
Top Interview 150
14. Longest Common Prefix
Easy
Write a function to find the longest common prefix string amongst an array of strings.
If there is no common prefix, return an empty string "".
Example 1:
Input: strs = ["flower","flow","flight"] Output: "fl"
Example 2:
Input: strs = ["dog","racecar","car"] Output: "" Explanation: There is no common prefix among the input strings.
Constraints:
1 <= strs.length <= 2000 <= strs[i].length <= 200strs[i]consists of only lowercase English letters.
Code
풀이 1 (2024.06.04)
class Solution(object):
def longestCommonPrefix(self, strs):
ans = ""
sList = [list(i) for i in strs]
sList.sort(key=len)
for i in range(len(sList[0])):
for j in sList[1:]:
if sList[0][:i+1] != j[:i+1]:
return "".join(ans)
ans = sList[0][:i+1]
return "".join(ans) Time: 26 ms (6.29%), Space: 11.9 MB (60.65%)
풀이 2 (2025.03.06)
class Solution(object):
def longestCommonPrefix(self, strs):
word = ""
target = ""
for i in range(len(strs[0])):
target += strs[0][i]
for j in strs[1:]:
if j[:i+1] != target:
return word
word = target
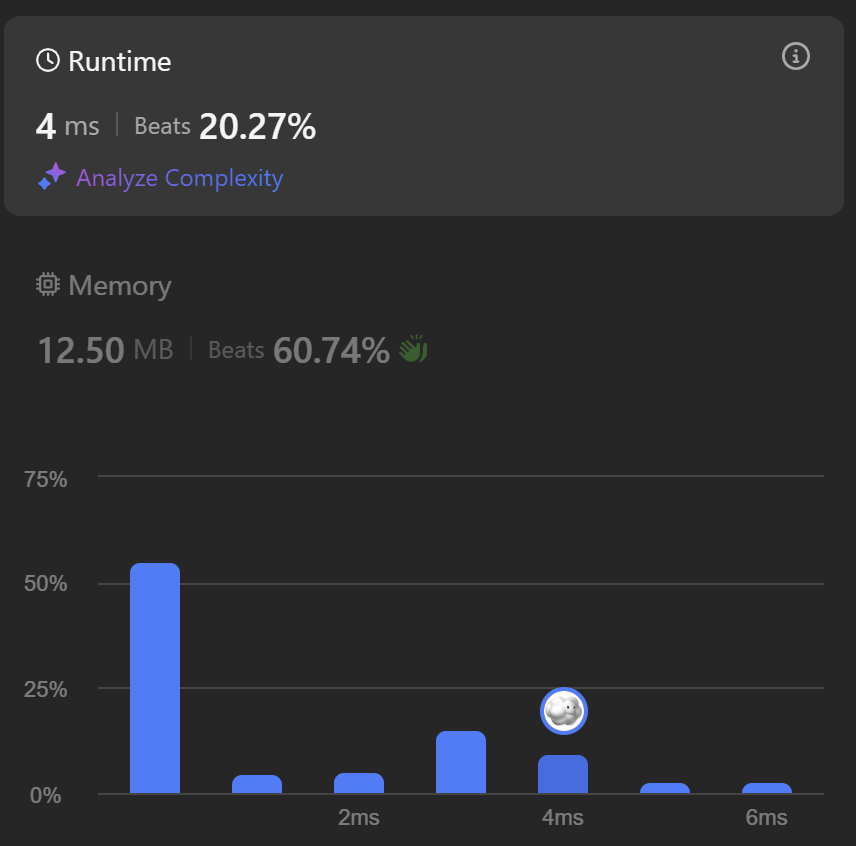
return wordTime: 4ms (20.27%), Space: 12.5MB (60.74%)
풀이 2는 시간적인 측면에서 매우 효율적이다.
약 1년이란 시간동안 아예 공부를 안한 건 아닌듯..
문자열들을 저장하고 있는 리스트인 strs에서 아무 문자열을 기준으로 삼는다. (나는 가장 첫번째 문자열을 기준으로 삼았다. strs[0])
그리고 해당 문자열의 처음부터 한 글자씩 추가한 문자열 target과 다른 문자열들을 비교한다. 만약 target과 접두사가 다른 문자열이 하나라도 등장하면, 바로 word를 반환한다.
여기서 word는 모든 문자열들의 공통된 접두사이다.
