Algorithm - 알고리즘
정렬된 범위 알고리즘
정렬된 범위 알고리즘은 정렬된 순차열에서만 동작한다.
➡ '정렬'은 특정 정렬 기준에 따라 원소에 순서가 있다는 의미 (기본 오름차순)
정렬되지 않은 순차열에 사용하면 잘못된 결과를 얻을 수 있다.
| 알고리즘 함수 | 사용 형태 (인자) | 역할 | 반환값 |
|---|---|---|---|
| binary_search | binary_search(first, last, val)binary_search(first, last, val, comp) | 정렬된 범위에서 값 존재 여부 확인 | bool |
| includes | includes(a_first, a_last, b_first, b_last)includes(..., comp) | A가 B를 포함하는지 검사 | bool |
| lower_bound | lower_bound(first, last, val)lower_bound(first, last, val, comp) | val 이상인 첫 원소의 위치 반복자 반환 | 반복자 (iterator) |
| upper_bound | upper_bound(first, last, val)upper_bound(first, last, val, comp) | val 초과인 첫 원소의 위치 반복자 반환 | 반복자 (iterator) |
| equal_range | equal_range(first, last, val)equal_range(first, last, val, comp) | val과 같은 원소의 범위 반환 | pair<iterator, iterator> |
| merge | merge(a_first, a_last, b_first, b_last, out)merge(..., comp) | A와 B를 병합하여 out에 정렬된 상태로 복사 | out 범위의 끝 반복자 |
| inplace_merge | inplace_merge(first, mid, last)inplace_merge(..., comp) | [first, mid), [mid, last) 두 구간을 제자리 병합 | 없음 (void) |
| set_union | set_union(a_first, a_last, b_first, b_last, out)set_union(..., comp) | A ∪ B (합집합)를 정렬 상태로 out에 복사 | out 범위의 끝 반복자 |
| set_intersection | set_intersection(a_first, a_last, b_first, b_last, out)set_intersection(..., comp) | A ∩ B(교집합)를 정렬 상태로 out에 복사 | out 범위의 끝 반복자 |
| set_difference | set_difference(a_first, a_last, b_first, b_last, out)set_difference(..., comp) | A - B (차집합)를 정렬 상태로 복사 | out 범위의 끝 반복자 |
| set_symmetric_difference | set_symmetric_difference(a_first, a_last, b_first, b_last, out)set_symmetric_difference(..., comp) | A △ B (대칭 차집합)를 정렬 상태로 복사 | out 범위의 끝 반복자 |
🔷 '같다' 연산 주의점 🔷
정렬 기반 알고리즘은 원소를 찾을 때 두 원소 a, b에 대해 a == b 연산을 사용하지 않는다.
➡ !(a < b) && !(b < a) 연산을 사용한다.
🔹 !(a < b) && !(b < a) 의미
➡ "a도 b보다 앞서 위치하지 않고 b도 a보다 앞서 위치하지 않으면 같은 원소로 판단한다."
📌 binary_search()
정렬된 순차열에서 이진 탐색으로 검사하는 방식이다.
아래의 코드에서 원소 20을 찾을 때 !(a < b) && !(b < a) 연산을 사용해서 원소가 같은지 판단한다.
binary_search(first, last, val)➡[first, last)구간에서var원소 찾기 ➡ bool 반환
binary_search(first, last, val, comp)
✅ 일반 binary_search()
binary_search()의 기본 정렬 기준은 오름차순(less<int>())기 때문에,
모든 원소에 대해 !(20 < 원소) && !(원소 < 20)를 연산한다.
➡ 순차열 중 20이 있다면 !(20 < 원소) && !(원소 < 20)가 만족하기 때문에 true를 반환한다.
int main()
{
vector<int>v;
v.push_back(10);
v.push_back(20);
v.push_back(30);
bool check = binary_search(v.begin(), v.end(), 20);
if (check == true) cout << "찾았습니다" << endl; // 20을 찾았습니다
else cout << "찾지 못했습니다" << endl;
}🟥 조건자 버전 binary_search() ➡ 실패 예시
비교 기준에 따라 '같다'의 범위가 바뀌기도 한다. 아래의 예시를 보자
-
binary_search()를 사용하기 위해, 순차열을Calculate비교 함수에 따라 정렬해준다.
