왜 그렇게 다들 대규모 트래픽 거리는가
이력서, 자소서, 경력사항, 지원자격, 선호 경험 등에 써 있는 대규모 트래픽, 대용량 트래픽, 부하에 강한 서버 설계 등등등... 개발자라면, 특히 서버 개발자라면 이 대규모 트래픽 처리에 목을 메고 있는 것을 쉽게 발견할 수 있다.
그러면 대규모 트래픽 처리는 왜 중요한가?
대학 수강 신청 경험이 있다면 아마 한 번 쯤은 수강 신청 후 결과가 10분 뒤에 나오거나, 그도 아니면 페이지를 표시할 수 없다는 에러 화면을 본 경험이 있을 것이다.
이는 순간적으로 수많은 요청이 서버에 몰림으로써 서버가 그 모든 요청을 다 수용하지 못했기 때문에 발생하는 일이다.
이렇게 서버가 사용자의 요청을 제대로 소화해내지 못하면 사용성, 가용성이 떨어지게 되고 사용자로 하여금 불편함과 불쾌감을 느끼게 할 수 있다.
대학 수강 신청이라면 이는 큰 문제가 아닐 수 있다. 물론 학생들 입장에서는 불편해 뒤지겠지만, 사용자가 포기하지 않고 계속해서 재요청을 보내기 때문이다. 지들이 수강 신청 안하면 어쩔건데 ㅋㅋ
하지만 동일 상품을 제공하는 경쟁자가 버젓이 존재한다면 고객 이탈이라는 뼈아픈 손해로 이어질 수 있다.
당장 나만 해도 그런 경험이 있다.
나는 원래 네이버 페이가 포인트를 쌓아주기 때문에 그걸 주로 썼는데,
어느날 결제를 하려는데 네이버 페이가 자꾸 에러를 반환하는 것이었다.
2~3번 재시도를 해보았지만 계속 해결이 안되어서 토스 페이로 바꿔서 해봤더니 됐다.
그래서 그 이후에는 해당 어플의 기본 결제 수단을 토스 페이로 바꾼 채로 내비뒀었다.
그런데 또 어느날 토스 페이도 에러를 반환하는 것이었다.
그래서 이번에는 재시도도 하지 않고 카카오 페이로 바꿔서 결제를 했더니 또 됐다. 이때, 네이버 페이로 바꿔서 시도해 볼 수도 있었지만, 지난 번의 실패 경험이 있었기에 우선순위에서 밀렸다.
그래서 지금은 기본 결제 수단으로 카카오 페이를 사용하고 있다.
나 같은 놈이 1명이면 기업 입장에서도 큰 문제는 없을 것이다. 1명이 이리저리 왔다갔다 한들, 뭐 그리 큰 영향을 끼치겠나.
하지만 나 같은 놈이 한 1만 명쯤 된다면? 서버가 한 번 터지는 것으로 1만 명이 영구히 이탈해버린다면? 생각만 해도 아찔할 것이다.
그렇기 때문에 대규모 트래픽 처리는 경쟁사가 많은 업종 일수록 목을 메고 해결해야 하는 과제라고 할 수 있겠다.
그래서 서버는 왜 터짐
대규모 트래픽 처리가 중요한 이유가 서버가 터졌을 경우에 잠재적인 고객 이탈 문제가 있기 때문이라는 것을 알았다.
그러면 서버를 안 터지게 하면 우선 급한 불은 끌 수 있을 것 아닌가.
서버를 안 터지게 하려면? 일단 서버가 터지는 이유를 알아야 할 것이다.
서버라는 것은 결국 외부로부터 들어오는 요청을 받아 처리해주고 응답을 주는 프로그램이 돌아가고 있는 어느 컴퓨터이다.
그 말은 즉, 서버 또한 그 처리 속도와 한계가 CPU, 메모리, 저장장치에 영향을 받는다는 소리다.
