week04_02
오늘은 뭘 배웠니?
오늘은 논리회귀에 대해 공부하고 실습했습니다..
논리회귀는 선형회귀로 구하기 어려운 상황을 구할수 있습니다.
선형회귀는 x인자를 통해 y값을 예측하고 움직이는 부분으로 mx+b = y의 형식으로 1차선 그래프를 생각하면 된다.
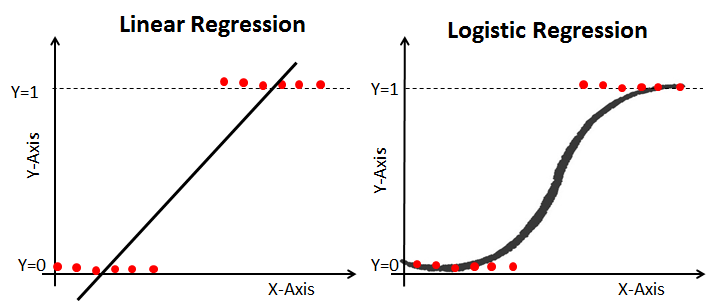
실생활에서 모든 원인과 결과는 직선 형태로 표현할 수 없습니다. 그로 인해 정확도가 떨어지고 이부분을 보완하기 위해 나온 개념이 '논리 회귀'입니다. 로지스틱 회귀는 선형회귀에서 구하는 직선 대신 S자 곡선을 이용하여 분류의 정확도를 향상한 방법입니다.
선형회귀는 종속변수와 독립변수 사이의 관계를 설정하는데 사용되며, 이는 독립변수가 변경되는 경우 결과 종속변수를 추정하는데 유용합니다. 논리 회귀 분석에서도 마찬가지이나, 종속변수가 이진일 뿐이며 주로 분류에 이용합니다. 논리회귀가 좀 더 정확한 이유는 선형회귀는 직선양의 그래프를 이용하여 분류하는 반면, 시그모이드(sigmoid)함수를 사용하여 S자 형태를 띄고 있기 때문입니다.
오늘 실습한 내용
https://colab.research.google.com/drive/1FwX8IZ7FLon8eb5U3gXkKArBIE9Ich8f#scrollTo=oeZ5lkMjzSnH
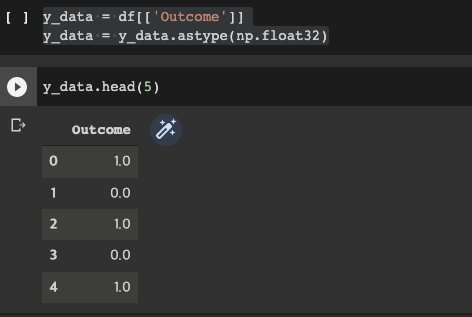
나이나 인슐린수치 등 여러요소를 고려해서 당뇨병환자를 찾아내는 내용이다.
여러가지 데이터 수치들이 있지만 그중에서 true와 false만을 나타내는 outcome 을 따로 y축으로 빼놨다. 아래 사진이 결과다.
그렇게 하고 데이터를 Standardscaler로 표준화를 시킵니다. 왜냐하면
데이터의 분류를 컴퓨터가 인식하기 쉽게 만들기 위함입니다. 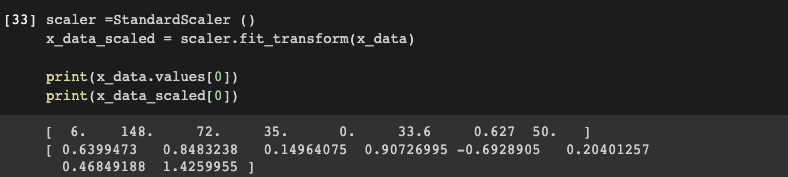
밑에 이러한 소수점의 형태로 만드는것입니다. 이러면 컴퓨터는 데이터를 인식하기 편해진다고 합니다.
이부분에 대해서는 왜 그런지 scaler에 대해서 좀더 알아보려고 합니다.
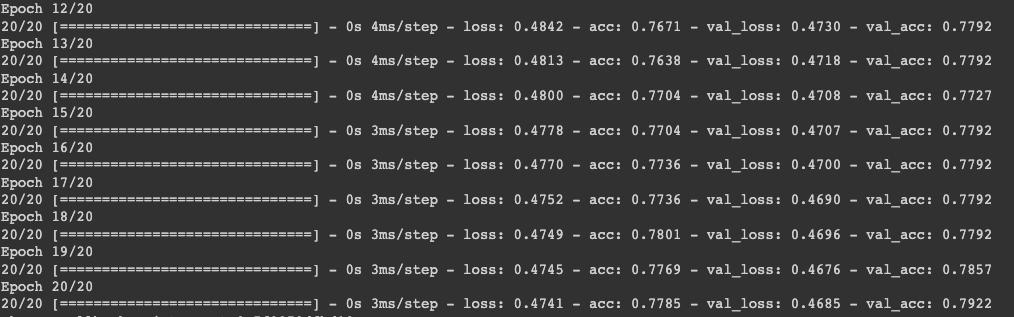
트레이닝을 하고 출력을 해서
그래서 위에 사진처럼 결과가 나왔습니다.
정확도는 79.22% 아 저기서 acc는 loss만으로 정확도를 판가름하기 부족해서
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.01), metrics=['acc'])
이 구문처럼 metrics = ['acc']를 넣어줘서 정확도를 계산해줍니다.
하면서 느낀점 앞으로 할일
우선 이론적인 내용은 이해가 되고 구글링을 통해서 부족한 부분은 이해하려고 하고 있습니다.
앞으로의 공부하면서 어느정도를 내가 이해를 하고 있는가 다시 한번 시험을 해보려고 합니다.
이해를 더 돕기 위해 복습을 내일 할 예정입니다.
그리고 프로젝트를 대비하기 위해서 진자2 템플릿을 공부하려고 합니다. 요즘 여러모로 피곤함이 많이
겹칩니다. 저번 프로젝트부터 뭔가 아쉬움 부끄럼움들이 많이 들었는데 이러한 점이 이번에는 나를 불태우려고 하는거 같습니다. 좋은 현상이지만 몸은 너무 힘드네여 ㅋㅋㅋ 행복한 코통입니다.
