AI & 기계학습 기초
- 데이터 구성요소
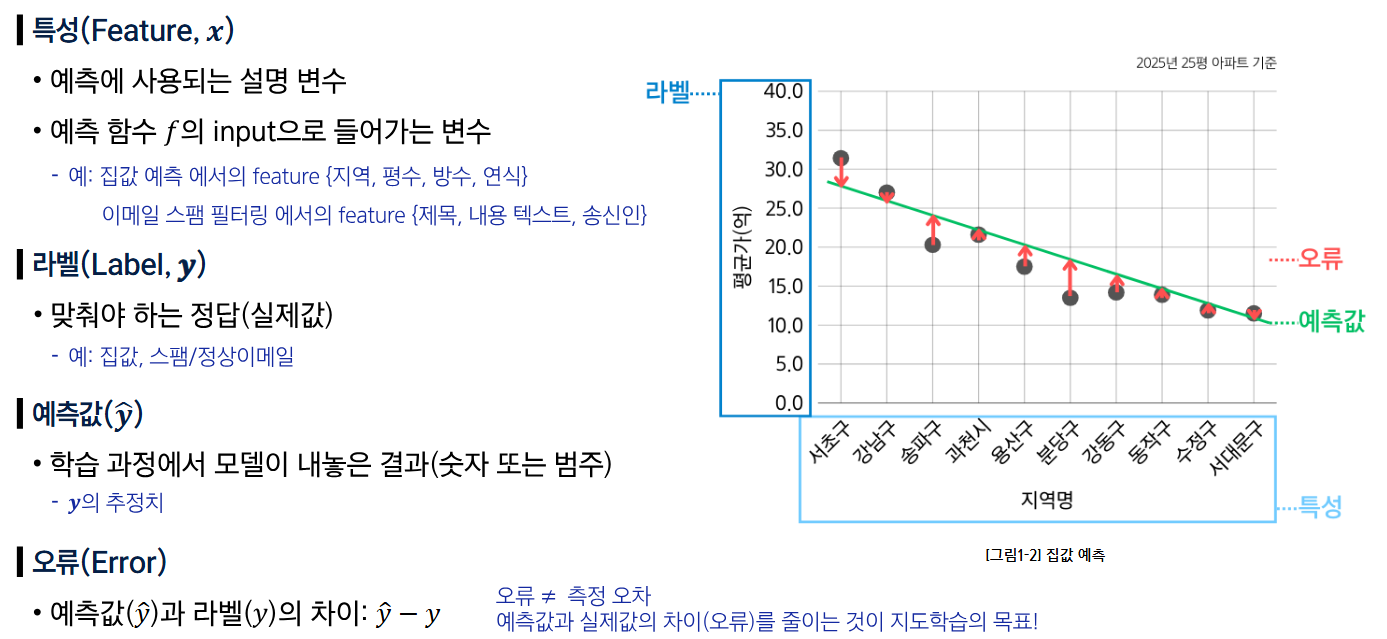
- Feature (특성/입력값) : 모델이 학습하기 위해 참고하는 '정보' 또는 '원인'이 되는 변수들
- ex. 메일 제목, 보낸 사람, 본문 단어 - Label (라벨, 출력값, 타겟) : 모델이 맞춰야 하는 '정답' 또는 결과가 되는 '목표' 변수
- ex. '스팸' 또는 '정상'이라는 결과
단일 피쳐 기반 학습
-
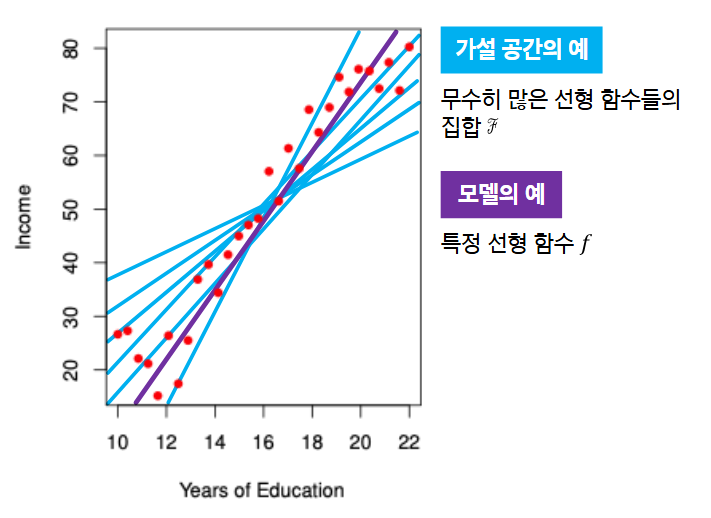
1D 피쳐 기반 학습 (단일 피쳐 학습) : Feature가 하나일 때 머신러닝이 학습하는 형태

- 모델과 가설 공간
- 학습 (Learning) : 입력 -> 출력 관계를 찾는 과정
- 평균 관계를 하나의 함수로 표현하는데, 관계를 표한하는 함수는 무수히 많음
- 가설 공간 : 관계를 표현할 수 있는 모든 후보 함수들의 모음
- 피쳐 공간과 라벨 공간 위에서 정의된 함수들의 집합
- 모델 : 가설 공간에 속한 특정 함수
- 학습에 필요한 데이터 3가지
- 데이터 : **입력(feature)와 정답(label)의 쌍으로 구성
- 가설 공간
