
1.개요
1)등장 배경
- LinkedIn에서 2011년 파편화된 데이터 수집 및 분배 아키텍쳐를 운영하는 데 어려움을 겪었다. 데이터를 생성하고 적재하기 위해서는 데이터를 생성하는 소스 애플리케이션 과 데이터가 최종 적재되는 타켓 애플리케이션이 연결되어야 했다. 초기 운영을 할 때는 단방향 통신을 이용해서 소스 코드를 작성했는데 이 당시에는 아키텍처가 복잡하지 않았기 때문에 운영이 힘들지 않았지만 아키텍처가 점점 복잡해지고 소스 애플리케이션 과 타겟 애플리케이션의 개수가 늘어나면서 문제가 발생
- 소스 애플리케이션 과 타겟 애플리케이션을 연결하는 파이프라인의 개수가 늘어나면서 소스 코드 및 버전 관리에서 이슈가 발생하기 시작했고 타겟 애플리케이션에 장애가 발생할 경우 그 영향이 소스 애플리케이션에 그대로 전달 - 강한 결합의 문제점
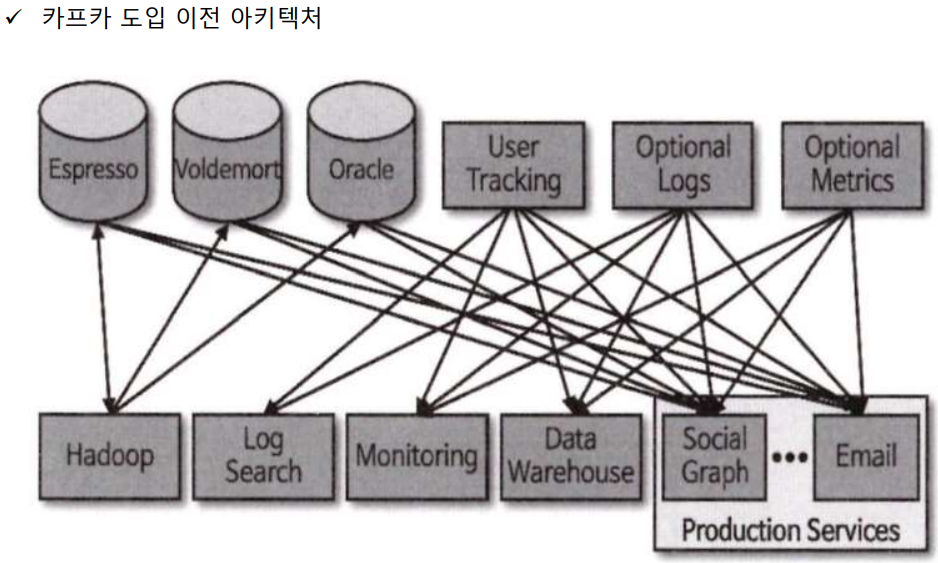
- 초창기에는 다양한 메세지 플랫폼 과 ETL(Extract Transform Load) 툴을 적용해서 아키텍처를 변경하려고 노력을 했는데 파편화된 데이터 파이프라인의 복잡도는 낮추는 아키텍처를 만드는 데는 실패
- LinkedIn의 데이터 팀은 새로운 시스템을 만들려고 했는데 그 결과물이 Apache Kafka
2)해결책
- 각각의 애플리케이션끼리 연결해서 데이터를 처리하는 것이 아니고 한 곳에 모아 중앙 집중화 방식으로 처리
- 카프카를 이용해서 웹 사이트, 애플리케이션, 센서 등에서 취합한 데이터 스트림을 한 곳에 모아서 관리
- 카프카는 대용량 데이터를 수집하고 이를 사용자들이 실시간 스트림으로 소비할 수 있게 만들어주는 애플리케이션
- 카프카를 중앙에 배치해서 소스 애플리케이션 과 타겟 애플리케이션 사의 의존도를 최소화 함
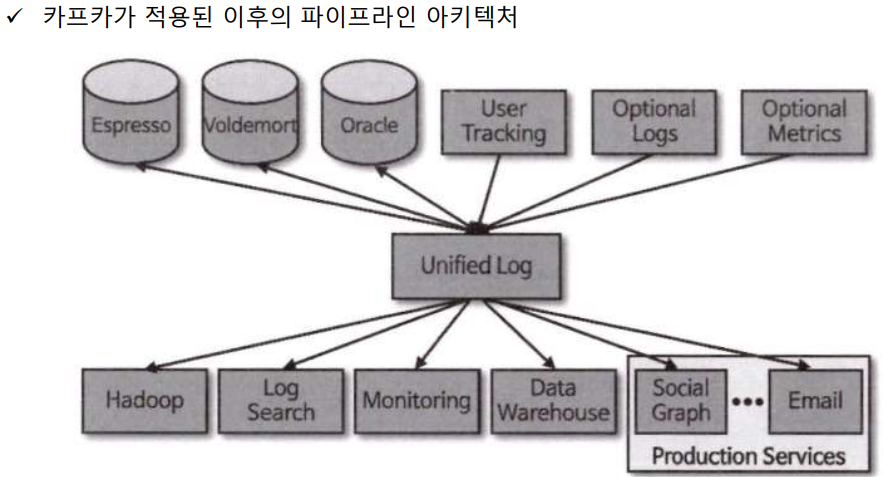
- 소스 애플리케이션은 어느 타겟 애플리케이션으로 데이터를 보낼 것인지 고민하지 않고 카프카로 넣으면 되고 카프카 내부에 데이터가 저장되는 파티션은 FIFO(First In First Out)의 형태로 동작
- 큐에 데이터를 보내는 동작은 프로듀서가 하고 큐에서 데이터를 가져가는 것은 컨슈머가 수행
3)데이터 포맷
