Kubernetes Objects
- Kubernetes에서 "객체(Objects)"는 클러스터 내에서 실행되는 워크로드 및 리소스를 정의하고 관리하는데 사용되는 중요한 구성 요소이다.
- Kubernetes 클러스터를 구성하고 애플리케이션을 배포하기 위해 다양한 종류의 객체를 정의하고 사용할 수 있다.
- 주요 객체는 아래와 같다.
Default Object
- 가장 기본적인 구성 단위이다.
- 쿠버네티스에 의해 배포 및 관리되는 가장 기본적인 오브젝트로 Pod, Service, Namespace, Volume이 있다.
Pod
파드는 Kubernetes에서 가장 작은 배포 단위이며 하나 이상의 컨테이너로 구성된다.
파드는 동일한 호스트에서 실행되며 네트워크 네임스페이스 및 스토리지 볼륨을 공유한다.
각 파드에는 고유 IP 주소가 할당된다.
같은 파드내의 컨테이너는 IP와 Port를 공유한다.
- 즉, 두개 이상의 컨테이너가 하나의 파드에 속했을 경우 localhost를 사용하여 서로 통신이 가능하다.
파드내의 컨테이너간에는 디스크 볼륨을 공유할 수 있다
- 즉, 애플리케이션만이 아닌 로그 수집기와 같은 여러 솔루션이 함께 배포되어, 애플리케이션 컨테이너와 로그 수집 컨테이너가 하나의 볼륨을 공유해 각자의 컨테이너 파일을 읽어올 수 있다.
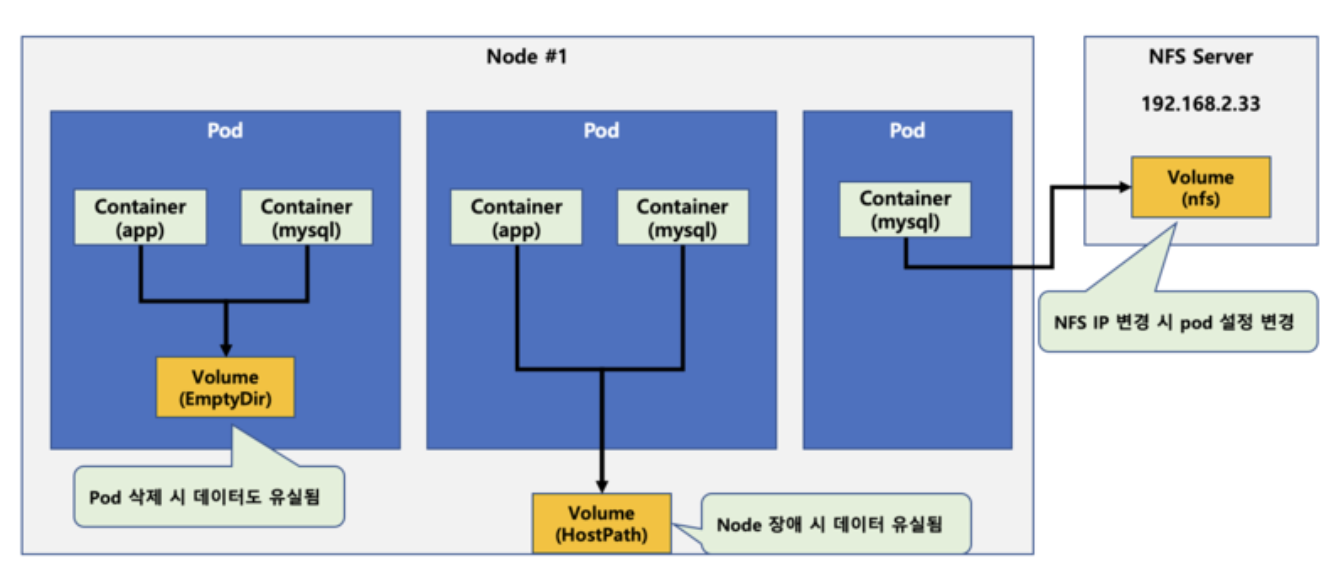
Volume
파드가 생성될 때 컨테이너가 실행되면서 로컬 디스크를 생성하는데, 이 로컬 디스크의 경우 컨테이너가 재실행되거나 종료되면 로컬 디스크안에 있는 파일도 함께 손실된다.
이 문제를 해결하기 위해 영구적으로 저장해야할 스토리지가 필요하였고, 쿠버네티스에서는 이를 위해 영구적인 스토리지를 제공하는데 이것이 볼륨이다.
볼륨은 파드가 실행될 때 컨테이너에 마운트되어 사용되며, 쉽게 컨테이너의 외장 디스크라고 생각하면 된다.
볼륨은 NFS, Cinder와 같은 네트워크 스토리지 부터 클라우드 플랫폼의 스토리지까지 다양한 유형의 볼륨을 지원한다.
따라서 볼륨이 파드 내부에 존재 할 수도 있으며, 파드 외부에 존재할 수도 있다.
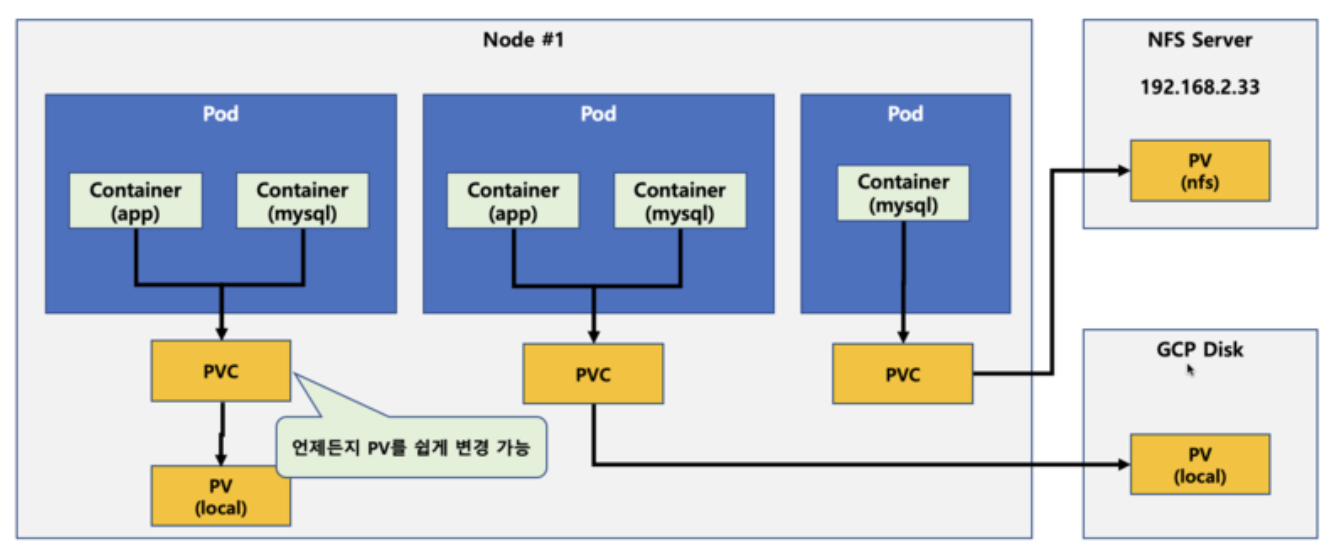
PV(PersistentVolume) & PVC(PersistentVolumeClaim)
- Kubernetes에서 PV(PersistentVolume)와 PVC(PersistentVolumeClaim)는 영속적인 스토리지를 관리하고 동적으로 할당하는 데 사용되는 중요한 개념이다.