- 선택 기준 (손실 함수) : 어떤 함수가 더 좋은지 판단하는 척도. 예측값과 실제값의 차이를 측정
- 모델 학습의 ㅍ필요성
- 예측 : 새로운 입력값에 대해 label 추론
- 중요 특성 파악 : 어떤 Feature가 결과에 중요한지 확인
- 해석 가능성 : 각 Feature가 결과에 어떤 영향을 미치는지 이해
복수 피쳐 기반 학습
2D 피쳐 기반 학습
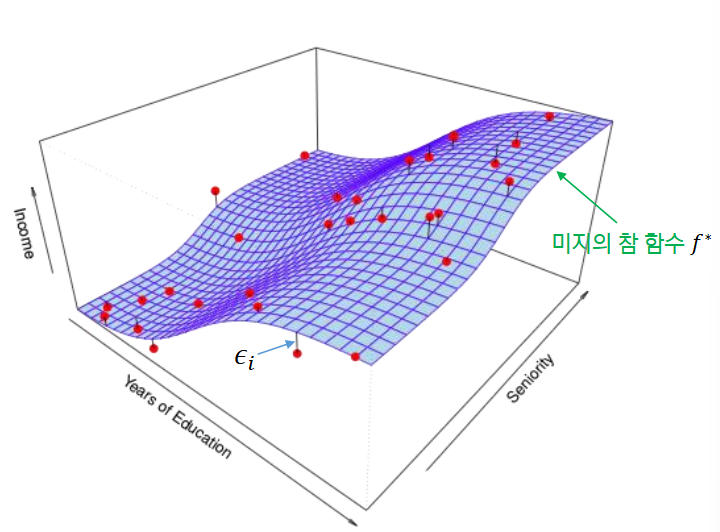
-
파란색 Surface (미지의 참 함수f)는 관측 불가능!
- 선형함수 가설공간과 비선형함수 가설공간으로 나뉨

- 측정오차 : 는 피쳐 와 독립 및 로 가정함
- 데이터를 수집할 때 발생하는 어쩔 수 없는 잡음(Noise)
지도학습은 무엇인가
지도학습 : 처음 보는 문제도 잘 푸는 AI 만들기
- 입력 + 정답을 가지고 예측 규칙을 배우는 방법
- 입력(feature)과 정답(label)이 항상 쌍으로 존재!!
- 훈련 데이터 뿐 아니라, 처음 보는 데이터에서도 예측 성능 향상!
- 지도학습의 종류
- 회귀(Regression) : 예측하고 싶은 결과값이 '숫자'일때
- 분류(Classification) : 예측하고 싶은 결과값이 '범주' 일 때
회귀 문제
입력으로부터 숫자를 얼마나 정확히 예측할까?
