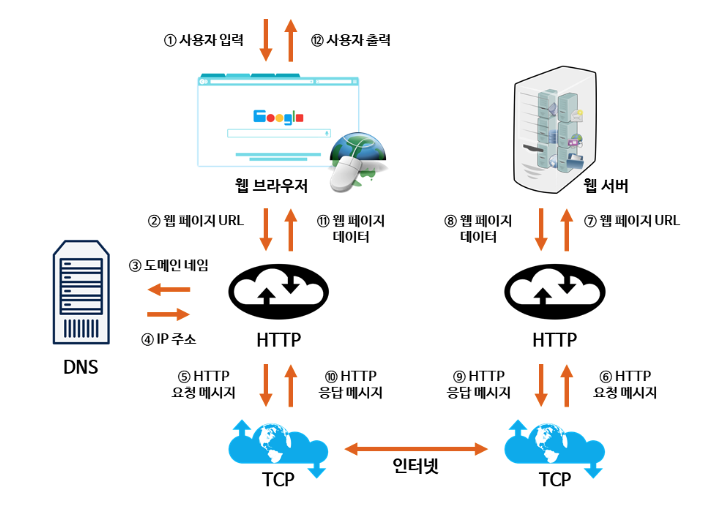
웹 브라우저에 google.com을 입력하면 일어나는 일에 대한 과정을 정리해보려고 한다.간단하게 google.com을 입력하면 생기는 과정들을 나열하면 다음과 같다.URL의 도메인 네임을 DNS 서버에 검색하여 해당하는 IP 주소를 찾아 입력된 URL과 함께 전달.브
40.[ CS / DataBase ] Transaction

데이터를 가공하다보면 하나의 API를 통해 여러 데이터를 한번에 수정하거나 생성하고 삭제하는 경우가 발생하기 마련이다. 이러한 API를 요청하여 서버가 이를 수행하던 도중 서버에 문제가 생겨 종료된다면 어떤 일이 발생할까?은행의 송금 시스템을 예로 들어보자. 만약 A가
41.[ CS / OS ] DeadLock
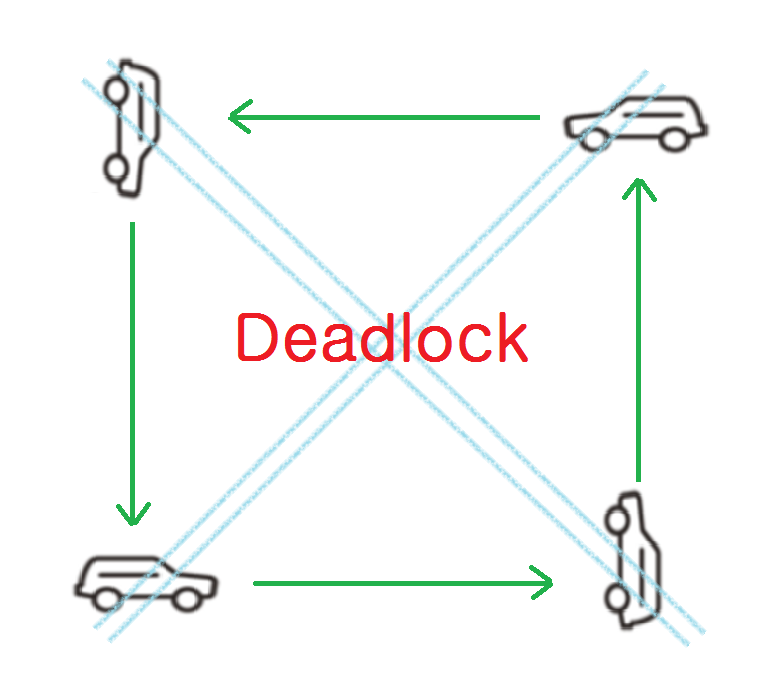
DeadLock이란 2개 이상의 작업이 서로의 종료를 기다리며 아무것도 완료하지 못하는 상태를 의미한다. DeadLock의 조건에는 4가지가 존재한다.작업이 필요로 하는 자원에 대해 배타적인 통제권을 가지는 것을 의미한다.각 작업들이 자원을 점유한 상태로 다른 작업의
42.[ CS / Data Structure ] Map
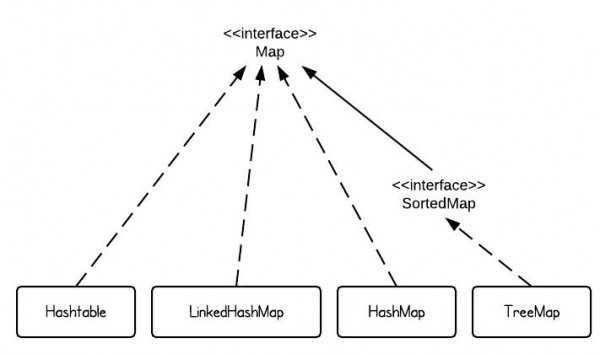