- 이들은 컨테이너화된 애플리케이션에서 데이터를 저장하고 유지하기 위한 스토리지 추상화 계층을 제공한다.
- PV는 파드에 데이터를 저장하는데 사용되며, PVC는 스토리지를 동적으로 할당하기 위해 사용된다.
PersistentVolume(PV)
- PV는 클러스터 내에서 스토리지 자원을 표현하는 Kubernetes 리소스이다.
- PV는 클러스터 수준에서 생성되고 관리되며, 여러 파드에서 공유할 수 있는 스토리지 볼륨을 나타낸다.
- PV는 스토리지 백엔드 (예: 네트워크 저장소, 로컬 디스크)에 대한 세부 정보를 포함하며, 볼륨의 크기 및 액세스 모드 (ReadWriteOnce, ReadOnlyMany, ReadWriteMany) 등을 정의한다.
- PV는 일반적으로 관리자에 의해 수동으로 생성하고 설정된다.
PersistentVolumeClaim(PVC)
- PVC는 파드에서 사용할 스토리지를 요청하는 Kubernetes 리소스이다.
- PVC는 파드가 원하는 스토리지 크기와 액세스 모드를 지정하며, 파드에 스토리지를 동적으로 할당하는데 사용된다.
- 파드는 PVC를 참조하여 어떤 스토리지를 사용할 것인지 지정하며, PVC는 PV를 찾아 할당하거나 적절한 PV를 생성하여 할당한다.
- PVC는 개발자 또는 애플리케이션에서 정의하며, 스토리지 요구 사항을 명시적으로 정의한다.
PV와 PVC의 워크플로우로 동작
- 관리자는 PV를 설정하고 클러스터에 만들며, 이때 PV의 세부 정보 (스토리지 유형, 크기 등)를 정의한다.
- 개발자 또는 애플리케이션 운영자는 PVC를 정의하고 원하는 스토리지 요구 사항을 명시하며, PVC는 파드에서 사용할 스토리지 크기와 액세스 모드를 지정한다.
- 파드 정의에서 PVC를 참조하여 해당 PVC에 연결된 PV가 할당되도록 설정한다.
- PVC가 PV에 바인딩되면 파드에서 PVC를 사용하여 스토리지를 마운트하고 데이터를 저장한다.
- 이러한 스토리지 추상화 계층을 사용하면 파드가 스토리지에 대해 명시적으로 알 필요 없이 스토리지를 동적으로 할당하고 사용할 수 있으며, 스토리지 관리 작업이 단순화된다.
- PV와 PVC는 다양한 스토리지 백엔드 (예: NFS, AWS EBS, GCE PD)와 함께 사용할 수 있으며, Kubernetes 클러스터의 스토리지 리소스를 효율적으로 활용할 수 있도록 도와준다.
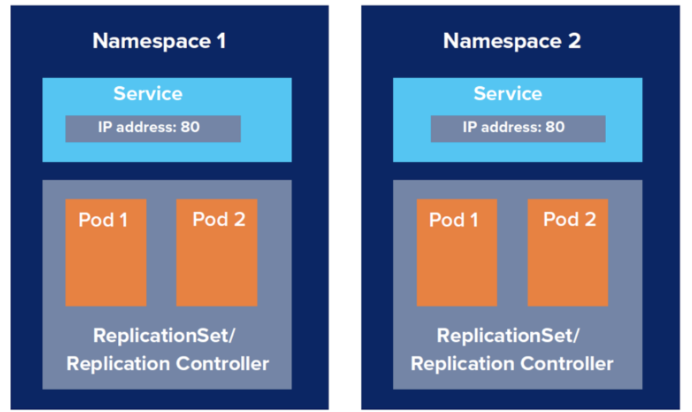
NameSpace
- 네임스페이스는 클러스터 내에서 리소스를 논리적으로 분리하기 위해 사용되는 하나의 단위이며, 다중 테넌시 및 접근 제어를 지원한다.
- 사용 목적에 따라 네임스페이스로 분류되며, 여러 팀에서 하나의 쿠버네티스 클러스터를 공유한다면 팀별로 네임스페이스를 나누어 구성할 수도 있다.
- 네임스페이스 별로 리소스(CPU, Memory, GPU 등) 지정하여 사용할 수 잇으며, 접근 권한도 부여할 수 있다.
- 하지만 네임스페이스는 물리적이 아닌 논리적으로 구분된 것이기 때문에, 다른 네임스페이스 간의 파드와도 통신할 수 있다. 네트워크 정책을 통해 막을 수도 있지만 이 경우 여러 클러스터를 운영하여 분리시키는 것이 바람직하다.
