
실무에서 Spring JPA를 사용하며 배운 Spring JPA 관련 개념들을 정리했습니다.
Entity 속성
@JoinColumn
- name: 매핑할 외래키 명
- referencedColumnName: 외래키가 참조하는 대상 테이블의 기본키 컬럼명
@Enumerated
자바 Enum 타입을 엔티티 클래스의 속성으로 매핑해서 사용할 수 있다.
@Enumerated(EnumType.ORDINAL): Enum 타입의 순서번호를 DB에 저장@Enumerated(EnumType.STRING): Enum 타입의 이름을 DB에 저장
@OneToMany
mappedBy
- 테이블의 경우 한 쪽의 외래키만 있어도 조인 연산을 통한 양방향 관계를 지니고 있지만 객체의 관계에서의 양방향 관계는 각자 객체를 참조하는 2개의 단방향 관계로 표현되기 때문에 두 개의 객체 중 하나의 객체만 테이블의 외래키를 관리하는 연관관계의 주인을 명시해야 한다.
- 다대일, 일대다 관계에서는 항상 다의 관계를 가진 객체가 연관관계 주인으로 외래키를 관리한다.
- 해당 속성을 명시한 엔티티는 연관관계 주인이 아니기 때문에 외래키 관리를 하지 않는다.
- 연관관계 주인이 아닌 엔티티에서의 연관관계 연산은 무시된다.
- 영속성 상태가 아닐 때에는 연관관계 관리를 하지 않기 때문에 양쪽에 연관관계 연산을 해주는 연관관계 편의 메소드를 사용하는 것이 가장 안전한다.
cascade
자식 엔티티에 부모의 영속 상태의 전이 수준을 지정할 수 있다.
CascadeType.ALL: 영속화 관련 모든 메소드가 자식 엔티티에게도 적용된다.CascadeType.PERSIST: 부모 엔티티가 영속화 되면 연관된 자식 엔티티까지 같이 영속성 상태가 전이된다.
orphanRemoval
연관관계가 끊어진 자식 엔티티에 대한 자동 삭제 여부를 지정할 수 있다.
fetch
엔티티 객체가 초기화 될 때 DB select 쿼리를 통해 초기화되는데 이 때 연관관계인 엔티티도 같이 초기화 될 지 실제 사용될 때 초기화할 지를 지정할 수 있다. 일대다 연관관계 객체를 저장하는 컬렉션 타입 프록시 객체의 경우 실제 내부 요소가 참조될 때 초기화가 이뤄진다.
FetchType.Eager: 즉시 로딩으로 객체가 초기화 될 때 연관관계 객체도 함께 초기화된다.FetchType.Lazy: 객체 내 연관관계 객체를 참조할 때 초기화되기 전까지 프록시 객체로 초기화된다.
프록시 객체
초기화가 실제 참조될 때 동작하는 FetchType.Lazy의 경우 영속성 컨텍스트에서는 해당 연관관계 객체 값이 비어있는 프록시 객체로 초기화하고 실제 참조가 될 때 값의 초기화가 진행된다.
N + 1 문제
엔티티를 읽어올 때 @OneToMany(fetch=FetchType.Lazy) 연관관계를 가진 엔티티는 프록시 객체로 반환되고 해당 연관관계 엔티티를 실제로 조회하는 경우에 추가적인 select 쿼리가 동작된다. 이 경우 N개의 엔티티마다 가진 연관관계 엔티티를 초기화하게 되면 추가적인 select 쿼리가 엔티티의 갯수만큼 발생한다.
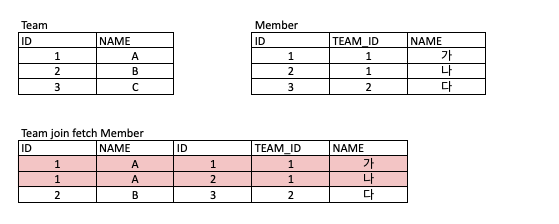
join fetch란?
JPQL에서 제공하는 키워드로 join 쿼리 뒤에 fetch 키워드를 붙여 사용하면 엔티티가 가진 연관관계 엔티티들의 값까지 채워주는 방식으로 동작하게 된다. join fetch에서는 연관관계인 객체의 값을 로딩하고 inner join의 경우 연관관계인 객체의 값을 초기화하지 않는 차이를 가지고 있다.
