
『스프링 배치 완벽 가이드』를 바탕으로 공부한 내용을 정리한 글입니다.
Spring Batch
대량 처리가 필요로 하는 비즈니스 작업인 배치 작업은 아래와 같은 특성들을 가지고 있다.
- 사용자 상호 작용 없이 가장 효율적으로 처리되는 대용량 정보의 자동화되고 복잡한 처리 작업
- 매우 큰 데이터 세트에서 반복적으로 처리되는 복잡한 비즈니스 규칙의 주기적인 적용
- 포맷, 검증 및 처리해야 하는 내부 및 외부 시스템에서 수신한 정보를 기록 시스템에 통합하는 작업에 대한 매일 수십억 개의 트랜잭션을 처리하는 데 사용하는 일괄 처리 작업
스프링 배치는 엔터프라이즈 시스템의 일상적인 운영에 필수적인 강력한 배치 애플리케이션을 개발할 수 있도록 설계된 가볍고 포괄적인 배치 프레임워크이다.
Job
배치 처리 프로세스를 표현한다. 스프링 배치에서는 아래 객체들을 통해 관리한다.
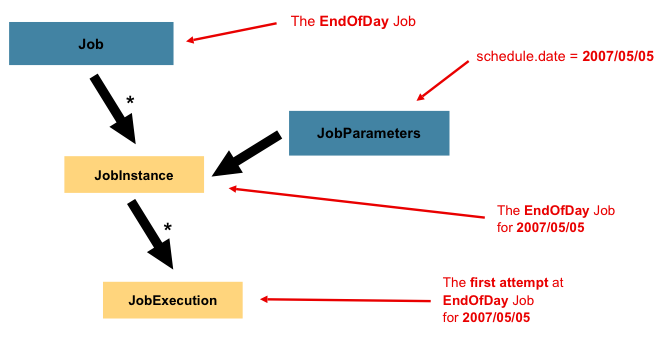
- JobInstance: 논리적인 Job의 실행을 표현한 객체
- JobParameters: Job을 실행할 때 사용하는 파라미터의 집합 객체
- JobExecution: Job의 실제 실행을 표현한 객체
- JobLauncher: JobParameters를 전달하며 Job을 실행하는 객체
- JobRepository: 실행중인 작업에 대한 메타 데이터를 관리해서 작업이 실행되는 일련의 모든 과정들을 저장하고 이에 대한 상태 조회를 제공하는 객체
- JobExplorer: JobRepository와 동일한 기능을 하지만 읽기 작업만 가능한 객체
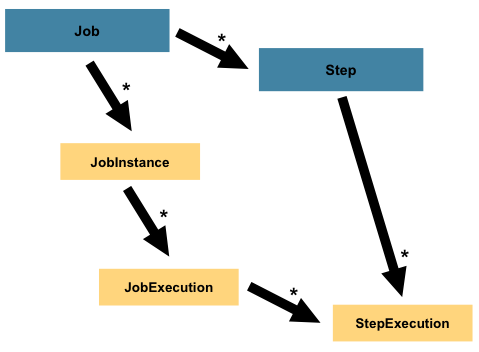
Step
Job을 구성하는 단계를 표현한다. 스프링 배치에서 step의 실행을 StepExecution 형태로 관리한다.
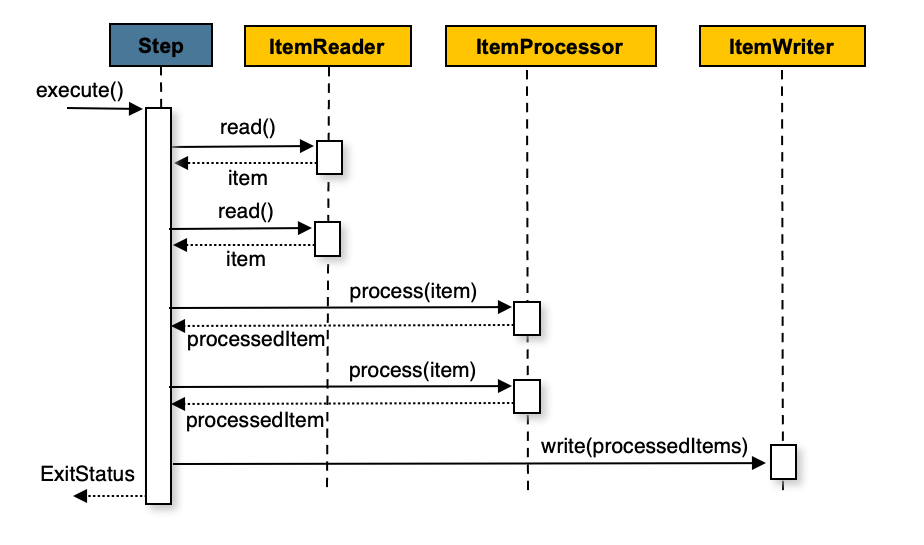
ItemReader, ItemProcessor, ItemWriter, Tasklet
Step을 구성하는 작업에 대한 인터페이스는 다음과 같다.
- ItemReader: 데이터 읽기 작업에 대한 인터페이스로 null을 리턴하면 읽기 작업을 멈춘다.
- ItemProcessor: 데이터 변환, 처리 작업에 대한 인터페이스로 null을 리턴하면 해당 데이터는 처리하지 않는다.
