
이번 주차는 SQL의 A부터 Z는 아니고,, Q까지 정도..?
이 모든 걸 너무 후다닥 나가버린 느낌이 없지 않아 있어서 실습을 좀 더 해봐야 할 것 같다는 생각을 함.
근데 내가 SQL을 언제 쓸 수 있을까 ..?
📑 목차
1. SQL 기본 문법
📌 SQL SELECT ~ FROM ~ WHERE 실습 정리
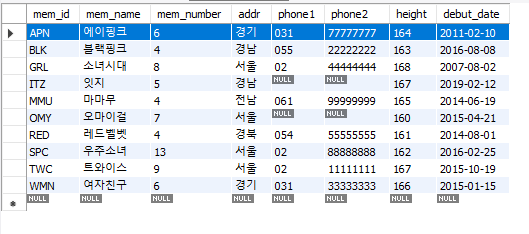
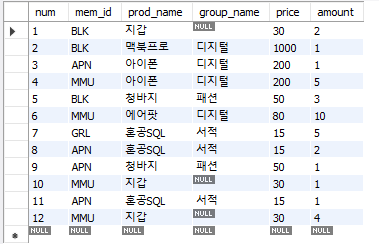
- 제품 이름에 ‘지갑’이 포함된 구매 내역 조회
SELECT *
FROM market_db.buy
WHERE prod_name = '지갑';
-- 어디에 지갑이 있는 지 모르니까..
SELECT *
FROM market_db.buy
WHERE prod_name LIKE '%지갑%';- 멤버 중 전화정보가 하나라도 비어있는(국번 또는 나머지 번호가 NULL) 사람 조회 (IS NULL)
SELECT *
FROM market_db.member
WHERE phone1 IS NULL OR phone2 IS NULL;💡 NULL 값과 비교 연산자
- SQL에서
NULL은 알 수 없음(unknown) 을 의미하는 특별한 값- 숫자
0이나 공백('')과는 다르며, 어떤 값과도 같거나 같지 않다고 비교할 수 없음- 따라서
NULL = NULL,NULL = '특정 값'같은 비교는 항상 FALSE
👉 그래서WHERE phone1 = null은 항상 거짓(false)이므로IS NULL을 사용해야 함.
- 멤버 이름이 두 글자인 행 조회
SELECT *
FROM market_db.member
WHERE CHAR_LENGTH(mem_name) = 2;
SELECT *
FROM market_db.member
WHERE mem_name LIKE '__';💡 MySQL 문자열 길이 계산
LENGTH()→ 바이트(byte) 단위 길이CHAR_LENGTH()→ 문자(character) 단위 길이- 한글은 글자당 3바이트 → "잇지"(2글자) →
LENGTH(mem_name)=6
👉 따라서 한글은CHAR_LENGTH()또는LIKE '__'를 사용해야 함.
- 디지털 또는 서적 분류에서 구매, 제품명이 ‘폰’으로 끝나는 내역 조회
SELECT *
FROM market_db.buy
WHERE (group_name = '디지털' OR group_name = '서적')
AND prod_name LIKE '%폰';❌ 잘못된 예시
SELECT *
FROM market_db.buy
WHERE prod_name LIKE '%폰'
IN (SELECT prod_name
FROM market_db.buy
WHERE group_name = '디지털' OR group_name = '서적');💡 오류 이유
=+ 서브쿼리 →= 연산자는 단일 값과 단일 값을 비교할 때 사용됨. 다중 값 반환 시 오류 발생- 여러 값 비교할 땐
IN사용해야 함- 조건은 독립적으로가 아니라
AND로 연결해야 논리적으로 맞음
WHERE절 vs HAVING / 서브쿼리 차이점
💡 집계 함수 주의
MAX()같은 집계 함수는HAVING이나 서브쿼리에서 사용해야 함WHERE MAX(height)→ 문법 오류 발생
📌 ORDER BY, LIMIT, DISTINCT, GROUP BY, HAVING
1. SELECT절 기본 구조
SELECT 열_이름
FROM 테이블_이름
WHERE 조건식
GROUP BY 열_이름
HAVING 조건식
ORDER BY 열_이름
LIMIT 숫자;2. ORDER BY
ASC(기본): 오름차순DESC: 내림차순
SELECT mem_id, mem_name, debut_date, height
FROM member
WHERE height >= 164
ORDER BY height DESC, debut_date;2.1 LIMIT
SELECT mem_name, height
FROM member
ORDER BY height DESC
LIMIT 3, 2;👉 3번째 행부터 2개 조회
2.2 DISTINCT
SELECT DISTINCT addr
FROM member;👉 중복 제거 후 결과 반환
3. GROUP BY & HAVING
GROUP BY→ 그룹 묶기- 집계 함수 (
SUM(),AVG(),MIN(),MAX(),COUNT())와 함께 사용
SELECT group_name, prod_name, SUM(amount) AS total
FROM buy
WHERE group_name IS NOT NULL
GROUP BY prod_name, group_name;👉 GROUP BY prod_name, group_name → 두 컬럼 조합으로 그룹 생성. 예를 들어, '디지털', '아이폰'은 하나의 그룹이 되고, '디지털', '맥북프로'는 또 다른 그룹이 됨.