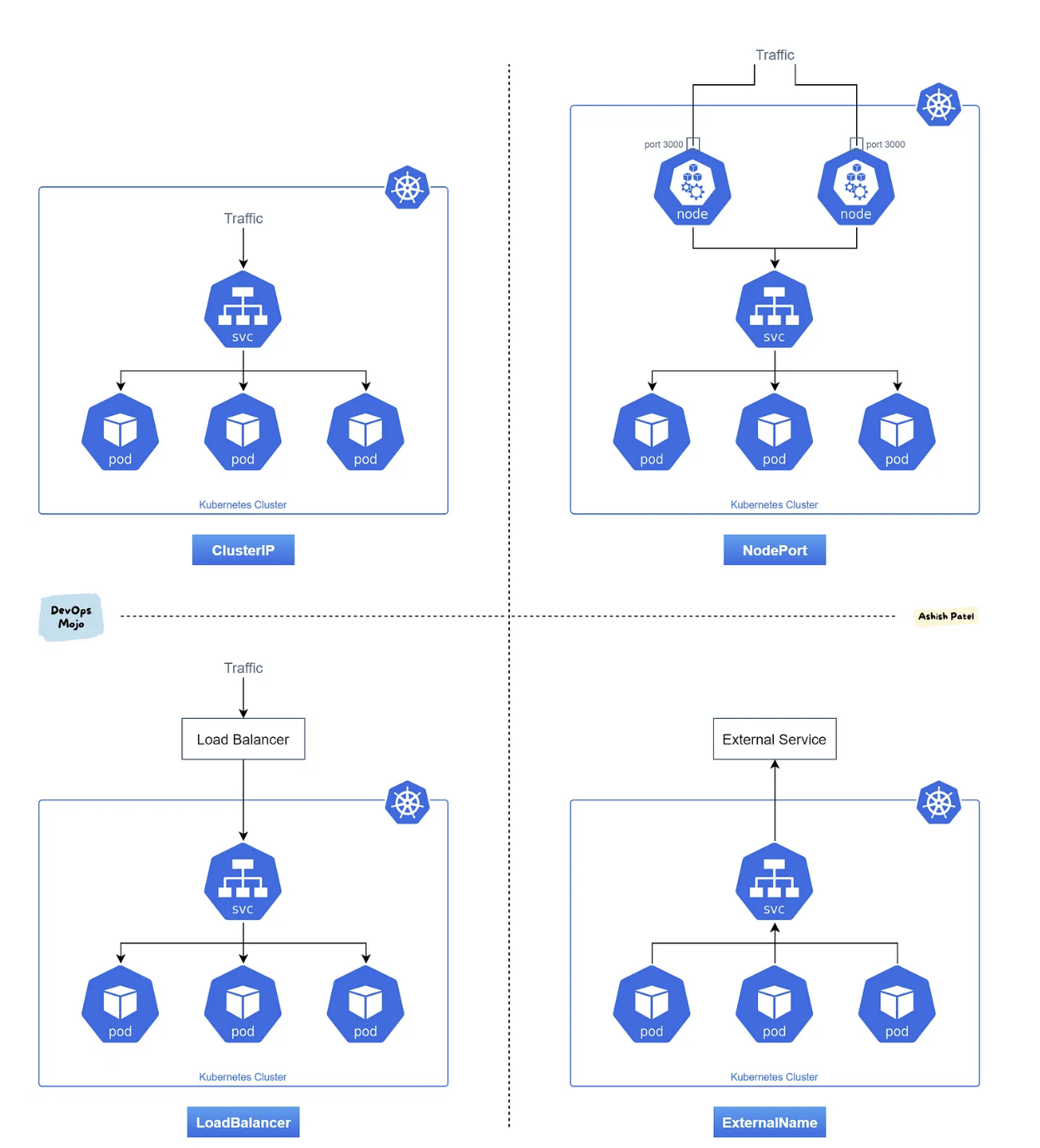
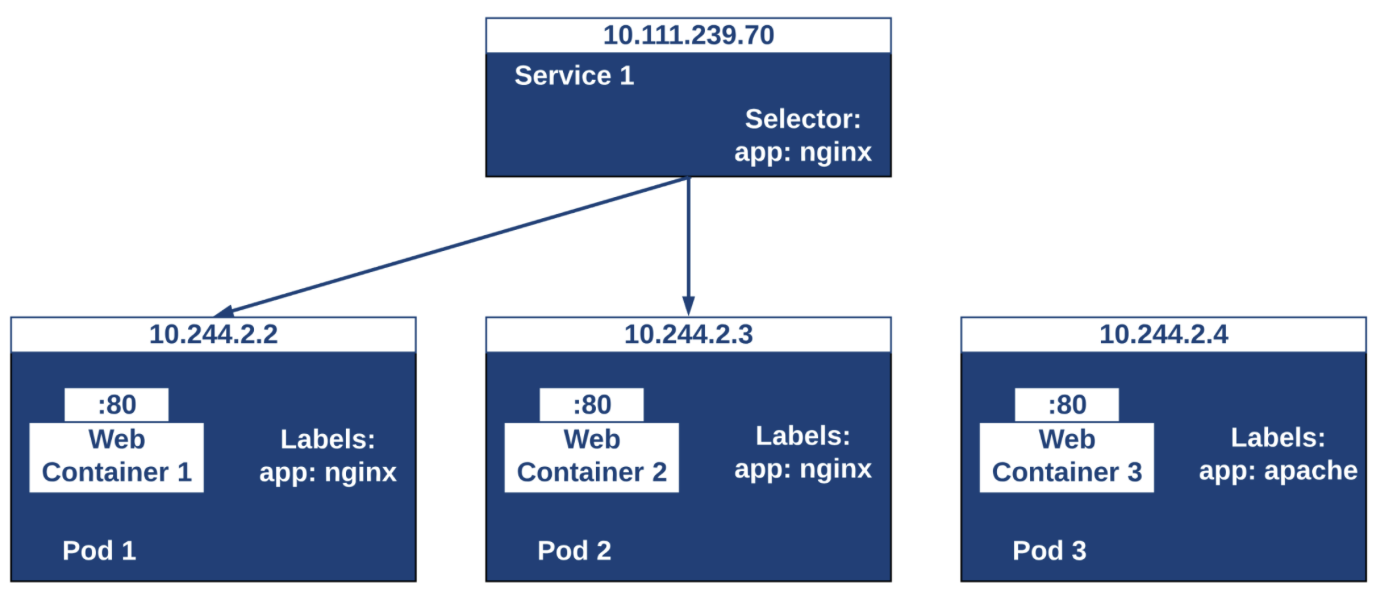
Service
- 서비스는 파드 집합을 논리적으로 그룹화하고 외부 또는 다른 파드에서 액세스할 수 있도록 하는 로드 밸런서 역할을 한다.
- 클러스터 내부 DNS를 통해 서비스에 접근할 수 있으며, 클러스터 외부로 노출할 수도 있다.
- 클러스터 내부에서 실행되는 파드들은 언제든지 삭제되고 생성될 수 있는데, 파드가 생성될 때마다 새로운 내부 IP를 할당하게 되므로, 클러스터 내/외부와 통신을 계속 유지하기 어렵다.
- 이를 위해서 쿠버네티스의 서비스 기능을 사용하여 라벨링을 통해 같은 라벨을 가진 파드를 묶어 단일 엔드포인트(ClusterIP, NodePort, LoadBalancer, ExternalName)를 제공해 주는 기능을 한다.
- 서비스는 클러스터 내부에서 고정적인 IP를 가지며, 파드가 변경되어도 이 서비스의 IP는 변하지 않기 때문에 클러스터 외/내부와의 통신을 계속 유지할 수 있다.
- 서비스는 파드간의 로드밸런싱 및 멀티 포트를 지원한다.
그 외 Object
ConfigMap & Secret
- ConfigMap은 설정 데이터 (환경 변수, 설정 파일)를 파드에 주입하는 데 사용되며, Secret은 비밀 데이터를 안전하게 관리한다.
Label
- 라벨은 쿠버네티스의 리소스를 선택하는데 사용되며, 모든 리소스는 라벨을 가지며, 동일한 특정 라벨을 가지고 있는 리소스만 선택하여 논리적으로 연관성 있는 것끼리 분류하여 운영할 수 있다.
