
힙 (Heap)
힙은 힙의 특성 (최소 힙에서는 부모가 항상 자식보다 작거나 같다)을 만족하는 거의 완전한 트리인 특수한 트리 기반의 자료구조이다.
힙은 트리 기반의 자료구조이다. 파이썬에서 우선순위 큐를 사용할 때 heapq 모듈을 사용하는데 이것이 바로 파이썬에서의 힙이다. 파이썬에서의 힙은 최소 힙만 구현되어 있다. 최소 힙은 항상 부모가 자식보다 작기 때문에 루트가 결국 가장 작은 값을 가지게 되며, 우선순위 큐에서 가장 작은 값을 추출하는 것은 매번 힙의 루트를 가져오는 형태로 구현된다. 기반 구현을 보면 우선순위 큐 ADT는 주로 힙으로 구현하고, 힙은 주로 배열로 구현한다. 따라서 우선순위 큐는 결국 배열로 구현되는 셈이다.
힙은 정렬된 구조가 아니라는 점에서 많이 착각한다. 최소 힙의 경우 부모 노드가 항상 작다는 조건만 만족할 뿐, 서로 정렬되어 있지 않다. 단지 부모가 자식보다 작다는 성질만 만족하기 때문에 노드의 레벨 차이에도 불구하고 더 큰 수가 위 레벨에 존재하기도 한다. 부모 자식간의 관계만 정의할 뿐, 좌우에 대한 관계는 정의하지 않기 때문이다.
자식이 둘인 힙은 특별히 이진 힙이라고 하며, 대부분 이진 힙이 널리 사용된다. 이는 이진 트리가 널리 사용되는 이유와 비슷하다.
이진 힙의 배열 표현은 루트부터 차례대로 1, 2, 4, ... 순서대로 각 레벨의 노드가 2배씩 증가하는 형태로 배열에 나열할 수 있다. 완전 이진 트리 형태인 이진 힙은 배열에 빈틈 없이 배치가 가능하고, 대개 트리의 배열 표현의 경우 계산을 편하게 하기 위해 인덱스는 1부터 사용한다.
힙은 항상 균형을 유지하는 특성 때문에 다양한 분야에 널리 활용되는데 대표적으로 우선 순위 큐 뿐만 아니라 이를 이용한 다익스트라 알고리즘에도 활용된다. 힙의 사용으로 다익스트라 알고리즘의 시간 복잡도가 O(V^2)에서 O(E log V)로 줄어들게 되었다. 이외에도 원래의 용도인 힙 정렬과 최소 신장 트리를 구현하는 프림 알고리즘 등에도 활용되며, 중앙값의 근사값을 빠르게 구하는 데도 활용될 수 있다. 부모, 자식 간의 관계가 정의되어 있는 완전 이진 트리이기 때문에 적절히 중간 레벨의 노드를 추출하면 중앙값에 가까운 값을 정확하진 않지만 근사치로 빠르게 추출할 수 있기 때문에다.
힙 연산
삽입
힙에 요소를 삽입하기 위해서는 업힙 연산을 수행해야 한다. 일반적으로 업힙 연산은 precolate_up()이라는 함수로 정의된다. 힙에 요소를 삽입하는 과정은 다음과 같다.
- 요소를 가장 하위 레벨의 최대한 왼쪽으로 삽입한다. (배열로 표현할 경우 가장 마지막에 삽입한다.)
- 부모 값과 비교해 값이 더 작은 경우 위치를 변경한다.
- 계속해서 부모 값과 비교해 위치를 변경한다. (가장 작은 값일 경우 루트가지 올라간다.)