평균보다 많이 팔린 제품 조회
SELECT prod_name, SUM(amount) AS prod_amount
FROM buy
GROUP BY prod_name
HAVING prod_amount > (
SELECT AVG(total_amount)
FROM (
SELECT prod_name, SUM(amount) AS total_amount
FROM buy
GROUP BY prod_name
) AS t
);💡 포인트
- 별칭(alias)을 어디서 지정했는지에 따라 사용 가능 여부 달라짐
- FROM 절에선, 다중이면 무조건 별칭 사용해야함
- 첫 번째
SELECT→prod_amount - 두 번째 서브쿼리 →
total_amount
2. SQL 고급 문법
1. MySQL 데이터 형식
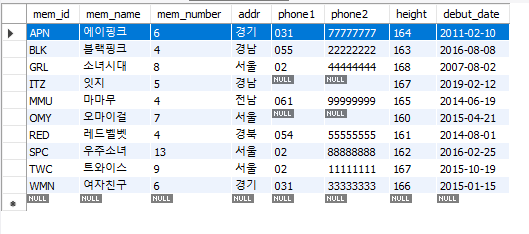
- 문자열로 받은 최소키(height) '165'를 정수로 형 변환 후, '최소 키' 이상인 멤버 조회
USE market_db;
set @min_h_str = '165';
set @min_h = cast( @min_h_str as signed);
select mem_id,mem_name, height,
date_format(debut_date,'%Y - %m') as debut_ym
from member
where height >= @min_h
order by height desc, mem_id;
DATE_FORMAT(debut_date, '%Y-%m'): debut_date를 YYYY-MM 형식으로 변환합니다. %Y는 4자리 연도, %m은 2자리 월을 나타냅니다.
- 구매 테이블에서 각 행의 구매 금액(price*amount)을 소수 2자리 DECIMAL로 변환
select *, cast(price * amount as decimal (10,2)) as line_amount
from market_db.buy;총 10자리를 사용하며, 그중 소수점 아래는 2자리.
- 이는 정수부가 최대 8자리(10-2=8)까지 가능하다는 것을 뜻함.
- DECIMAL(10, 2) → 총 10자리, 소수점 2자리 (정수부 8자리까지 가능)
Prepared Statement (준비된 구문)
- 미리 SQL을 컴파일(준비)해두고, 동일한 쿼리를 다른 값으로 여러 번 실행 가능 → SQL Injection 방지하는 보안상 이점이 있음
- 3단계: PREPARE → EXECUTE → DEALLOCATE
PREPARE구문:SQL 구문을 정의하고, 값이 들어갈 위치에?와 같은 자리표시자 사용EXECUTE: USING 절을 사용하여 변수들을 자리표시자에 바인딩해제 (DEALLOCATE): 사용이 끝난 준비된 구문을 메모리에서 해제
