Abstract
당시 3D object detection 연구 하고있었으나 multimodal에 대한 연구는 거의 없었다. 혹은 있더라도 복잡한 파이프라인을 지녔거나 late fusion을 수행하여서 early fusion 방식은 없었다. 이를 위해 당시 최근에 소개된 VoxelNet 을 활용하여 RGB 와 포인트 클라우드를 fusion 하는 PointFusion 과 Voxel Fusion을 제안
KITTI 데이터셋을 사용하여 벤치마크 6개중 3개의 버드아이뷰와 3D detection에서 2등을 달성함
INTRODUCTION
3D센서의 등장과 다양한 프로그램에의해 detection, segemtation 등에 대한 연구가 증가되고있다.
이 논문에서는 여러 모달리티(LiDAR, camera 등) 을 fusion하여 감지성능을 향상시키는것이 목표!
기존 2D detect는 CNN으로 성능이 잘나왔으나 3D에서는 입력이 다르기에 적용할 수없다. 기존엔 point cloud를 depth, BEV로 수작업으로 변환한뒤 2D CNN에 적용하였으나 적은 포인트들과 기하학적문제로인한 양자화 문제를 발생시킴.
다른 기술법으론 3D point cloud를 voxel grid로 나타내고 3D CNN을 사용하여 결과를 도출하나 이는 전체 장면을 처리할때 메모리 요구사항에 제한을 받는다.
최근 연구는 point cloud를 직접사용하는 end to end 방식의 학습이 가능한 신경망에 중점.
Point net을 사용하려 했으나 높은 계산량과 메모리비용으로 문제해결이 불가능 => 이를 극복한것이 voxel net이다.
VoxelNet은 pointcloud의 복셀화와 VFE(Voxel Feature Encoding)을 stack한것을 포함한 방식 하지만 이또한 point cloud 에만 의존한다.
RGB 이미지는 밀도가 높은 텍스쳐 정보를 제공하기에 두 모달리티를 모두 활용하는것이 바람직하다.
그렇기에 본 논문에서는 Multimodal VoxelNet( MVX Net ) 을 제안한다.
LiDAR 포인트에 semantic 이미지 특정을을 추가하고 정확한 3D oject Detection을 위해 image 와 LiDAR feature를 ealry fusion 한것을 학습하도록 한다.
VoxelNet 알고리즘을 확장한 방식으로 2가지를 제안함
-
PointFusion : point 들을 이미지에 투영한다음, pre-trained 된 2D detector로 부터 image feature extraction하는 방법, 이후 image feature 와 상응하는 포인드들의 연결은 Voxel Net에서 이루어진다.
-
VoxelFusion : VoxelNet에 의해 생성 된 비어 있지 않은 3D 복셀을 이미지로 투영 한 다음 pretrained 된 CNN을 사용하여 image feature을 진행하는 방법
이 feature들은 모든 복셀에 VFE feature 인코딩에 추가되어 3D RPN에서 3D boudingbox를 생성하는데 사용된다.
1 vs 2
VoxelFusion pointfusion에비해 later fustion tech지만 빈 복셀을 처리할수있어 라이다의 pointcloud에 대한 의존성을 낮출수있다.
실제로 성능향상에 의미가있었음
RELATED WORK
여러 다른 논문들의 방법론을 제시 해줌
본 논문과는 연관없는 거같아 생략
결론 : 기존 방법든은 다른 모달리티들을 처리하기위해 복잡한 파이프라인을 사용하거나 late fusion을 사용하는 반면 본 논문의 방식은 간단하면서도 효과적인 모달리티간 상호작용을 early fusion으로 학습할수있다!
PROPOSED METHOD
1. 2D Detection Network
2. Voxel Net
-
원시 포인트클라우드를 그대로 사용
-
3D 공간에서의 다양한 단위? 세분성을 자연스럽고 효과적인 인터페이스를 제공 -> 점, 복셀
Voxel Net의 구조를 그대로 인용해온다.
