AWS S3

AWS의 S3는 AWS Simple Storage Service의 약자로 안전하고 가변적인 Object 저장 공간을 제공한다. 공식 문서에서는 웹서비스 인터페이스를 사용하여 데이터를 저장, 검색할 수 있다고 설명되어 있다.
S3는 파일 저장소이다. 로그파일, 이미지, 비디오, 압축파일 등을 업로드할 수 있다. 또한 HTML, CSS, JS 파일을 업로드하여 웹사이트 호스팅도 할 수 있다.
S3의 구조
S3는 Bucket과 Object라는 단위로 구성된다.
- Object
Key, Value, Version ID, Metadata, CORS(Cross Origin Resource Sharing)와 같은 다양한 구성요소로 구성된 저장 단위이다.
-> Key: 파일명
-> Value: 파일에 대한 데이터
-> Version ID: 같은 파일의 다른 버전을 업로드할 수 있도록 돕는 인식표
-> Metadata: 업로드 날짜, 파일의 Owner 등의 자동 생성 데이터
-> CORS: 하나의 Bucket의 파일에 다른 Bucket이 접근 가능하도록 해주는 기능 - Bucket
Object를 저장하고 관리한다. Bucket을 생성하면 Owner권한을 부여받으며 Bucket 단위로 여러가지 기능들을 제어할 수 있다.
S3 일관성 모델
다음은 AWS S3의 데이터 일관성 모델의 특징을 그대로 인용한 것이다.
"Amazon S3은 모든 리전의 S3 버킷에 있는 새 객체의 PUT에 대해 한 가지 주의 사항을 제시함으로써 읽기 후 쓰기 일관성을 제공합니다. 주의할 점은 객체를 만들기 전에 (객체가 있는지 찾기 위해) 키 이름에 HEAD 또는 GET 요청을 하는 경우 Amazon S3가 읽기 후 쓰기에 대한 최종 일관성을 제공하는 것입니다.
Amazon S3은 모든 리전의 덮어쓰기 PUT 및 DELETE에 대한 최종 일관성을 제공합니다."기존의 RDS는 동시성을 가진다. 동시성이란 같은 시간에 조회하는 데이터는 항상 동일한 데이터임을 보증하는 것을 기본으로 하는 것을 말한다. 그러나 분산 노드를 사용하여 빅데이터에 대한 빠른 데이터 처리가 주 목적인 NoSQL을 사용할 경우에는 동시성을 보장하기 힘들어진다.
최종 일관성은 데이터 변경이 발생했을 때에 점차적으로 여러 노드에 전파되어 즉각적인 일관성은 아니지만 최종적으로는 일관성이 유지되는 것을 말한다. 위에서 인용한 S3의 특징은 동시성은 제공하지 않지만 결과적으로 일관성을 갖게 된다는 것을 설명하고 있는 것이다.
이는 객체를 처음 생성한 후 가져올 경우에는 일관성을 제공하지만 삭제 후 객체를 가져올 경우에는 일관성 없는 결과를 반환할 수도 있다는 것이다.
S3 스토리지
S3는 단순한 하드디스크의 개념을 넘어 다채로운 유형이 존재한다. S3 스토리지를 선택할 때는 용도와 목적에 따라 적합한 스토리지가 사용되어야 한다.
- 일반 S3
- S3 - IA
- S3 - One Zone IA
- Glacier
- Intelligent Tiering
일반 S3
높은 내구성과 가용성을 자랑하는 스토리지로 가장 무난하게 사용되는 스토리지이다. 내구성은 데이터의 손실 없이 복원되는 정도이고, 가용성은 데이터 접근의 용이성에 대한 정도이다.
S3 - IA (Infrequent Access)
만약 특정 파일에 자주 접근할 이유가 없지만 이 파일에 접근해야 할 경우 빠르게 접근해야 하는 경우에 사용된다. 일반 S3에 비해 비용은 저렴하지만 데이터에 접근할 때에 추가 비용이 발생한다. 멀티 AZ의 도움으로 인해 가용성이 높다.
