K-디지털트레이닝(빅데이터) 34일차
오늘은 네이버 api로 토픽분석 및 유투브 크롤링, 인스타 댓글 및 해시태크 크롤링을 했다.
- 패키지 로드
import os
import sys
import urllib.request
import json
import re
import konlpy
from konlpy.tag import Okt
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image- 다 합쳐서 하나의 함수로 만들어 놓은걸 가져온다.
#blog크롤링과 워드클라우드를 하나로 합친 함수
#나중에 이것만 호출하면 자동으로 된다.
def get_blog():
keyword = input('검색어를 입력하세요:')
client_id = "OKQPTGKiQf0V3yitzK6o"
client_secret = "uIGSvzveCB"
encText = urllib.parse.quote(keyword)
tlist = []
llist = []
dlist = []
for pagenum in range(1,1000,100):
try:
url = "https://openapi.naver.com/v1/search/blog?query=" + encText +"&display=100&sort=sim&start="+str(pagenum)# json 결과 블로그 1~100 101~200
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # xml 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
jtemp = response_body.decode('utf-8')
jdata = json.loads(jtemp)
jdata['items']
for temp in jdata['items']:
hangul = re.compile('[^ ㄱ-ㅎ|가-힣]+')
tdata = temp['title']
ldata = temp['link']
ddata = hangul.sub(r'',temp['description'])
tlist.append(tdata)
llist.append(ldata)
dlist.append(ddata)
else:
print("Error Code:" + rescode)
except:
print('Error')
result = []
for temp in range(len(tlist)):
temp1 = []
temp1.append(tlist[temp])
temp1.append(llist[temp])
temp1.append(dlist[temp])
result.append(temp1)
f = open('{0} - 네이버API 블로그검색.csv'.format(keyword) , 'w', encoding='utf-8')
f.write('제목'+',' + '링크' + ',' + '내용' + '\n')
for temp in result:
f.write(temp[0] + ',' + temp[1] + ',' + temp[2] +'\n')
f.close()
#여기서 결과를 리턴해줘야 쓸수있음
return result
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
def get_cafe():
client_id = "OKQPTGKiQf0V3yitzK6o"
client_secret = "uIGSvzveCB"
keyword = input('카페 검색어를 입력해주세요')
encText = urllib.parse.quote(keyword)
tlist = []
llist = []
dlist = []
for pagenum in range(1,1000,100):
try:
url = "https://openapi.naver.com/v1/search/cafearticle?query=" + encText +"&display=100&sort=sim&start="+str(pagenum)# json 결과 블로그 1~100 101~200
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # xml 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
jtemp = response_body.decode('utf-8')
jdata = json.loads(jtemp)
jdata['items']
for temp in jdata['items']:
hangul = re.compile('[^ ㄱ-ㅎ|가-힣]+')
tdata = temp['title']
ldata = temp['link']
ddata = hangul.sub(r'',temp['description'])
tlist.append(tdata)
llist.append(ldata)
dlist.append(ddata)
else:
print("Error Code:" + rescode)
except:
print('Error')
result = []
for temp in range(len(tlist)):
temp1 = []
temp1.append(tlist[temp])
temp1.append(llist[temp])
temp1.append(dlist[temp])
result.append(temp1)
f = open('{0} - 네이버API 카페검색.csv'.format(keyword) , 'w', encoding='utf-8')
f.write('제목'+',' + '링크' + ',' + '내용' + '\n')
for temp in result:
f.write(temp[0] + ',' + temp[1] + ',' + temp[2] +'\n')
f.close()
return result
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
def get_news():
client_id = "OKQPTGKiQf0V3yitzK6o"
client_secret = "uIGSvzveCB"
keyword = input('뉴스 검색어를 입력해주세요')
encText = urllib.parse.quote(keyword)
tlist = []
llist = []
dlist = []
for pagenum in range(1,1000,100):
try:
url = "https://openapi.naver.com/v1/search/news?query=" + encText +"&display=100&sort=sim&start="+str(pagenum)# json 결과 블로그 1~100 101~200