Voxel Net은- VFE(Voxel feature encoding)layer
- Convolutional Middle layers
- 3D region proposal network 의 특징을 가짐.
3. Multimodal Fusion
Voxel Net Framework를 확장하여 RGB데이터를 point cloud 데이터와 퓨전하기위해 2개지 간단한 기술을 제안한다.
1). Point fusion:
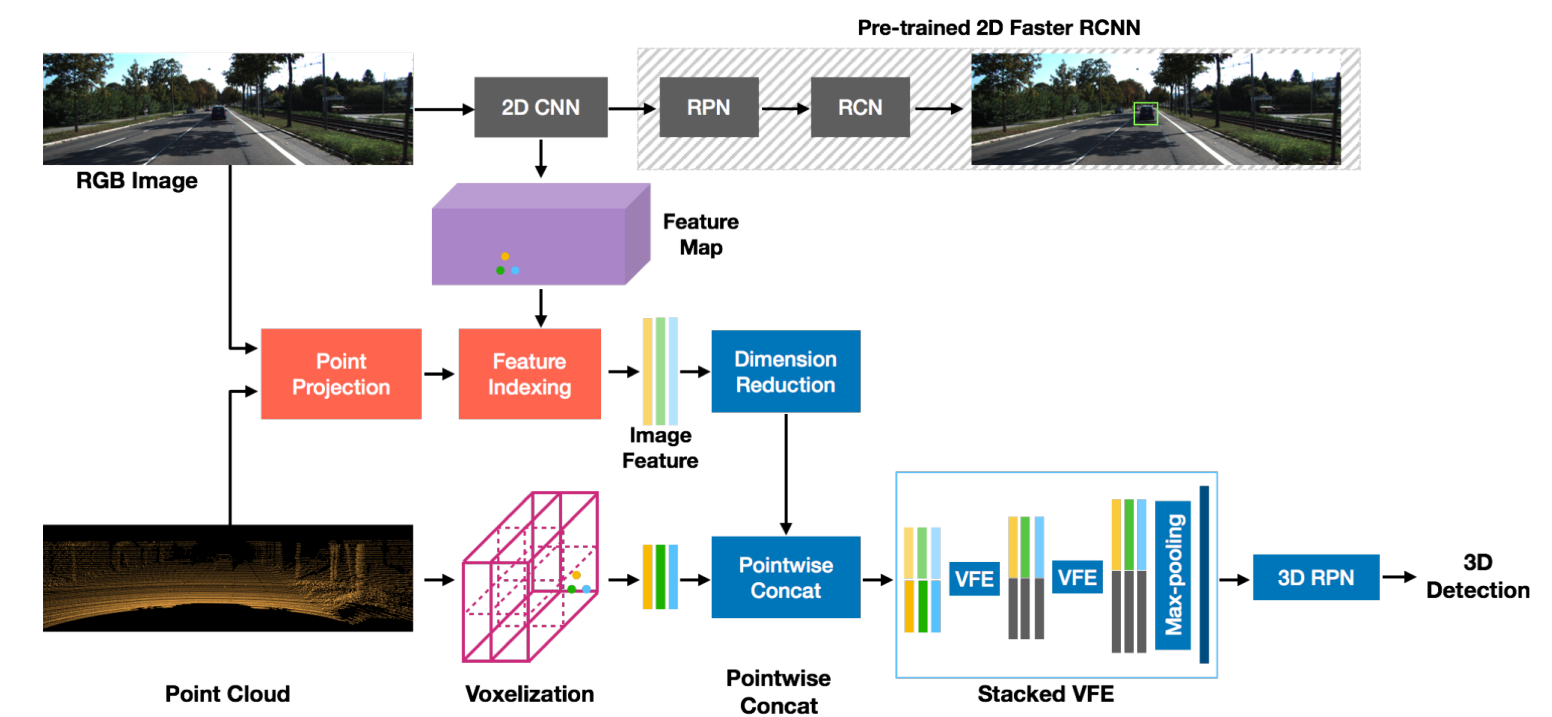
모든 3D 포인트가 이미지 특징에 의해 집계되어 밀도 있는 컨텍스트를 캡처하는 초기 퓨전 기술입니다.(?) 2D detection 네트워크를 사용하여 이미지로부터 high level feature map을 추출하여 이미지 기반 의미론을 인코딩함. 그 후 보정행렬(calibration matrix)를 사용하여 3D point를 이미지에 투영하ㅇ고 해당 투영 위치 인덱스에 해당하는 특징과 함깨 포인트를 추가한다.
