노드간의 다양한 통신 시나리오
- message 손실이 있는가?
- 데이터 크기에 따라 전송 속도의 변화?
- 처리속도가 느린경우 처리하지 못한 데이터는 어떻게 되는가?
- 타임슬롯을 넘어가면 어떤 문제가 나타나는가?
- 의존성이 있는 node의 데이터를 순차적으로 적리할 수 있는가?
- 수신하는 노드가 없으면 메시지 전송 속도가 빨라지는가?
- 토픽을 수신하는 노드의 수가 많아지면 메시지 전달 속도가 느려지는가?
과제
위 5가지 문제에 대한 증상에 대한 원인 분석, 해결책 적용 및 결과 정리
그리고 위 과정에 대한 2개의 새로운 시나리오를 추가적으로 정리
사용 할 패키지
├── xycar_ws
├── build
├── devel
├── .catkin_workspace
└── src
├── CMakeLists.txt
└── topic_practice (package)
├── launch
│ └── *.launch
│ └── ...
└── src
├── *.py
└── ...1. message가 분실 없이 잘 도착했는가?
roslaunch <package_name> <*.launch> 명령의 경우 node의 실행 순서를 강제할 수 없다는 단점이 있다. 만약 message를 받는 node가 나중에 실행이 된다고 가정하면, 누락되는 데이터가 발생할 수 있다. 때문에 rosrun 명령을 사용하면 원하는 순서대로 실행시킬 수 있다. 더 좋은 방법이 있는지 알아보자.
# 파일 이름
serial_sender.py
serial_receiver.py
serial.launch
sender_serial에서 메시지를 보내면 위 그림처럼 데이터 1을 받지 못한다는 것을 확인할 수 있다. ROS에서 메시지를 전달하기 위해서는 roscore에 등록되어 있는 정보를 토대로 발행자와 구독자를 연결시켜준다. 이 과정이 끝나기 전에 데이터가 먼저 발행되기 때문에 첫 번쨰 데이터가 유실되게 된다.
이러한 문제를 해결하기 위한 방법으로 Publisher 객체 안에있는 get_num_connections() 함수를 사용할 수 있다. 이 함수는 등록된 노드의 수를 확인하는 함수로 publisher가 발행중인 topic을 구독하고 있는 subscriber의 수를 반환한다. 또한 1:다 통신 과정에서도 유용하게 사용될 수 있다.
...
while(pub.get_num_connections() == 0):
# 메시지 전달 처리...
...
get_num_connections() 함수를 사용하면, 1번 메시지부터 잘 들어오는 것을 확인할 수 있다.
# serial_sender.py 파일
#!/usr/bin/env python
import rospy
from std_msgs.msg import Int32
rospy.init_node('sender_serial')
pub = rospy.Publisher('serial_topic', Int32)
rate = rospy.Rate(2)
count = 1
while (pub.get_num_connections() == 0):
pass
while not rospy.is_shutdown():
pub.publish(count)
count+=1
rate.sleep()# serial_receiver.py
#!/usr/bin/env python
import rospy
from std_msgs.msg import Int32
def callback(msg):
print(msg.data)
rospy.init_node('receiver_serial')
sub = rospy.Subscriber('serial_topic', Int32, callback)
rospy.spin()2. 데이터 크기에 따른 전송 속도의 변화는?
일반적인 통신 과정에서 데이터가 큰 경우 데이터를 분할하고 재조합 하는 등의 오버헤드가 증가하기 때문에 전송 속도가 느려진다. 만약 subscriber가 없다면 전송 속도가 더 빨라지는지 확인해보자.