➡ 두 수의 차이가 3보다 큰 순으로 정렬 -
찾고 싶은 원소를 비교 함수에 따라 찾는다.
➡ 기준이 비교 함수가 되기 때문에 찾고자 하는 값과 순차열 내 원소의 차이가 3보다 작아서 false를 반환할 경우 값을 찾았다고 인식한다.
➡!(Calculate(32, 30) && !(Calculate(30, 32)➡ 비교 함수에 따라 32라는 원소를 찾았다. (실제 같은 원소는 아니지만) -
찾고자 하는 값 35는
!(Calculate(35, 30) && !(Calculate(30, 35)의 연산에서 원소의 차이가 3보다 크기 때문에 true를 반환한다. ➡ 35원소를 찾지 못했다는 판정
// 두 수의 차이가 3이상이라면 앞에 온다.
bool Calculate(int a, int b)
{
return 3 < b - a;
}
int main()
{
vector<int>v;
v.push_back(40);
v.push_back(46);
v.push_back(12);
v.push_back(80);
v.push_back(10);
v.push_back(47);
v.push_back(30);
v.push_back(55);
v.push_back(90);
v.push_back(53);
// 현재 상태 : 40 46 12 80 10 47 30 55 90 53
// binary_search()는 정렬 상태에서 사용하는 알고리즘이기 때문에 정렬 필수
sort(v.begin(), v.end(), Calculate); // 정렬 기준에 의해 정렬
// 정렬 상태 : 12 10 30 40 46 47 55 53 80 90
bool check = binary_search(v.begin(), v.end(), 32, Calculate); // 32를 찾는다
if (check == true) cout << "32 찾았습니다" << endl;
else cout << "32 찾지 못했습니다" << endl;
check = binary_search(v.begin(), v.end(), 35, Calculate); // 35 찾는다
if (check == true) cout << "35 찾았습니다" << endl;
else cout << "35 찾지 못했습니다" << endl;
}
✅ 조건자 버전 binary_search() ➡ 성공 예시
가장 일반적인 오름차순, 내림차순을 기준으로 정렬 & 비교 함수로 사용하면 더 쉽게 이해할 수 있다.
// 내림차순 bool Less(int a, int b) { return a < b; } // 오름차순 bool Greater(int a, int b) { return a > b; }
int main()
{
vector<int>v;
v.push_back(10);
v.push_back(30);
v.push_back(40);
v.push_back(50);
v.push_back(20);
sort(v.begin(), v.end()); // 기본 less 정렬
// 정렬 상태 : 10 20 30 40 50
bool check = binary_search(v.begin(), v.end(), 20, less<int>()); // 20 찾기
if (check == true) cout << "20 찾았습니다" << endl;
else cout << "20 찾지 못했습니다" << endl;
sort(v.begin(), v.end(), greater<int>()); // greater 정렬
// 정렬 상태 : 50 40 30 20 10
check = binary_search(v.begin(), v.end(), 30, greater<int>());
if (check == true) cout << "30 찾았습니다" << endl;
else cout << "30 찾지 못했습니다" << endl;
} 📌 includes()
한 순차열이 다른 순차열의 부분 집합인지 판별할 때 사용한다.
includes()를 사용할 때는 반드시 두 순차열을 같은 기준으로 정렬하고, 같은 비교 함수를 넣어야 정확하게 동작한다.
includes(a_first, a_last, b_first, b_last)➡ b구간이 a 구간에 포함되었는 지 bool 반환
includes(a_first, a_last, b_first, b_last, comp)
int main()
{
vector<int>v1;
v1.push_back(10);
v1.push_back(20);
v1.push_back(30);
v1.push_back(40);
v1.push_back(50);
vector<int>v2;
v2.push_back(10);
v2.push_back(20);
v2.push_back(40);
// v2가 v1에 포함되는 지
bool check = includes(v1.begin(), v1.end(), v2.begin(), v2.end()); // 오름차순 기준
if (check)
cout << "포함되었습니다" << endl;
else
cout << "포함되지 않았습니다" << endl;
// ----------------------------------------
sort(v1.begin(), v1.end(), greater<int>());
sort(v2.begin(), v2.end(), greater<int>());
check = includes(v1.begin(), v1.end(), v2.begin(), v2.end(), greater<int>()); // 내림차순 기준
if (check)
cout << "포함되었습니다" << endl;
else
cout << "포함되지 않았습니다" << endl;
} 📌 lower_bound() & upper_bound()
lower_bound : 찾고자 하는 값과 동일한 처음 원소의 반복자를 반환한다.
upper_bound : 찾고자 하는 값과 동일한 마지막 원소의 다음 반복자를 반환한다.