- 라벨로 선택된 리소스는 service에 연결하거나 네트워크 접근 권한을 부여하는 등 다양하게 사용될 수 있다.
- 라벨은 key:value 형태로 정의되며, 하나의 리소스에 여러개의 라벨을 적용할 수 있다.
NetworkPolicy
- NetworkPolicy는 파드 간 트래픽 흐름을 제어하기 위해 사용되며, 보안 및 네트워크 정책을 정의하고 적용한다.
Custom Resource Definitions (CRDs)
- CRD를 사용하여 Kubernetes API에 사용자 정의 객체 유형을 도입하고 확장할 수 있다.
Controller
- 쿠버네티스는 기본적인 오브젝트만으로 애플리케이션을 배포하고 운영 가능하지만, 좀 더 편리하게 관리하기 위해 컨트롤러라는 고수준의 오브젝트를 제공한다.
- Kubernetes 컨트롤러는 Kubernetes 클러스터 내의 리소스 상태를 원하는 상태로 유지하는 역할을 하는 중요한 컴포넌트이다.
- 컨트롤러의 종류로 ReplicationController, ReplicaSet, Deployment, StatefulSet, DaemonSet, Job, CronJob가 있다.
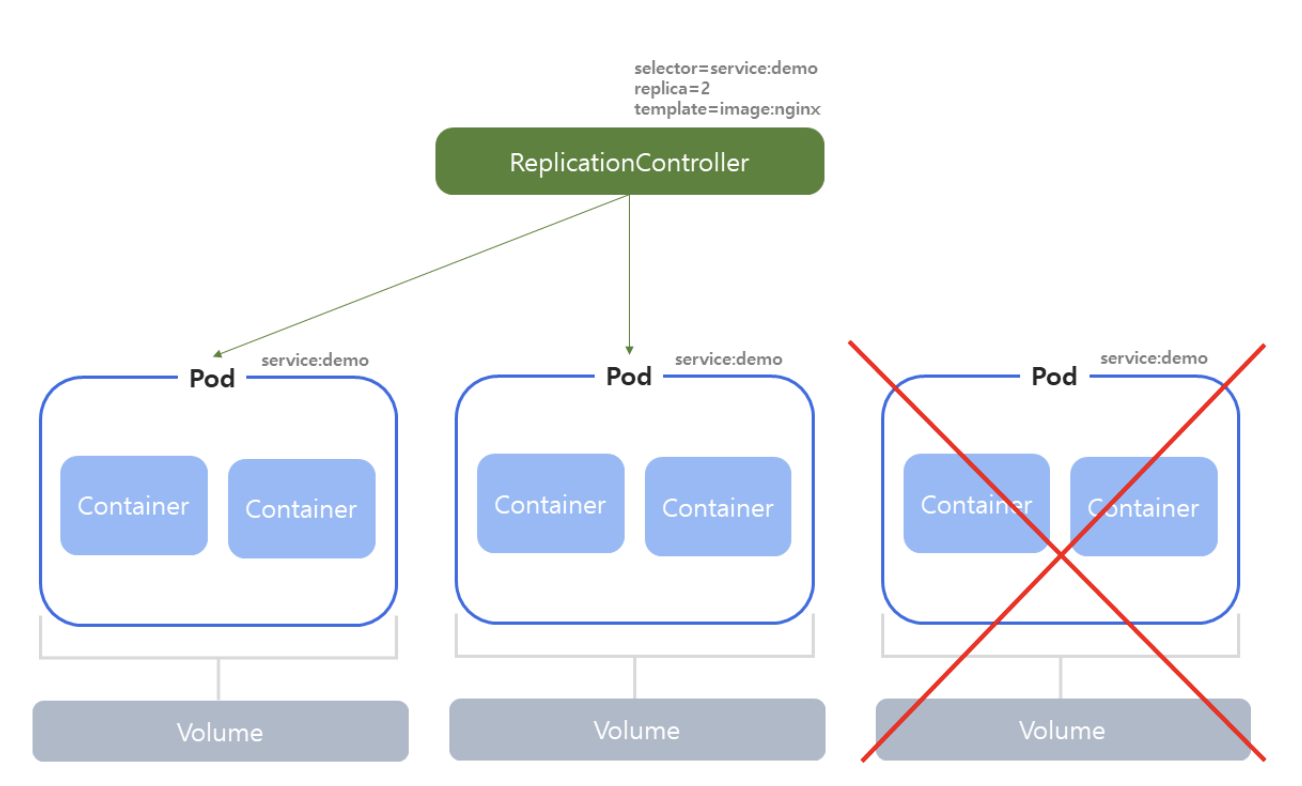
ReplicationController
- ReplicationController(RC)는 파드를 관리하는 역할을 한다.
- ReplicationController에 지정된 Replica 수 보다 파드가 많으면 파드를 삭제하고 파드가 적으면 파드를 추가한다.
- 사용자가 수동으로 생성한 파드와는 달리 ReplicationController가 관리하는 파드는 파드가 삭제되거나 종료되는 경우 파드를 자동으로 설정한 원하는 수로 유지한다.
주요 특징
- 복제본 수 관리: ReplicationController는 특정 파드 템플릿을 기반으로 한 원하는 복제본 수를 유지한다. 파드 템플릿은 파드의 스펙(예: 컨테이너 이미지, 리소스 요청 등)을 정의한다.
- 자동 복구: 파드가 실패하면 ReplicationController는 복제본 수를 원하는 수로 다시 맞추기 위해 새로운 파드를 생성한다. 이로써 애플리케이션의 가용성이 향상된다.
- 업데이트 관리: ReplicationController를 사용하여 파드 템플릿을 업데이트하고 새로운 애플리케이션 버전으로 롤링 업데이트를 수행할 수 있다. 이때 한 번에 일정 수의 파드를 교체하고 롤백도 가능하다.
- 스케일링: ReplicationController는 수동 또는 자동으로 파드 복제본 수를 조절하여 수직 및 수평 스케일링을 지원한다. 이를 통해 트래픽 변동에 대응할 수 있다.
- 레이블 셀렉터 사용: ReplicationController는 레이블 셀렉터를 사용하여 어떤 파드를 복제할지 선택한다. 레이블은 파드의 선택 기준을 지정하는 데 사용된다.
ReplicationController를 권장하지 않는 이유
- Kubernetes의 최신 버전에서는 ReplicationController(ReplicaController라고도 함)보다 더 강력하고 유연한 대안인 ReplicaSet과 Deployment를 사용하는 것이 권장된다.
- 이러한 변경은 Kubernetes의 진화와 관련이 있으며, ReplicaSet와 Deployment는 ReplicationController와 비교하여 더 많은 이점이 제공된다.