이번 게시물은 자료구조 중 Map과 HashMap, TreeMap의 차이에 대해 알아보려고 한다.Map은 interface의 종류이다. Key와 Value를 가지는 자료형으로, Key값의 중복은 허용하지 않으며, java.util 패키지에 여러 집합들을 사용하기 위한
43.[ CS / Data Structure ] List vs Array
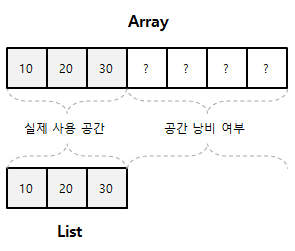
이번 게시물에서는 리스트(List)와 배열(Array)에 대하여 알아보려고 한다. 리스트는 빈틈없는 데이터 적재에 초점을 맞춘 자료구조이다. 리스트는 원소들 간의 순서가 있는 데이터의 모임이라고 할 수 있다.리스트의 인덱스는 각 원소들의 순서를 나타내는 지표로 사용된다
44.[ CS / Data Structure ] 정렬 알고리즘
보통 코테 문제를 풀이할 때는 sort()함수를 사용하여 정렬하지만, 정렬을 실제로 구현하는 데에는 많은 방법이 존재한다. 정렬 알고리즘의 종류에는 Selection Sort(선택 정렬), Bubble Sort(버블 정렬), Quick Sort(퀵 정렬), Insert
45.[ CS / DataBase ] Transaction isolation level