- 특징 : 라벨 및 예측 모델의 출력은 연속적인 수치
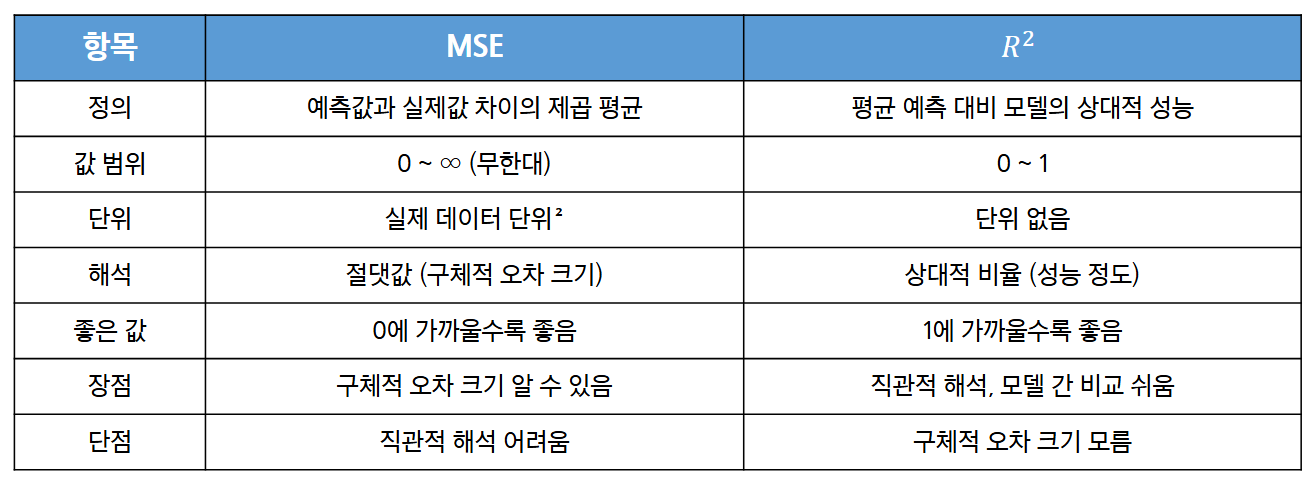
모델의 정확도를 평가하기 위한 정량 지표 두가지
- 회귀 오류 측정 - MSE(평균제곱오차)
- 각 데이터에서 정답과 예측의 평균 제곱 차이값
- 틀린 정도를 제곱해서 더 큰 오류에 패널티 부여!
- R^2 (결정계수)
- 회귀 모델이 얼마나 일을 잘했는지 측정하는 계수
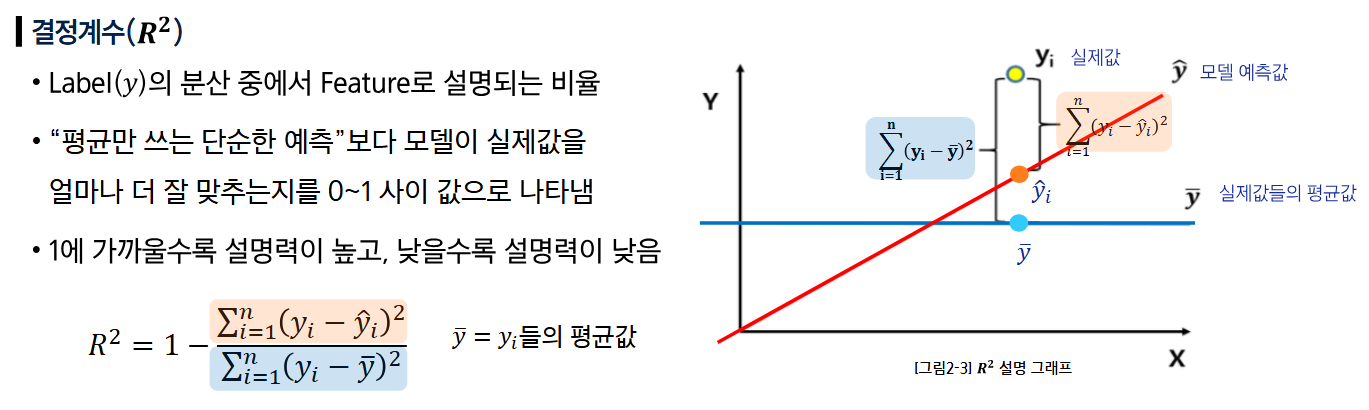
- 0에 가까우면: 모델이 그냥 평균치만 말하는 수준
- 1에 가까우면: 모델이 실제 데이터의 변화를 거의 완벽하게 설명함
평균적으로 1000만원 정도 실제값과 차이가 있다 (MSE) vs 모델이 데이터 변동의 80%를 설명한다 (R^2)
- 이런 느낌으로 두 성능 지표를 비교할 수 있다!