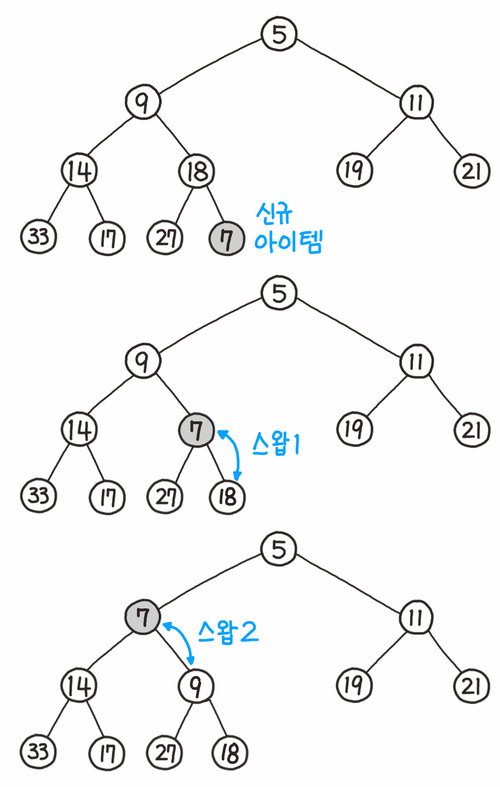
이 그림에서는 신규 아이템 7이 마지막에 삽입되어 부모 노드의 값과 비교하면서 점점 스왑되는 과정이 나타나 있다. 두 번째 스왑 이후에야 부모 노드인 5보다 더 크기 때문에 더 이상 스왑되지 않고 멈추는 것을 확인할 수 있다. 이 과정은 코드로 다음과 같이 나타낼 수 있다.
def _percolate_up(self):
i=len(self)
parent=i//2
while parent>0:
if self.items[i]<self.items[parent]:
self.items[parent], self.items[i]=self.items[i], self.items[parent]
i=parent
parent=i//2
def insert(self, k):
self.items.append(k)
self._percolate_up()삽입은 insert로 실행되고 insert()함수 내에서 append를 통해 가장 뒤에 값을 넣은 후에, percolate_up() 함수를 호출하여 스왑이 이뤄지도록 한다. 이 과정으로 인해 삽입의 시간 복잡도는 O(log n)이다.
추출
추출 자체는 간단하다. 루트를 추출하면 된다. 그러나 추출 이후에 다시 힙의 특성을 유지하는 작업이 필요하기 때문에 시간 복잡도는 O(1)이 아닌, O(log n)이 된다.
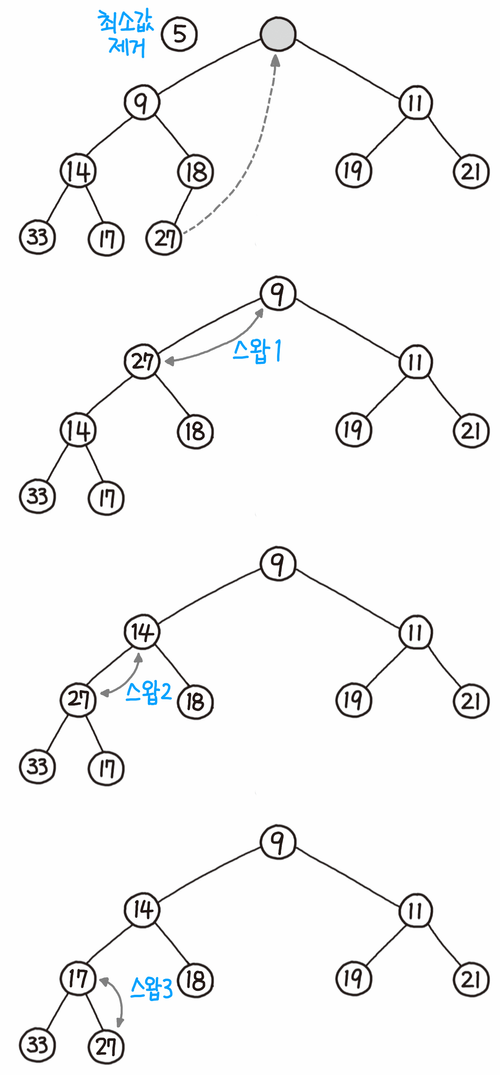
위의 그림에서는 이진 힙에서 요소의 추출 과정을 설명한다. 추출 이후에 비어 있는 루트에는 가장 마지막 요소가 올라가게 되고, 삽입과 반대로 자식 노드와 값을 비교하여 자식보다 크면 내려가는 다운힙 연산이 수행된다. 일반적으로 힙 추출에 많이 쓰이는 percolate_down()이라는 이름의 함수로 구현할 수 있다. 추출 과정의 수도코드는 다음과 같다.