SET @addr = '서울';
SET @min_h = 165;
SET @sql = 'SELECT mem_id, mem_name, addr, height FROM member WHERE addr = ? AND height >= ?';
PREPARE stmt FROM @sql;
EXECUTE stmt USING @addr, @min_h;
DEALLOCATE PREPARE stmt;2. JOIN
LEFT JOIN
- 왼쪽 테이블의 모든 행 + 조건에 맞는 오른쪽 테이블의 행 결합
- 조건에 맞는 행이 있는 경우: 양쪽 테이블의 데이터가 결합되어 출력
- 조건에 맞는 행이 없는 경우: 왼쪽 테이블의 행은 유지하고, 오른쪽 테이블의 열은 모두NULL값으로 채워짐. LEFT JOIN + IS NULL조합 → Anti-join (차집합 구하기)
3. SQL Programming
- MySQL에서 프로그래밍 기능은 스토어드 프로시저에 작성
DELIMITER $$ ... END$$안에 작성,CALL로 호출
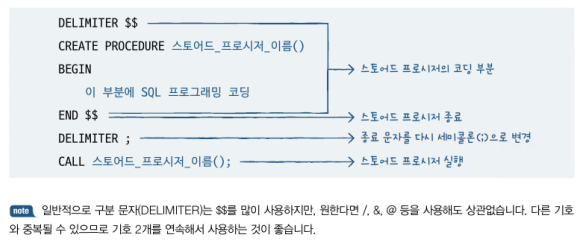
1) IF문
IF <조건식> THEN
SQL 문장들
END IF;2) CASE문

- IF는 2중 분기 / CASE는 다중 분기
3) WHILE문
ITERATE [레이블]: 반복 계속LEAVE [레이블]: 반복 종료
3. 데이터베이스 개체
1. 뷰 (VIEW)
- 뷰는 데이터 저장하지 않음 → SELECT 실행 결과를 가상 테이블처럼 보여줌
- 종류: 단순 뷰(1개 테이블), 복합 뷰(2개 이상 테이블)
- 복합 뷰로는 테이블의 데이터 수정 불가
CREATE VIEW 뷰_이름
AS
SELECT문;뷰의 장점
- 보안(SECURITY)
- 복잡한 SQL 단순화
뷰의 작동
- 사용자는 뷰를 테이블이라고 생각하고 접근
- MySQL이 뷰 안에 있는 SELECT를 실행해서 그 결과를 사용자에게 보냄
- 뷰는 기본적으로 '읽기 전용'이지만, 원본 테이블의 데이터를 수정할 수도 있음
뷰 관련 명령
- 생성:
CREATE VIEW 뷰이름 AS SELECT ... - 수정:
ALTER VIEW ... - 삭제:
DROP VIEW ...
뷰에 접근 → 일반 테이블처럼 SELECT 사용
SELECT 열이름 FROM 뷰이름
[where 조건];2. 인덱스
데이터를 빠르게 찾을 수 있도록 도와주는 도구
- Clustered Index
- 기본 키로 지정하면 자동 생성되며 테이블에 1개만 만들 수 있음
- 기본 키로 지정한 열을 기준으로 자동 정렬됨
- Secondary Index
- 고유 키로 지정하면 자동 생성되며 여러 개를 만들 수 있음