- MSE : 구체적인 오차 크기가 중요할 때 / 실제 손실 비용을 계산할 때
- R^2 : 여러 모델을 비교할 때 / 모델 성능을 직관적으로 평가할 때 / 모델이 전반적으로 얼마나 좋은지 알고 싶을 때
분류
- 입력특성으로부터 출력이 범주값으로 나타나는 예측 문제
- 범주라벨 (이진/다중)
분류 정확도
- Accuracy = 올바르게 맞춘 개수 / 전체 예측 개수
- 한계 : 불균형 데이터 (양성 1%, 음성 99%) : 전부 음성이라 해도 정확도 99%처럼 보임
- 혼동 행렬 (Confusion Matrix)
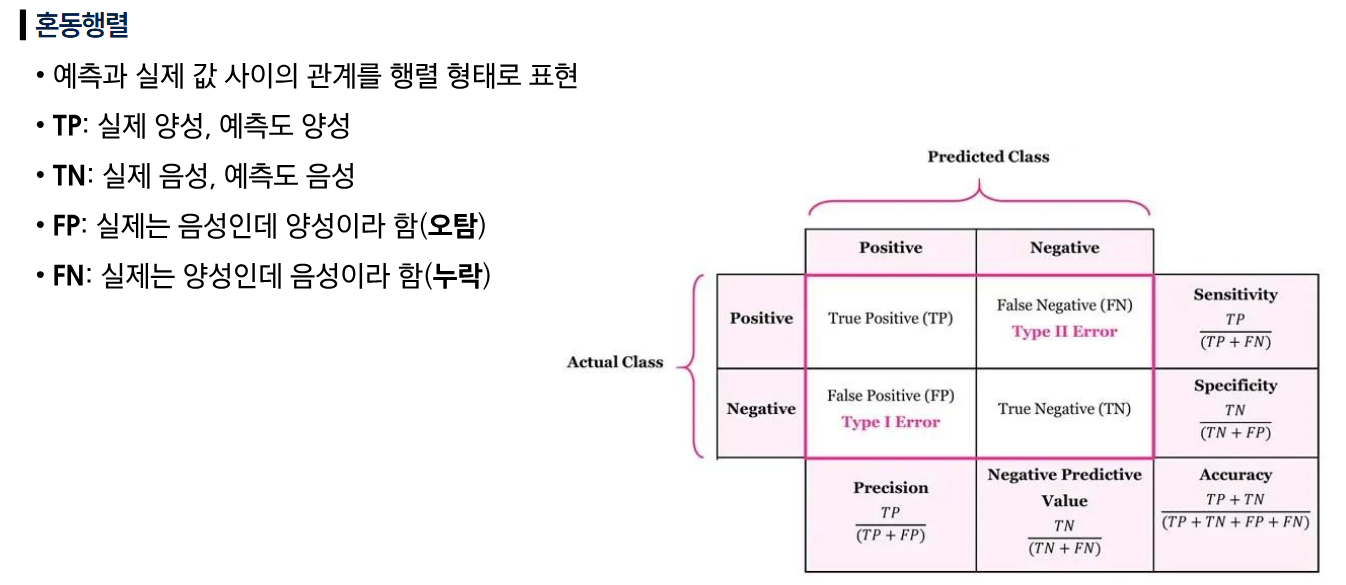
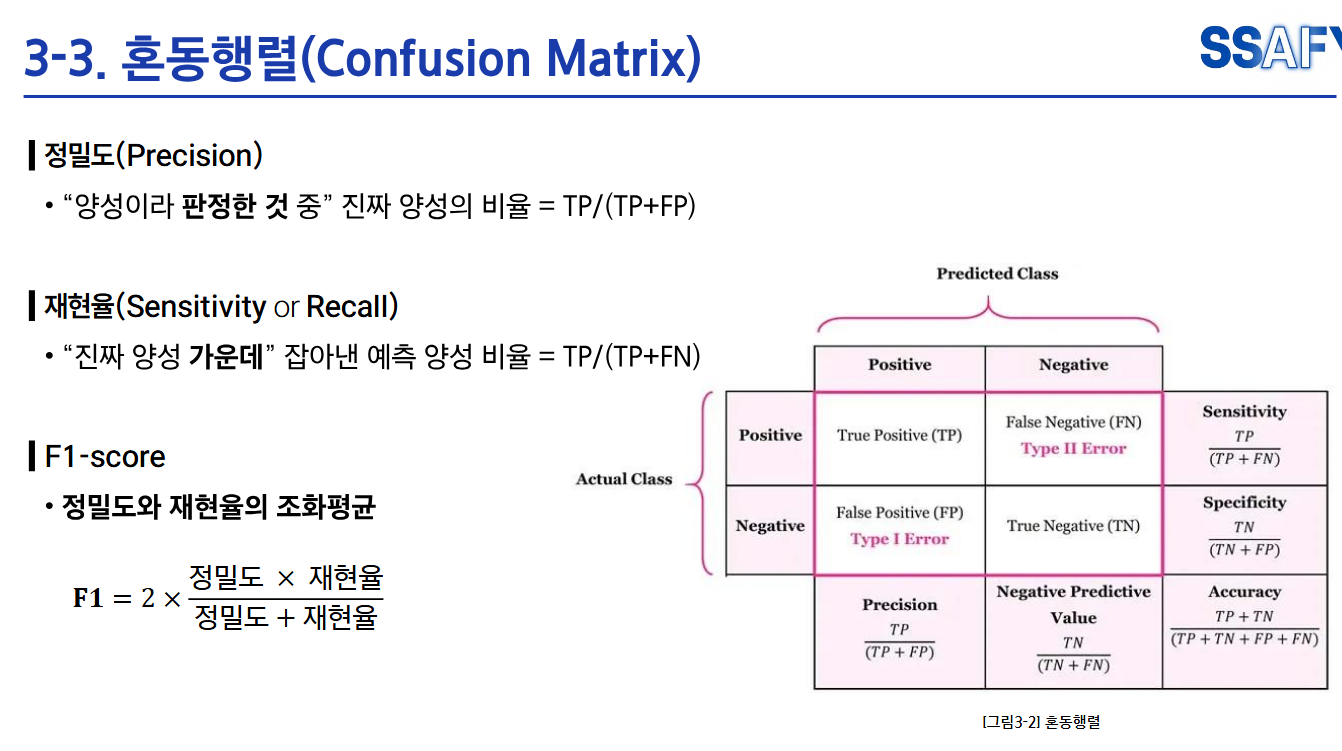
- F1-score : 정밀도와 재현율의 조화평균
- 산술평균이 아닌 조화평균 쓰는 이유 : 어느 한쪽이라도 점수가 매우 낮으면 전체 점수가 낮게 나오도록 하기 위해서
학습의 목적
학습의 목적은 훈련 데이터로 학습한 모델이 새로운 데이터에서도 정확한 예측을 수행하도록 하는 것!!
Overfitting
- 훈련 데이터의 우연한 패턴/잡음까지 외워버린 바람에 훈련에서는 잘 맞지만 테스트에서는 성능이 나빠지는 현상
- 현상 : 훈련 오류 낮음, 테스트 오류 높음/요동
- 문제 : 표본 의존->불안정 (과하게 맞추어 학습하면 샘플 몇개만 바뀌어도 예측 크게 흔들림) / 일반화 실패
- 오버피팅이랑 분포 변화(distribution shift)로 인한 에러 증가를 착각하지 말자!