@OneToMany join fetch 시 주의할 점
일대다 관계를 가진 객체에 대한 join fetch을 수행한 경우 내부적으로 수행되는 inner join의 결과로 인해 중복되는 객체가 나올 수 있다. 따라서 이런 경우에 중복된 엔티티를 가져오고 싶지 않으면 JPQL에 distinct 키워드를 사용해서 중복되는 객체를 제외하고 받게 처리할 수 있다.
join fetch에서의 Paging 메모리 사용 이슈
join fetch와 paging을 같이 사용하면 문제 없이 페이징 결과가 반환된다. 하지만 사이즈가 큰 테이블에 대해 수행하는 join fetch + paging 연산을 수행하는 경우에는 다음과 같은 warn 레벨의 로그가 확인할 수 있다.
HHH000104: firstResult/maxResults specified with collection fetch
해당 경고 문구를 검색해보면 애플리케이션 상에서 페이징을 하기 위해 쿼리 수행 결과를 메모리에 저장해서 발생하게 되는 메모리 사용량에 대한 경고 문구로 해석된다.
JPQL의 join fetch는 paging 갯수를 result set의 row 갯수가 아닌 객체의 갯수로 판단하고 앞서 말한 일대다 관계를 가진 객체의 경우 join fetch의 결과가 중복되는 객체가 나올 수 있기 때문에 DB에서 limit을 사용하지 않고 전체 테이블을 join한 result set을 모두 메모리에 저장한 후 애플리케이션에서 n개의 객체를 반환한다. 이 때 limit 쿼리 없이 테이블 조인 결과를 메모리에 저장하기 때문에 메모리 사용량이 상당하다. 따라서 페이징 쿼리와 join fetch 쿼리를 나눠서 동작하게 수정해서 사용해야 우리가 예상한대로 쿼리가 동작된다.
- 페이징 쿼리를 통해 join fetch를 할 엔티티의 식별자 리스트를 가져온다. (limit 동작 O)
- 1의 엔티티를 join fetch한다. (where in 사용)
MultipleBagFetchException
2개 이상의 일대다 연관관계를 가진 객체에 대한 join fetch의 수행 결과로 나오는 카타시안 곱을 반환할 때 복수개의 객체에 대한 구분을 못하기 때문에 발생하는 에러로 다음과 같은 방법을 통해 해당 에러 없이 join fetch가 가능하다.
- 일대다 연관관계 객체를 담는 Collection 타입을 Set으로 변경한다.
- @OrderColumn를 사용한다.
- @OrderBy를 사용한다.
JPA 성능 개선
단순히 조회를 하는 경우에는 영속성 컨텍스트에서의 변경 감지를 위한 스냅샷이나 쓰기 지연을 위해 동작하는 트랜잭션 플러쉬 과정이 필요하지 않다. 따라서 다음과 같은 방법을 통해 성능 최적화를 할 수 있다.
-
메모리 최적화
조회 쿼리 작성시 @QueryHint의 readOnly를 통해 읽기 전용 쿼리로 명시하게 되면 스냅샷 인스턴스를 만들지 않는다. 또한 엔티티 타입의 조회가 아닌 스칼라 타입의 조회를 하는 경우에도 영속성 컨텍스트가 결과를 관리하지 않아 메모리 사용을 하지 않게 된다. -
속도 최적화
@Transaction(readOnly=true)를 하게 되면 트랜잭션 커밋 시점에 변경 감지를 위한 flush를 수행하지 않아 속도가 개선된다.
+ 스프링 5.1 버전 이후 관련 업데이트 상황
@Transaction(readOnly=true)로 설정하면, @QueryHint의 readOnly까지 모두 동작하게 되서 메모리 개선과 조회 속도 개선이 함께 된다. 따라서 조회하는 쿼리에는 반드시 readOnly 옵션을 true로 설정하는 것을 권장한다.
JPA 참고 자료 추천
hibernate 기술과 관련된 여러 자료들을 볼 수 있다.
자바 ORM 표준 JPA 프로그래밍
join fetch + paging issue
MultipleBagFetchException
@Transaction(readOnly=true)
