오늘은 SNA 분석을 했다.
- 패키지 불러오기
import os
import sys
import urllib.request
import json
import re
import konlpy
from konlpy.tag import Okt
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import networkx as nx
plt.rc('font',family='NanumBarunGothic')
%matplotlib inline- 만들어놓은 함수 가져오기
#blog크롤링과 워드클라우드를 하나로 합친 함수
#나중에 이것만 호출하면 자동으로 된다.
def get_blog():
keyword = input('검색어를 입력하세요:')
client_id = "OKQPTGKiQf0V3yitzK6o"
client_secret = "uIGSvzveCB"
encText = urllib.parse.quote(keyword)
tlist = []
llist = []
dlist = []
for pagenum in range(1,1000,100):
try:
url = "https://openapi.naver.com/v1/search/blog?query=" + encText +"&display=100&sort=sim&start="+str(pagenum)# json 결과 블로그 1~100 101~200
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # xml 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
jtemp = response_body.decode('utf-8')
jdata = json.loads(jtemp)
jdata['items']
for temp in jdata['items']:
hangul = re.compile('[^ ㄱ-ㅎ|가-힣]+')
tdata = temp['title']
ldata = temp['link']
ddata = hangul.sub(r'',temp['description'])
tlist.append(tdata)
llist.append(ldata)
dlist.append(ddata)
else:
print("Error Code:" + rescode)
except:
print('Error')
result = []
for temp in range(len(tlist)):
temp1 = []
temp1.append(tlist[temp])
temp1.append(llist[temp])
temp1.append(dlist[temp])
result.append(temp1)
f = open('{0} - 네이버API 블로그검색.csv'.format(keyword) , 'w', encoding='utf-8')
f.write('제목'+',' + '링크' + ',' + '내용' + '\n')
for temp in result:
f.write(temp[0] + ',' + temp[1] + ',' + temp[2] +'\n')
f.close()
#여기서 결과를 리턴해줘야 쓸수있음
return result- 검색하기
blogdata = get_blog()- 리스트에 검색결과 담기
blogdata_list = []
for temp in blogdata:
blogdata_list.append(temp[2])- 태그 분석
#korean pos tags comparison chart 에서 Tag 찾아서 분석하면된다.
from konlpy.tag import Komoran
def tag_contents(contents):
tag_result = []
#안에있는 기능쓰려고 객체로 만들어줌
ma = Komoran()
for temp in contents:
ma_content = ma.pos(temp)
tag_result.append(ma_content)
return tag_result
ma_result = tag_contents(blogdata_list)
ma_result- 필터와 불용어 사전을 만들어준다.
FILTER = ['NNG','NNP','XR']
STOPWORD = ['으로','어요','니다']
def tag_result_select(ma_result,FILTER,STOPWORD):
tag_result_list = []
for temp in ma_result:
text_result = []
for temp1, temp2 in temp:
if temp2 in FILTER and temp1 not in STOPWORD:
text_result.append(temp1)
tag_result_list.append(text_result)
return tag_result_list
tdata = tag_result_select(ma_result,FILTER,STOPWORD)- 갯수를 세어준다.
from collections import Counter
from itertools import combinations
# for temp in combinations(['정동','길','카페','커피'],2):
# print(temp)
word_count = Counter()
def word_matrics(tdata):
for temp in tdata:
for word1, word2 in combinations(temp,2):
if len(word1) == 1 or len(word2) == 1:
continue
if word1==word2:
continue
elif word_count[(word1,word2)] >=1 :
word_count[(word1,word2)] += 1
else:
word_count[(word1,word2)] = 1
return word_count
wresult = word_matrics(tdata)- 갯수를 튜플안에 넣어준다.
graphdata = []
for temp in wresult:
data = (temp[0], temp[1], wresult[temp])
graphdata.append(data)
graphdata- 정렬해준다.
def count_key(t):
return t[2]
graphdata.sort(key=count_key)
graphdata.reverse()
graphdata- sna분석
def sna_graph(word_data, NETWORK_MAX):
G = nx.Graph()
i = 0
#edgr 생성
for word1, word2, count in word_data:
i += 1
if i > NETWORK_MAX: break
G.add_edge(word1,word2,weight=count)#가중치
#MST모델 생성
T = nx.minimum_spanning_tree(G)
nodes = nx.nodes(T)
degrees = nx.degree(T)
#노드 사이즈
node_size = []
for node in nodes:
ns = degrees[node] * 100
node_size.append(ns)
#그래프로 표현
plt.figure(figsize=(15,10))
nx.draw_networkx(T,
pos = nx.fruchterman_reingold_layout(G,k=0.5),
node_size = node_size,
node_color = 'yellow',
font_family='NanumBarunGothic',
with_labels=True,
font_size = 12
)
plt.axis('off')
plt.show()
sna_graph(graphdata, 50)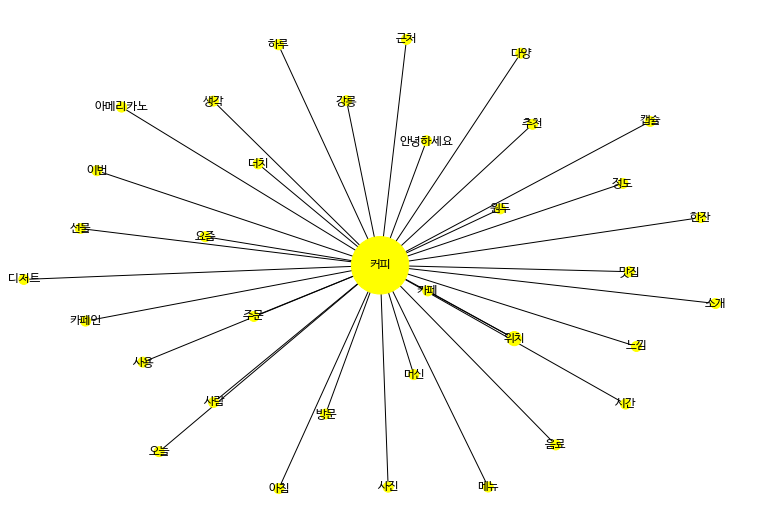

smilegate