즉 2D 이미지에서오부터의 물체의 위치와 존재여부를 모두 3D 포인트와 연관시킨다.
VGG16의 conv5에서 추출되어 512차원이고. 차원감소를 진행시켜 FCN으로 16차원으로 줄이고 이를 point feature와 concat함.
이런 과정은 VFE layer에서 진행되고 detection 단계에서 사용된다.
장점:
매우 초기단계에서 fusion이 발생하기때문에 VFE layer에서 양쪽 모달리티의 유용한 정보를 잘 요약할수있도록 학습할수있다.
이는 LiDAR 포인트 클라우드를 활용하며 해당 이미지 특징을 3D 포인트의 좌표로 변환한다.
2 Voxel Fusion
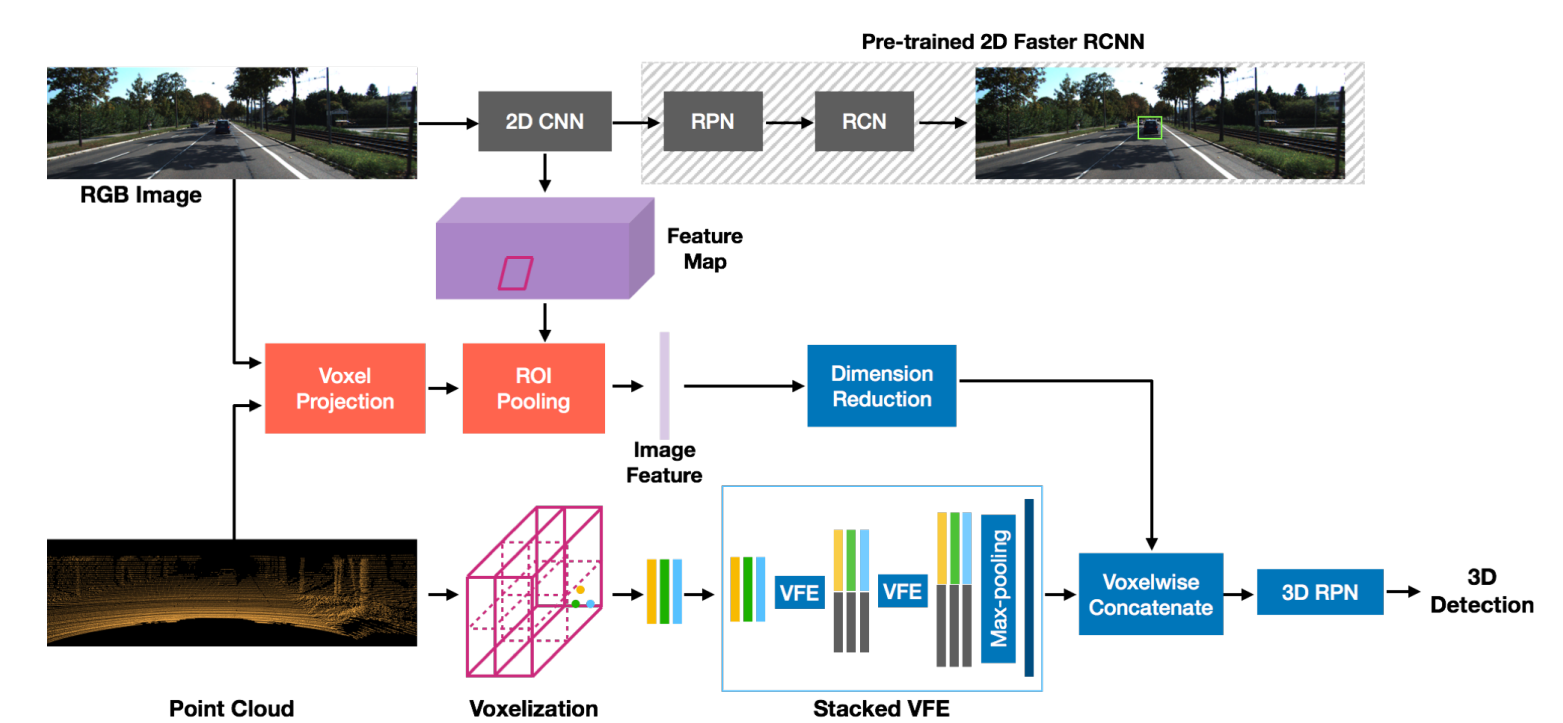
Point Fusion 대비 상대적으로 늦은 퓨전을 사용(그래도 일반적인 ealry fusion 임)
모든 비어있지 않은 복셀이 이미지평면으로 투영되어 2D ROI를 생성. pretrained VGG16에서 가져온 feature map을 사용하여 ROIㄴ의 특징을 풀링하여 512차원의 feature를 생성하고. 차원을 64로 감소한뒤 모든 복셀에서 stack한 VFE layer에 의해 생성된 특징 벡터를 추가한다. 이러한 과정은 각 복셀에서 2D 이미지로 부터 이전 정보를 인코딩 한다.
장점 :
낮은 LiDAR 해상도나 먼 물체 등의 이유로 LiDAR 포인트가 샘플링되지 않는 빈 복셀에 영상 정보를 집계하기 쉽게 확장할 수 있어 고해상도 LiDAR 포인트의 가용성에 대한 의존성을 줄일 수 있습니다.
VoxelFusion은 PointFusion에 비해 메모리 소모량 측면에서 더 효율적입니다