- 제한 없음
- 자바에서 사용 가능한 모든 객체는 사용할 수 있는데 직렬화(객체 단위로 데이터를 전송할 수 있도록 해주는 것 - Serializable 인터페이스나 Parceable 인터페이스를 구현한 객체) 와 역직렬화를 이용
4)구성
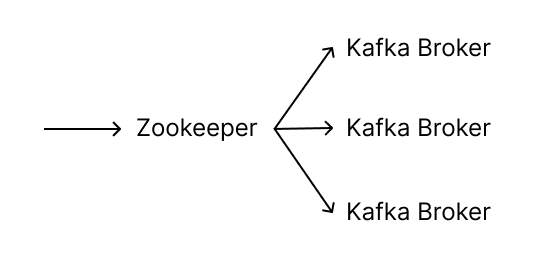
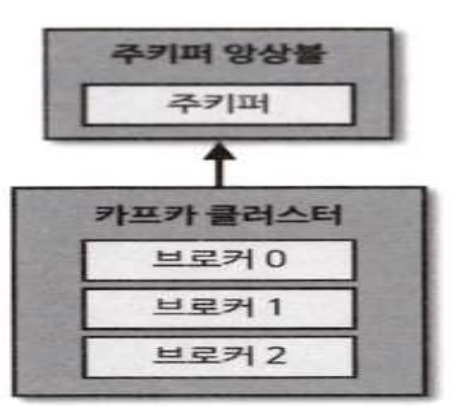
- 카프카는 상용환경에서 최소 3대 이상의 서버(Broker)로 운영
- 3대 이상으로 구현을 하게 되면 클러스터 중 일부에 장애가 발생하더라도 데이터를 지속적으로 복제하기 때문에 안전하게 운영할 수 있습니다.
5)현재
- 카프카 소스 코드는 깃허브 저장소(https://github.com/apache/kafka)에 공개
- KIP(Kafka Improvement Proposal)을 통해서 변경 사항을 제안하는 것이 가능
2.Kafka의 역할
1)Big Data
- 다양한 종류의 많은 또는 빠르게 생성되는 데이터
2)Data Pipeline
- Data Lake: 생성되는 데이터를 모두 모은 것
- Data Warehouse: 필터링이나 패키지화가 된 데이터
- Data Pipeline은 Data Warehouse 와 다르게 필터링 되거나 패키지화 되지 않은 데이터가 저장되는 것. 운영되는 서비스로부터 수집 가능한 모든 데이터를 모으는 것. 데이터 과학자는 모든 데이터를 가지고 서비스에 활용할 수 있는 비지니스 인사이트를 도출
- 서비스에서 발생하는 데이터를 데이터 레이크로 모으려면 웹, 앱, 백엔드 서버, 데이터베이스에서 발생하는 데이터를 직접 End-To-End 방식으로 넣을 수 있는데 서비스하는 애플리케이션의 개수가 적고 트래픽이 많지 않을 때는 문제가 되지 않지만 서비스가 복잡해지게 되면 Extracting(추출), Transform(변경), Loading(적재) 하는 과정을 하나로 만드는 Data Pipeline을 구축해야 함
- Data Pipeline의 동작은 자동화 되어야 합니다.
- Data Pipeline을 구축할 때 Kafka 와 같은 Message Broker 와 Airflow(스케줄러) 같은 Tool을 많이 이용합니다.