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # xml 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
jtemp = response_body.decode('utf-8')
jdata = json.loads(jtemp)
jdata['items']
for temp in jdata['items']:
hangul = re.compile('[^ ㄱ-ㅎ|가-힣]+')
tdata = temp['title']
ldata = temp['link']
ddata = hangul.sub(r'',temp['description'])
tlist.append(tdata)
llist.append(ldata)
dlist.append(ddata)
else:
print("Error Code:" + rescode)
except:
print('Error')
result = []
for temp in range(len(tlist)):
temp1 = []
temp1.append(tlist[temp])
temp1.append(llist[temp])
temp1.append(dlist[temp])
result.append(temp1)
f = open('{0} - 네이버API 뉴스검색.csv'.format(keyword) , 'w', encoding='utf-8')
f.write('제목'+',' + '링크' + ',' + '내용' + '\n')
for temp in result:
f.write(temp[0] + ',' + temp[1] + ',' + temp[2] +'\n')
f.close()
return result
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
#위에는 뉴스, 블로그, 카페 크롤링이고 밑에는 워드클라우드 부분
def get_tags(text, ntags=50):
spliter = Okt()
nouns = spliter.nouns(text)
count = Counter(nouns)
return dict(count.most_common(ntags))
def clean_str(s):
hangul = re.compile('[^ㄱ-ㅎ|가-힣]+')
s = hangul.sub(r' ',s)
cp = re.compile("["
u"\U00010000-\U0010FFFF"
"]+", flags=re.UNICODE)
s = cp.sub(r' ',s)
return s.strip()
def get_tagslists():
pass
def get_text(data):
result_text = ''
for temp in data:
result_text = result_text +' ' + temp[2]
return result_text
def Wordcloud(data , savename , maskname=''):
if maskname == '':
wc = WordCloud( font_path='font/BMEULJIROTTF.ttf' , background_color='white', max_font_size=60, colormap='copper')
else:
maskimg = np.array(Image.open(maskname))
wc = WordCloud(font_path='font/BMEULJIROTTF.ttf' , background_color='white', mask=maskimg, max_font_size=60, colormap='copper')
wc.generate_from_frequencies(data)
plt.figure(figsize=(20,10))
plt.imshow(wc)
plt.tight_layout(pad=0)
plt.axis('off')
plt.show()
wc.to_file(savename + ".png")- 블로그 크롤링을 해서 가져온다.
bdata = get_blog()# 여기를 블로그 대신 뉴스나 카페로 고치면 뉴스나 카페로 크롤링 가능
# rtext = get_text(bdata)
# rtags = get_tags(rtext, ntags=100)
# Wordcloud(rtags,'커피블로그')
result = []
# for temp in bdata:
# a = []
# a.append(temp[2])
# result.append(a)
# result
#결과를 저장
for temp in bdata:
result.append(temp[2])- 한국어 형태소 분석을 한다.
#한국어 형태소 분석기
spliter = Okt()
result_list = []
#리스트안에 넣기
for temp in result:
nouns = spliter.nouns(temp)
result_list.append(nouns)
result_list- 토픽분석
#gensim -> 토픽분석을 해준다.
# corpora는 단어에 숫자를 부여해서 변환해준다. 예를들어 카페 : 0 이렇게
#
import gensim
import gensim.corpora as corpora
dictionary = corpora.Dictionary(result_list)
corpus = []
#백터화
for temp in result_list:
corpus.append(dictionary.doc2bow(temp))
#여기서 출력을 하면 한 리스트 안에 어떤 단어들이 몇번 나왔는지 숫자로 매핑해준다.
corpus- 한글로보기
#이렇게하면 다시 한글로 보여줌
dictionary.token2id- 학습
k = 10 #토픽의 갯수
#core로 학습을 시킨다.
#passes => corpus 데이터에서 모델을 학습시키는 빈도
#튜닝하는게 중요하다.
lda_model = gensim.models.ldamulticore.LdaMulticore(corpus, iterations=12, num_topics = k, id2word=dictionary, passes=1, workers=10)
#토픽과 단어와의 관계를 뽑아낸다.
#토픽에서 단어가 미치는 영향력을 나타낸다.
print(lda_model.print_topics(num_topics=k, num_words=15))- 시각화
import pyLDAvis.gensim_models as gensimvis
import pyLDAvis
pyLDAvis.enable_notebook()
#토픽으로 학습을 시키고 처리를한다.
