week04_01
오늘은 무엇을 배웠는가?
많은것을 배웠지만 주로 선형회귀를 집중으로 배워보고 케글이라는 사이트도 코랩이라는 것도 알게 됐다.
가장 기억에 남는건 무엇일까?
앞서 말했듯이 주로 선형 회귀를 배워보고 선형회귀를 여러가지 방법으로 해봤다.
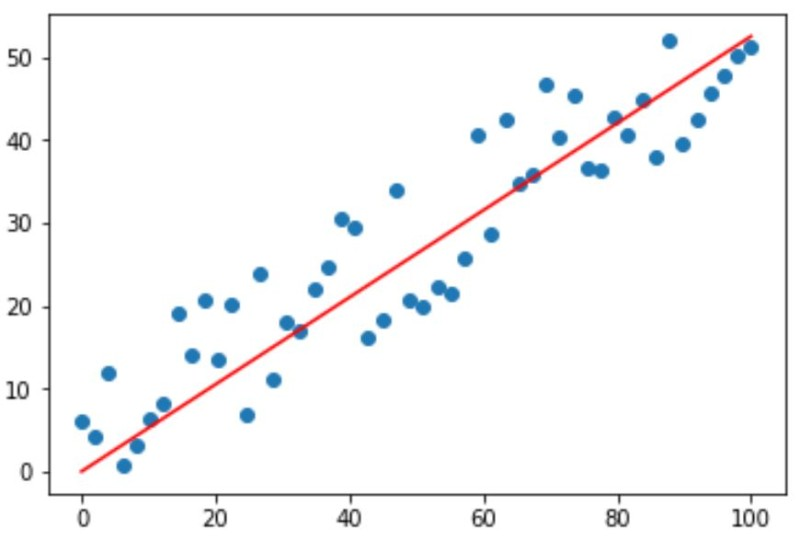
선형회귀 알고리즘 영어로는 Linear Regressiond알고리즘이다.
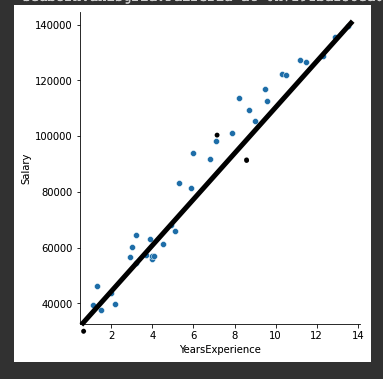
급여와 근무년수를 나타낸것인데...
보통 이러한 식은 y=mx + b로 나타낼것이다.
기울기 m이 절편 b에따라 선의 모양이 정해져서 x를 넣으면 y를 구할수 있다.
선형회귀의 목적은 저 m과 b를 얻는것이다.
선형회긔에서는 오차 손실 즉 Loss가 발생하는데
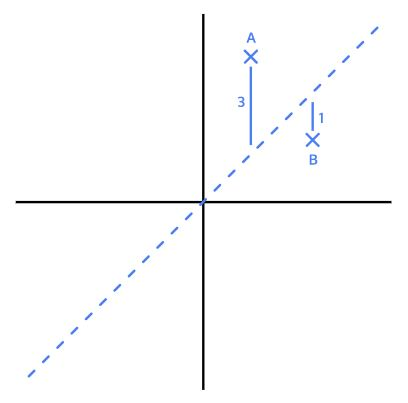
a와 대각선의 오차? 물론 약간의 차가 있겠지만 일종의 오차이다.
A는 3 B는 1만큼 손실이 발생했다.
보통은 양음수의 구분이 없게끔 그리고 눈에 잘띄게끔 발생한 오차의 제곱해서
손실을 구한다. 이런걸 평균제곱오차 mean squared error,MSE라고 부릅니다.
이젠 실제로 만들어볼 차례였다. 물론 처음이라 따라치면서 뭔지를 이해하려고 애는 썻다.
처음엔 텐써플로우로 선형회귀를 만들어보았다. 여담으로 자주 쓰이는 방법은 아니라고 한다. 이유는 계속 반복되는 구조만 나와서 만든 사이트에서도 1버전은 권유 하지 않는다고 한다. 그 다음으로는 케라스는 방법?으로 만들어보았다. 가장 최신의 방법이고 트렌드라고 합니다.
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
x_data = np.array([[1], [2], [3]])
y_data = np.array([[10], [20], [30]])
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.1))
model.fit(x_data, y_data, epochs=100) # epochs 복수형으로 쓰기!가장 간단한 구조로 만들어 보았다. 방식은 케라스 방식이고 물론 알려준대로 처음한거라 치긴 했다.
epochs =100은 백번까지 돌린다는 뜻이다 점점 반복할수록 로스값이 줄어야
성공을 한것이다.
Epoch 93/100
3/3 [==============================] - 0s 577us/sample - loss: 0.0242
Epoch 94/100
3/3 [==============================] - 0s 727us/sample - loss: 0.0230
Epoch 95/100
3/3 [==============================] - 0s 633us/sample - loss: 0.0219
Epoch 96/100
3/3 [==============================] - 0s 637us/sample - loss: 0.0209
Epoch 97/100
3/3 [==============================] - 0s 643us/sample - loss: 0.0199
Epoch 98/100
3/3 [==============================] - 0s 658us/sample - loss: 0.0189
Epoch 99/100
3/3 [==============================] - 0s 964us/sample - loss: 0.0180
Epoch 100/100
3/3 [==============================] - 0s 621us/sample - loss: 0.0172
너무 길기에 뒤에서 7개정도만 보았다.
점점 로스값이 줄어드는게 보이는가 성공한것이다. 오차를 0으로는 만들수 없지만 그 오차값을 0에 가깝게 만드는게 이상적인... 방향이다 현실도 그랬으면 좋겠다.
과제..
과제는 근속년수에 따른 급여로 연차에 따른 연봉을 구해보기이다. 이때는 케글이라는 것을 통해서 데이터를 내용을 받아서 해보았다.
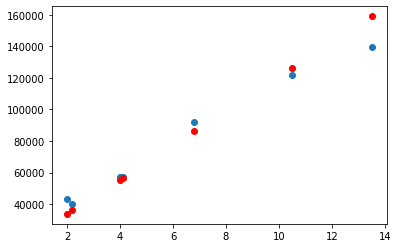
결과는 잘 나왔다 우리가 구한 값과 예측값이 비슷한 궤도로 잘 맞아 떨어진다. (빨간점이 예측값이다)
보통은 연차가 올라갈수록 보통은 연봉도 같이 오른다.
model = Sequential([
Dense(1)
])
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.01)) # 왜 0.01일까?
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val),
epochs=100
)
가장 마지막 구문이다. 물론 과제도 실습이랑 비슷하기에 어느정도 익히고 따라 쳐보면서 각각 구문들이 뭔지를 찾아봤다. 가장 아래 부분이 좀 뭔가 처음부터 이해가 안됐다. 우선 opimizer라는걸 변형해 보면서 구해보라고 했는데 왜 그런 얘기를 했는가 했는데 이 optimizer에는 여러가지 종류들이 있다.
스텝 방향에 따라서 스텝사이즈에 따라서 그 종류도 다양하고 얽히고 섥혀있다. 물론 이 글을 쓰는 시점에선 아직 찾아보고 공부는 못했다 ㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎ 오늘 공부하고 내일이나 글을 쓸떄 다시한번 올려봐야겠다.!
