
Machine Learning은 program의 performance를 given data, previous results 혹은 experiences를 이용해서 향상시키는 것
program의 성능을 개선을 시키기 위해 사람이 code를 typing을 해서 즉, 사람이 개입하는 것이 아니라 주어진 data 혹은 이전의 결과 혹은 이전에 했던 경험들을 활용을 해서, 그걸 기반으로 해서 자동적으로 program의 성능을 향상 시키겠다는 그러한 노력들, 또는 그러한 기법들에 해당이 됩니다.
머신러닝을 위해 Data에서 pattern을 찾을 때 valid 한 pattern이어야 하고 Noisy 한 엉뚱한 pattern을 찾아서는 안되며 novel 한 pattern을 찾아내야 됩니다.
또 understandable 한 pattern을 찾아내야 하고 찾아낸 data pattern을 해석하는 것도 이 Machine Learning에서 중요한 작업 중 하나라고 할 수 있겠습니다.

Machine Learning의 응용 분야는 굉장히 많습니다.
음성 인식, 얼굴 인식, 지문 인식, 홍채 인식, 그리고 Web-search, Documnet & information retrieval, 기계 번역, 추천, Credit card 오남용과 오사용 등 data 쌓이고 있는 모든 분야에서 기계학습은 사용되고 있습니다.
그리고 이렇게 많은 분야에 사용되는 여러 기계 학습은 pattern recognition, data mining, 인공지능, adaptive control, intelligent system과 같은 다른 여러 분야들과 겹쳐 있습니다.