웹 서버라는 프로세스가 있다면, 그 프로세스 안에는 다수의 요청을 시분할 처리하기 위한 스레드들이 있다.
스레드 수가 아무리 많아 봐야 결국 task를 처리하는 것은 cpu이기 때문에 처리 속도에는 명백한 한계가 있다.
메모리 오버플로우
또한 모든 task를 동시에 처리할 수는 없기 때문에 결국 task들을 큐에 넣어 순차적으로 처리하게 되는데, 이 큐는 대체 어디에 존재하는 걸까? 바로 메모리다.
즉, 요청을 들어오는 족족 무식하게 큐에다가 쑤셔박다 보면 메모리 오버플로우가 날 수 있다는 말이다.
웹 서버라는 것은 결국 프로그램인데 메모리 오버플로우가 나면? 종료가 되겠지. 그렇게 터지는 거다.
하지만 이런 일은 거의 없을 것이라고 생각한다. 웹 서버를 맨땅에서부터 만들어서 사용한다면 또 모르겠지만, 보통은 tomcat 같이 이미 만들어진 것을 사용할테니까.
(물론 tomcat은 웹 서버라기보단 웹 컨테이너 내지는 WAS라고 하는게 정확하겠지만, 그런 terminology는 글의 주제와 전혀 상관이 없으므로 그냥 대충 부르겠다)
메모리 오버플로우 이슈가 핸들링 되었다면, 또 어떤 부분에서 server failure가 발생할 수 있나?
큐 오버플로우
아래는 Tomcat의 요청 수락/처리와 관련된 그림이다.
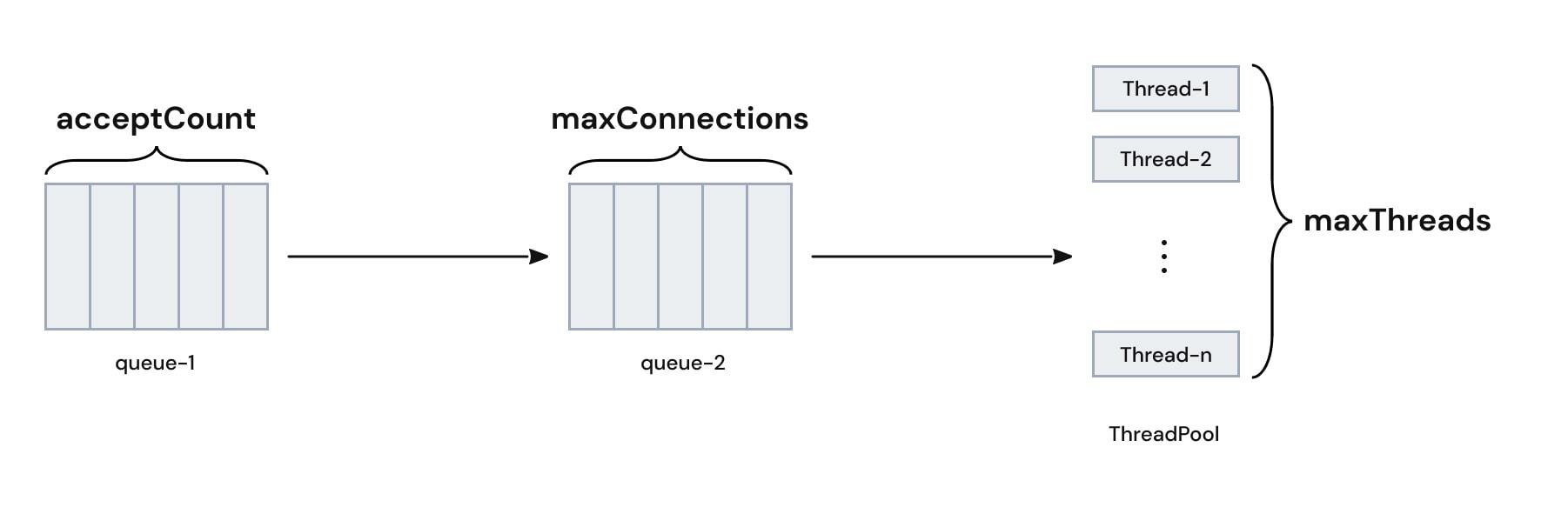
각각의 요소는 다음을 의미한다.