- ItemWriter: 데이터 쓰기 작업에 대한 인터페이스
- Tasklet: 하나의 단계로 구성된 step을 위한 인터페이스
chunk 기반 처리
ItemReader, ItemProcessor, ItemWriter로 등록된 스텝은 작업을 묶어서 수행할 아이템 갯수를 chunk로 지정해 chunk로 지정한 갯수만큼 읽기와 처리 작업을 수행한 후 1번의 ItemWriter의 쓰기 작업을 수행하고 chunk 단위의 커밋과 롤백을 수행하는 것이 특징이다.
스프링 배치 사용하기
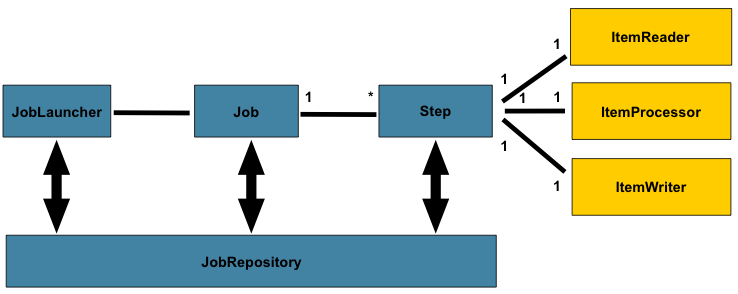
Job Configuration
스프링 배치를 사용하기 위해서는 실행할 잡과 잡을 구성하는 스텝을 빈으로 등록해야 한다.
실행 설정
spring boot의 기본 설정을 통해 등록한 잡이 SimpleJobLauncher를 통해 자동으로 실행되는데 아래와 같은 방법들을 통해 실행되는 잡을 변경할 수 있다.
- 프로퍼티 파일을 통한 실행 잡 설정
spring.batch.job.name=job_name - 명령어 파라미터를 통한 실행 잡 설정
java -jar demo.jar --job.name=job_name - 자동 실행이 아닌 JobLauncher를 통한 실행 잡 설정 방법
spring.batch.job.enabled=falsejobLauncher.run(job(), jobParameters);
Job 설정
스프링 배치 잡을 관리하는 JobRepository를 사용하기 위한 RDB 설정 빈(Datasource, PlatformTransactionManager)이 필요하다.
@Configuration
@RequiredArgsConstructor
public class BatchConfig extends DefaultBatchConfigurer {
@Override
public void setDatasource(Datasource datasource) {
// 별도로 설정을 안하면 인메모리 맵을 통한 잡 레포지터리가 설정된다.
}
@Bean
public Job job(Step step) {
return new JobBuilder("job")
.preventRestart()
.start(step1())
.next(step2())
.build();
}
@Bean
public Step step1() {
return new StepBuilder("step1")
.<String, String>chunk(10)
.reader(reader())
.processor(processor())
.writer(write())
.build();
}
@Bean
public Step step2() {
return new StepBuilder("step2")
.tasklet(tasklet())
.build();
}@JobScope, @StepScope
JobParameters를 매개변수로 참조하는 빈의 생성을 JobParameters가 전달되는 잡이나 스텝의 실행 시점으로 지연시켜 명령이나 다른 소스에서 받아들인 JobParameters를 주입받을 수 있다.
ExecutionContext
JobExecution 또는 StepExecution의 속성으로 잡이 실행되고 있는 동안 저장하고 있는 상태 정보를 잡이나 스텝 간에 공유가 가능하게 한다.
@Bean
@JobScope
public Job job(Step step) {
return new JobBuilder("job")
.tasklet(step(null))
.build();
}사용 방법
- ItemReader, ItemProcessor, ItemWriter: @BeforeStep을 등록한 메소드에 전달되는 매개변수인 StepExecution의 getExecutionContext 메소드를 통해 접근한다.
- Tasklet: execute 메소드에 전달되는 매개변수인 StepContribution의 getExecutionContext 메소드를 통해 접근한다.
재시도 처리
- 스프링 배치는 실패된 작업에 대한 재시도 처리가 가능하다.
- 실패된 작업에 대한 별도의 스텝 처리를 stepBuilder를 통해 등록이 가능하다.
- 실패된 작업 재시도 처리를 stepBuilder의 faultTolerantStepBuilder를 통해 등록이 가능하다.
스프링 배치의 성능 개선
스프링 배치 작업을 구성하는 스텝에 대한 병렬 처리로 작업 성능을 개선할 수 있다.
- 다중 스레드 스텝: 스텝 내부의 chunk 처리를 각 스레드에서 처리하는 방식이다.
- 병렬 스텝: 순서 상관 없는 스텝들을 병렬 처리하는 방식이다.
- AsyncItemProcessor: ItemProcessor 작업을 병렬로 실행할 수 있도록 지원하는 객체로 사용하기 위해 AsyncItemWriter를 같이 사용해야 한다.
- 원격 청킹: ItemReader 역할을 하는 마스터 노드와 ItemProcessor 역할을 하는 원격 워커로 구성되어 있고 원격 통신을 위한 I/O cost가 발생한다.
- 파티셔닝: 워커들을 관리하는 마스터 스텝과 워커들로 구성되어 있어 워커들의 작업이 모두 완료될 때까지 진행하지 않는다.
