인턴 과제
1.과제 이해
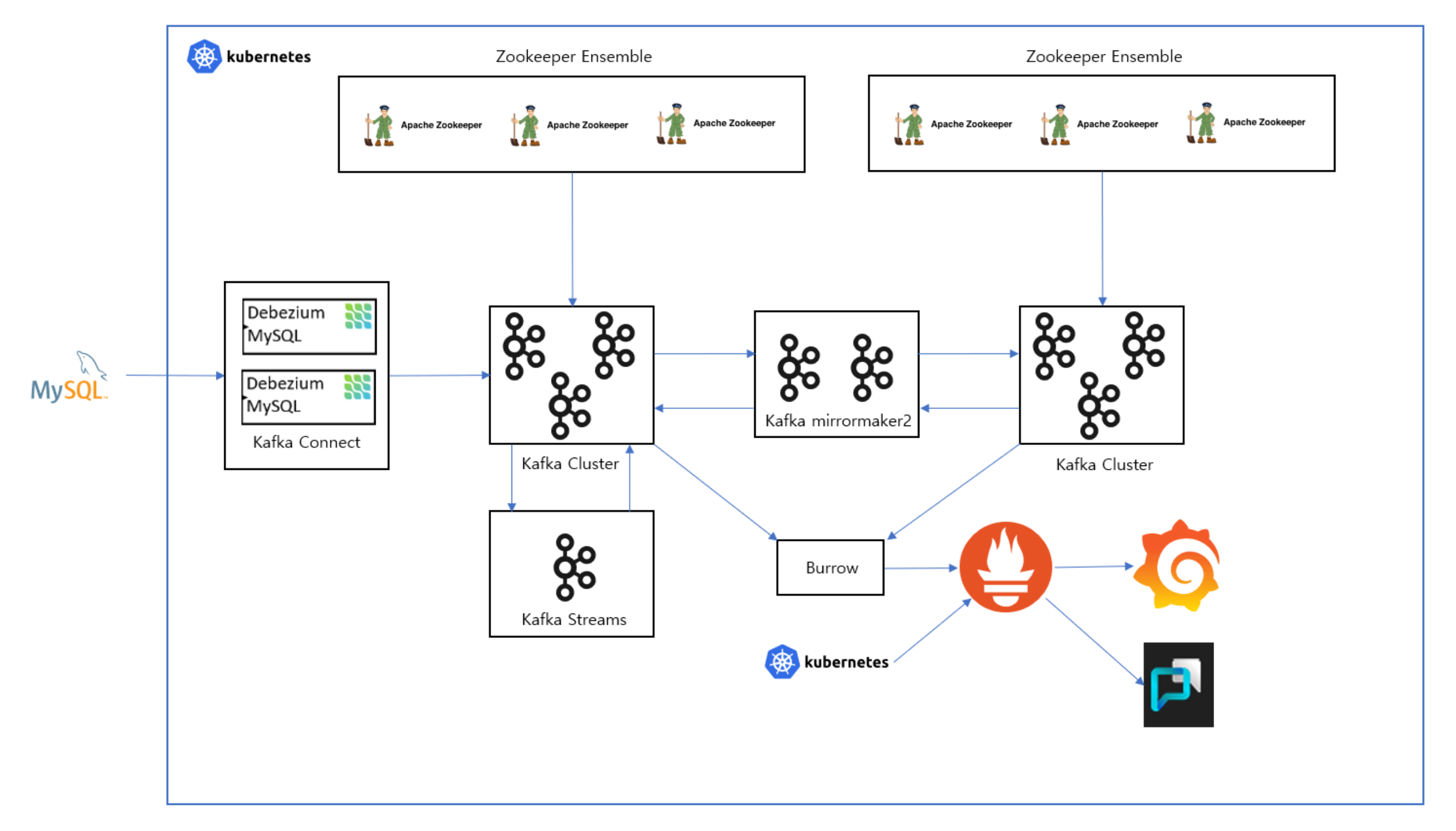
쿠버네티스를 사용하지 않고 ec2 만 사용하면 scale in/out을 수동으로 해야 함.쿠버네티스를 이용하여 자동으로 scale in/out 및 각종 장애 상황 대응namespace 생성하여 관리mysql에 실시간으로 데이터 넣으면서 데비지움, 스트림, 미러메이커 테
2.도커 컴포즈로 카프카 실행

docker 설치docker-compose 설치docker-compose파일 작성컨테이너에 접속sudo docker exec -it kafka1 /bin/bash토픽 생성kafka-topics.sh --create --bootstrap-server kafka1:9092
3.모르는 용어들
스테이트풀셋애플리케이션의 상태를 저장하고 관리하는 데 사용되는 쿠버네티스 객체.기존의 포드를 삭제하고 생성할 때 상태가 유지되지 않는다.스테이트풀셋으로 생성되는 포드는 영구 식별자를 가지고 상태를 유지시킬 수 있다.헤드리스 서비스쿠버네티스 서비스 생성 시 .spec.c
4.ubuntu에 쿠버네티스 설치 & 마스터, 워커 노드 설정