- 따라서 Kubernetes에서는 ReplicationController를 사용하는 대신 ReplicaSet과 Deployment를 사용하는 것이 더 좋은 선택이며, 이전에 ReplicationController를 사용하더라도 클러스터가 여전히 작동할 수 있지만, 새로운 애플리케이션을 배포하거나 관리할 때는 ReplicaSet과 Deployment를 사용하는 것이 권장된다.
- ReplicationController는 레거시 시스템에서 계속 사용될 수 있지만 새로운 Kubernetes 배포에는 사용하지 않는 것을 권장한다.
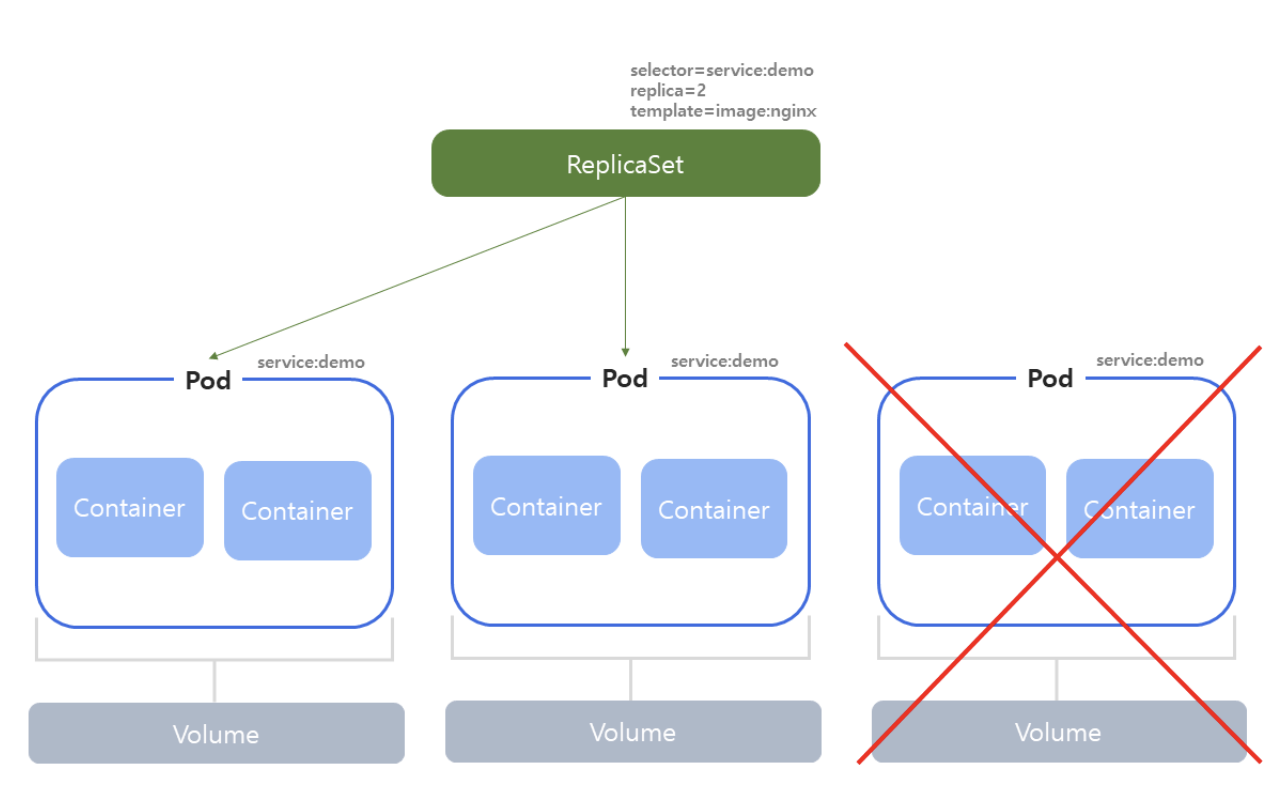
ReplicaSet
- ReplicaSet은 ReplicationController의 업그레이드된 상위 버전으로, 쿠버네티스 공식 문서에서는 ReplicationController보다 ReplicaSet사용을 권장한다.
- ReplicaSet은 특정 파드 템플릿을 기반으로 한 원하는 복제본 수를 유지하며 파드의 가용성과 확장성을 관리한다.
- 주요 특징은 ReplicationController과 동일하며 차이점은 아래와 같다.
ReplicationController과의 차이점
- 선택자 표현식(Selector Expression)
- ReplicationController: ReplicationController는 파드 선택에 사용하는 레이블 셀렉터를 단순한 평등 연산자만 지원한다. 이는 완전한 유연성을 제공하지 않고, 정확한 레이블 일치가 필요히다.
- ReplicaSet: ReplicaSet은 선택자 표현식(Selector Expression)을 지원하여 파드 선택에 보다 더 복잡한 조건을 적용할 수 있다. 이로 인해 파드를 더 정교하게 선택할 수 있다.
- 롤링 업데이트 및 롤백
- ReplicationController: ReplicationController는 파드 업데이트 및 롤백에 대한 기능이 상대적으로 제한적이다. 업데이트 시 일괄적으로 모든 파드를 교체한다.
- ReplicaSet: ReplicaSet은 롤링 업데이트 및 롤백을 보다 유연하게 지원한다. ReplicaSet을 사용한 Deployment는 파드 업데이트를 통해 일부 파드를 먼저 업데이트하고 다음에 나머지 파드를 업데이트하는 롤링 업데이트 전략을 적용할 수 있다.
- 레이블 셀렉터 표현식:
- ReplicationController: ReplicationController는 단순한 레이블 셀렉터를 사용하며 레이블의 표현식을 지원하지 않는다.
- ReplicaSet: ReplicaSet은 표현식을 사용하여 레이블 셀렉터를 더 정교하게 설정할 수 있다.
- 표시 이름(Label Selector):
- ReplicationController: ReplicationController는 matchLabels를 사용하여 파드를 선택한다.
- ReplicaSet: ReplicaSet은 matchExpressions 및 matchLabels를 모두 사용하여 파드를 선택할 수 있다.
- API 그룹(API Group):
- ReplicationController: ReplicationController는 api/v1 API 그룹에 속하며, 기본적인 기능만 제공한다.
- ReplicaSet: ReplicaSet은 apps/v1 API 그룹에 속하며, 보다 더 발전된 기능과 확장성을 제공한다.
