파운데이션 모델
자연어 처리 및 텍스트 파운데이션 모델 "거대 언어 모델 (LLM)"
파운데이션 모델 : 인공지능의 기초가 되는 거대 AI 모델
- 텍스트 기반: GPT-4 (ChatGPT), Claude, Gemini
- 이미지 기반: Stable Diffusion, Midjourney, DALL-E
- 멀티모달 입력을 통해 멀티모달 출력 (Gpt-4o)
파운데이션 모델
- 새로운 태스크를 해결할 때 자세한 설명(프롬프트) 입력해주는 것으로 충분
- 3가지 구성 요소
- 빅데이터 - 딥러닝 기반 AI모델은 학습 데이터가 늘어날수록 성능 증가
- 자가 학습 알고리즘
- 어텐션 기반 트랜스포머 모델
- 어텐션 : 입력 데이터에서 중요한 부분에 주의를 집중하는 메커니즘
- 트랜스포머 : 어텐션 메커니즘을 기반으로 한 신경망 구조
- 트랜스포머는 문장 전체를 한꺼번에(병렬로) 보고 어텐션으로 연결 고리를 찾기 때문에, 엄청나게 방대한 데이터를 빠르게 학습가능
텍스트 파운데이션 모델
- 거대 언어 모델의 특이점
- 규모의 법칙 : 더 많은 데이터, 큰 모델, 긴 학습 -> 더 좋은 성능
- 창발성 : 특정 규모를 넘어서면 갑자기 모델에서 성질이 발현됨
ex. 인-컨텍스트 학습 , 추론 능력 등
예시
- 폐쇄형 LLM : ChatGPT(OpenAI), Claude(Anthropic), Gemini(Google)
- 더 우수한 성능 및 최신 기능
- 단점 : API 사용시마다 비용 발생, 모델이나 출력에 대한 정보 제한적 제공
- 개방형 LLM (Open Sourced) : Gemma(Google), LLaMa(Meta)
- 무료이용, 오픈소스
- 단점 : 성능이 폐쇄형에 비해 낮음, 충분한 계산 자원 필요
LLM 의 학습
GPT-3
- 학습 방법 : Next token prediction
- 단순히 통계적으로 가장 확률이 높은 단음 단어 찾는 것이기 때문에 옳지 않거나 유해한 응답 생성 가능
=> 정렬 학습 : LLM의 출력이 사용자의 의도와 가치를 반영하도록 하는 것
- 지시 학습 (Instruction tuning) : 주어진 지시에 대해 어떤 응답 생성?
- 선호 학습 (Preference Learning) : 상대적으로 어떤 응답을 더 선호 ?
지시 학습
-
방식 자체는 Next Token Prediction 과 동일한데, 데이터의 성격이 다름
-
사전 학습 상태: "민수야, 숙제 했니?"라고 물으면, "라고 엄마가 물으셨다. 나는 고개를 끄덕였다."라며 소설을 써버립니다. (다음에 올 말을 예측했을 뿐)
-
지시 학습 후: "민수야, 숙제 했니?"라고 물으면, "네, 수학 숙제 다 했어요!"라고 대답
지시 학습 : 모델에게 "이제부터 사용자가 질문(Instruction)을 던지면, 너는 그에 맞는 답변(Response)을 내놓아야 해"라는 '대화의 규칙'을 가르치는 과정
- 데이터 구성 : (지시, 답변) 세트
- 단순히 지식을 암기하는 것이 아니라 사용자의 의도를 파악하는 능력을 길러야 함!
- 번역지시 / 요약 지시 / 코딩 지시 등 다양한 명령어 패턴을 학습 데이터에 넣어서 훈련시킴.
FLAN(Finetuned Language Net)
-
구글이 발표한 지시학습의 유명한 모델이자 방법론
-
기존 데이터 1 (감정 분석): "영화가 재밌다" -> 긍정
-
기존 데이터 2 (번역): "Apple" -> 사과
-
FLAN의 학습 방식: "이 문장의 감정을 말해봐: '영화가 재밌다'" -> "긍정입니다."
-
"다음 단어를 한국어로 번역해: 'Apple'" -> "사과입니다."