단점 :
pointfusion에 비해 약간의 성능이 낮음
Training Details
Multimodal VoxelNet
VoxelNet 설정을 유지하지만 몇가지 단순화 진행 (효율성 향상을 위해)
두 세트의 VFE layer 와 3개의 CNN 중간 layer를 사용 , 입력 출력 의 차원은 퓨전 방식에 따라 달라짐
-
point fusion은 VFE stack이 VFE-1(7+16,32) and VFE-2(32,128) 로 구성
VFE-1 의 입려은 7차원의 point feature 와 16차원의 CNN feature의 concat
사전 훈련된 2D detect 의 conv5에서 추출된 차원은 512인데 이를 FCN을 사용하여 96으로 줄이고 BN, ReLU로 16차원 까지 줄임 -
voxel fusion은 VFE stack이 VFE-1(7,32) and VFE-2(32,64)로 구성
사전 훈련된 2D detect 의 conv5에서 추출된 차원은 512인데 이를 FCN을 사용하여 128, 64로 줄이고 BN, ReLU 을 추가해줌. 이는 VFE02에서 생성된 벡터에 연결되어 128벡터를 형성한뒤 이를 64로 줄이면
CNN 중간층이 변형되지않고 구조가 유지됨을 보장한다.
- 메모리 footprint(차지공간)을 줄이위해 Resnet블록수의 절반만 사용하여 RPN을 다듬는다.
기존 voxelnet과 같이 같은 앵커매칭 전략을 사용한다.
둘다 초기 lr 0.01로 시작하여 150에폭동안 훈련, 훈련 종료시점에선 10배 감소=> 0.001 이겟죠?