기계학습이 풀고자 하는 문제를 개념적으로 나눠보면 몇 가지로 나눌 수 있습니다.
classification, regression, recommedation, clustering과 dimension reduction 등 입니다.

classification 문제들에 대해 살펴보겠습니다.
여기에 빨간 점(양품)과 까만 점(불량품)이 있습니다.
unknown data가 들어왔을 때 이것이 양품인지 불량품인지 예측하고 싶습니다.
즉, classification은 예측 기법입니다
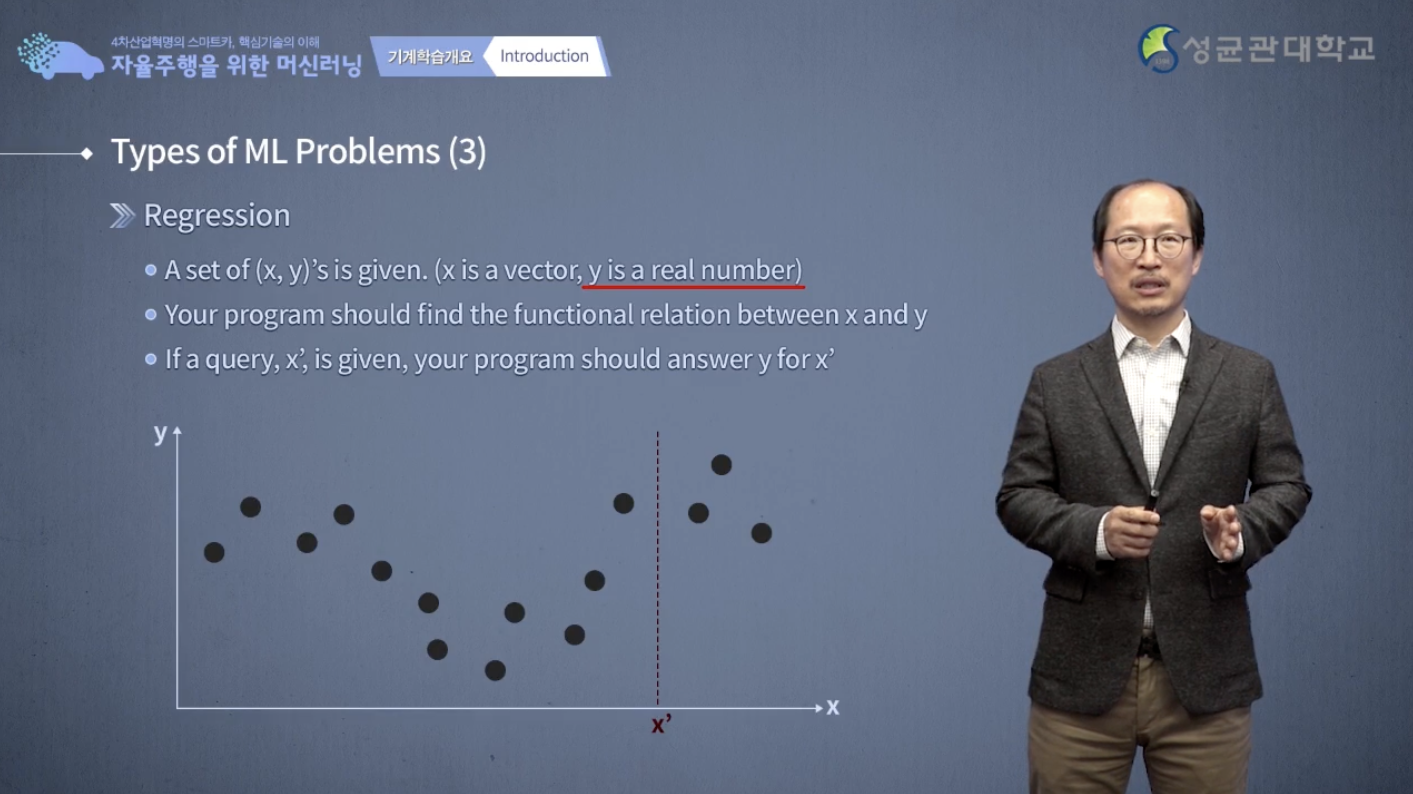
다음은 regression 문제입니다.
regression은 classification과 비슷하게 예측에 대한 겁니다.
그림에서 보시다시피 x는 입력이고, y는 출력입니다.
출력이라는 것은 바로 예측하고 싶은 값을 의미합니다.
과거의 data에서 x가 이 값일 때 y가 이 값이었고 x가 이 값이었을 때 y가 이 값이었고, x가 이 값이었을 때 y가 이 값이었다 라는 것을 사전에 수집해 놨습니다.
그리고 새로운 data x'이라고 봤을 때 이 x'에 대해서 y는 어떤 값을 가질까?
이렇게 예측하고 싶은 것, 예측하고 하고 싶은데 그 예측 대상이 real number 일 때는 그 문제를 regression이라고 부릅니다.
앞에서 classification 하고 차이는 예측하고 싶은 것이 classification에서는 양품이다, 불량품이다 였다면 regression은 예측하고 싶은 것이 real number 실수가 되는 것입니다.
그런데 양품을 1, 불량품을 0이라고 놓으면은 결국 classification도 real number를 예측하는 것입니다.