# 파일 이름
speed_sender.py
speed_receiver.py
speed.launch

# speed_sender.py
#!/usr/bin/env python
#!/usr/bin/env python
import rospy
from std_msgs.msg import String
rospy.init_node('sender_speed')
pub = rospy.Publisher('speed_topic', String)
pub = rospy.Publisher('speed_topic', String)
rate = rospy.Rate(1)
idx = 0
pub_size = [1000000] # 1M = 1000000byte
pub_size += [5000000] # 5M
pub_size += [10000000] # 10M
pub_size += [20000000] # 20M
pub_size += [50000000] # 50M
# data = "#" * pub_size
while (pub.get_num_connections() == 0):
pass
while not rospy.is_shutdown():
try:
data = "#" * pub_size[idx];
except IndexError:
idx = 0
data = "#" * pub_size[idx];
idx += 1
# print(len(data), data/1000000+"M")
pub.publish(data + ":" + str(rospy.get_time()))
rate.sleep()
# speed_receiver.py
#!/usr/bin/env python
import rospy
from std_msgs.msg import String
def callback(msg):
# print(msg.data)
curren_time = str(rospy.get_time())
data, arrival_time = str(msg.data).split(':')
time_diff = float(curren_time) - float(arrival_time)
string_size = len(data)
rospy.loginfo(str(string_size) + " byte: " + str(time_diff) + " second")
try:
rospy.loginfo("speed: " + str(float(string_size)/time_diff) + "byte/s")
except ZeroDivisionError:
rospy.loginfo("speed: " + str(float(string_size)/time_diff) + "byte/s")
rospy.init_node('receiver_speed')
rospy.loginfo("init")
sub = rospy.Subscriber('speed_topic', String, callback)
rospy.spin()3. 처리 속도가 느려 처리하지 못하는 데이터가 발생하면?
메시지로 받은 데이터를 처리하는 과정이 길어지면 지속적으로 들어오는 데이터를 바로 처리하지 못하고 쌓일 수 있다.
# 파일 이름
overflow_sender.py
overflow_receiver.py
overflow.launch
그림과 같이 1초에 한 번씩 데이터를 받는데에 반해 데이터를 처리하는 과정이 길어지면서 중간에 데이터가 유실되는 모습을 확인할 수 있다. 이런 문제는 queue_size를 늘려주면 해결할 수 있다. queue는 먼저 들어온 데이터를 먼저 내보내는 자료구조로 네트워크나 순차적인 처리가 필요한 경우에 주로 사용된다.

그림은 subscriber의 queue_size를 1000으로 설정한 결과이다. queue가 buffer 역할을 수행하기 때문에 1씩 증가하는 데이터를 출력하는 것을 볼 수 있다.
4. 주기적 발송에서 타임슬롯을 넘어가면 어떻게 되는가?
ROS를 이용해서 message를 개발하는데 있어 일반적으로 rospy.Rate()함수를 이용해서 주기적인 loop를 이용한다. 만약 loop에서 처리하는 리소스가 증가해 주어진 시간을 초과하면 어떤 문제가 나타날지 알아보자.
# 파일 이름
timeslot_sender.py
timeslot_receiver.py
timeslot.launch
위 그림은 rospy.rate(5)로 설정한 상태에서 count 만큼의 메시지를 보내는 시간과 rate.sleep()을 하는데 걸린 시간을 나타낸 것이다. 위에서 부터 1000, 100000, 110000개의 메시지를 보낸 것이다. 1000개를 보내는 경우, 메시지를 전송하는데 0.01초, sleep 하는데 0.19초 정도 걸리며, 의도한대로 1초에 5번의 메시지를 전송하는 것을 확인할 수 있다. 반면, 100000개의 메시지를 보내는 경우, 메시지는 보내는데에 0.2초 이상이 걸리게 되면서 sleep 시간이 0이 되는 것을 확인할 수 있으며, 그 이상의 메시지를 전송하는 경우에는 전체 통신 과정이 타입슬롯을 넘어간다.
# sender_timeslot.py
#!/usr/bin/env python
import rospy
from std_msgs.msg import Int32
import time
rospy.init_node('sender_timeslot')
pub = rospy.Publisher('timeslot_topic', Int32, queue_size=0)
rate = rospy.Rate(5)
def pub_count(count):
for n in range(0, count):
pub.publish(n)
while not rospy.is_shutdown():
count = input("count: ")
rate.sleep()
total_time = time.time()
for _ in range(0, 5):
start_pub_time = time.time()
pub_count(count)
end_pub_time = time.time()
rate.sleep()
end_sleep_time = time.time()
print(("pub_time: ",
round(end_pub_time - start_pub_time, 4),
"sleep_time: ",
round(end_sleep_time - end_pub_time, 4)))
print("total: ", round(time.time() - total_time, 4))5. 의존성이 있는 node들을 순서대로 실행시킬 수 있는가?