- 자동 정렬되지는 않음
- 고유 인덱스는 값이 중복되지 않는 인덱스 → 기본 키나 고유 키로 지정하면 고유 인덱스가 자동 생성됨
인덱스의 문제점
- 필요 없는 인덱스를 만드는 바람에 데이터베이스가 차지하는 공간만 더 늘어남
- 인덱스를 이용해서 데이터를 찾는 것이 전체 테이블을 찾는 것보다 느려짐
인덱스의 장점
- select 문으로 검색하는 속도가 매우 빨라짐
- 그 결과 컴퓨터의 부담이 줄어서 결국 전체 시스템의 성능이 향상됨
1. 인덱스의 내부 작동 원리
-
Clusterd Index와 Secondary Index는 모두 내부적으로 균형 트리(B-tree)로 만들어짐
-
Balanced tree, B-tree는 자료 구조에서 범용적으로 사용되는 데이터 구조
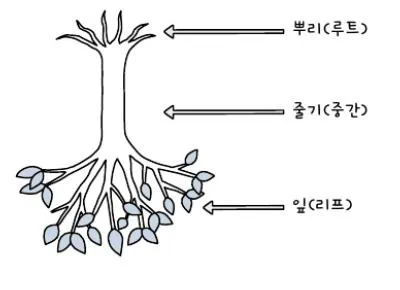
B-tree 구조에서 데이터가 저장되는 공간을 node라고 함→ Root node, Internal node, Leaf node로 구성 → MySQL에서는 node를 page라고 부름 → 페이지는 최소한의 저장 단위로, 16kbyte 크기를 가짐
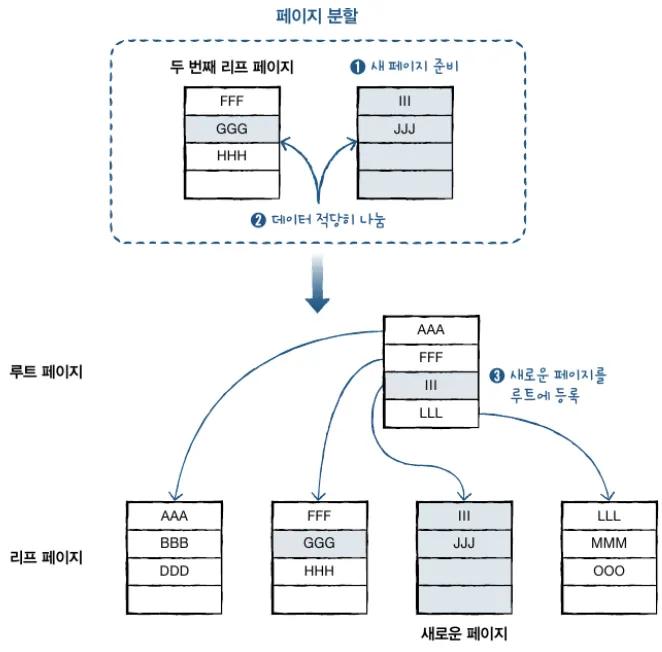
균형 트리의 페이지 분할
- 인덱스를 구성하면 데이터 변경 작업( INSERT, UPDATE, DELETE) 시 성능이 나빠짐
- 특히 INSERT 작업이 일어날 때 더 느리게 입력될 수 있음 → “페이지 분할” 작업 때문
1. 클러스터형 인덱스 구성
→ 실제 데이터는 다음과 같이 데이터 페이지가 정렬되고 균형 트리 형태의 인덱스가 형성됨
ALTER TABLE cluster
ADD CONSTRAINT
PRIMARY KEY(mem_id);2. 보조 인덱스 구성
ALTER TABLE second
ADD CONSTRAINT
UNIQUE (mem_id);
SELECT* FROM second;- 보조 인덱스가 생성되었는데도 입력한 것과 순서가 동일
- 데이터 페이지를 건드리지 않음
3. 인덱스에서 데이터 검색하기
클러스터형 vs 보조 인덱스
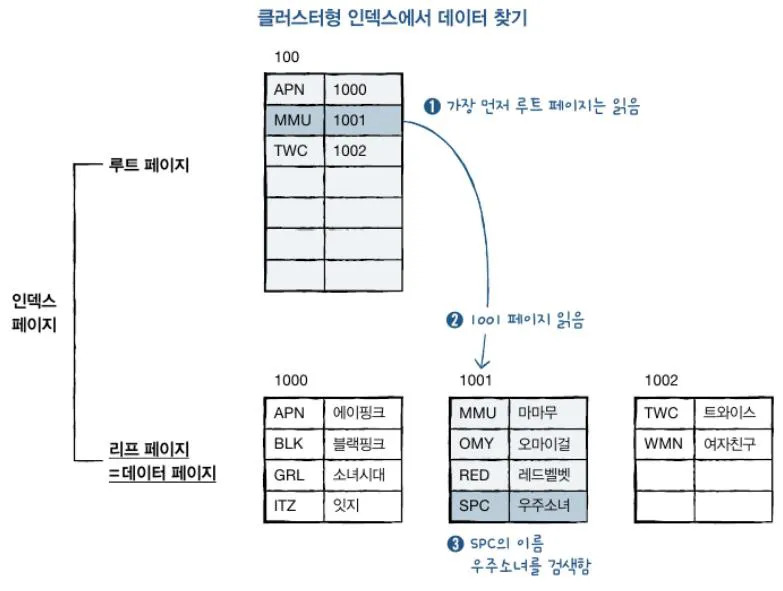
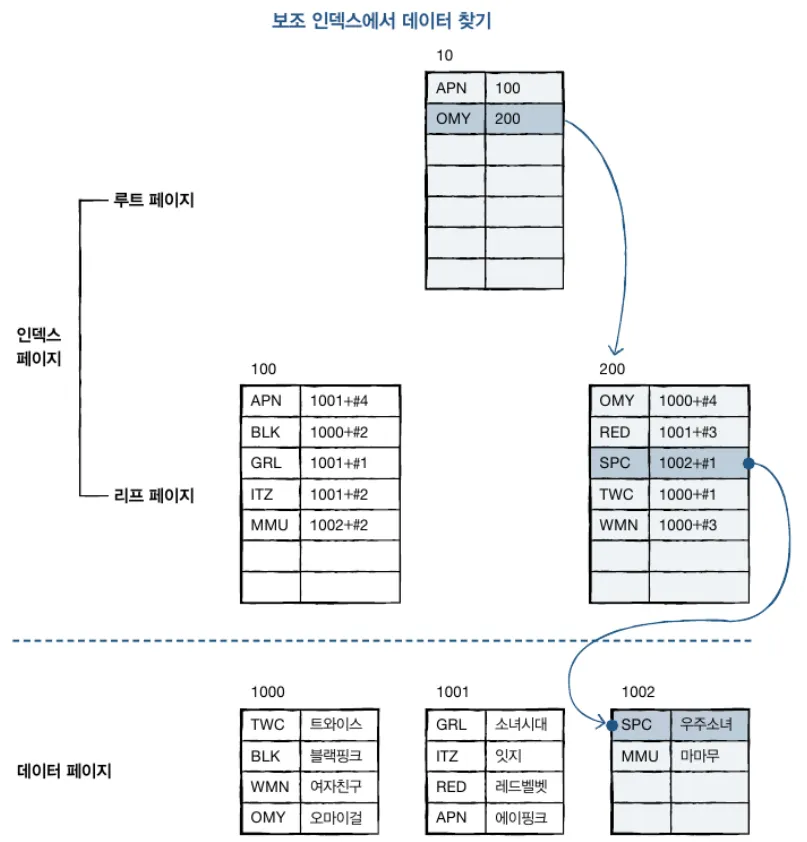
💡 FULL SCAN: 전체 테이블 검색은 데이터를 처음부터 끝까지 검색하는 것. 인덱스가 없으면 전체 페이지를 검색하는 방법밖에 없음
페이지 분할은 데이터를 입력할 때, 입력할 페이지에 공간이 없어서 2개 페이지로 데이터가 나눠지는 것을 말함
인덱스 검색은 클러스터형 또는 보조 인덱스를 이용해서 데이터를 검색하는 것. 속도는 인덱스를 사용하지 않았을 때보다 빠름