➡ 정렬된 순차열에서 사용하기 때문에, 마지막 원소의 다음 반복자는 찾고자 하는 값보다 큰 첫 원소의 반복자이다.
upper_bound(first, last, val)
upper_bound(first, last, val, comp)
int main()
{
vector<int>v1;
v1.push_back(10);
v1.push_back(20);
v1.push_back(30); // iter_lower
v1.push_back(30);
v1.push_back(30);
v1.push_back(40); // iter_upper
v1.push_back(50);
vector<int>::iterator iter_lower, iter_upper;
iter_lower = lower_bound(v1.begin(), v1.end(), 30); // 30과 동일한 첫 원소 반복자
iter_upper = upper_bound(v1.begin(), v1.end(), 30); // 30과 동일한 마지막 원소의 다음 반복자
} 📌 equal_range()
순차열에서 찾는 원소의 반복자 쌍(구간)을 얻을 때 사용한다. [ )
equal_range(first, last, val)➡ 찾고자 하는 값val의 시작 반복자와 끝 반복자 반환
equal_range(first, last, val, comp)
int main()
{
vector<int>v1;
v1.push_back(10);
v1.push_back(20);
v1.push_back(30); // iter_pair.first
v1.push_back(30);
v1.push_back(30);
v1.push_back(40); // iter_pair.second
v1.push_back(50);
pair<vector<int>::iterator, vector<int>::iterator> iter_pair;
iter_pair = equal_range(v1.begin(), v1.end(), 30);
cout << *iter_pair.first << " " << *iter_pair.second << endl;
} 📌merge()
순차열1과 순차열2를 순차열3으로 합병한다. ➡ 기존 순차열1과 순차열2의 원소는 그대로 남아있다.
merge(a_first, a_last, b_first, b_last, out)➡ b구간과 a 구간을 합병하여 out으로 저장
merge(a_first, a_last, b_first, b_last, out, comp)
int main()
{
vector<int>v1;
v1.push_back(10);
v1.push_back(20);
v1.push_back(30);
vector<int>v2;
v2.push_back(20);
v2.push_back(40);
v2.push_back(60);
vector<int>v3(10); // 사이즈 10
merge(v1.begin(), v1.end(), v2.begin(), v2.end(), v3.begin());
for (int i = 0; i < v3.size(); i++)
{
cout << v3[i] << " "; // 10 20 20 30 40 60 0 0 0 0
}
}
📌inplace_merge()
하나의 순차열이 두 구간으로 정렬되어 있을 때 하나의 구간으로 정렬하기 위해 사용한다.
inplace_merge(first, mid, last)➡[first, mid)구간 &[mid, last)구간
inplace_merge(first, mid, last, comp)
아래의 코드를 보면 하나의 순차열v1에 오름차순으로 정렬된 두 구간이 있다.