트랜잭션 격리 수준이란, 여러 개의 트랜잭션이 동시에 처리될 때에 트랜잭션 간 고립의 정도를 나타내는 것이다.격리 수준은 다음과 같이 4가지로 나눠진다.READ UNCOMMITTEDREAD COMMITTEDREPEATABLE READSERIALIZABLEREAD UNC
46.[ CS / Network ] SSL (Secure Socket Layer)

SSL은 Secure Socket Layer의 약자로, 암호화 기반 인터넷 프로토콜이다. 인터넷 통신의 정보 보호, 인증, 무결성을 보장하기 위해 등장하였다.SSL은 OSI 7 Layer의 Presentation Layer에서 처리되고, 공개키 암호화 기법으로 암호화를
47.[ CS / Network ] RESTful API
그동안 개발을 해오면서 RESTful API를 구현해왔지만, RESTful API에 대한 정의는 알지 못하고 있었다. 그래서 이번에는 RESTful API에 대한 내용을 정리해보려고 한다.REST는 Representational State Transfer의 약자로, 자
48.[ CS / OS ] Blocking VS Non-blocking / Sync VS Async
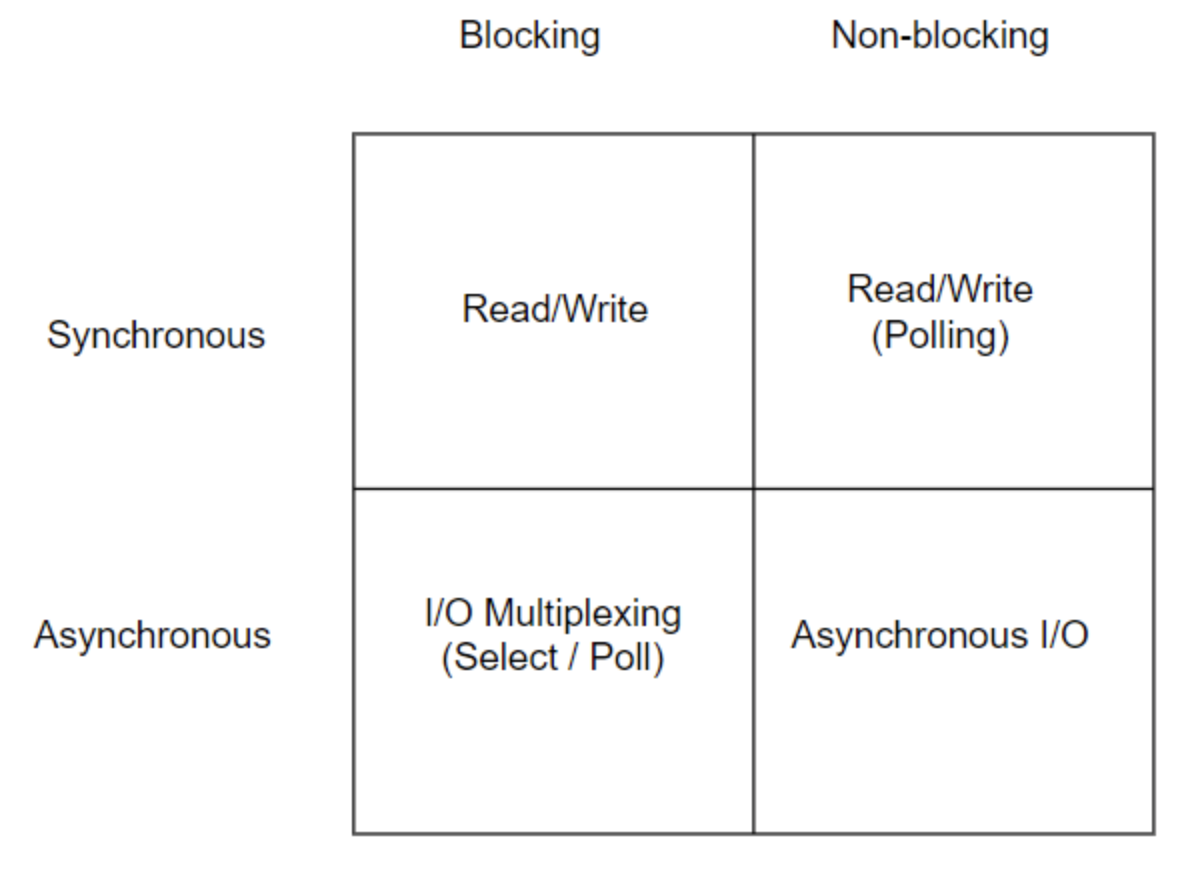
이번에 신한은행 1차 면접에서 Blocking과 Non-blocking의 차이를 설명해보라는 질문이 나왔다. 정말 기초적인 부분이지만, 놓치고 있었던 부분이었고, 이 부분에 대해 설명드리지 못해 너무나 아쉬웠다. 기초적이지만 놓치고 있었던 부분을 하나하나씩 찾아보며 공