설치 초반 따라하기 -> 삭제 -> 노드 구성 -> 만약 container 실행중이 아니라고 하면 재실행 링크
5.앞으로의 계획
ec2 인스턴스로 마스터 노드, 워커 노드 설정주키퍼 앙상블 쿠버네티스로 실행카프카 쿠버네티스로 실행데비지움 쿠버네티스로 실행미러메이커2를 이용하여 프로듀서, 컨슈머 클러스터 분리내가 이해한거로는 프로듀서가 클러스터1의 토픽에 데이터를 보내면 미러메이커2를 이용하여 컨
6.statefulset을 위한 pv
문제는 직접 만들어야 한다는 점... 자동 생성 방법을 찾아야겠다.
7.zookeeper - 권한
zookeeper.yaml에 이렇게 설정하니 mkdir: cannot create directory '/var/lib/zookeeper/data': Permission deniedchown: cannot access '/var/lib/zookeeper/data': No
8.statefulset zookeeper 클러스터 구축
이건 쿠버네티스 공식문서에서 친절하게 설명해준다.링크replicas에서 설정한 수 만큼 생성현재 영구 볼륨이 노드에 존재하기 때문에 노드가 다운되면 볼륨 유지가 안된다.추후에 동적 프로비저닝 사용 예정
9.statefulset kafka 클러스터 구축
KAFKA_ADVERTISED_LISTENERS에서 막혀서 일주일을 고생했는데 쿠버네티스 자체에서 podIP를 받을 수 있다. 환경 변수를 삽입해주면 해결!!aws loadbalancer 서비스 이용 예정
10.kafka broker 종료 테스트
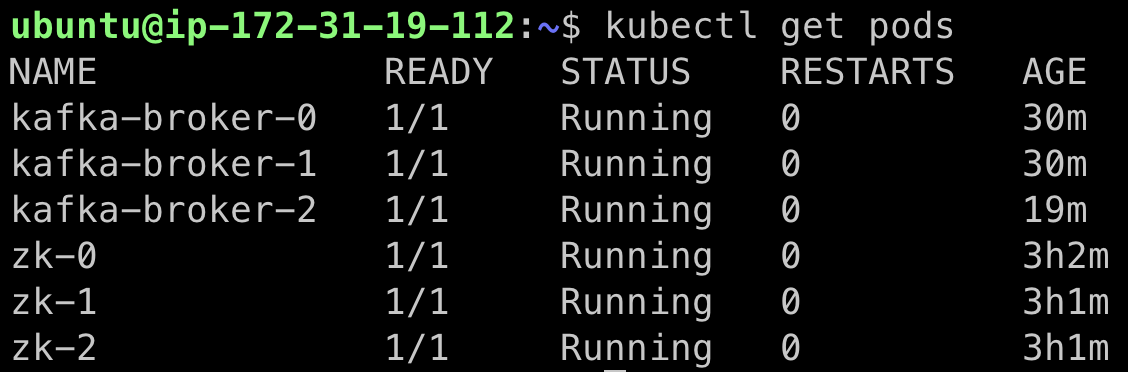
kafka의 broker pod를 중단하면 재기동이 되는데 기동 후에 토픽의 데이터가 남아있는지 확인.kubectl get podskubectl delete pods kafka-broker-1데이터가 그대로 남아있다!!!!
11.쿠버네티스에 카프카 커넥트 and debezium 구축
debezium에서 만든 이미지를 사용했다. 환경 변수 설정하는 데서 시간을 오래 잡아먹었는데 처음에는 s CONNECT\_를 앞에 붙여야 하는 줄 알았는데 알고 보니 빼고 써야 했다.statefulset으로 구성을 했다.bootstrap_servers -> 여기에 자
12.카프카 커넥터 생성
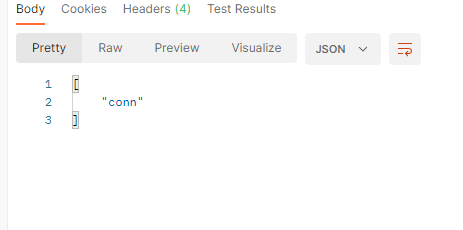
이렇게 rest 요청을 전송한다.curl -X GET podIP:8083/connectorscurl -X GET podIP:8083/connectors/connectorname/status정상적으로 받아진다.
13.미러메이커2
의문 다른 카프카 클러스터끼리 같은 주키퍼 앙상블을 사용해도 될까? 테스트 해보니 두 클러스터 모두 같은 토픽이 만들어졌다. 이걸 보아 다른 주키퍼로 해야하나?
14.Kafka Producer Application
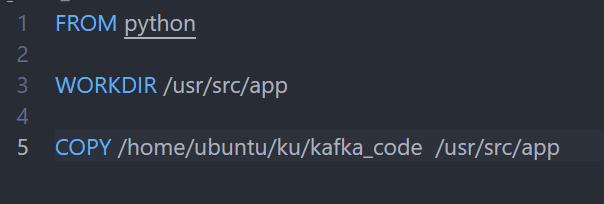
python 파일을 python 이미지 안에 넣어서 이미지를 직접 만들었다.→ copy 안됨해결 방법파일을 직접 copy해서 해결.pip install kafka를 하게되면 아래와 같은 오류가 생긴다.따라서 pip install kafka-python으로 해결간단하게
15.kafka stream application

앞에서 만들었던 1부터 9999까지 숫자를 넣는 걸 이용.홀수인 숫자만 다시 토픽으로 넣는 스트림 애플리케이션을 개발 예정추후에 데이터 정해지면 해당 데이터에 맞게 개발 예정