➡ 이를 하나의 오름차순 순차열로 만드는 것
int main()
{
vector<int>v1;
// [v1.begin() , v1.begin() + 3)
v1.push_back(10);
v1.push_back(20);
v1.push_back(30);
// [v1.begin() + 3, v1.end())
v1.push_back(20);
v1.push_back(40);
v1.push_back(60);
inplace_merge(v1.begin(), v1.begin()+3, v1.end());
for (int i = 0; i < v1.size(); i++)
{
cout << v1[i] << " "; // 10 20 20 30 40 60
}
}
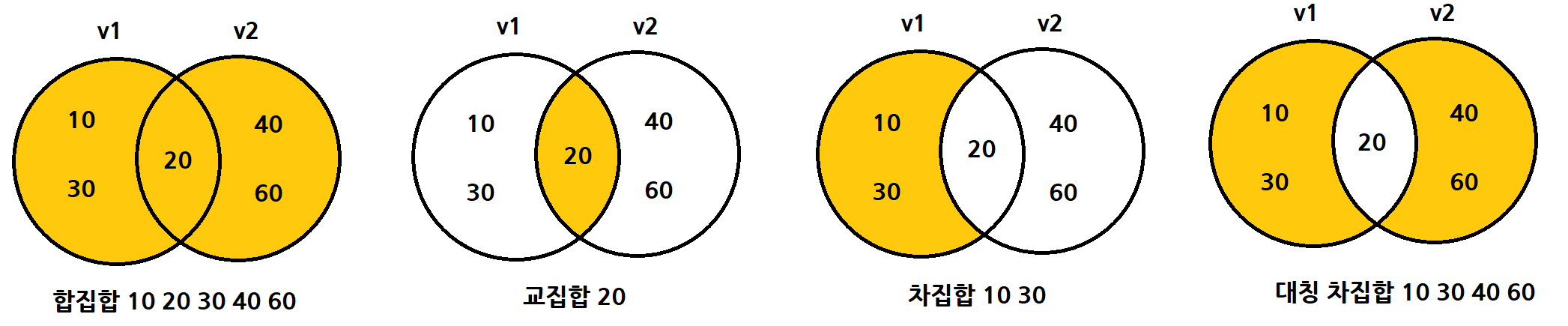
📌 set_union() ➡ 합집합 A ∪ B
a구간과 b구간의 원소 중 합집합을 out에 저장한다.
set_union(a_first, a_last, b_first, b_last, out)
int main()
{
vector<int>v1;
v1.push_back(10);
v1.push_back(20);
v1.push_back(30);
vector<int>v2;
v2.push_back(20);
v2.push_back(40);
v2.push_back(60);
vector<int>v3(6); // 사이즈 6
// v1 v2의 합집합을 v3에 저장
set_union(v1.begin(), v1.end(), v2.begin(), v2.end(), v3.begin());
for (int i = 0; i < v3.size(); i++)
{
cout << v3[i] << " "; // 10 20 30 40 60 0
}
} 📌 set_intersection() ➡ 교집합 A ∩ B
a구간과 b구간의 원소 중 교집합을 out에 저장한다.
set_intersection(a_first, a_last, b_first, b_last, out)
int main()
{
vector<int>v1;
v1.push_back(10);
v1.push_back(20);
v1.push_back(30);
vector<int>v2;
v2.push_back(20);
v2.push_back(40);
v2.push_back(60);
vector<int>v3(6); // 사이즈 6
// v1 v2의 교집합을 v3에 저장
set_intersection(v1.begin(), v1.end(), v2.begin(), v2.end(), v3.begin());
for (int i = 0; i < v3.size(); i++)
{
cout << v3[i] << " "; // 20 0 0 0 0 0
}
} 📌 set_difference() ➡ 차집합 A - B
a구간과 b구간의 원소 중 차집합을 out에 저장한다.
set_difference(a_first, a_last, b_first, b_last, out)
int main()
{
vector<int>v1;
v1.push_back(10);
v1.push_back(20);
v1.push_back(30);
vector<int>v2;
v2.push_back(20);
v2.push_back(40);
v2.push_back(60);
vector<int>v3(6); // 사이즈 6
// v1 v2의 차집합을 v3에 저장
set_difference(v1.begin(), v1.end(), v2.begin(), v2.end(), v3.begin());
for (int i = 0; i < v3.size(); i++)
{
cout << v3[i] << " "; // 10 30 0 0 0 0
}
} 📌 set_symmetric_difference() ➡ 대칭 차집합 A △ B
a구간과 b구간의 원소 중 대칭 차집합을 out에 저장한다.
➡ 대칭 차집합 : 합집합 - 교집합을 의미한다.
set_symmetric_difference(a_first, a_last, b_first, b_last, out)
int main()
{
vector<int>v1;
v1.push_back(10);
v1.push_back(20);
v1.push_back(30);
vector<int>v2;
v2.push_back(20);
v2.push_back(40);
v2.push_back(60);
vector<int>v3(6); // 사이즈 6
// v1 v2의 차집합을 v3에 저장
set_symmetric_difference(v1.begin(), v1.end(), v2.begin(), v2.end(), v3.begin());
for (int i = 0; i < v3.size(); i++)
{
cout << v3[i] << " "; // 10 30 40 60 0 0
}
}