S3 - One Zone IA
하나의 AZ에만 의존하기 때문에 데이터 접근에 많은 제한이 생길 수 있다. 만약 하나의 AZ 서버에 문제가 생기면 그 AZ는 사용이 불가능해지고 One Zone 스토리지 또한 사용할 수 없다. 서버의 문제가 해결되면 접근이 가능해진다. 이 특징 때문에 가용성이 조금 떨어진다. 가격은 IA보다 저렴하다.
Glacier
빙하라는 뜻을 가지고 있으며 데이터 접근이 거의 필요 없을 경우 적합하다. 데이터를 단순 저장만 해두는 용도로 사용하기 때문에 비용이 저렴하다. 하지만 데이터에 접근하기 위해서는 4~5시간 정도가 소요된다.
Intelligent Tiering
데이터의 접근 주기를 분석하여 Frequenct Tier 또는 Infrequent Tier 중 하나로 선택된다. 데이터 접근이 한달 이상 없을 경우 Infrequent Tier로 분류하고, 데이터 접근이 몇 번 발생하면 Frequent Tier로 분류한다. 당연히 Frequent Tier가 더 비싸다.
Bucket 접근 권한
S3의 Bucket을 생성하면 Bucket을 생성한 Owner만 접근할 수 있다. 외부에서 이 Bucket에 접근을 시도할 경우 Access Denied 에러가 발생한다. 특정 유저나 특정 그룹에게만 Bucket 접근 권한을 부여하고 싶다면 다음과 같은 방법으로 부여할 수 있다.
- 버킷 정책 변경
버킷 정책을 변경하면 버킷 안에 있는 모든 파일에 변경 사항이 적용된다. 버킷 정책을 퍼블릭으로 변경하면 외부에서 해당 버킷의 모든 파일에 접근할 수 있게 된다. - 접근 제어 리스트 변경
모든 파일에 변경 사항이 적용되는 버킷 정책 변경과는 달리 각각의 파일에 다른 접근 권한을 부여할 수 있다.
Use
본인은 학교에서 주관한 공모전에서 작품을 만들 때 S3를 사용했다. 사용자들이 업로드하는 이미지들을 저장하는 용도로 S3를 사용하였다.
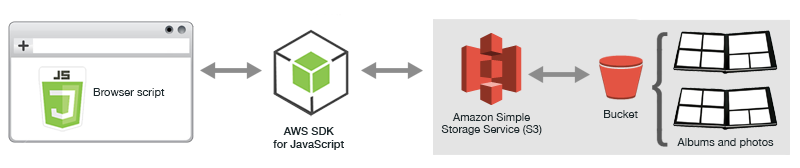
브라우저 자바 스크립트가 JavaScript SDK를 사용하여 AWS S3 버킷과 상호작용함으로써 이미지를 저장하고 불러오는 방식이다.
src 폴더 안의 config 폴더에 multer.js라는 파일을 다음과 같이 작성하여 s3를 사용하였다.
const multer = require('multer');
const multerS3 = require('multer-s3');
const aws = require('aws-sdk');
const s3 = new aws.S3({
accessKeyId: process.env.S3_ACCESS_KEY,
secretAccessKey: process.env.S3_PRIVATE_KEY,
region: process.env.REGION,
});
const upload = multer({
storage: multerS3({
s3: s3,
bucket: process.env.BUCKET_NAME,
contentType: multerS3.AUTO_CONTENT_TYPE,
acl: 'public-read',
key: (req, file, cb) => {
cb(null, `${Date.now()}_${file.originalname}`);
},
}),
limits: { fileSize: 1000 * 1000 * 10 },
});
module.exports = upload;Key value와 같은 민감한 데이터의 경우 .env파일을 통해 관리하였고 위의 코드에서도 .env파일에 접근하여 Key value를 사용하는 것을 볼 수 있다.