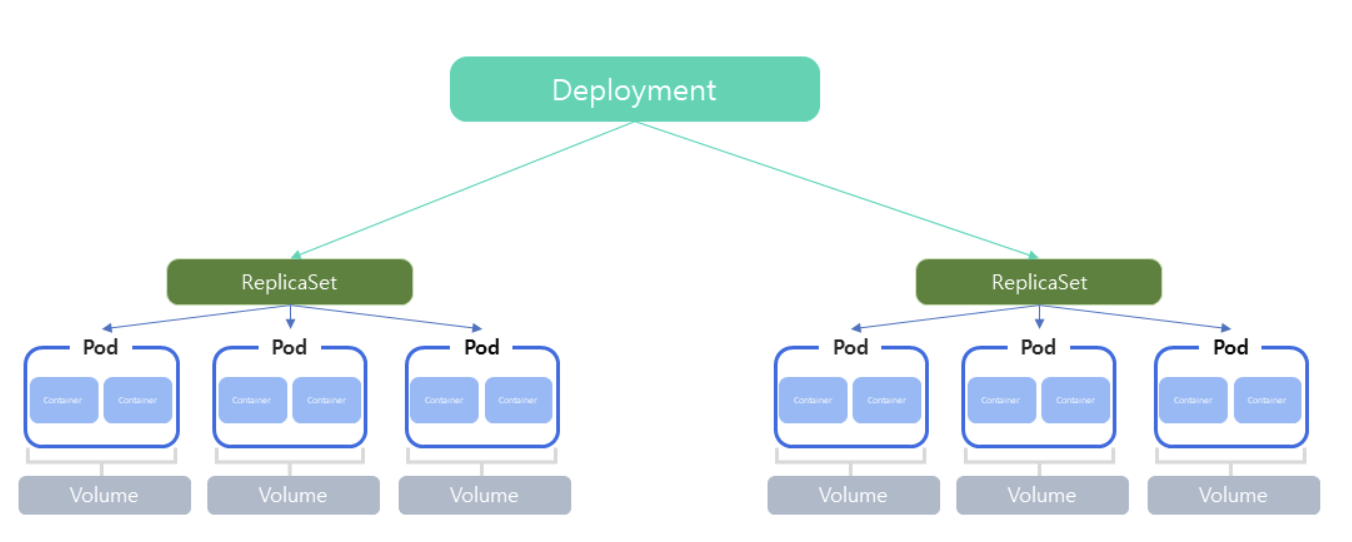
Deployment
- Deployment는 Kubernetes에서 애플리케이션 배포와 관리를 단순화하고 자동화하기 위한 리소스 객체이다.
- Deployment를 사용하면 애플리케이션 업데이트, 롤백, 확장 및 파드 스케일링을 쉽게 수행할 수 있다.
- Deployment는 ReplicaSet의 상위 개념으로, 파드와 ReplicaSet에 대한 배포를 관리한다.
- 운영 중에 어플리케이션의 새 버전을 배포해야하거나 부하가 증가하면서 ReplicaSet을 추가하는 등 여러 가지 동작을 Deployment로 관리할 수 있다.
- Deployment는 배포에 대한 이력을 관리하는데 만약 배포한 새버전의 문제가 생긴 경우 Deployment를 통해 쉽게 이전 버전으로 롤백할 수 있다.
- 쿠버네티스로 서비스를 운영하는 상황이라면 ReplicaSet만으로 운영하기 보다는 대부분 Deployment단위로 Pod와 ReplicaSet을 관리하여 운영한다.
- Deployments에서 자주 사용되는 배포 전략으로는 Rolling Update, Blue/Green, Canary 등이 있다.
주요 특징
- 더 안전한 업데이트 및 롤백
- Deployment는 애플리케이션 업데이트를 관리하고 롤백할 수 있는 기능을 제공한다.
- 새로운 애플리케이션 버전을 배포할 때, Deployment는 이전 버전의 파드를 유지한 채로 새로운 버전의 파드를 점진적으로 생성하고 활성화시킨다.
- 이로써 업데이트가 원활하게 이루어지며, 문제가 발생하면 이전 버전으로 롤백할 수 있다.
- 자동 파드 관리
- Deployment는 관리하려는 파드의 원하는 상태를 정의하는 파드 템플릿을 사용한다.
- Deployment는 이 템플릿을 기반으로 원하는 수의 파드 복제본을 유지하고, 파드가 실패하면 자동으로 재생성한다.
- 스케일링 및 로드 밸런싱
- Deployment는 파드의 수평 스케일링을 지원하며, replicas 필드를 업데이트하여 파드의 수를 늘리거나 줄일 수 있다.
- 또한, 서비스(Service)와 연계하여 애플리케이션에 대한 로드 밸런싱을 제공할 수 있다.
- 업데이트 전략 커스터마이징
- Deployment는 업데이트 전략(rolling update strategy)을 커스터마이징할 수 있다.
- 업데이트 속도, 동시 업데이트 파드 수 등을 조절하여 애플리케이션 업데이트의 세부 사항을 제어할 수 있다.
- 이력 및 롤백
- Deployment는 애플리케이션 업데이트 이력을 기록하며, 이전 버전으로 롤백하는 데 사용할 수 있는 업데이트 이력을 관리한다.
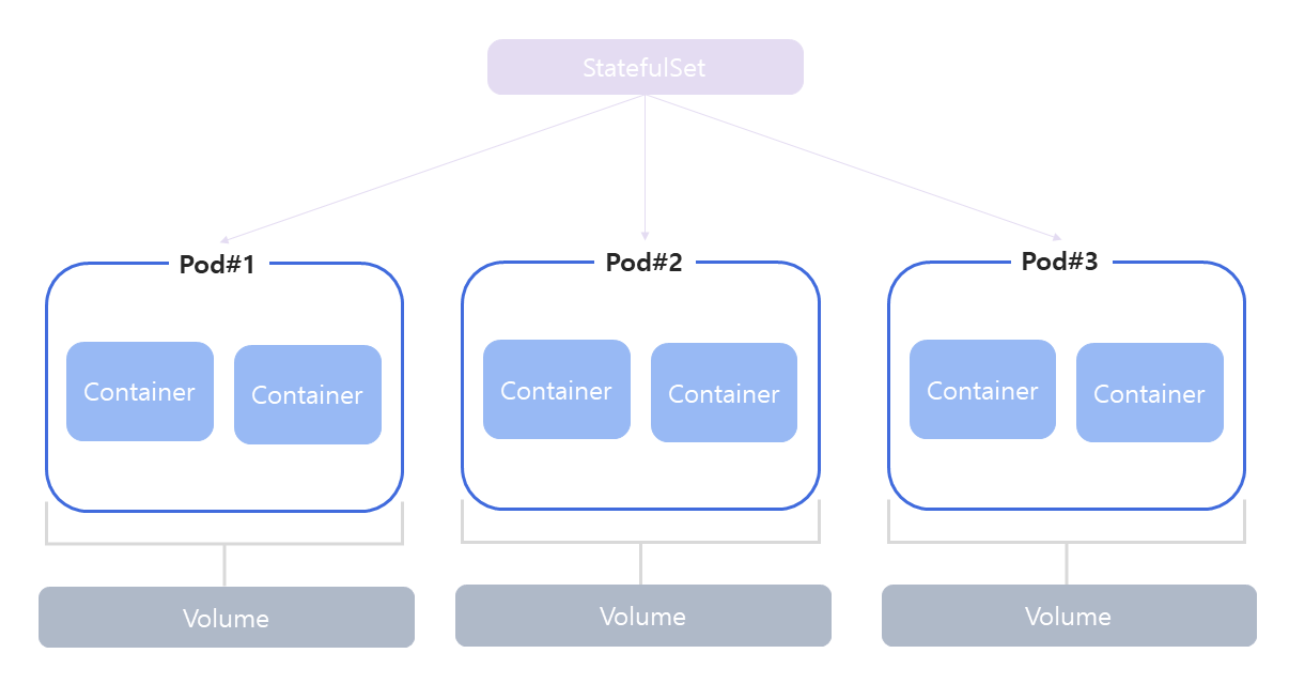
StatefulSet
- StatefulSet은 Kubernetes에서 상태가 있는 애플리케이션(예: 데이터베이스, 메시지 큐, 저장소)을 배포하고 관리하기 위한 리소스 객체이다.