Max-Heapify (A, i):
left<-2*i
right<-2*i+1
largest<-i
if left<=heap_length[A] and A[left] > A[largest] then:
largest<-left
if right<=heap_length[A] and A[right] > A[largest] then:
largest<-right
if largest!=i then:
swap A[i] and A[largest]
Max-Heapify(A, largest)이 수도코드에서는 인덱스가 1 이상일 때만 동작하도록 구현되어 있다. 앞서 1번 인덱스부터 사용한다고 언급한 바가 있고, 이후 코드에서도 0번 인덱스는 None을 할당하여 사용하지 않았다.
0번 인덱스는 항상 비워두고, 1번 인덱스부터 사용하는 이유는 인덱스 계산을 편하게 하기 위함이다. 1번 인덱스부터 사용하게 되면 인덱스 계산이 갈끔하게 떨어진다. 1번 인덱스부터 사용하게 되면 부모 노드는 2로 나눈 올림값으로 정리되고, 왼쪽은 i*2로, 오른쪽은 i*2+1로 깔끔하게 계산이 처리된다.
수도코드를 최소 힙으로 적절히 변형하여 파이썬으로 구현하면 다음과 같이 구현할 수 있다.
def _percolate_down(self, idx):
left=idx*2
right=idx*2+1
smallest=idx
if left<=len(self) and self.items[left]<self.items[smallest]:
smallest=left
if right<=len(self) and self.items[right]<self.items[smallest]:
smallest=right
if smallest!=idx:
self.items[idx], self.items[smallest]=self.items[smallest], self.items[idx]
self._percolate_down(smallest)
def extract(self):
extraced=self.items[i]
self.items[1]=self.items[len(self)]
self.items.pop()
self.percolate_down(1)
return extracted추출은 extract() 함수를 호출해 실행되고 이후 루트 값이 추출되고 percolate_down()이 실행된다. 왼쪽 자식과 오른쪽 자식을 비교하고 더 작다면 해당 인덱스로 교체된다. 인덱스가 교체되었다면 서로 값을 스왑하고 다시 재귀 호출한다. 값이 스왑되지 않을 때까지 계속 자식 노드로 내려가면서 스왑된다.
이진 힙의 연산의 전체 코드는 다음과 같다.
class BinaryHeap(object):
def __init__(self):
self.items=[None]
def __len__(self):
self.len(self.items)-1
def _percolate_up(self):
i=len(self)
parent=i//2
while parent>0:
if self.items[i]<self.items[parent]:
self.items[parent], self.items[i]=self.items[i], self.items[parent]
i=parent
parent=i//2
def insert(self, k):
self.items.append(k)
self._percolate_up()
def _percolate_down(self, idx):
left=idx*2
right=idx*2+1
smallest=idx
if left<=len(self) and self.items[left]<self.items[smallest]:
smallest=left
if right<=len(self) and self.items[right]<self.items[smallest]:
smallest=right
if smallest!=idx:
self.items[idx], self.items[smallest]=self.items[smallest], self.items[idx]
self._percolate_down(smallest)
def extract(self):
extraced=self.items[i]
self.items[1]=self.items[len(self)]
self.items.pop()
self.percolate_down(1)
return extracted이진 힙 vs 이진 탐색 트리
이진 힙과 이진 탐색 트리의 차이점은 무엇일까? 비슷해보이지만 차이점이 존재하고 혼동되기도 쉽다.
