week04_01
오늘 배운것
저번 선형회귀시간때 옵티마이저 종류에 대한 내용과
논리회귀에 대해서 배웠습니다.
논리회귀는 선형회귀로 풀기 어려운 방법을 푸는데 쓰인다.
선형회귀는 x인자의 여부에 따라 y의 값을 예측하고 움직이는데 주로 쓰인다.
하지만 실생활에서 모든 원인과 결과는 직선 형태로 표현할 수 없습니다.
그로 인해 정확도가 떨어지고 이부분을 보완하기 위해 나온 개념이 '논리 회귀'입니다.
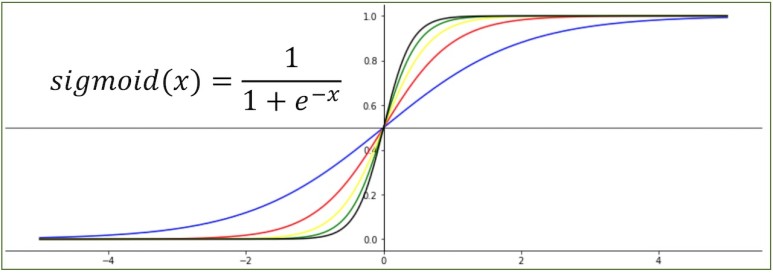
논리 회귀가 좀 더 정확한 이유는 선형회귀는 직선양의 그래프를 이용하여 분류하는 반면,
시그모이드(sigmoid)함수를 사용하여 S자 형태를 띄고 있기 때문입니다.
오늘 한것
https://colab.research.google.com/drive/1FwX8IZ7FLon8eb5U3gXkKArBIE9Ich8f#scrollTo=oeZ5lkMjzSnH
연령, 혈압, 인슐린 수치 등을 통해 당뇨병환자를 구하는것이다.
우선 데이터를 살펴봤고 당뇨병인지 아닌지의 유무를 알아내면 되기에 Outcome부분만 Y축으로 뺏다.
x_data = df.drop(columns=['Outcome'],axis=1)
x_data = x_data.astype(np.float32)
이러한 방식으로 Outcome을 df에서 drop을 했다.
y_data = df[['Outcome']]
y_data = y_data.astype(np.float32)
그리고 Y데이타로 위치시키고 데이타 앞부분 5군데만 나타내봤다.
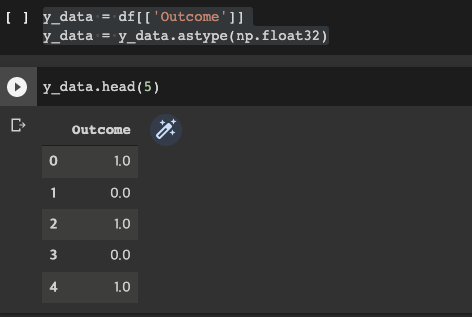
0이면 당뇨병환자는 아니다. 1이면 당뇨병 환자.
그다음에 스탠다드스케일러로 표준화를 하고 데이터를 x,y로 분류를 한뒤
출력을 하는 순으로 만들었다.
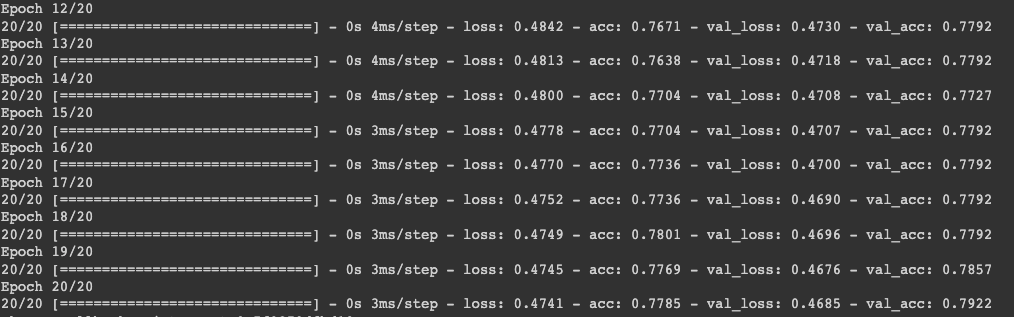
에폭은 20번 돌렸고 acc라는 것을 하나 달아주었다. 이것은 정확도를 loss값으로만으로 하기엔 부정확점이 많아서 0과1사이에 숫자로 정확도를 알려준다. 20번째 에폭에서 acc는 0.7922 즉 79.22%의 정확도를 가진 데이터모델이라는 것.
마치고 나서..
이론적인 면은 어느정도 구글링을 통해서 이해도 하고, 공부를 하고 있다.
물론 이해도 되지만 아직 어려운점도 많다. 특히 과제를 할때 머신러닝을 쓰는 언어의 문법을 쓰는게
아직 미숙하고 힘들다고 느껴진다. 그리고 몇몇 어려운 용어도 찾아가면서 하니까 아직은 시간이 많이
걸리는거 같다.
앞으로 할것
이제 프로젝트를 대비해서 jinja2 템플릿에 대해서 좀 공부를 하려고 한다.
물론 한참 부족하고 이제 코딩을 본격적으로 한지 20일정도 했다. 점점 공부량을 더 늘려서
열심히 채워야겠다...