의존성이 있는 node들 간의 실행 순서는 어떻게 동기화 시키는가 알아보자. 이를 확인하기 위해서 4개의 노드가 first - second - third - fourth로 순서대로 메시지를 전달 하는 과정을 가정했다.
# 파일 이름
first.py
second.py
third.py
fourth.py
receiver_order.py
order.launch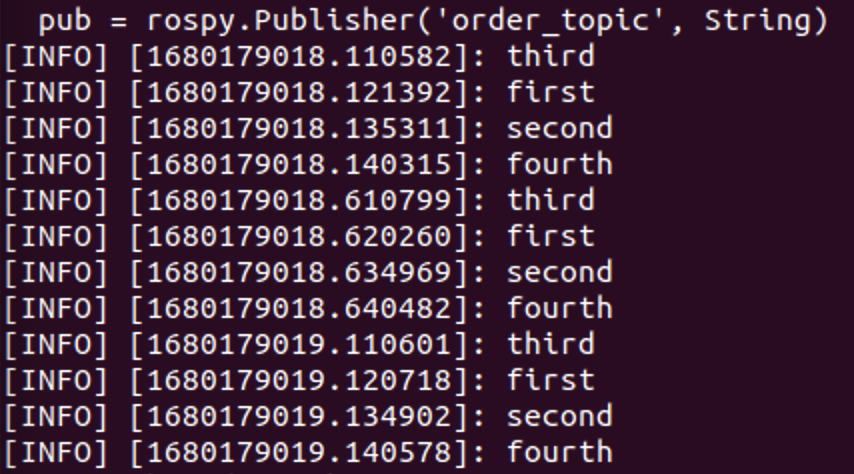
메시지 전달 순서를 보장하기 어렵다. 프로그램을 실행 시킬 때 마다 메시지의 전달 순서가 달라진다.
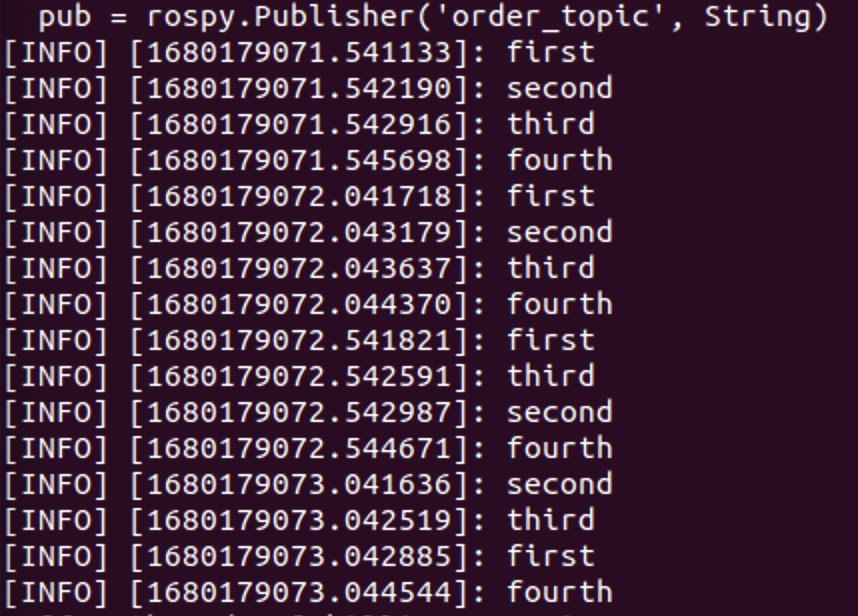
이러한 문제를 해결하기 위해서 receiver가 모든 노드가 실행되기를 기다렸다가 실행 순서대로 특정 플레그를 sender에게 전달한다. 실행 플레그를 받은 sender들은 순서에 따라 receiver에게 메시지를 전달하게 되면서, 위 그림과 같이 receiver가 순서대로 메시지를 받는것을 확인할 수 있다.