이렇게 40개 이상의 데이터셋에서 100개 이상의 작업을 "지시(Instruction)" 형태로 변환해서 모델을 훈련시킴!
선호 학습 (Preference Learning)
- 정답이 정해져 있는 객관적 태스크에서는 지시 학습의 응답이 자연스럽지만, 번역과 같이 정답이 정해져 있지 않은 개방형 태스크에서는 '주어진 입력에 대해 적절한 하나의 응답이 있다'고 가정하는 것이 부자연스러움!!
선호 학습 : 다양한 응답 중 사람이 더 선호하는 응답을 생성하도록 추가 학습
- 다양한 응답 : 모델이 생성 / 응답간의 선호도 : 사람이 제공
InstructGPT <- ChatGPT 핵심 알고리즘
- 사람의 피드백을 통한 강화학습 (RLHF, Reinforcement Learning from Human Feedback)
방법
1. 지시 학습을 통해 텍스트 파운데이션 모델(ex. GPT-3) 추가 학습
- 실제 유저로부터 다양한 지시 입력 수집
- 사람의 선호 데이터를 수집하여 보상 모델 (Reward model, RM) 학습
- 사람이 선호하는 응답이 입력으로 주어지면 높은 보상 출력
결과
1. 유저의 지시를 얼마나 잘 수행하는지 사람이 직접 평가
2. 얼마나 안전한 응답을 생성하는지 평가
LLM의 추론
Decoding 알고리즘
1. 거대 언어 모델의 자동회귀 생성 (Auto-regressive Generation)
- LLM은 문장을 한 번에 만드는 게 아니라, 단어(토큰)를 하나씩 만드는데,,
입력: "오늘" -> 모델 예측: "날씨가"
새로운 입력: "오늘 날씨가" -> 모델 예측: "정말"
새로운 입력: "오늘 날씨가 정말" -> 모델 예측: "좋다"이렇게 이전에 생성된 단어들이 다시 다음 단어를 예측하는 '재료'가 되는 과정을 자동회귀라고 함.
2. 디코딩 알고리즘
- 모델이 다음에 올 단어들을 예측하면, 내부적으로 각 단어의 확률 점수를 매김.
ex. '오늘 날씨가' 뒤에 올 단어의 점수
좋다: 0.7
흐리다: 0.2
맛있다: 0.01- 이 점수표(확률 분포)를 보고 최종적으로 어떤 단어를 선택할지 결정하는 전략이 디코딩 알고리즘
- Greedy Decoding : 가장 확률이 높은 다음 토큰을 선택
- 장점 : 사용하기 쉽다
- 단점 : 직후만 고려하기 때문에 생성 응답이 최종적으로 최선이 아닐 수 있다.
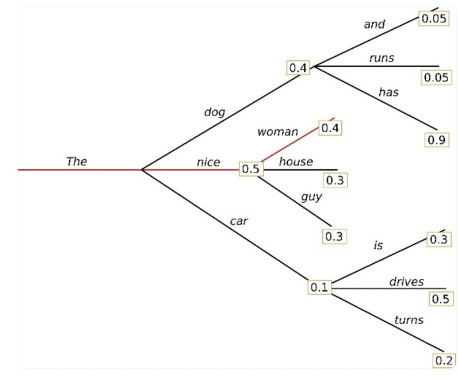
-
Beam Search : 확률이 높은 k개의 후보를 동시에 고려
-
Sampling : 가장 높은 확률을 가진 단어만 무조건 고르는 게 아니라, 모델이 제시한 확률 분포에 따라 랜덤하게 단어를 뽑는 방식 - 가끔 황당한 답변 나올 수 있음
-
Sampling with Temperature : 랜덤하게 뽑긴 하되, '확률의 높낮이'를 인위적으로 조절(Temperature, )해서 답변의 성격을 바꾸는 기법
-
Top-K Sampling : 확률이 높은 K개 토큰들 중에서만 랜덤하게 확률에 따라 샘플링

화장품 정보 찾으러 들어왔더니 이상한 모델..? 설명만 있네요.. ^^; 이게 뭐람~