- maxThreads : 동시에 일하는 스레드의 최대 개수이다.
- maxConnections : 하나의 Tomcat 인스턴스가 동시에 유지할 수 있는 Connection의 최대 개수이다.
- acceptCount : maxConnections를 초과하는 요청에 대한 대기큐의 크기이다.
각 속성의 자세한 설명에 대해서는 아래 글을 읽어보자
https://bcho.tistory.com/788
일단 정석적인 설명을 했으니, 언제나 그렇듯 내 멋대로 뜻을 풀어보겠다.
maxThreads는 사실 별로 풀어서 쓸 게 없다. 일하는 놈이 몇이나 있나 이거고, 얘가 작으면 그만큼 전체 일을 처리하는데 오래 걸린다. 예를 들어 1000개의 요청을 보낼 때, maxConnections가 1000, maxThreads가 1이라고 해보자. 요청을 전부 받아서 처리는 하겠지만, 한 놈이 1000개의 요청을 일일이 처리해야하므로 오지게 오래걸린다.
maxConnections는 받아서 처리를 할 예정이지만 아직 처리되지 않은 요청들의 큐라고 할 수 있을 것 같다. 처리 중인 요청도 있고, 처리 대기 중인 요청도 있는데 이 처리 대기 중인 요청에는 Keep Alive를 통해 일부러 연결을 유지시킨 요청도 포함되어 있다.
acceptCount는 maxConnection의 개수를 넘어가는 추가 요청들을 몇 개까지 가지고 있을거냐고 정의하는 부분이다. 이 큐에도 요청이 들어가지 못하는 상황이라면 먼저 들어간 요청들이 처리되지 않고 있다 -> 문제 상황이 발생했을 확률이 높다는 뜻이므로 운영체제에서 요청을 거부한다.
그렇게 요청이 거부될 경우 사용자 입장에서는 서버가 터졌구나 싶은 응답을 받게 된다.
타임아웃
요청에는 대개 타임아웃이 설정되어 있다. 보낸 요청이 처리될 때까지 언제까지고 기다릴 수는 없으므로 일정 시간이 지나면 실패로 간주해버리는 것인데, 서버가 다른 요청들을 처리하느라고 바빠서 그 이후에 들어온 요청들을 타임아웃이 걸릴 때까지 처리하지 못 할 경우, 사용자 입장에서는 역시 서버가 터졌나 싶은 응답을 받게 된다.
그럼 어떻게 해야 안 터짐
서버가 터지는 이유는 결국 아직 처리되지 못한 요청이 쌓이고 쌓이고 쌓여서 그렇게 되는 것이므로, 단순히 생각해 요청을 충분히 빠르게 처리하면 된다.
이때 2가지 방법으로 해결책을 모색할 수 있다.
scale-out
처리하는 놈 (서버)를 물리적으로 늘려버리는 경우다. 업무를 1명이 할 때 보다는 2명이, 2명이 할 때 보다는 3명이 하는 게 더 빠른 게 당연하잖은가.
이 방법으로 해결을 하려고 할 때 고려해야 할 것은 업무의 배분이다.
모든 업무 (요청)이 동일한 처리 시간을 요구하지는 않기 때문에 어떤 요청은 보다 많은 처리 시간이 필요하고, 어떤 요청은 그렇지 않을 것이다.
이때, 특정 서버에 장시간의 처리가 필요한 요청이 쏠리면 해당 서버만 터지게 될 것이고, 운 없게도 해당 서버로 요청을 보내게 된 사용자들은 불편하고 불쾌한 경험을 하게 될 것이다.