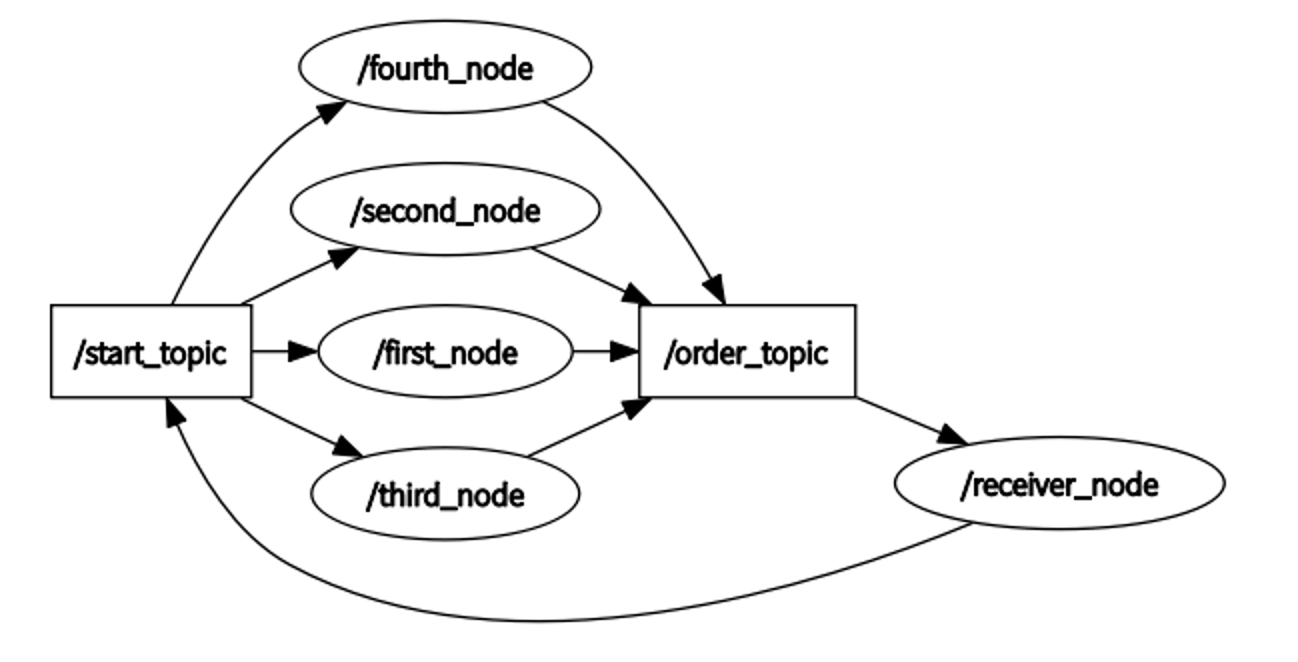
메시지는 전달 구조는 위 그림과 같다.
# receiver_order.py
#!/usr/bin/env python
import rospy
from std_msgs.msg import String
def callback(msg):
rospy.loginfo(msg.data)
rospy.init_node('receiver_order')
rospy.Subscriber('order_topic', String, callback, queue_size=4)
pub = rospy.Publisher('start_topic', String)
while not pub.get_num_connections() == 4:
pass
senders = ["first", "second", "third", "fourth"]
for sender in senders:
pub.publish(sender)
rospy.sleep(1)
# print(sender)
rospy.spin()# first, second, third, fourth.py
#!/usr/bin/env python
import rospy
from std_msgs.msg import String
name = "first"
is_start=False
def callback(msg):
print(msg.data)
if msg.data == name:
global is_start
is_start = True
rospy.init_node('sender_serial')
rospy.Subscriber('start_topic', String, callback, queue_size=4)
while True and not rospy.is_shutdown():
# rospy.sleep(0.5)
if is_start:
break
pub = rospy.Publisher('order_topic', String)
rate = rospy.Rate(2)
while not rospy.is_shutdown():
pub.publish(name)
rate.sleep()6. 수신하는 노드가 없으면 메시지 전송 속도가 빨라지는가?
