Unicode(유니코드)
- 전 세계의 모든 문자를 다루도록 설계된 표준 문자 전산 처리 방식
- 사용 중인 운영체제, 프로그램, 언어에 관계없이 문자마다 고유한 값을 제공
- 자바는 모든 문서를 유니코드로 처리함
- 아스키코드의 한계성을 해소할 수 있는 체계로 만들어진 코드
- Unicode Consortium에서 제정, 관리함
- 유니코드 문자의 경우 해당 글자의 코드를 표기할 때 U+(16진수 숫자)로 씀
ex)'가' : U+AC00 - 한글을 그대로 전송하면 깨지기 때문에, 한글을 유니코드 값으로 인코딩시켜서 전송하고 받는 쪽에서는 받은 유니코드 값을 다시 한글로 디코딩하여 사용함
Unicode Transformation Format - 8bits(UTF-8)
UTF-8의 부호단위는 1바이트이다. 변환 과정은 그만큼 더 복잡하지만, 대신 데이터의 낭비가 줄어든다는 장점이 있다. 변환된 결과값은 1바이트부터 4바이트까지의 가변길이이다.
| 16진수 부호점 | 2진수 UTF-8 |
|---|---|
| U+0000 ~ U+007F | 0xxxx xxxx |
| U+0080 ~ U+07FF | 110x xxxx 10xx xxxx |
| U+0800 ~ U+FFFF | 1110 xxxx 10xx xxxx 10xx xxxx |
| U+10000 ~ U+10FFFF | 1111 0xxx 10xx xxxx 10xx xxxx 10xx xxxx |
유니코드를 한글로 표현하는 법
U+AC00 ~ U+D7A3까지의 부호점들은 한글 음절을 나타내며, 이 부호점을 통해 한글을 조합하여 사용할 수 있다.
((초성) 588 + (중성) 28 + (종성)) + 44032
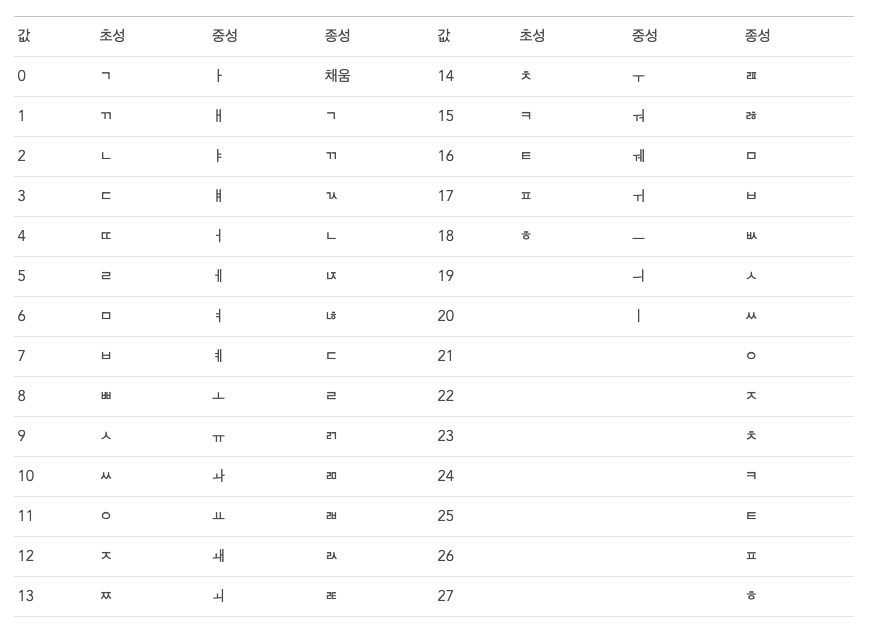
ex)'한' : (18 588 + 0 28 + 4) + 44032 = U+D55C
JAVA에서 변환
- 변환할 문자를 저장할 buffer 생성
- 모든 글자를 탐색하며 앞 2글자가 '\u'인 경우 추출
- '\u'뒤의 네자리수는 16진수이므로, 16진수를 10진수로 변환
- 변환한 10진수를 char 형으로 변환하여 단일문자로 만들어줌
- buffer에 넣음
- i를 5 만큼 증가시켜 다음 '\u'로 이동
1import com.choikang.chukahaeyo.common.Decode;
import lombok.extern.log4j.Log4j;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import org.springframework.test.context.web.WebAppConfiguration;
@Log4j
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes = {config.MvcConfig.class})
@WebAppConfiguration
@Slf4j
public class DecodeTest {
@Test
public void getDecode() {
String a = Decode.unicodeDecode("\\uc548\\ub155\\ud558\\uc138\\uc694");
System.out.println("decode:" + a);
}
}

컴퓨터가 이해하는 코드는 바보도 작성할 수 있다. 사람이 이해하도록 작성하는 프로그래머가 진정한 실력자다. -마틴 파울러