- StatefulSet은 각 파드에 고유한 식별자를 부여하고, 파드 간의 안정적인 네트워킹과 순서 있는 배치를 제공하여 상태를 보존하고 확장 가능한 방식으로 운영한다.
- Deployment를 통해 파드를 삭제하고 생성하면 완전히 새로운 가상환경이 시작되는데, 이 경우 StatefulSet을 사용하여 파드를 생성하면 파드가 삭제되고 재생성되어도 기존의 상태를 그대로 유지할 수 있다.
- StatefulSet은 주로 데이터베이스 클러스터, 메시지 큐, 오픈소스 데이터 스토어 등과 같이 상태를 가지는 애플리케이션을 배포하고 운영하기 위해 사용된다.
- 이러한 애플리케이션은 순서 있고 안정적인 배치를 필요로 하며, 각각의 파드가 고유한 데이터 또는 상태를 가지고 있어야한다.
- Deployment는 Rolling Update, Blue/Green, Canary 배포 등 다양한 배포를 지원하지만 SatetfulSet은 On Delete와, Rolling Update 배포만 지원한다는 점에서 차이점이 있다.
주요 특징
- 고유한 파드 식별자
- StatefulSet은 각 파드에 고유한 이름을 부여하며, 파드의 이름은 StatefulSet의 이름과 숫자로 구성된다(예: web-0, web-1, web-2 등).
- 이러한 고유한 이름은 파드가 재시작되더라도 변경되지 않으므로 데이터베이스와 같은 상태 유지 애플리케이션에서 중요하다.
- 파드가 추가될 경우 생성된 파드의 마지막 번호(예: web-2)의 다음 번호(예: web-3)로 생성되며 삭제될 경우 마지막 번호(예: web-3)부터 삭제된다.
- 순차적 배포
- StatefulSet은 파드를 순차적으로 배포하고 시작하므로 파드 간에 의존성이 있는 애플리케이션의 경우 안정적으로 시작될 수 있다.
- 볼륨 보존
- StatefulSet은 각 파드에 고유한 볼륨을 동적으로 할당하고 관리하여 데이터의 안정성을 보장한다.
- 이로써 데이터는 파드가 재시작되거나 이동되더라도 지속적으로 보존된다.
- 스케일링
- StatefulSet은 파드의 수평 및 수직 스케일링을 지원한다.
- 스케일링 시에도 파드에 고유한 이름이 부여된다.
- 서비스 디스커버리
- StatefulSet은 Headless Service를 자동으로 생성하며, 파드에 DNS 이름을 부여하여 내부에서 서로 찾아볼 수 있도록 한다.
- 이를 통해 서로 다른 파드 간의 통신이 용이해진다.
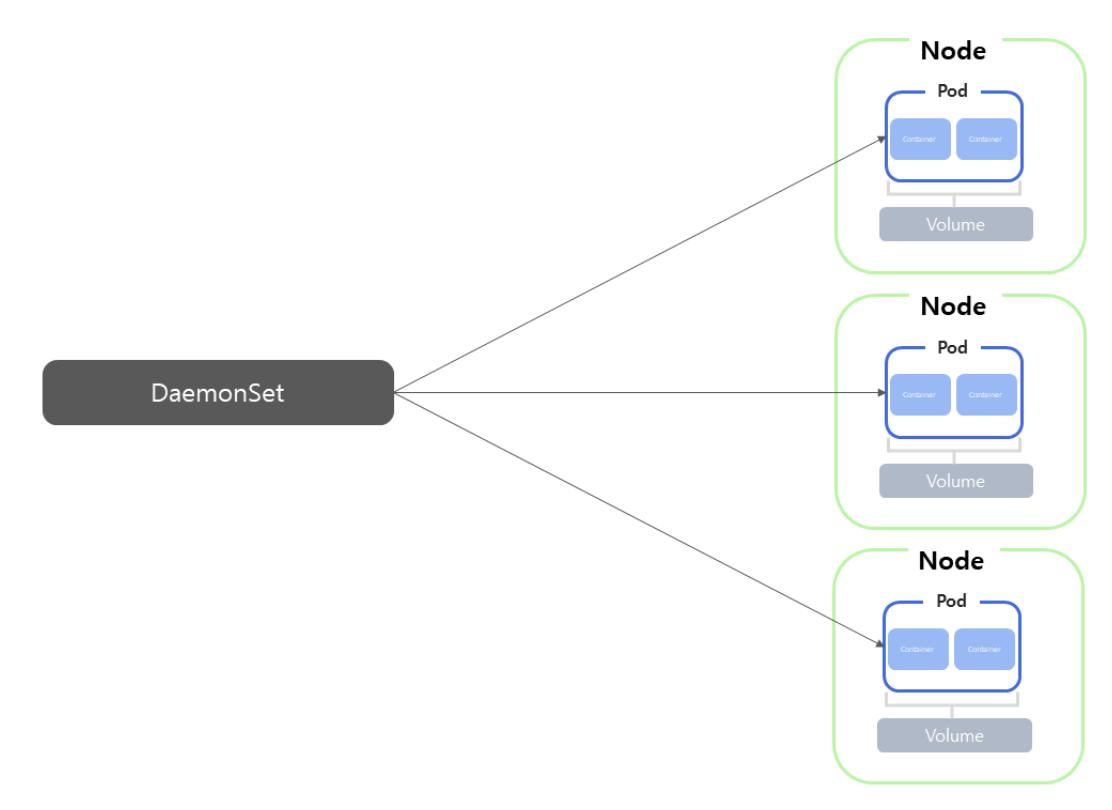
DaemonSet
- DaemonSet 또한 Deployment와 유사하게 파드를 생성하고 관리하지만, DaemonSet은 Kubernetes에서 DaemonSet이 관리하는 파드는 기본적으로 모든 노드에 균등하게 생성되지만, 특정 노드에만 파드가 하나씩 생성되도록 구성할 수도 있다.