49.[ CS / OS ] Thread-safe
멀티 스레드를 활용하는 경우, 가장 조심해야 할 부분이 바로 동기화이다. 프로세스 내부에서 스택을 제외한 힙, 데이터, 코드 영역을 공유하기 때문에 내부적으로 통신은 간편하지만, 그만큼 공유자원의 충돌이 발생할 수 있기 때문에 동기화를 잘 적용해줘야 안전하게 사용할 수
50.[ CS / Network ] Cookie & Session
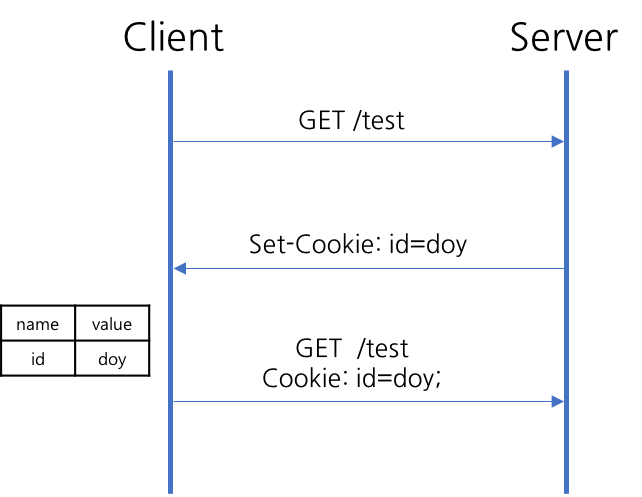
HTTP프로토콜은 다음과 같은 특징을 가진다.비연결 지향 (Connectionless)요청에 의한 응답을 완료하면 바로 연결을 끊는다.상태정보 유지 안함 (Stateless)연결을 끊으면 클라이언트와 서버 간의 통신이 종료되고, 상태정보를 남기지 않는다.쿠키는 클라이언
51.[ CS / OS ] Fragmentation (단편화)
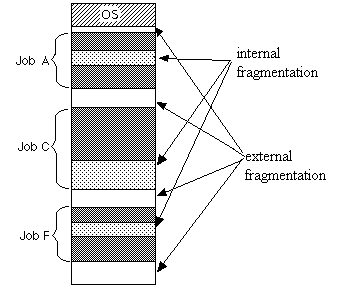
단편화란 기억장치의 빈 공간 또는 자료가 여러 개의 조각으로 나뉘는 현상을 말한다. 할당된 메모리 간의 프로그램이 들어갈 수 없을 정도의 남는 메모리 공간이 발생하는 것을 말한다.이 경우, 해당 공간에 프로그램을 적재할 수 없기 때문에 메모리 낭비를 초래한다.어떠한 프