가장 직관적인 차이점은 힙은 상/하 관계를 보장하며, 특히 최소 힙에서는 부모가 항상 자식보다 작다. 반면 이진 탐색 트리는 좌/우 관계를 보장한다. 부모는 왼쪽 자식보다는 크며, 오른쪽 자식보다는 작거나 같다.
이 특징으로 인해 이진 탐색 트리는 탐색과 삽입이 모두 O(log n)에 가능하며, 모든 값이 정렬되어야 할 때 사용한다. 반면 가장 큰 값을 추출하거나 가장 작은 값을 추출하려면 이진 힙을 사용해야 한다. 이진 힙은 이 작업이 O(1)에 가능하다. 우선순위와 연관되어 있으며 따라서 이진 힙은 우선순위 큐에 활용된다.
LeetCode 215.Kth Largest Element in an Array
정렬되지 않은 배열에서 k번째 큰 요소를 추출하라.
우선 혼자서 풀어보았다. 힙에 주어진 nums의 요소들에 -를 붙여 넣어 최대 힙을 구현하였고 주어진 k번 추출하여 마지막에 추출한 값을 반환하도록 작성하였다.
import heapq
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
q=[]
answer=[]
for i in range(len(nums)):
heapq.heappush(q, -nums[i])
for _ in range(k):
tmp=heapq.heappop(q)
answer.append(tmp)
return -answer[-1]
Solution 1 heapq 모듈 이용
전에 풀었던 상위 K 빈도 요소와 비슷한 문제로 다른 점은 가장 큰 값과 가장 빈번한 값에서 있다. 값을 힙에 푸시하고 순서만큼 팝하는 형태로 작성하면 다음과 같이 작성 가능하다.
import heapq
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
heap=list()
for n in nums:
heapq.heappush(heap, -n)
for _ in range(1, k):
heapq.heappop(heap)
return -heapq.heappop(heap)
Solution 2 heapq 모듈의 heapify 이용
모든 값을 꺼내서 푸시하지 않고도 한번에 heapify()하여 처리할 수 있다. heapify()란 주어진 자료구조가 힙 특성을 만족하도록 바꿔주는 연산이며, 이 경우 파이썬의 일반적인 리스트는 힙 특성을 만족하는 리스트로 값의 위치가 변경된다.
import heapq
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
heapq.heapify(nums)
for _ in range(len(nums)-k):
heapq.heappop(nums)
return heapq.heappop(nums)
Solution 3 heapq 모듈의 nlargest 이용
heapq 모듈은 강력한 기능을 많이 지원한다. 그중에는 n번째 큰 값을 추출하는 기능도 있다. 이 기능을 사용하면 전체 코드를 다음과 같이 한 줄로 처리할 수 있다.
import heapq
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
return heapq.nlargest(k, nums)[-1]
k번째만큼 큰 값이 가장 큰 값부터 순서대로 리스트로 리턴된다. 여기서 마지막 인덱스 -1이 k번째 값이 된다. 힙이 아니더라도 내부적으로 heapify() 함수도 호출해 처리해주기 때문에 별도로 힙 처리를 할 필요가 없어 편리하다. nsmallest() 함수를 사용하면 동일한 방식으로 n번째 작은 값도 추출 가능하다.
Solution 4 정렬을 이용한 풀이
이번에는 정렬부터 한 다음 k번째 값을 추출하는 방식으로 풀이해본다. 추가, 삭제가 빈번할 때는 heapq를 이용한 힙 정렬이 유용하지만 이처럼 입력값이 고정되어 있을 때는 한번 정렬하는 것만으로 충분하다.
import heapq
class Solution:
def findKthLargest(self, nums: List[int], k: int) -> int:
return sorted(nums, reverse=True)[k-1]
모든 방식은 실행 속도에 큰 차이가 없으나 정렬 방식이 가장 빠르다. 파이썬의 정렬 함수는 팀소트를 사용하며 C로 매우 정교하게 구현되어 있기 때문에 대부분의 경우에는 파이썬의 내부 정렬 함수를 사용하는 편이 가장 성능이 좋다.