이런 문제를 해결하기 위한 기술이 로드밸런싱이다
남은 큐의 크기, 이미 축적된 요청들의 예상 처리 시간 (특별한 시스템에서만 측정 가능하다) 등을 고려해 최적의 서버로 요청들을 분배해 특정 서버에만 부하가 가중되는 것을 방지할 수 있다.
scale-up
처리하는 놈을 더 강하게 만들어버릴 수도 있다.
들어오는 공 (요청)을 앞으로 던져버리는 게 업무라고 한다면, 팔이 2개 일 때에는 한 번에 2개씩 밖에 처리를 못하지만 팔이 6개 쯤 되면 한 번에 6개씩 처리가 가능해진다.
그런데 컴퓨터의 전투력을 규정하는 것은 결국 데이터 처리 속도이다.
문제는 컴퓨터가 단 하나의 부품으로 만들어지는 게 아니기 때문에 파트에 따라 이 속도가 다르다는데 있다.
CPU, 메모리, 기억장치. 이 중 무엇이 결과적으로 데이터 처리 속도를 규정할까?
바로 기억장치이다.
엥? 컴퓨터의 머리통은 CPU 아닌가? 라고 할 수 있다.
그 말은 맞다. 하지만 데이터를 영속적으로 처리하기 위해서는 결국 기억장치를 통해 데이터를 읽고/쓰는 작업이 필요하다.
그렇기에 아무리 CPU의 연산 속도가 뛰어나도 기억장치의 I/O 속도가 거북이 같다면 요청의 처리 속도도 거북이가 될 수 밖에 없다.
물론, 이 이론에는 예외가 있을 수 있다.
ML의 모델 트레이닝 등의 경우에는 기억장치로부터 데이터를 읽고 -> 최종적으로 기억장치에 모델을 쓰는 과정 사이에 어마어마한 양의 연산이 들어간다.
이런 경우에는 CPU와 메모리의 처리 속도가 더 중요할 수 있다.
하지만, 이런 작업의 경우에는 애초에 더럽게 오래걸린다는 것을 개발자 뿐만 아니라 엄마, 아빠, 삼촌, 누나, 형, 언니, 동생, 옆집 강아지, 윗집 고양이까지 모두 알고 있기 때문에 사용자의 요청으로 해당 작업을 수행하는 경우는 특별한 서비스가 아닌 이상 드물고, 그렇기에 대규모 트래픽과는 별 연관이 없는 경우가 많다.
그렇기 때문에 대규모 트래픽 처리를 위한 scale-up을 고려하는 경우 기억장치의 처리 속도 업그레이드를 고려해야 한다.
구체적인 해결책이 뭐임
기억장치 성능 향상
기억장치의 처리 속도를 업그레이드 하려면 어떻게 해야 할까?
동일한 종류의 기억장치 중에서 그나마 나은 것으로 변경할 수도 있겠지만,
기억 장치의 종류 그 자체를 변경할 수도 있다.
HDD를 SSD로 바꾸거나, 혹은 아싸리 메모리로 바꿔버리거나.
DB의 세계에는 In-memory Database라는 필살기가 존재한다.
인메모리 DB의 대표격으로는 Redis와 Memcached가 있다.
이 둘의 대표적인 사용처는 캐싱인데, 캐싱이 반복적으로 요청되는 특정 데이터에 대한 Read 비용 감소를 목적으로 하고 있다는 것을 생각하면, 캐싱 또한 대규모 트래픽 처리의 한 부분이라는 것을 알 수 있다.
하지만 캐싱만으로는 한계가 있다. 왜냐면 이 친구는 DB의 정보를 읽어오는 것만을 빠르게 해주기 때문이다.
예를 들어, 선착순 발매 쿠폰의 개수처럼 계속해서 변경이 되어야 하는 정보라면?
변경된 개수는 어쨌거나 계속해서 기록이 되어야 한다. 허술하게 서버용 프로그램 내 전역 변수 등으로 관리하다가 도중에 이런저런 문제가 발생해서 서버가 진짜로 내려가 버리면?