Time Complexity
- : 기준 문자열
strs[0]의 길이 - :
strs에 저장된 문자열의 개수
보완점
2번째 풀이에서 기준 문자열을
strs[0]으로 아무 값으로 잡는 것이 아닌,strs.sort(key=len)으로 길이순으로 정렬하고 가장 짧은 문자열을 기준으로 세웠으면 더 효율적일 것 같다.
class Solution(object):
def longestCommonPrefix(self, strs):
word = ""
target = ""
strs.sort(key=len) # update: 기준 문자열을 길이가 가장 짧은 문자열로 설정
for i in range(len(strs[0])):
target += strs[0][i]
for j in strs[1:]:
if j[:i+1] != target:
return word
word = target
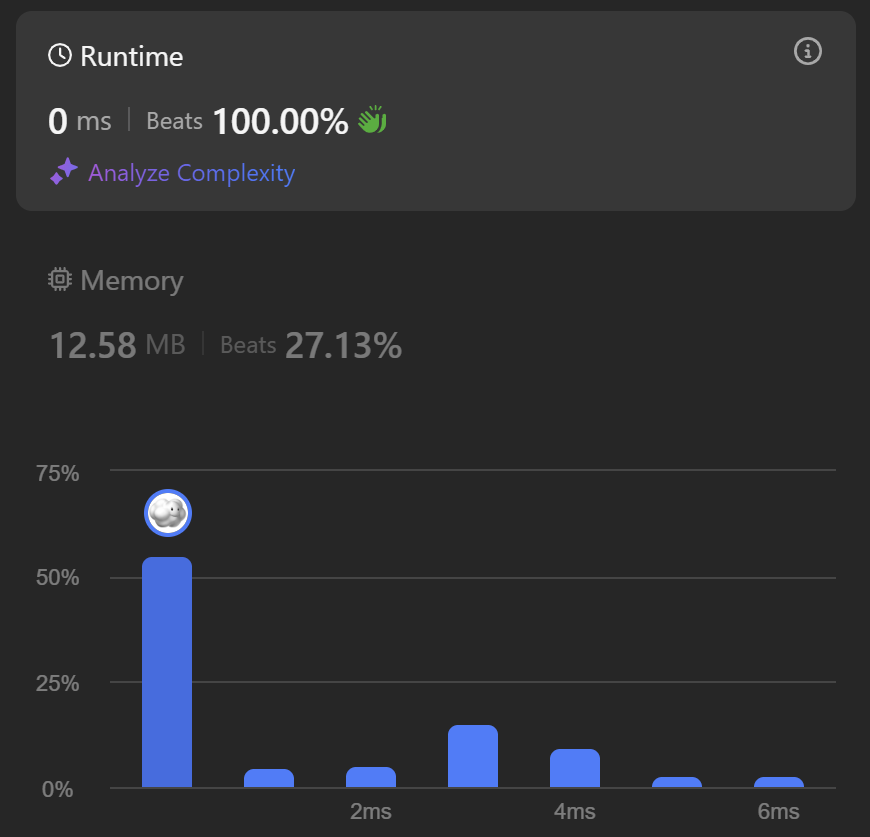
return wordTime: 0ms (100.00%), Space: 12.58MB (27.13%)
훨씬 효율적이다..
이런 사소한 점들을 잘 캐치하는 것이 중요한 것 같다.
다른 풀이법
출처: Akbar님의 풀이
class Solution:
def longestCommonPrefix(self, v: List[str]) -> str:
ans=""
v=sorted(v)
first=v[0]
last=v[-1]
for i in range(min(len(first),len(last))):
if(first[i]!=last[i]):
return ans
ans+=first[i]
return ans strs를 정렬 (v)하고first = v[0],last = v[-1]로 설정first와last만 앞에서부터 한 자리씩 비교- 같지 않을 때
ans(지금까지 first와 last의 공통 접두사)를 반환
- 같지 않을 때
여기서 주목해야 할 점
문자열들을 정렬하고, 가장 앞의 문자열과 가장 뒤의 문자열만 비교하면 되는 이유는 "문자열의 정렬방식"이다.
first와 last는 strs의 문자열들 중에서 서로 가장 다른 문자열이다. 즉, 문자열을 정렬할 때 앞 인덱스의 문자가 동일하면 그 다음의 인덱스를 비교해서 정렬한다.
그래서, first와 last만 비교해서 공통된 접두사를 반환해주면 된다.