궁극적으로 classification과 regression은 사실 동일한 문제라고 인식해도 아무런 차이가 없습니다.
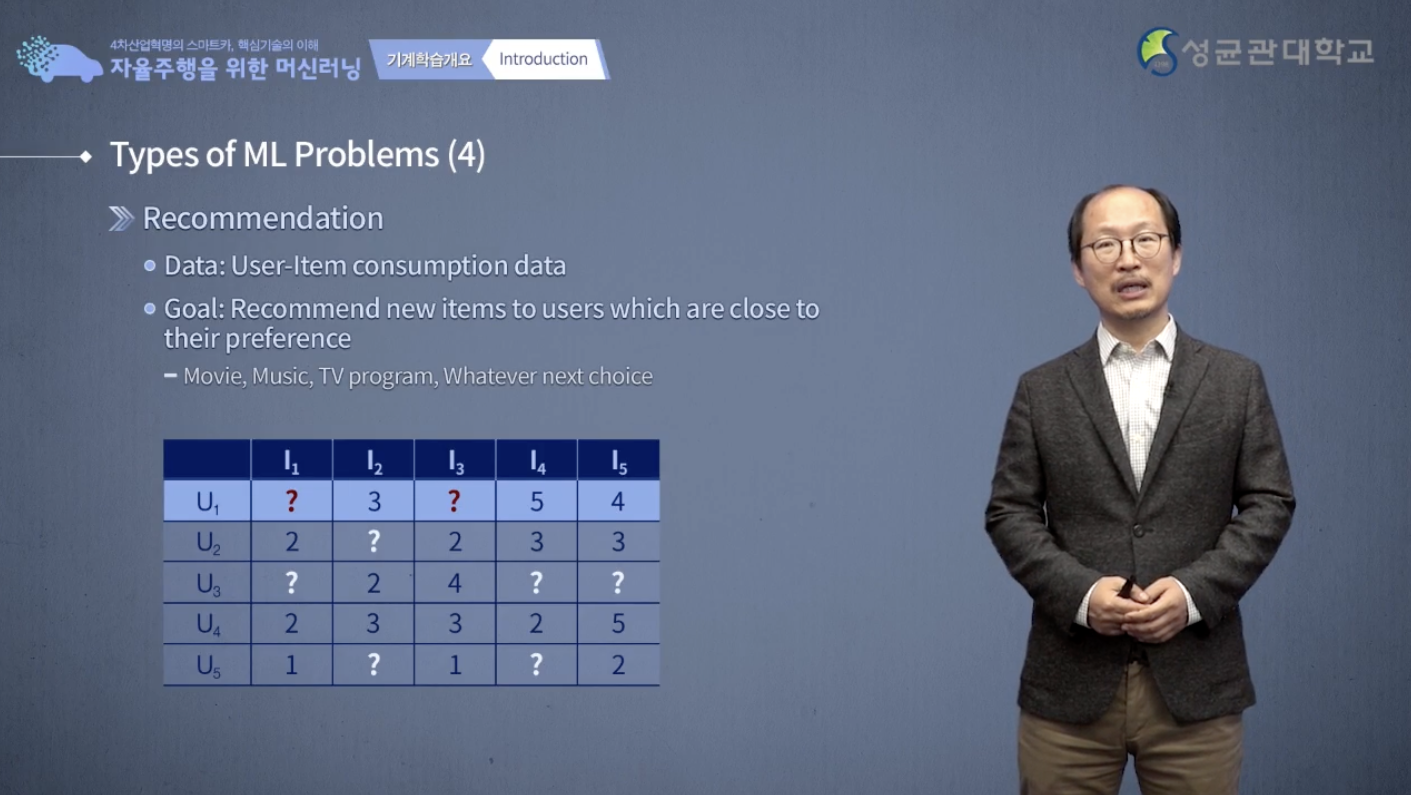
다음은 recommendation입니다.
예를 들면 여기 보시는 matrix와 같이 영화 온라인 서비스하는 회사에 근무한다고 생각을 해볼 수 있습니다.
I는 영화이고 U는 user입니다.
5명이 있는데, U1은 I2에서 3점을 줬고, I4에 대해서 5점을 줬고, I5에 4점을 줬습니다.
1, 3는 아직 보지 않았습니다.
자 U1 한테 어떤 영화를 추천을 하면 좋을까요?
추천은 잘해야 됩니다. 왜냐하면 추천이 엉터리다 라는 것을 사용자들이 알기 시작한 다음부터는 여러분 회사에 대한 신뢰도가 떨어지기 때문입니다.
이런 문제를 해결하고자 하는 것이 recommendation입니다.
또한 user가 있고, item이 있는데 user가 어떤 item을 사용을 했고, 어떤 item을 사용하지 않았을 때 그다음에 유저가 어떤 아이템을 사용하게 될 것인가? 그걸 예측하는 것, 알아내는 것이 바로 recommendation이라고 말할 수가 있습니다.
이것은 영화사가 아니더라도 쇼핑몰이 아니더라도 그 기법을 많은 곳에서 사용될 수가 있습니다.

다음 문제는 clustering 입니다.
지금까지 classification, regression, recommendation은 예측이었습니다.
하지만 clustering은 예측의 문제가 아닙니다.
data 자체에 대한 궁금증을 해석하기 위한 분석 기술입니다.
clustering은 주어진 data 내에 존재하는 data의 group을 말합니다.