쓰기 동작이 실행되기 전에 데이터가 날아가버렸기에 도대체 얼마나 소모가 되었는 지 알 수가 없고, 이는 회사로 하여금 큰 손해를 입게 할 수도 있다.
그렇기 때문에 서버와는 별개로 메모리를 사용하면서 데이터를 DB마냥 조작할 수 있는 인메모리 DB가 다시금 필요해지게 된다.
인메모리 DB를 사용할 경우, 어쨌거나 메모리를 사용하는 것이기 때문에 데이터의 영속성 처리에 주의를 기울여야 한다. 그렇지 않으면 아차하는 순간 데이터가 모조리 날아갈 수 있다.
많은 회사들이 Redis를 선호하는 이유에 이 영속성 처리도 한 몫하고 있다고 보는데, Redis는 Replica를 통해 데이터를 복제해 Master에 장애가 발생해 사용이 불가능해진다고 해도 데이터 자체는 남게 되기 때문이다.
데이터가 남아 있기에 동작 중인 Replica 중 하나를 Master로 승격시키고, 기존 Master는 복구를 시도한 후 Replica로 강등시켜 버리면, 기존의 Master 또한 새 Master를 통해 데이터가 갱신되므로 전체적으로 데이터의 영속성과 지속성에 문제가 없게 된다.
다만, 이 데이터 복제 부분이 비동기로 이루어지기 때문에 이 부분에 대한 문제가 조금 있기는 하지만 이 글의 주제와는 관련이 없으므로 여기서 다룰 내용은 아닌 듯 하다.
I/O 큐의 성질 변화
아무래도 메모리는 조금 비싸다. 그런 이유로 인메모리 DB를 사용하기가 조금 꺼려질 수도 있다.
혹은 정말 아주 잠시만 트래픽이 폭주하는 것 뿐이라, 잠시 뒤에는 통상 트래픽으로 돌아올 것이기에 굳이 인메모리 DB까지는 필요하지 않아도 판단할 수도 있다.
요청에 대한 처리가 단순 CRUD에 가까울 수록 기억장치의 처리 속도에 영향을 크게 받는다고 했다.
그러면, DB에 기록하는 부분만 잠시 미룰 수는 없을까?
CPU와 메모리를 이용해 데이터를 처리하는 부분은 충분히 빠를테니 말이다.
그럴 때 사용할 수 있는 게 메세지 큐이고, 이 메세지 큐의 대표격이 RabbitMQ이다.
RabbitMQ와 Kafka가 종종 비교되곤 하는데, 이 둘이 소화해 낼 수 있는 일은 비슷한 게 맞고, 여기서 RabbitMQ를 통해 하려는 일을 Kafka로 할 수 있기도 하다. 하지만 이 둘은 사용 목적이 다르고, 분류가 다르고, 이 글에서는 MQ에 대해 말하고 있으므로 Kafka에 대해서는 생략한다.
그리고 개인적으로 consumer가 DB 하나 뿐이기도 하고, 만약 DB에 기록되는 순서를 신경 쓸 필요가 있다면 RabbitMQ가 더욱 적격이라고 생각한다.