또한 멀티모달리티이기에 기존에 제안된 point cloud rotation 방식은 적용하지 않음 (데이터 증강 X)
그럼에도 LiDAR만 사용한 Voxel net 보다 성능이 우수했음
IV. EXPERIMENTS AND RESULTS
KITTI dataset 사용
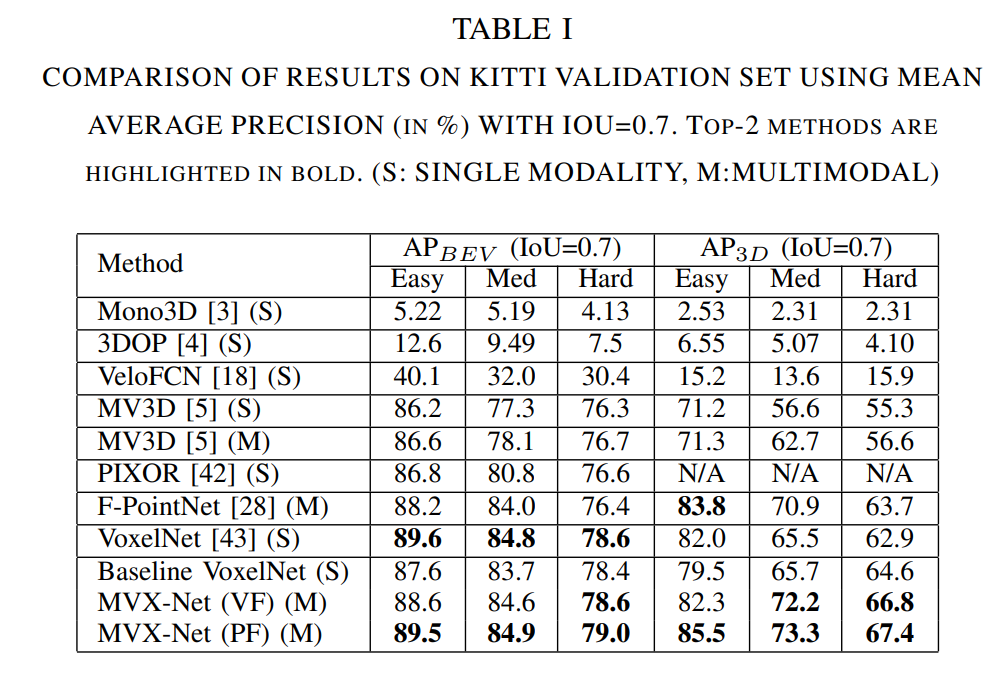
기존 VoxelNet 보다 성능이 크게 향상됨을 보임.
Voxelfusion은 pointfusion에비해 약간 성능이 떨어져보이는것으로 보임. -> pointfusion은 보다 빠르게 퓨전하기 떄문으로 추측.
Point fusion은 LiDAR 중심이지만 VoxelFusion은 독립적으로 두 모달리티를 다 이용할 수있다.
VoxelFusion은 빈복셀에서도 이미지를 투영할수있다. 이미지기반 전략이기에 포인트가 없어도 이미지 정보를 사용할수있고, 해상도가 낮은 원거리 탐지에도 도움이 될수있다.
추가로 ablation study를 진행
원본이미지의 패치를 크롭하고 3D 포인터를 추가하여 2DCNN 특징을 대체하는것으로 연구진행
이미치 패치 크기를 3x3, 5x5를 테스트 하여 r기존보다 0.5~1.0 % 증가됨을 확인
하지만 이미지CNN을 통한 high level feature를 사용하는 것만 큼은 좋지않았다.
KITTI Test set

6개의 BEV, 3d 검출에서 우수한 성능을 도출
느낀점
- 사실상 그냥 voxel net 리뷰 인 느낌
- Fusion 전략이 언급해있지만 그렇게 구체적이지 않는거같다.
- 그래서 pointfusion을 쓴다는건지 voxelfusion을 쓴다는건지 둘다 쓴다는건지는 코드를 뜯어봐야될듯하다.
- 왜 아무도 리뷰가 없는지 알거같은 논문? 이였다 ㅎㅎ