예를 들면 지금 data같은 경우는 좌측에 있는 4개의 점과 가운데에 있는 5개의 점과 오른쪽에 있는 7개의 점이 이렇게 하나의 cluster로 묶여서 총 3개의 cluster가 될수 있습니다.

다음은 dimension reduction입니다.
data가 주어졌을 때 이 주어진 data의 차원을 축소하는 겁니다.
축소할 때 정보의 손실을 최소화시켜야 합니다.
위 그럼처럼 빨간 점들이 있을 때 이건 2차원 정보이지만 이것을 1차원으로 축소하고 이 축소된 정보가 원래 data와 비교해서 손실, 정보 손실은 좀 있지만 data의 경향성은 큰 차이가 없다는 걸 알 수가 있습니다.
이런 식으로 data 차원을 줄여서 내가 처리해야 되는 정보의 양을 줄이는 것, 그걸 dimension reduction이라고 부릅니다.
이 dimension reduction도 data 분석에서 굉장히 중요한 위치를 차지하고 최근 들어서 big data 시대가 되면서 훨씬 더 많이 요구가 되는 그러한 기법 중 하나입니다.
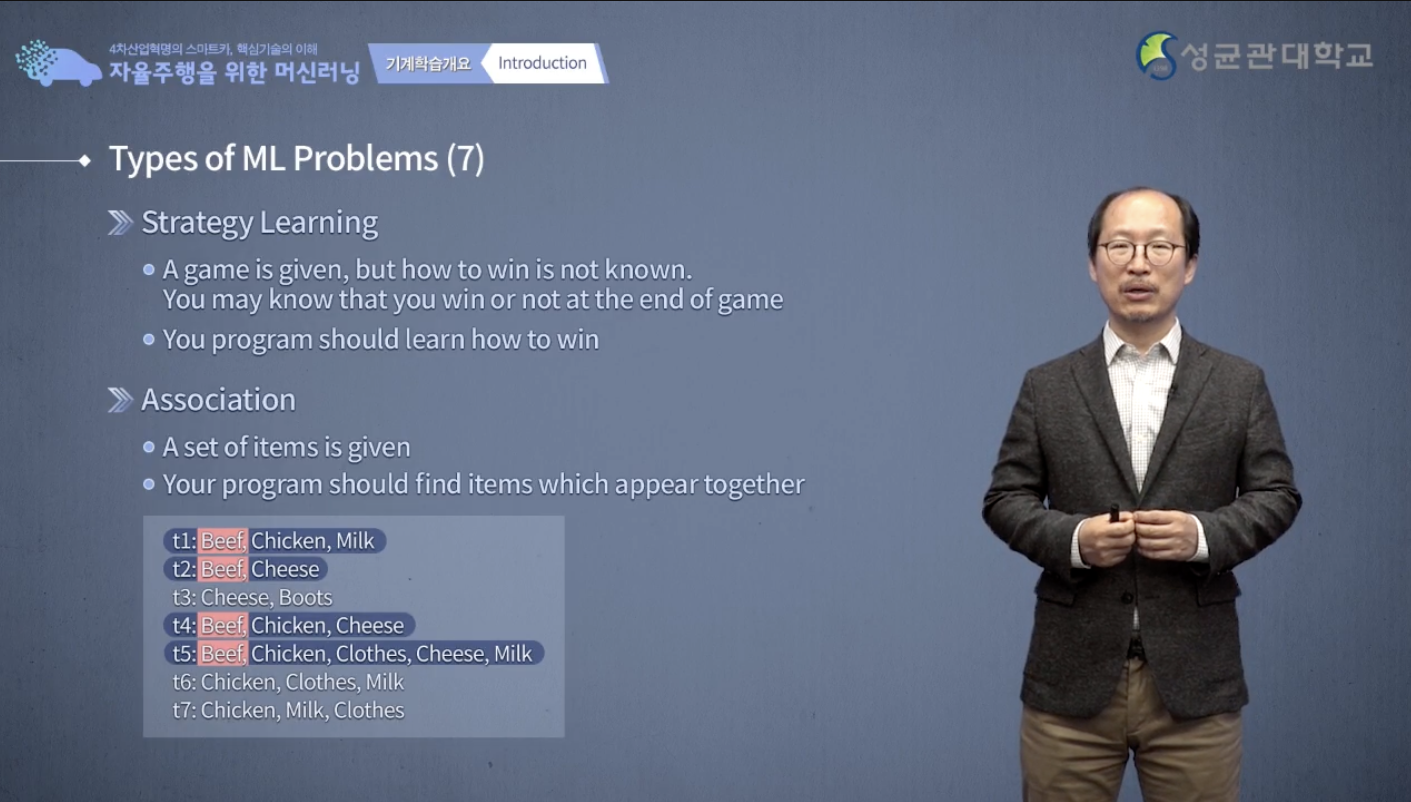
strategy learning이라는 것은 어떤 전략입니다.