- 예를 들어 각 노드의 모니터링 환경을 구성하기 위해 노드 마다 로그 수집용 파드를 실행해야 하는 경우 DaemonSet을 사용하여 파드를 관리하면 노드가 추가되어도 로그 수집용 파드가 자동으로 노드에 추가되어 좀 더 쉽게 모니터링 환경을 구축할 수 있다.
주요 특징
- 노드 수준 배포
- DaemonSet은 클러스터 내의 모든 노드 또는 특정 노드 그룹에 하나의 파드 인스턴스를 배포한다.
- 이것은 각 노드에서 특정 작업을 실행하기 위한 이상적인 방법이다.
- 스케줄링 제어
- DaemonSet은 특정 노드 그룹에 파드를 배치하도록 제어할 수 있다.
- 레이블 셀렉터를 사용하여 특정 노드에만 DaemonSet을 배치하거나 배치하지 않을 수 있다.
- 자동 롤아웃 및 업데이트
- DaemonSet을 사용하여 업데이트된 이미지 또는 구성 변경 사항을 적용하는 것이 가능하다.
- DaemonSet은 롤링 업데이트를 자동으로 수행하여 이전 버전의 파드를 안전하게 종료하고 새 버전을 시작한다.
- 파드 안정성
- DaemonSet은 파드가 계속 실행되도록 보장한다.
- 노드가 죽거나 새로운 노드가 클러스터에 추가될 때 새 파드 인스턴스를 시작하여 파드의 안정성을 제공한다.
- 애플리케이션 배포에 유용
- DaemonSet은 클러스터 노드에서 실행되어야 하는 애플리케이션 컴포넌트(예: 로깅 에이전트, 모니터링 에이전트, 스토리지 드라이버)를 관리하는 데 매우 유용하다.
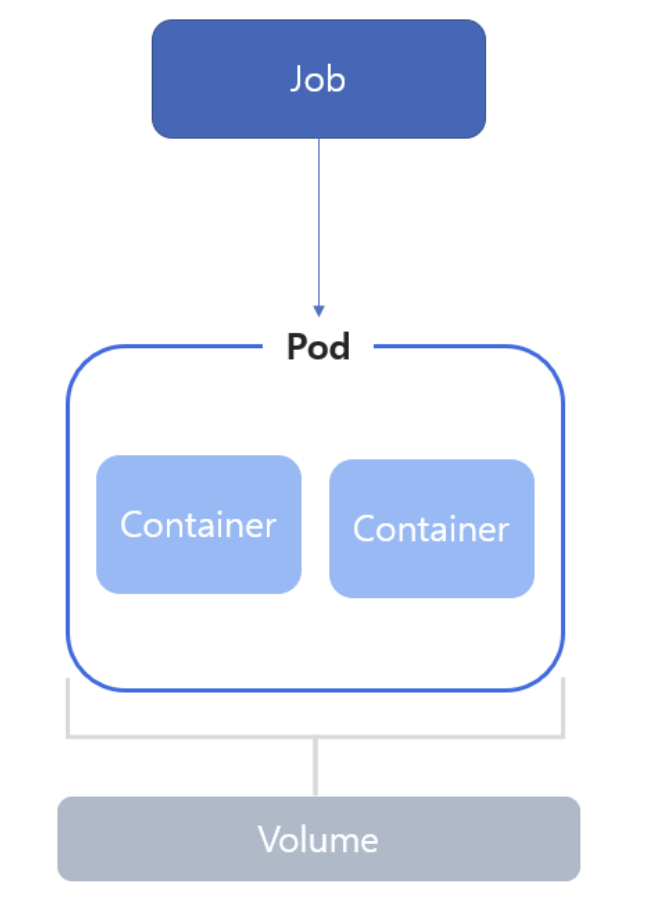
Job & CronJob
- Job은 하나 이상의 파드를 지정하고 지정된 수의 파드를 실행한다.
- 파드가 정상적으로 실행되지 않을 경우 Job은 새로운 파드를 새로 생성하고 실행한다.
- Job은 주로 백업이나 배치 작업과 같은 한번 실행되고 종료되는 작업에 사용된다.
- Job은 재실행 정책에 따라 파드 생성 실패시 수행하는 작업이 달라진다.
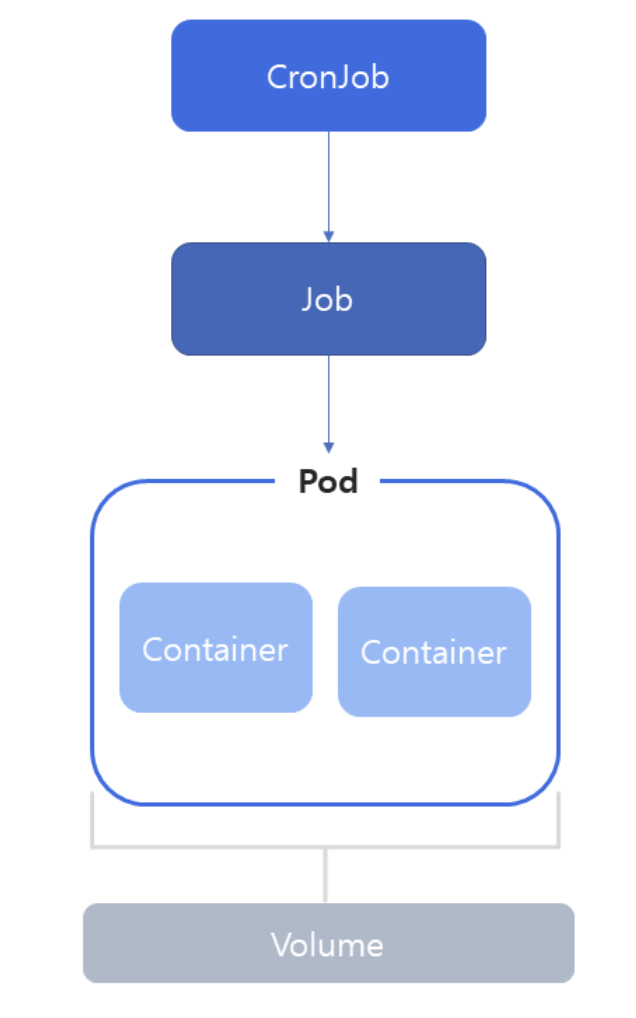
- CronJob은 이름 그대로 Job을 주기적으로 실행 시킨다.
- Linux의 Crontab과 유사하며 CronJob은 주로 특정 시간에 실행되거나 일정 주기마다 실행해야 하는 작업에 사용된다.