RabbitMQ vs Kafka에 대해서는 아래 글을 읽어보자
https://www.cloudamqp.com/blog/when-to-use-rabbitmq-or-apache-kafka.html
https://betterprogramming.pub/rabbitmq-vs-kafka-1779b5b70c41
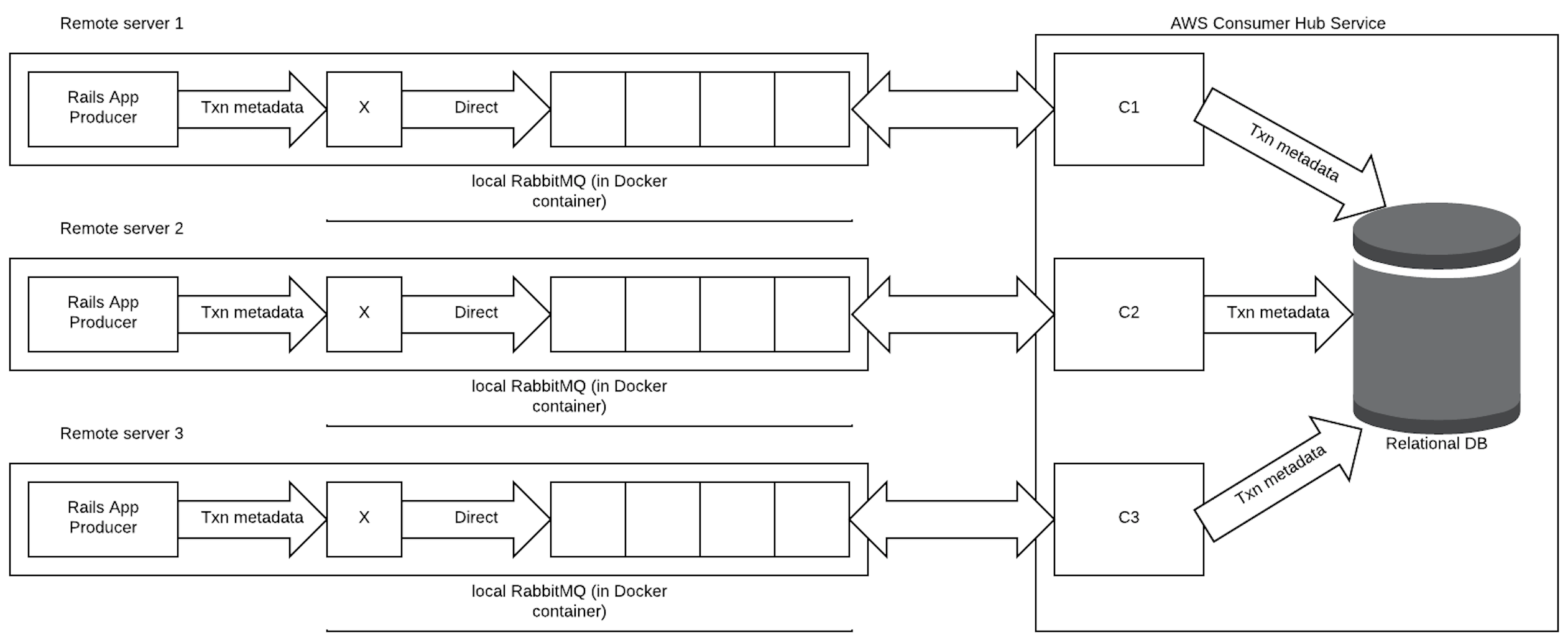
위와 같이 DB 앞에 MQ를 두게 된다면, 사용자의 요청에 대한 응답은 DB에 실제로 넣지 않았지만, 넣어질 것이라고 가정한 상태에서 할 수 있게 된다.
즉, 실저장이라는 하나의 스탭을 생략하고 응답을 하게 되므로 각 요청에 대한 응답 시간이 짧아지게 되는 것이고, 이는 곧 총 처리 시간의 감소라고 볼 수 있게 되는 것이다.
총 처리 시간이 감소해 요청이 들어오는 속도만큼 빨리지거나 이보다 더 빨라진다면, 요청이 쌓일 일이 없어 서버가 안정적으로 동작하게 된다.
References
- Apache Tomcat Tuning (아파치 톰캣 튜닝 가이드): https://bcho.tistory.com/788
- When to use RabbitMQ or Apache Kafka: https://www.cloudamqp.com/blog/when-to-use-rabbitmq-or-apache-kafka.html
- RabbitMQ vs. Kafka: Head-To-Head: https://betterprogramming.pub/rabbitmq-vs-kafka-1779b5b70c41