내가 이 문제를 풀 때 어떻게 접근해 나가면 될까? reinforcement learning이라는 기법을 쓰면 바로 이 전략 strategy를 학습할 수가 있습니다.
그 외에도 association이라는 것이 있습니다.
예를 들어 다음 보시는 것과 같이 transaction1에는 beef, chicken, milk가 있고 transaction2에는 beef, cheese가 있고, transaction3에는 cheese, boots 이런 것들이 있을 때 beef, 소고기를 사가는 사람은 또 뭘 또 사갈까 궁금합니다.
왜냐하면 그런 association 뭘 사갈 때 뭘 사간다는 association을 알고 나면 여러분이 진열을 할 때 도움이 되기 때문입니다.
소고기 옆에 우유를 같이 놓는다든지 하면 매출이 조금 더 늘 수 있습니다.
이런 것처럼 어떤 item이 어떤 item과 같이 빈번히 자주 같이 나타난다라는 사실을 파악하고 싶다면 그건 바로 association을 찾고 싶어 하는 거고, 그런 association을 찾고 싶은 여러 기법을 사용하면 되겠습니다.

Machine Learning에서 문제들을 풀기 위해서 우리가 사용하는 방법들을 구분을 해 보면 다음처럼 supervised, semi-supervised, unsupervised, reinforcement learning 으로 이렇게 나눠볼 수가 있겠습니다.
대표적으로 classification과 regression을 해결 하고자 하는 방법들 대부분은 supervised learning입니다.
이 방법은 얘들이 뭐라고 예측을 했을 때 누군가가 이 예측과 맞았다, 이 예측과 틀렸다, 누군가가 알려줘야만 학습이 가능한 방법입니다.
unsupervised learning은 주로 예측이 아닌, data 분석하는 작업에 많이 사용이 됩니다.
data 분석이라는 것은 크게 2가지 목적이 있죠.
예측을 하기 위해서 분석을 하지만 이 data 자체를 이해 하기 위해서 평균이 얼마야, 분산이 얼마야처럼 자체의 이해를 하기 위해서 입니다.
그럴 때 data 자체를 이해하기 위한 분석을 하는 기법들은 대부분 unsupervised learning 을 사용합니다.
왜냐하면 우리가 clustering을 한다고 치면 우리 고객이 30대 여성이 많고, 40대 여성이 많고, 뭐 50대 여성이 많다 라는 사실은 분석을 했더니 얻어낸 거지, 그게 정답이냐 고 물어보면 모르기 때문입니다.
clustering 기법, dimension reduction 기법, asscociation을 찾는 그런 기법들이 대부분은 unsupervised learning 방식으로 개발이 되고 있습니다
그 다음에 semi-supervised learning은 supervised learning 과 unsupervised learning 사이에 있는 거라서 예를 들면은 어떤 data에 대해서는 내가 맞았는지, 틀렸는지 말해줄 수 있는데 어떤 data는 나도 말 못하는 경우에는 우리가 semi-supervised learning 기법을 사용해서 학습을 시키기도 합니다.
그 다음 reinforcement learning은 어떤 행동을 했을 때 그것에 대한 reward를 최대화하기 위해서는 어떻게 해야 될까? 이런 식으로 필요할 때 reinforcement learning 기법을 사용하기도 합니다.
