
You Only Look Once(YOLO)란?
YOLO는 one-state 객체 인식 알고리즘으로 빠른 속도와 높은 정확도를 보여주는 실시간 객체 인식을 위한 대표 알고리즘 중 하나입니다.

위 그림은 YOLO를 설명하는 유명한 그림입니다. 그림처럼 이미지를 특정 영역으로 나누고 각 cell이 하나의 객체의 여부를 찾는 방식으로 동작하기 때문입니다. 하나의 grid cell은 0부터 1로 정규화된 공간으로 하나의 Bbox에 대한 중점과 높이 그리고 너비를 예측하는 방식을 동작합니다.
정리하면, yolo는 원본 이미지를 특정 개수의 grid로 나눠서 객체를 탐지한다. 이때, 각 grid에는 상대적인 크기의 중점을 가르키는데 예를 들어 가로, 세로 (25, 25)크기의 이미지를 (5, 5)의 출력 grid로 구성된다면, 한 grid는 원본 영상에 대해 (5, 5) 영역에 대한 정보를 압축하고 있는 특징이 된다.
결국 한 gird는 [x, y, w, h] 상대적인 크기를 갖는다. 다만, 중점(x, y)는 한 grid cell 안에서 존재해야 하기 때문에 0~1 크기를 갖으며 상대적인 위치를 나타낸다. 가로와 세로(w, h)의 경우 grid cell보다 크기 때문에 1보다 클 수 있다. 이는 뒤쪽 loss function을 설계하는 과정에서 고려된다.
Target label
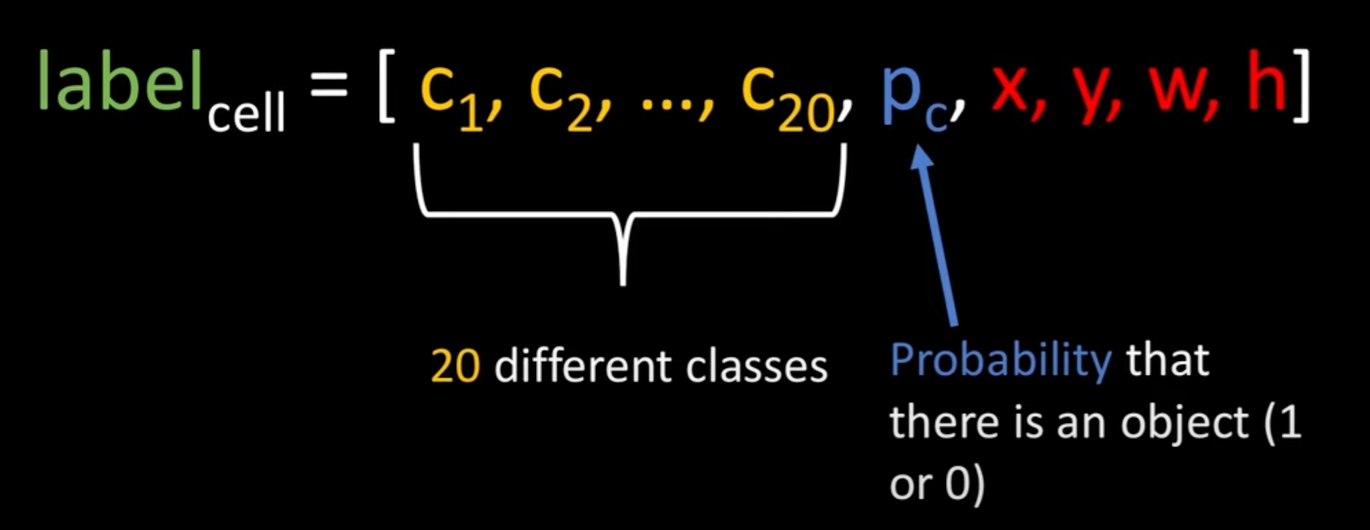
YOLO 모델은 위와 같은 형태의 Data annotation을 사용한다. 20개의 class로 구성된 데이터를 예로 든 것이다. 먼저 앞 20개의 경우 각 class를 one-hot encoding 해서 나타낸 것이다. 만약, 1번 class라면 두 번째 위치를 제외한 나머지는 0으로 표기한다. 그 뒤에는 객체가 존재할 확률, Bbox의 중점 위치, 높이와 너비를 나타낸다. label의 경우 확률은 1로 고정한다.
Predict label
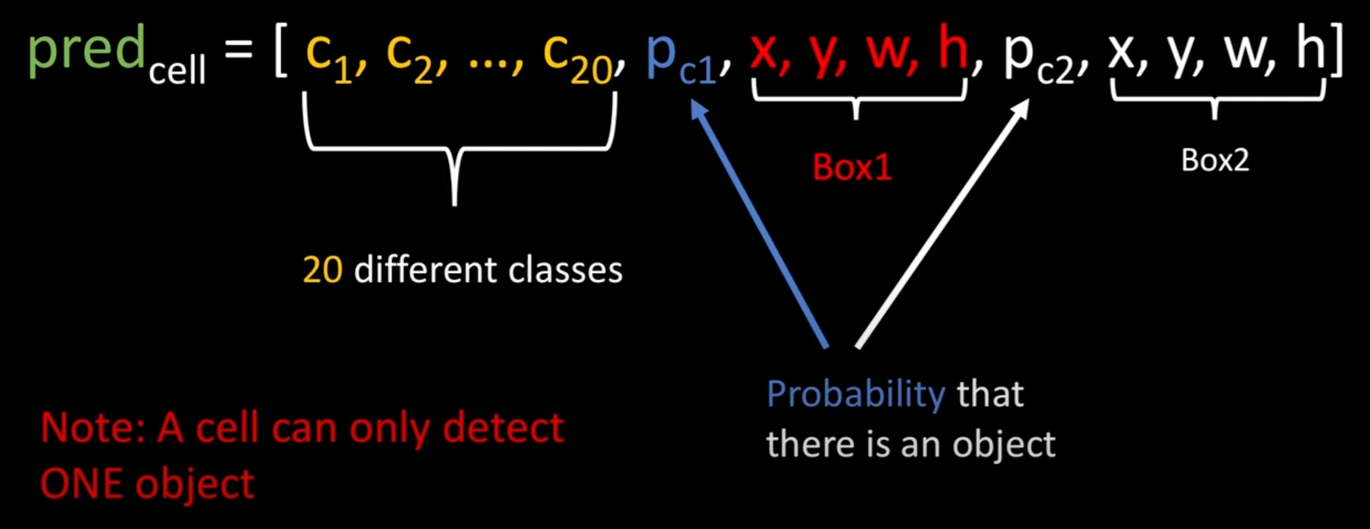
신경망의 output은 1개의 bbox 정보가 추가된 형태로 위 그림과 같이 두 개의 bbox 정보가 포함된다. 여기서 저자들은 한 개의 bbox는 옆으로 크고 나머지 한 개는 위로 큰 형태로 정의해서 사용한다.
Model archtecture