52.[ CS / OS ] Interrupt (인터럽트)
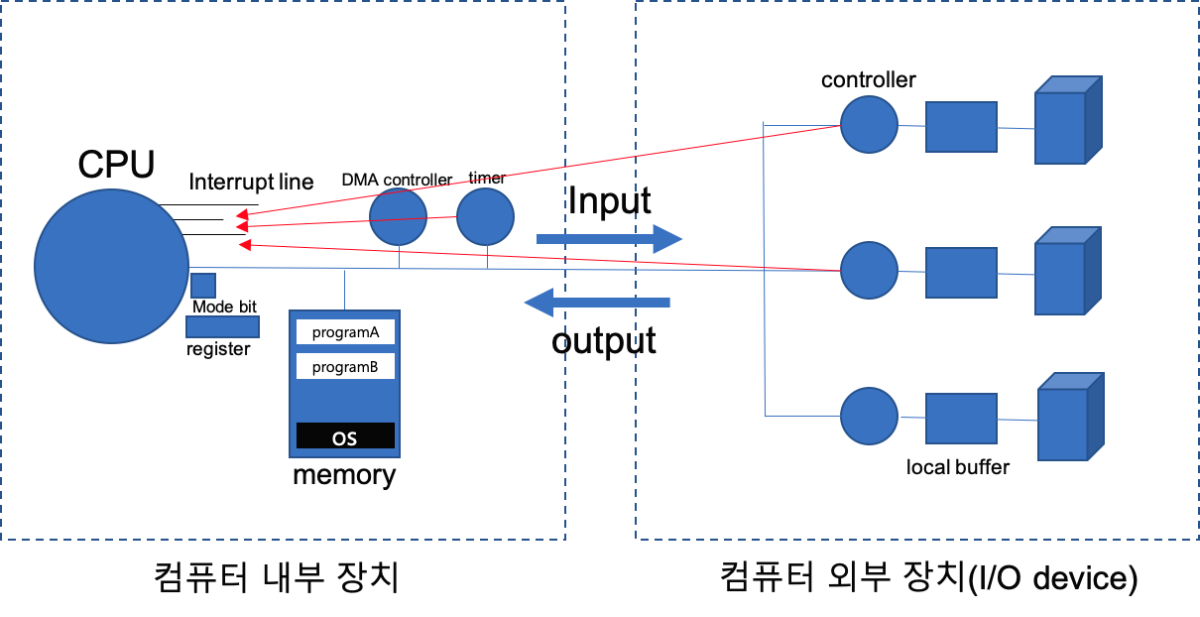
인터럽트란 하드웨어 장치가 CPU에게 어떠한 이벤트를 전달하거나 어떠한 수행을 요구할 때에 CPU의 인터럽트 라인을 세팅하여 발생시킨다. CPU는 PC(Program Counter)가 가리키고 있는 작업을 계속해서 수행하는데, 이렇게 다음 작업을 수행하기 전에 인터럽트
53.[ CS / Network ] Load Balancing
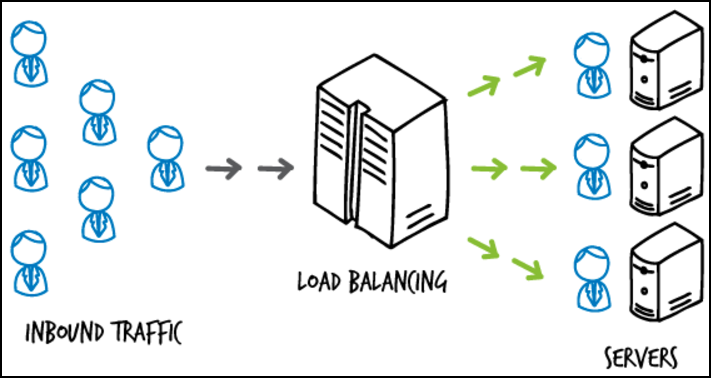
오늘날 웹/앱 서비스를 이용하는 고객들이 계속해서 증가하고 있다. 이에 따라 1개의 서버로는 수많은 요청을 처리할 수 없기 때문에 여러 개의 서버를 사용한다. 수많은 요청이 여러 개의 서버 중 하나에 집중된다면 어떻게 될까? 다른 서버들은 작업을 수행하지 않아 낭비될
54.[ CS / Network ] CORS
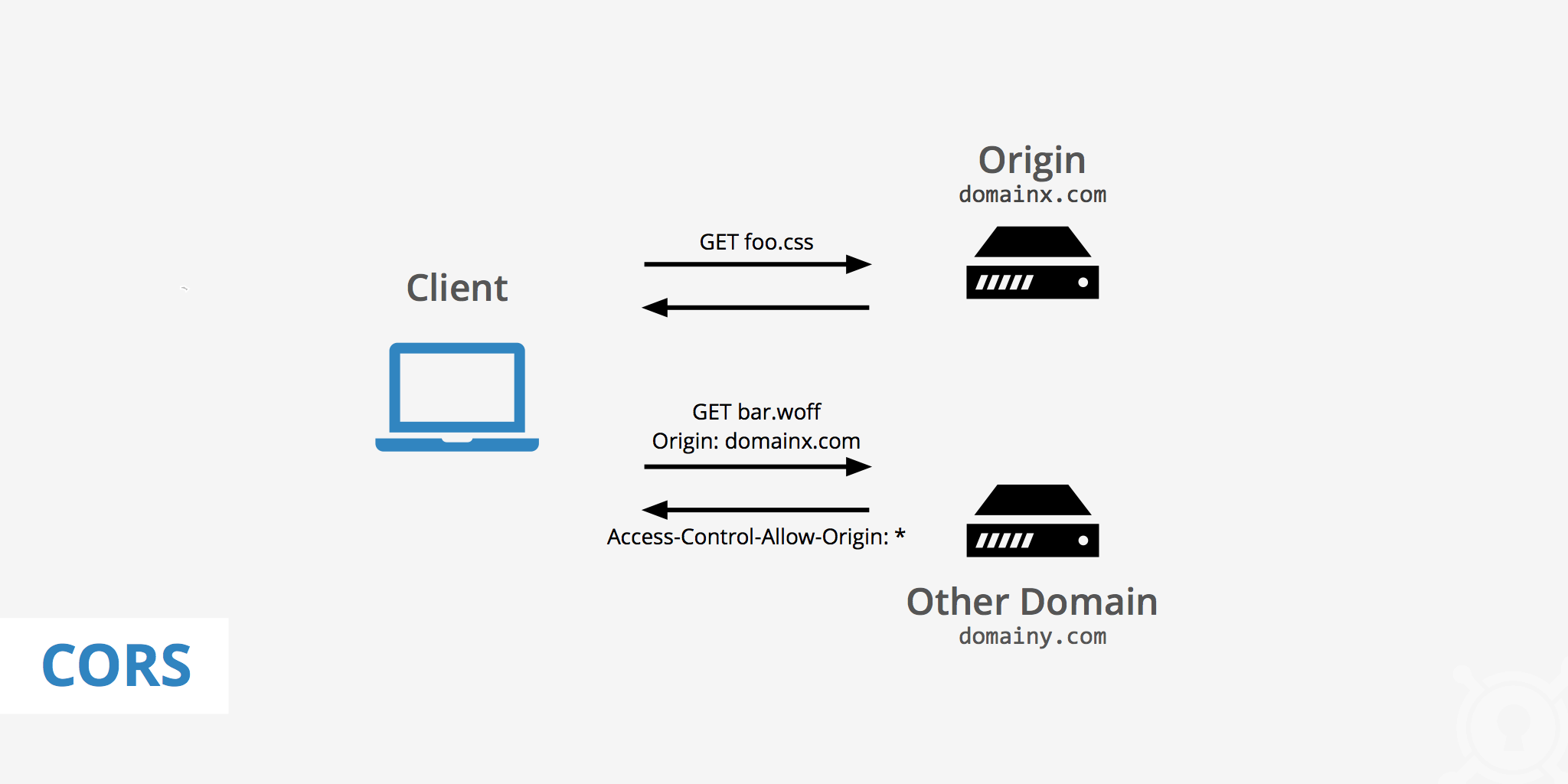
브라우저는 Cross-Origin HTTP요청들을 받으면, 이를 보안상의 이유로 제한한다. Cross-Origin 요청에 대한 응답을 받기 위해서는 서버의 동의가 필요한데, 서버가 이를 동의할 경우 요청에 대한 응답을 처리하고, 그렇지 않을 경우 브라우저에서 거절한다.