교차 검증 (Cross-Validation)
테스트 성능 평가
-
훈련 오류 : 모델을 학습시킨 같은 데이터에 다시 적용해 계산한 오류
-
테스트 오류 : 학습에 쓰지 않은 새 관측치에 대해 모델을 적용했을 때의 평균 예측 오류
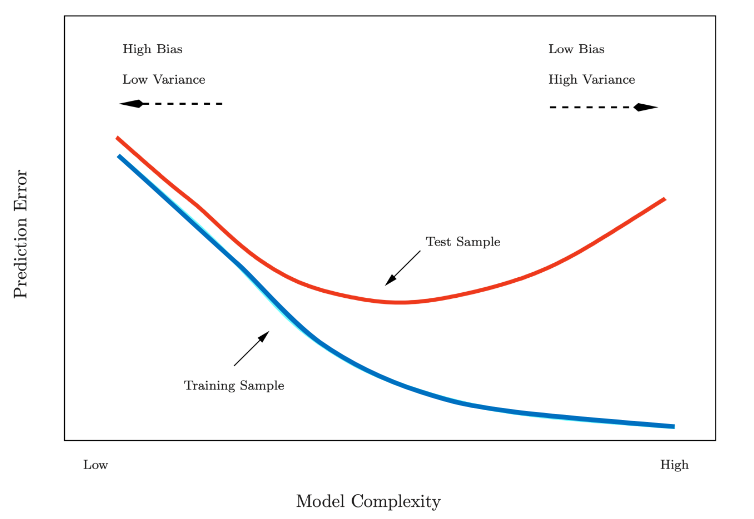
-
테스트 오류의 U자형의 바닥이 되도록 하는 적절한 모델 찾기
P : 현실에서는 테스트만을 위한 데이터를 갖기에 데이터 자체 부족할 수 있어서
S : 재표본화(resampling)를 통한 테스트 오류 추정
- 데이터를 나눠서 여러번 '훈련->평가' 반복해 테스트 오류 가늠
ex) 시험용 문제가 없으면 기존 문제집의 문제들을 이용해 모의고사 보기- 방법 : 검증셋, K겹 교차검증
검증셋(Hold-out) 방법
- 가용 샘플들을 무작위로 모의고사용/학습용으로 나누고 모의고사 1 번 보기
- 훈련셋으로 모델 적합 / 검증셋으로 예측 후 검증오류를 계산
- 학습 : 훈련셋에서, 성능평가 : 검증셋에서
- 검증오류 : 정량 반응은 MSE/ 범주 반응은 F1-score 측정
K겹 교차검증
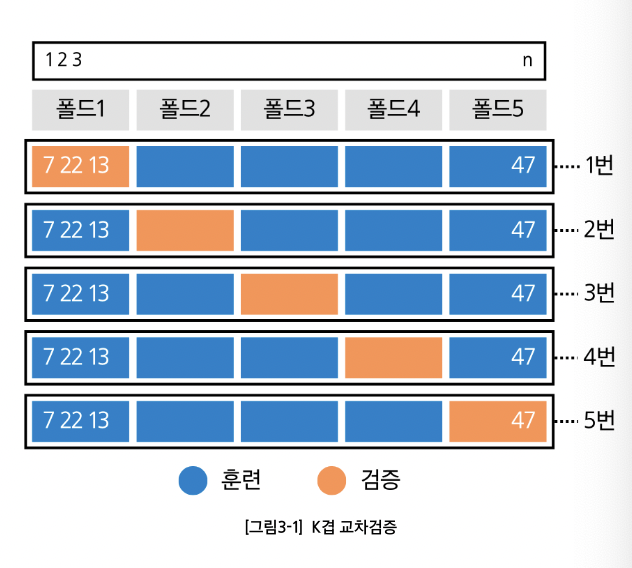
-
테스트 오류 추정의 표준적 접근.
-
데이터 전체를 크기 동일한 K개 폴드로 무작위 분할해서 폴드 k를 검증에, 나머지 K-1개를 훈련에 사용함.
- k = 1부터 K까지 반복 후, K개의 MSE를 평균해 테스트 오류를 추정함!
-
이와 비슷하게 Leave-One-Out 교차검증이 있음. (범주 작게 한것)
- 훈련셋 : 관측치 하나만 제외한 나머지 전부
- 검증셋 : 제외한 1개 관측치
- 이 과정을 n번 반복해 나온 n개의 MSE 평균으로 테스트 오류 추정
비지도 학습은 무엇인가?
1. 비지도학습
- 레이블(정답) 없이 데이터의 구조, 패턴, 집단을 찾아내는 학습
- ex. 군집화(clustering), 차원 축소(PCA), 밀도 추정/이상치 탐지 등
- 출력 : 정답 예측이 아니라 구조/요약/표현
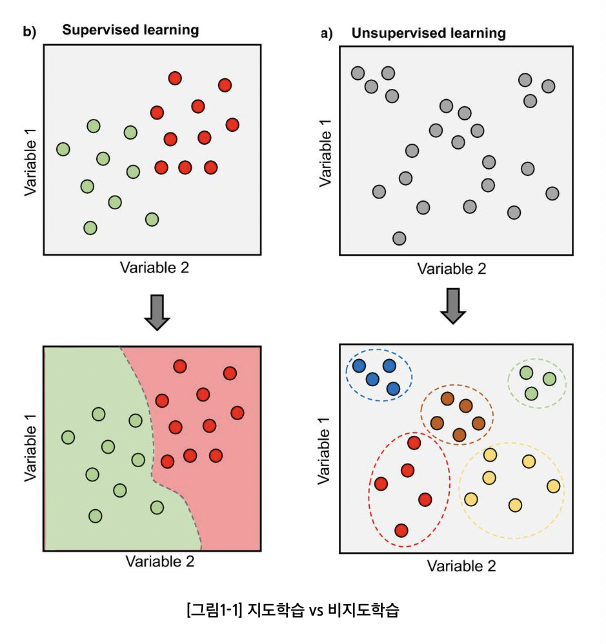
2. clustering
-
데이터 안에서 하위 집단을 찾는 기법들의 총칭
-
집단 내부는 서로 유사, 집단 간은 서로 상이하도록 데이터 분할 !
