Redis

Redis는 Remote Dictionary Server의 약자로, Key-Value 구조의 NoSQL 중 하나이다. Redis는 Memcached와 비슷한 캐시 시스템으로서 동일한 기능을 제공하며, 영속성, 다양한 데이터 구조와 같은 부가적인 기능을 지원한다. 모든 데이터를 메모리에 저장하는 인메모리 DB이기 때문에 데이터를 불러오는 속도가 매우 빠르다.
즉, Key-Value 구조의 NoSQL DBMS임과 동시에 Memcached와 같은 인메모리 솔루션으로 분리된다.
Redis 특징
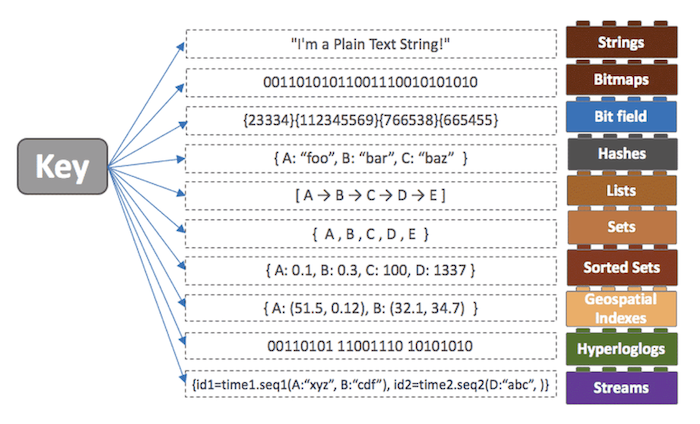
- 다른 인메모리 DB들과 다르게 다양한 데이터 구조 지원
- 개발의 편의성 증가
- 개발 난이도 낮아짐
- ex) 데이터를 정렬해야 하는 상황에서 RDBMS를 이용할 경우, DB에 데이터를 저장하고 저장된 데이터를 정렬하여 다시 읽어오는 과정에서 디스크에 직접 접근하기 때문에 시간이 오래 걸림 -> Redis의 Sorted-Set 자료구조를 사용하면 더 빠르고 간단하게 데이터를 정렬할 수 있음.
- 영속성을 지원하는 인메모리 데이터 저장소(디스크 X)
- 높은 읽기 성능을 위한 서버 측 복제 지원
- 높은 쓰기 성능을 위한 클라이언트 측 샤딩 지원
In-Memory Cache
인메모리 캐시란 말 그대로 데이터를 디스크에 저장하지 않고, 메모리 상에 저장하여 빠르게 접근할 수 있는 캐시로 사용하는 것이다.
DB 접근 요청이 많이 이뤄지면 디스크에 접근하는 횟수가 많아져 DB서버에 부하가 증가하게 되는데, 이때 인메모리 캐시를 적용하면 디스크가 아닌 메모리 상에서 바로 접근이 가능하기 때문에 성능과 처리 속도가 개선된다.
즉, DB에 캐시를 적용하여 성능을 높이는 기술이다.
Redis 장점
Redis는 대형 서비스 업체들이 사용자들 간의 대규모 메세지를 실시간으로 처리하기 위해 사용된다. NoSQL 중 Redis가 특히 많이 사용되는 이유는 다음과 같다.
- 데이터 저장소로 입출력이 가장 빠른 메모리를 채택
- Key-Value라는 단순한 구조를 통한 빠른 속도
- 캐시 및 데이터 스토어에 유리
- 다양한 API 지원
- 메모리를 활용하면서 데이터 영속성 지원
- 디스크에 직접 저장하는 방법 (RDB: Snapshotting)
- 모든 write/update 연산 자체를 log 파일에 기록하는 방법 (AOF: Append On File)
Redis 단점
- 메모리 단편화가 발생하기 쉬움
- 메모리 2배로 사용
- 데이터 변경이 잦기 때문에 실제 메모리만큼 자식 프로세스가 복사하게 되고, 이 때문에 메모리가 2배로 사용됨
- 싱글 쓰레드
- copy-on-write 방식 사용
- 메모리 2배로 사용
- 대규모 데이터에 대한 응답 속도 불안정성
- jemalloc를 사용하기 때문에 매번 malloc과 free를 통해 메모리 할당이 이루어짐.
- 극단적인 대규모 데이터가 들어왔을 경우 응답 속도가 불안정할 수 있음
- jemalloc를 사용하기 때문에 매번 malloc과 free를 통해 메모리 할당이 이루어짐.
Redis 자료형 실습
brew install redis (Redis 설치)
redis-server (Redis Server 실행)
redis-cli (Redis Client 접속)
brew services start redis (Redis 서비스 실행)
brew services stop redis (Redis 서비스 중지)
brew services restart redis (Redis 서비스 재실행)
flushAll (Redis 모든 Key 삭제)Redis-cli

- Redis Client를 실행한다.
Key-Value

set key value문법을 통해 key-value 데이터를 추가한다.
위의 이미지에서는 key1이 key가 되고, "Hello"가 value가 된다.get key문법을 통해 입력된 key에 대한 value를 조회할 수 있다.
위의 이미지에서는 key1을 조회한 결과이다.- 실습 때는 까먹고 못했지만
append key value문법을 통해 해당 key에 대한 value를 이어 붙일 수 있다.
Set
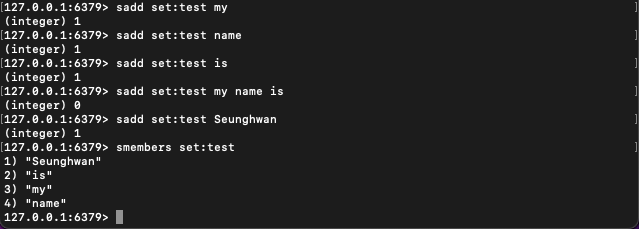
sadd set:setname value문법을 통해 set 데이터를 추가한다.
위의 이미지에서는 test라는 set에 my, name, is, my name is, Seunghwan을 넣은 것이다.smembers set:setname문법을 통해 set의 데이터를 조회한다.
위의 이미지에서는 test라는 set을 조회한 결과이다.
SortedSet

zadd ranking score value문법을 통해 sortedSet 데이터를 추가한다.
위의 이미지에서는 1이라는 가중치를 가진 A, B, C, D를 넣은 것이다. 가중치로 정렬된다.zrange ranking start stop문법을 통해 출력 범위를 지정할 수 있다.
위의 이미지에서는 0 -1을 범위로 주어 전체를 조회한 결과이다.
HashMap
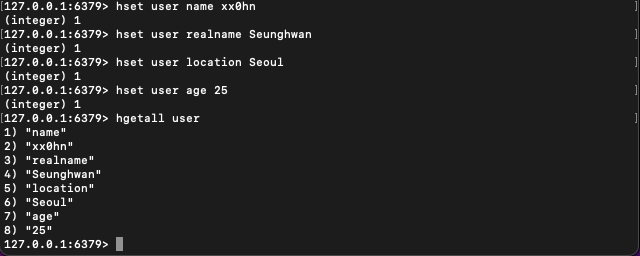
hset hsetname hashkey hashvalue문법을 통해 hashmap 데이터를 추가한다.
위의 이미지에서는 user라는 hashmap에 name: xx0hn, realname: Seunghwan, location: Seoul, age: 25를 추가한 것이다.hgetall hsetname문법을 통해 hashmap을 조회한다.
위의 이미지에서는 user라는 hashmap을 조회한 결과이다.

꾸준함을 꿈꾸는 SW 전공 학부생의 개발 일기