토픽을 수신하는 노드가 없으면 메시지의 전송 속도가 빨라지는지를 확인한다.
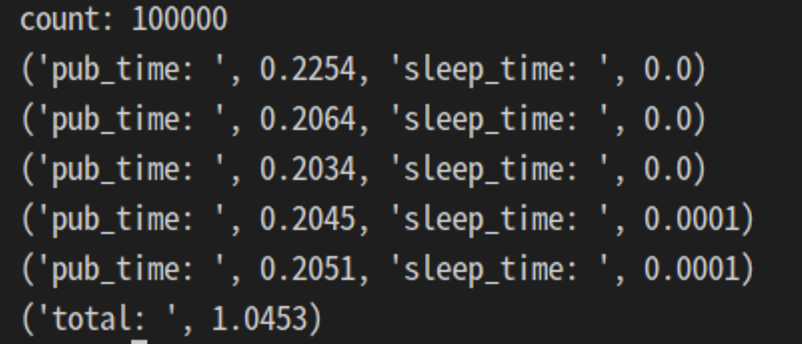
실험결과 토픽을 수신하는 노드가 없으면 메시지 전송 속도가 빨라지는 것을 확인할 수 있었다. 또한 queue_size를 늘려도 속도는 동일했다.
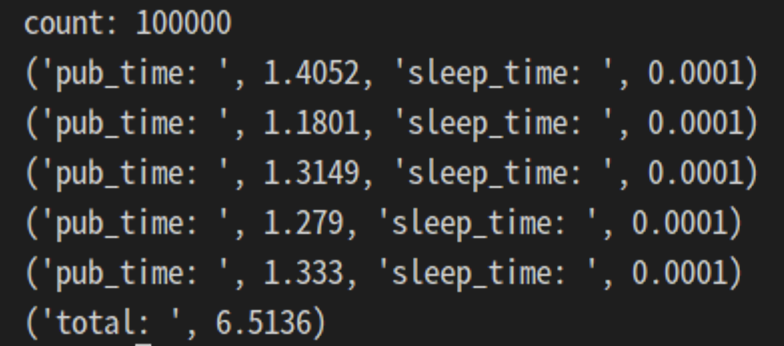
7. 토픽을 수신하는 노드의 수가 많아지면 메시지 전달 속도가 느려지는가?
토픽을 구독하는 노드의 수에 따른 메시지 전송 속도를 비교하였다.
- 토픽을 구독중인 노드가 1 개인 경우
count: 100000
('pub_time: ', 1.4052, 'sleep_time: ', 0.0001)
('pub_time: ', 1.1801, 'sleep_time: ', 0.0001)
('pub_time: ', 1.3149, 'sleep_time: ', 0.0001)
('pub_time: ', 1.279, 'sleep_time: ', 0.0001)
('pub_time: ', 1.333, 'sleep_time: ', 0.0001)
('total: ', 6.5136)- 토픽을 구독중인 노드가 2 개인 경우
count: 100000
('pub_time: ', 3.1562, 'sleep_time: ', 0.0001)
('pub_time: ', 3.2577, 'sleep_time: ', 0.0001)
('pub_time: ', 2.9082, 'sleep_time: ', 0.0001)
('pub_time: ', 2.8771, 'sleep_time: ', 0.0)
('pub_time: ', 2.943, 'sleep_time: ', 0.0)
('total: ', 15.1428)- 토픽을 구독중인 노드가 4 개인 경우
count: 100000
('pub_time: ', 8.6363, 'sleep_time: ', 0.0001)
('pub_time: ', 8.0214, 'sleep_time: ', 0.0001)
('pub_time: ', 8.7448, 'sleep_time: ', 0.0001)
('pub_time: ', 8.0193, 'sleep_time: ', 0.0)
('pub_time: ', 8.5715, 'sleep_time: ', 0.0001)
('total: ', 41.9938)위 실험의 결과로 구독중인 노드가 많은 경우 발행하는 노드의 메시지 처리 시간이 증가하는 것을 확인할 수 있었다. 이러한 경우 메시지 목적에 따라 발행 노드를 적절히 분리하는 것이 도움이 될 수 있다.