lda_vis = gensimvis.prepare(lda_model, corpus, dictionary)
pyLDAvis.display(lda_vis)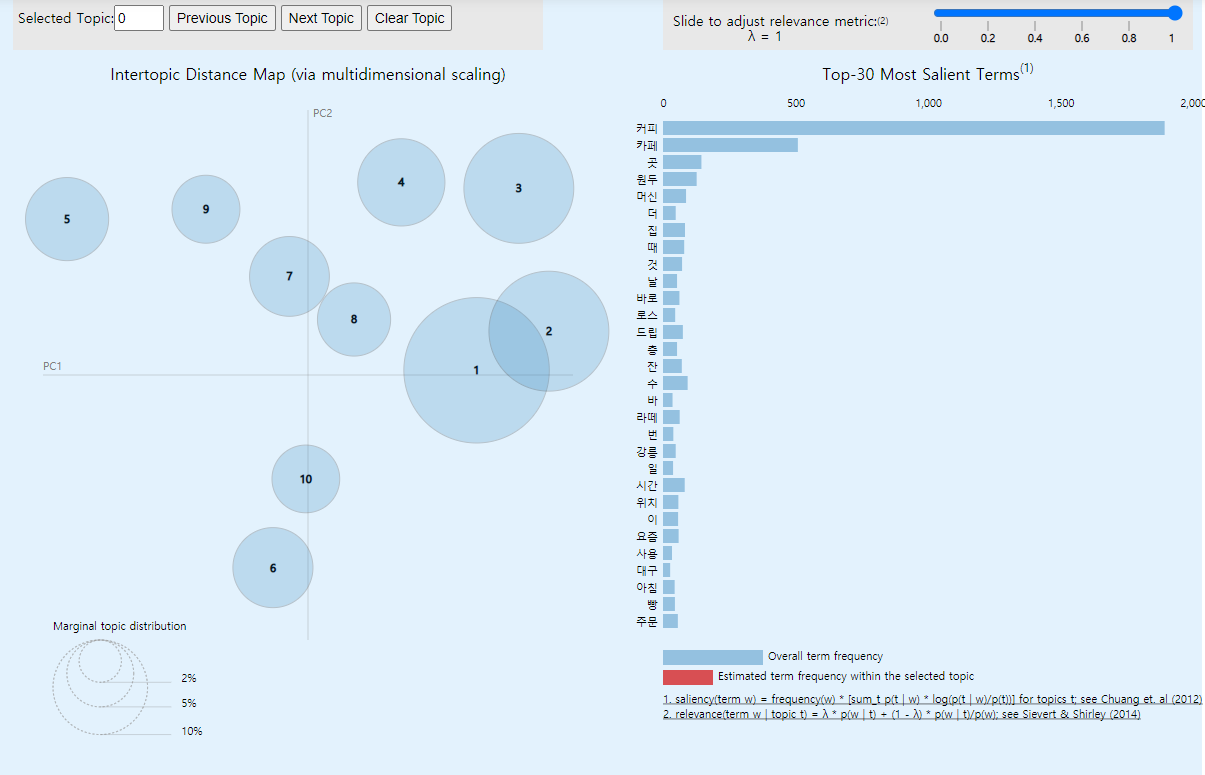
유튜브 크롤링
- 패키지 불러오기
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import time
from bs4 import BeautifulSoup
import csv- 검색어 입력받기
keyword = input('검색어를 입력하세요 :')- 전체화면으로 만들기 및 주소 접속
#방법1
#옵션
options = Options()
options.add_argument('--start-fullscreen')
#풀스크링 방법 2
#driver.maximize_window()
#드라이버를 로드할 때 옵션 같이 넣어준다.
driver = webdriver.Chrome('chromedriver.exe', chrome_options=options)
#열릴 떄 까지 1초 대기시킨다
driver.implicitly_wait(1)
#접속
driver.get('https://www.youtube.com/')
#3초대기
time.sleep(3)- 검색하고 엔터
# id가 search인걸 찾고
e = driver.find_element_by_id('search')
#누른다.
e.click()
#안에 아까 입력한 keyword값을 넣고
e.send_keys(keyword)
#엔터를 누른다.
e.send_keys(Keys.ENTER)
time.sleep(2)- 필터에서 동영상을 클릭한다.
# 글자로 찾는다. 필터라는 글자를 클릭해라
e = driver.find_element_by_link_text('필터')
e.click()
time.sleep(1)
# 글자로 찾는데 동영상이라는 글자를 클릭
e = driver.find_element_by_link_text('동영상')
e.click()
time.sleep(1)- 페이지를 내려준다.
#몸체 전체를 스크롤 해야하기때문에 body를 찾는다.
body = driver.find_element_by_tag_name('body')
#페이지를 3번 내려준다.
for i in range(0,3):
body.send_keys(Keys.PAGE_DOWN)
time.sleep(1)- 내용 가져오기
#여기서부터는 내용 가져오기
html = driver.page_source
soup = BeautifulSoup(html,'lxml')
titledata = soup.find_all('a',{'id' : 'video-title'})
title_result_list = []
for temp in titledata:
title_result_list.append(temp.attrs['title'])- 썸네일 저장하기
#썸네일로 클릭해서 들어갈 수 있기때문에 썸내일을 받아온다.
thumbnail = driver.find_elements_by_tag_name('ytd-video-renderer')
result = []
f = open('{0} - 유튜브댓글.csv'.format(keyword) , 'w', encoding='utf-8')
f.write('제목'+',' + '내용' + '\n')- 썸네일을 꺼내와서 클릭하고 스크롤을 내려 댓글을 크롤링한다.