55.[ CS / Network ] Socket
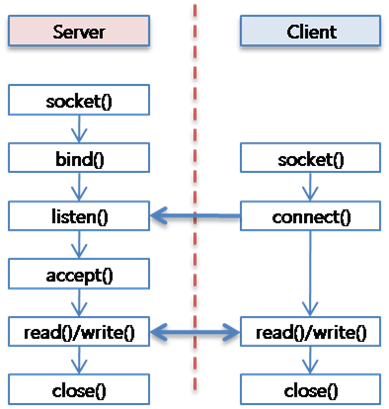
소켓은 네트워크 상에서 돌아가는 두 개의 프로그램 간 양방향 통신의 하나의 엔드포인트이다. 포트번호로 바인딩되어 TCP 계층에서 데이터가 전달되어야하는 Application을 식별할 수 있게 해준다.소켓은 프로토콜, IP주소, 포트번호로 정의된다. 다시 말해 소켓은 두
56.[ CS / Web ] JWT (JSON Web Token)
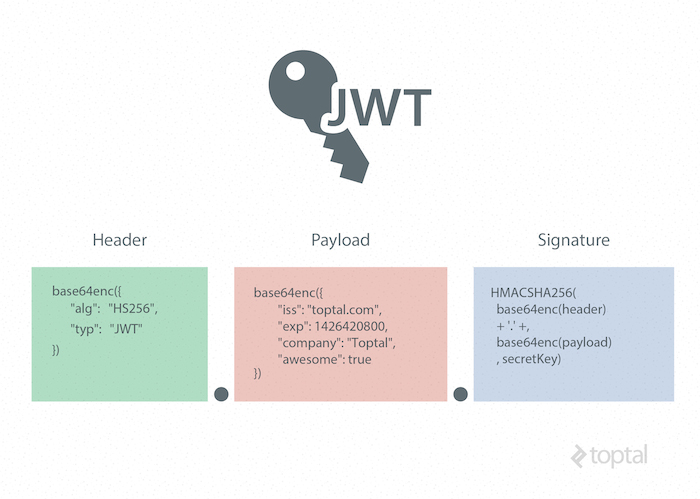
JWT는 JSON Web Token를 줄인 말로, 말 그대로 두 개체에서 JSON 객체를 사용하여 가볍고 자기수용적인 방식으로 정보를 안전성 있게 전달해주는 웹 토큰이다.쿠키나 세션이 탈취당하여 발생할 수 있는 보안 문제를 막을 수 있음JWT는 쿠키를 사용하지 않기 떄
57.[ CS / DataBase ] Redis

Redis는 Remote Dictionary Server의 약자로, Key-Value 구조의 NoSQL 중 하나이다. Redis는 Memcached와 비슷한 캐시 시스템으로서 동일한 기능을 제공하며, 영속성, 다양한 데이터 구조와 같은 부가적인 기능을 지원한다. 모든