Message Broker가 받은 데이터를 전처리 작업을 수행한 후 데이터 저장소에 저장
3)kafka 사용 이유
- 높은 처리량: 데이터를 묶어서 전송할 수 있고 병렬 처리가 가능
- 확장성이 좋음: 브로커의 개수를 조절
- 영속성
- 카프카는 데이터를 파일에 저장(카프카가 종료되었다 켜지더라도 데이터는 그대로 보존)
- 속도는 Page Cache를 이용해서 보완
- 고가용성
- 여러 개의 서버로 운영이 되기 때문에 일부 서버에 장애가 발생해도 무중단으로 안전하고 지속적으로 데이터를 처리
3.Docker에 설치
1)docker-compose.yml 파일을 생성
version: "2"
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka:2.12-2.5.0
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
- /var/run/docker.sock:/var/run/docker.sock- 카프카는 설치를 할 때 2개의 이미지를 이용
- 카프카와 주키퍼(카프카 코디네이터)를 같이 설치
2)터미널에서 명령을 수행
-
클러스터 1개를 가진 카프카 서버를 실행
docker-compose up -d
-
컨테이너 실행 확인
docker ps
3)외부에서 사용할 수 있도록 설정 변경
-
터미널에서 도커 컨테이너 안으로 접속
docker exec -it kafka /bin/bash
-
설정 파일을 수정
vi /opt/kafka/config/server.properties# 주석 해제 listeners=PLAINTEXT://:9092 # 추가 delete.topic.enable=true auto.create.topics.enable=true -
외부에서 접속가능하도록 할 때 추가
advertised.listeners=PLAINTEXT://공인ip:9092
4)토픽 생성 과 조회 및 삭제
-
명령어를 사용하기 위해서 프롬프트 이동
cd /opt/kafka/bin -
첫번째 카프카 서버의 첫번째 영역에 토픽(exam-topic) 생성
kafka-topics.sh --create --bootstrap-server localhost:9092 --topic exam-topic
-
토픽 리스트 조회
kafka-topics.sh --bootstrap-server localhost:9092 --list
- 토픽 삭제
kafka-topics.sh --delete --zookeeper zookeeper:2181 --topic exam-topic
5)메세지 전송 및 받기
메시지 전송
- 프롬프트 이동
cd /opt/kafka/bin kafka-console-producer.sh --topic exam-topic --broker-list localhost:9092 - 프롬프트가 바뀌면 메세지를 작성
안녕하세요 반갑습니다
메시지 받기
- 새로운 터미널에서
docker exec -it kafka /bin/bashcd /opt/kafka/bin - 토픽 받기
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic exam-topic --from-beginning
6)Python에서 카프카 메세지 전송 및 받기
-
가상 환경을 생성 (Mac 이나 Linux는 pythone 대신에 python3)
python -m venv kafka_env -
가상환경 활성화
Mac 이나 Linux:source kafka_env/bin/activateWindows:
kafka_env\Scripts\activate -
패키지 설치
pip install kafka-python pip install six==1.6.0
메시지 전송
-
메시지 전송하는 python 코드 작성 - producer.py
import sys import six if sys.version_info >= (3, 12, 0): sys.modules['kafka.vendor.six.moves'] = six.moves from kafka import KafkaProducer import json class MessageProducer: def __init__(self, broker, topic): self.broker = broker self.topic = topic #key_serializer=str.encode 를 추가하면 key 와 함께 전송 #그렇지 않으면 value 만 전송 self.producer = KafkaProducer( bootstrap_servers=self.broker, value_serializer=lambda x: json.dumps(x).encode("utf-8"), acks=0, api_version=(2, 5, 0), key_serializer=str.encode, retries=3, ) def send_message(self, msg, auto_close=True): try: print(self.producer) future = self.producer.send(self.topic, value=msg, key="key") self.producer.flush() # 비우는 작업 if auto_close: self.producer.close() future.get(timeout=2) return {"status_code": 200, "error": None} except Exception as exc: raise exc # 브로커와 토픽명을 지정 broker = ["localhost:9092"] topic = "exam-topic" pd = MessageProducer(broker, topic) #전송할 메시지 생성 msg = {"name": "John", "age": 30} res = pd.send_message(msg) print(res) -
메시지 전송
python producer.py
-
실행 한 후 터미널의 카프카 컨슈머가 데이터를 받는지 확인

메시지 수신
-
메시지 전송하는 python 코드 작성 - consumer.py
import sys import six if sys.version_info >= (3, 12, 0): sys.modules['kafka.vendor.six.moves'] = six.moves from kafka import KafkaConsumer import json class MessageConsumer: def __init__(self, broker, topic): self.broker = broker self.consumer = KafkaConsumer( topic, # Topic to consume bootstrap_servers=self.broker, value_deserializer=lambda x: x.decode( "utf-8" ), # Decode message value as utf-8 group_id="my-group", # Consumer group ID auto_offset_reset="earliest", # Start consuming from earliest available message enable_auto_commit=True, # Commit offsets automatically ) def receive_message(self): try: for message in self.consumer: #print(message.value) result = json.loads(message.value) for k, v in result.items(): print(k, ":", result[k]) print(result["name"]) print(result["age"]) except Exception as exc: raise exc # 브로커와 토픽명을 지정한다. broker = ["localhost:9092"] topic = "exam-topic" cs = MessageConsumer(broker, topic) cs.receive_message() -
작성한 파일을 실행하면 에러가 발생
: 이전에 JSON 형식이 아닌 데이터를 전송했는데 그 데이터를 파싱할려고 해서 에러가 발생
- 토픽을 삭제하고 다시 전송한 후 실행
- 토픽 삭제
docker exec -it kafka /bin/bash cd /opt/kafka/bin kafka-topics.sh --delete --zookeeper zookeeper:2181 --topic exam-topic - producer.py 실행
- consumer.py 실행

- 토픽 삭제