-
K-means클러스터링- 좋은 군집화 = 클러스터 내부 변동이 작은 분할
- 클러스터 거리, 차이의 합이 최소가 되도록 데이터 나누는 것이 목표
- 중첩 불가
-
Hierarchial클러스터링K-means클러스터링은 K를 미리 지정해야하는 단점이 존재하지만, 계층적 군집은 K를 고정하지 않고 전체 구조를 덴드로그램으로 제공
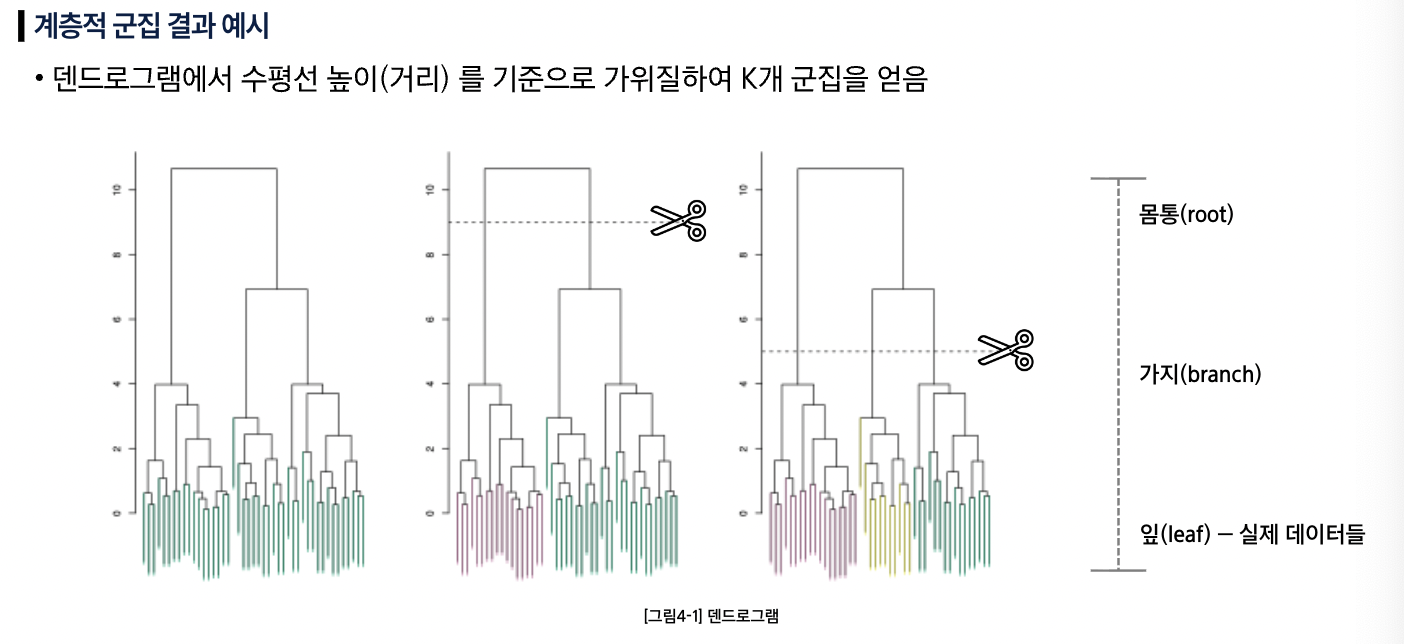
- 클러스터링 시 주의점
- 스케일링 : 표준화 (평균 0 표준편차 1로 입력 변수 변환) 필요 !
- 몇 개의 클러스터가 적당한지는 합의된 정답 없음
- 단일 시도가 아닌 여러 번 시도 권장