58.[ CS / DataBase ] CAP 이론
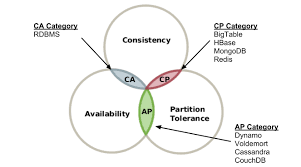
데이터베이스에는 CAP 이론이 존재한다. CAP 이론은 일관성(Consistency), 가용성(Availability), 분단 허용성(Patition Tolerance)의 줄임말로, 이렇게 3가지 특성 중 2가지 특성만 충족 가능하다는 이론이다. 이는 구현하고자 하는
59.[ CS / Network ] TCP Hand-Shake Sequence Number
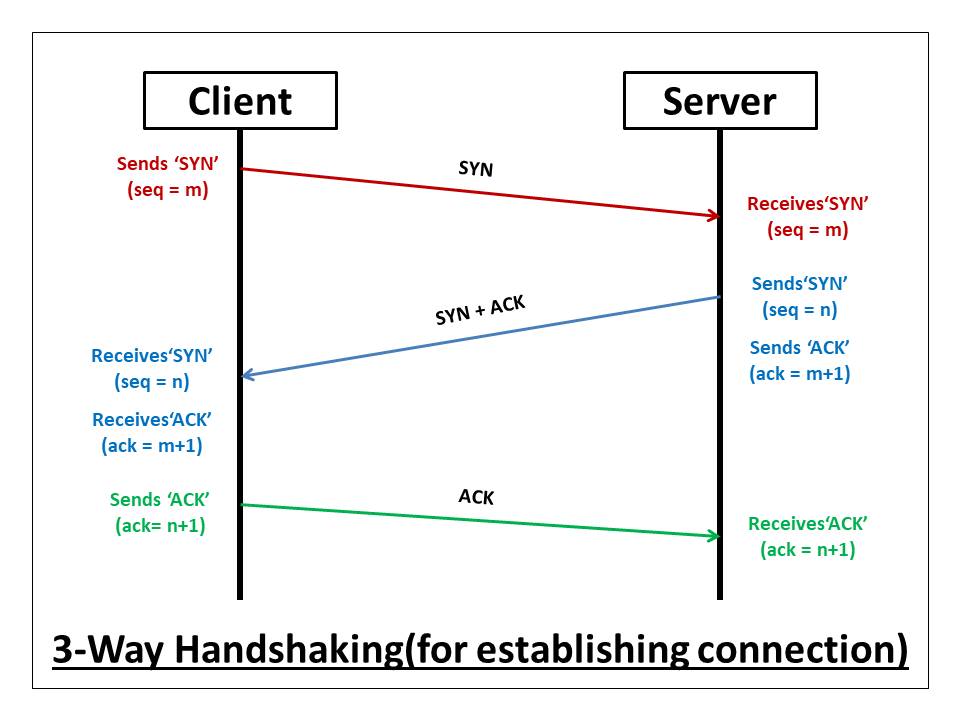
TCP는 데이터를 주고 받을 때 사용되는 프로토콜 중 하나로, 연결 지향형으로 알려져 있다. 가상 회선을 연결하여 클라이언트와 서버 간의 통신에 신뢰를 보장하는 방식이다. 가상 회선을 연결하기 위해 연결 요청과 연결 허가에 대한 통신이 먼저 이루어지고, 이 과정에서 신
60.[ CS / DataBase ] Statement & Prepared Statement
statement와 Prepared Statement에 대해 공부해보자.우선 가장 큰 차이점은 캐시의 사용 여부이다. 쿼리문을 수행할 때마다 SQL 실행단계 1, 2, 3단계를 거친다. SQL문을 수행할 때마다 매번 컴파일하기 때문에 성능 이슈가 있다.실행되는 SQL문