#썸내일 주소를 하나씩 꺼내온다.
for temp in thumbnail:
try:
tresult_list = []
#썸네일을 클릭한다.
temp.click()
time.sleep(2)
#이것도 스크롤 내릴라고 하는거임
tbody = driver.find_element_by_tag_name('body')
#원래는 끝까지 해야함
#이것도 스크롤
for temp1 in range(0, 1):
tbody.send_keys(Keys.PAGE_DOWN)
time.sleep(1)
#나머지는 댓글 찾는거
html = driver.page_source
soup = BeautifulSoup(html,'lxml')
rdata = soup.find_all('yt-formatted-string',{'id':'content-text'})
#ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ댓글
#이건 제목 찾기
tdata = soup.find('h1',{'class':'title style-scope ytd-video-primary-info-renderer'})
ttitle = tdata.text
#제목 저장
replytext = ''
for temp in rdata:
replytext = replytext + temp.text + ' '
tresult_list.append(ttitle)
tresult_list.append(replytext)
result.append(tresult_list)
f.write(ttitle + ',' + replytext +'\n')
except:
print('오류')
driver.back()
f.close()
#driver.back()
result- 형태소 분석 및 워드클라우드
#이거로 형태소 분석이랑 워드클라우드 해보기
import os
import sys
import urllib.request
import json
import re
import konlpy
from konlpy.tag import Okt
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
def get_tags(text, ntags=50): #태그를 나눈다. 태그란? 각 글자를 의미
#기본값을 50으로 설정해준다. ntags는 단어수를 의미한다.
spliter = Okt() #Open Korean Text -> 한국어 분석기
nouns = spliter.nouns(text) # 명사로 나눈다
count = Counter(nouns) #명사의 갯수를 센다.
return dict(count.most_common(ntags)) # 딕셔너리형태로 갯수를 반환해준다.
def clean_str(s): #특수기호와 영어를 제거해준다.
hangul = re.compile('[^ㄱ-ㅎ|가-힣]+')
s = hangul.sub(r' ',s)# 띄어쓰기를 넣어줘야 띄어쓰기가 되서 나온다.
cp = re.compile("["
u"\U00010000-\U0010FFFF"
"]+", flags=re.UNICODE) #이건 영어 제거였나 그럼
s = cp.sub(r' ',s)
return s.strip() #쓸데없는거 지우고 리턴해준다.
#####워드클라우드
def Wordcloud(data , savename , maskname=''):
#워드클라우드는 폰트가 중요하다. 왜냐하면 보여지는게 중요하기때문
if maskname == '':
wc = WordCloud( font_path='font/BMEULJIROTTF.ttf' , background_color='white', max_font_size=60, colormap='copper')
else:
maskimg = np.array(Image.open(maskname)) #마스크(사진)이 있으면 불러오고 그에 맞게 만들어준다.
wc = WordCloud(font_path='font/BMEULJIROTTF.ttf' , background_color='white', mask=maskimg, max_font_size=60, colormap='copper')
#여기서부터는 시각화 부분이라 몰라도되고 그냥 가져다 쓰자
wc.generate_from_frequencies(data)
plt.figure(figsize=(20,10))
plt.imshow(wc)
plt.tight_layout(pad=0)
plt.axis('off')
plt.show()
wc.to_file(savename + ".png")
textdata = ''
#크롤링해서 나온 데이터를 하나로 합쳐주는 역할,,, 이어쓰기? 라고 보면될듯
for temp in result:
textdata = textdata + ' ' + temp[1]
#2번이 description 그니까 설명 부분이다. 강사님은 설명부분 가져다씀
tresult = get_tags(textdata)
print(tresult)
tresult = get_tags(textdata,ntags=200)
Wordcloud(tresult,'유투브')
#위에서 정의해준 함수를 보면 된다.... 커피블로그는 사진이 만들어지는 이름
인스타 크롤링
- 불러오기
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import time
from bs4 import BeautifulSoup
import csv
import urllib
#만약 ssl 오류생기면
# import ssl
# ssl._create_default_https_context = ssl._create_unverifled_context- 검색어 입력
keyword = input('검색어를 입력하세요 : ')-
크롬브라우저 실행 후 30초정도를 기다리게 한다.
url = 'https://www.instagram.com/explore/tags/'+str(urllib.parse.quote(keyword)) +'/'
driver = webdriver.Chrome('chromedriver.exe')
driver.implicitly_wait(1)
driver.get(url)
#30초안에 로그인하고 검색으로 들어가
time.sleep(30) -
첫 번째 사진 클릭
#이건 제일 처음 사진 클릭하는거
driver.find_element_by_class_name('eLAPa').click()
time.sleep(2)- 태그 찾기
for temp in range(0,5):
html = driver.page_source
soup = BeautifulSoup(html,'lxml')
#이거로 해시태그 찾는다.
rdata = soup.find_all('a',{'class':' xil3i'})
for temp1 in rdata:
print(temp1.text)
#.string도 있음
#다음 클릭해주면 다음으로 넘어간다.
driver.find_element_by_link_text('다음').click()
#여기서 랜덤으로 시간주는게 좋음
time.sleep(2)
smilegate