Loss function

Localization loss
- : 영상 내에 객체가 없는 영역이 있는 영역보다 많이 존재할 수 있다. 이런 경우 Confidence score가 0으로 수렴되기 쉬워져 Gradient가 다른 Loss를 압도하여 학습에 악영향을 줄 수 있다. 저자는 해당 값을 5로 설정했다.
- : grid cell의 수(=7x7=49)
- B: grid cell별 bounding box의 수(=2)
- : i번쨰 grid cell의 j번째 bbox가 객체를 예측하도록 할당(responsible for)받았을 때 1, 그렇지 않으면 0인 indicator function이다. grid cell에는 B개의 bbox를 예측하지만 그 중에서 가장 높은 confidence score를 갖는 하나의 bbox만을 학습한다.
- : i 번째 label의 bbox의 중점 좌표인 x, y와 가로, 세로 크기인 width, height를 의미한다. 특히, bbox의 크기는 cell의 크기를 넘어갈 수 있기 때문에 상대적으로 큰 bbox의 loss가 크게 발생한다. 작은 bbox의 loss를 보정하기 위해 제곱근을 사용해서 표현한다.
- : 모델의 prediction에 대한 bbox의 x, y 좌표, width, height를 나타낸다.
Confidence loss
- : 객체를 포함하지 않는 grid cell에 대한 가중치를 의미한다. 저자는 0.5를 사용하였으며, 객체가 없는 경우에도 0.5보다 작아지지 않도록 하여 gradient가 크게 작용하는 것을 막는다. 또한 보가 작게 설정되어 객체가 있는 경우에 대한 loss의 중요도를 높이는 역할도 수행한다.
- : i 번째 grid cell의 j 번째 bbox가 객체를 예측하도록 할당(responsibel for) 받지 않았을 경우 1, 그렇지 않은 경우에는 0이 되는 indicator function이다.
- : 객체가 포함되어 있는 경우 1, 그렇지 않은 경우 0이다.
- : 예측한 bbox의 confidence score를 의미한다.
Classification loss
- : target label의 class probabilities이다.
- : prediction의 class probabilities이다.