2. 인덱스 생성 제거
인덱스 생성 문법
CREATE (UNIQUE) INDEX 인덱스_이름
ON 테이블_이름(열_이름) (ASC or DESC)→ UNIQUE를 사용하면 고유 인덱스 생성, 생략하면 중복 허용 보조 인덱스 생성
인덱스 제거 문법
DROP INDEX 인덱스_이름
ON 테이블_이름→ 기본 키, 고유 키로 자동 생성된 인덱스는 DROP INDEX로 제거하지 못함
→ ALTER TABLE 문으로 자동 생성된 인덱스 제거 가능
- 인덱스 생성 실습
CREATE INDEX idx_member_addr
ON member(addr)
ANALYZE TABLE member;생성한 인덱스를 실제로 적용시키려면 ANALYZE TABLE 문으로 먼저 테이블을 분석/처리해줘야 함
3. Stored procedure
-
SQL에 프로그래밍 기능을 추가해서 일반 프로그래밍 언어와 비슷한 효과를 낼 수 있음
: SQL + 프로그래밍 기능 -> 스토어드 프로시저

-
특징:
-CREATE PROCEDURE로 정의,CALL로 실행.
- 매개변수 3종: 입력(IN), 출력(OUT), 입출력(INOUT).
- 조건문(IF), 반복문(WHILE), 동적 SQL 등 프로그래밍 로직 작성 가능. -
활용 예시:
회원 검색, 계산 처리, 반복 작업 자동화 등.
복잡한 쿼리를 재사용할 때 효율적. -
CREATE PROCEDURE는 스토어드 프로시저를 만든 것뿐이며, 아직 실행한 것은 아님 -
CALL 스토어드_프로시저_이름();로 호출함 -
DROP PROCUDURE
📌 실습 예제
1) 입력 매개변수
DELIMITER $$
CREATE PROCEDURE user_proc1(IN username VARCHAR(20))
BEGIN
SELECT * FROM member WHERE mem_name = username;
END $$
DELIMITER ;
CALL user_proc1('APINK');2) 출력 매개변수
DELIMITER $$
CREATE PROCEDURE user_proc2(OUT cnt INT)
BEGIN
SELECT COUNT(*) INTO cnt FROM member;
END $$
DELIMITER ;
CALL user_proc2(@total);
SELECT @total; -- 출력 값 확인3) 조건문 활용
DELIMITER $$
CREATE PROCEDURE checkAgeProc(IN age INT)
BEGIN
IF age >= 20 THEN
SELECT '성인입니다.';
ELSE
SELECT '미성년자입니다.';
END IF;
END $$
DELIMITER ;
CALL checkAgeProc(25);