
해시테이블
데이터를 효율적으로 저장하고 검색할 수 있는 자료구조이다
KEY 값과 VALUE값을 사용하여 값을 저장한다
- Key : 데이터 고유의 식별자 (Key값을 통해 value를 알아낸다)
- Value : 실제 저장될 데이터
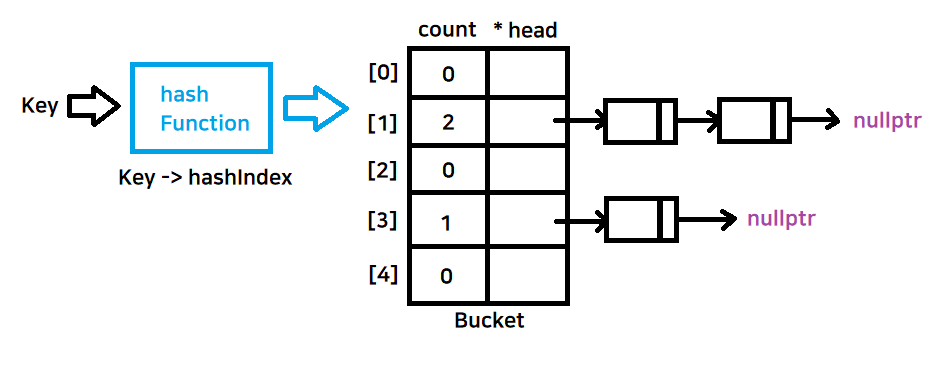
해시테이블 과정
- 해쉬함수는 Key값을 사용해 hashIndex로 바꿔주는 함수이다
-> 우리가 임의로 만들어 줄 것이다 - Bucket은 Key값과 Value값이 저장된 기본 저장공간 (배열의 형태)
- count 는 안에 들어간 노드의 갯수
- head는 노드를 가리키는 포인터
클래스 정의 & 생성자
-
template를 사용하여 메인에서 자료형을 지정하고 Key값과 Value를 받을 것이다
-
우리가 필요한 것은 노드들을 저장해둘 버킷, 키값과 벨류값을 가진 노드 구조를 만들어야한다
-
Node 구조체와 Bucket 구조체를 생성
-
생성자에서 bucket의 배열안의 내용을 초기화
#include <iostream>
#define SIZE 6
using namespace std;
template <typename KEY, typename VALUE>
// 배열로 구성
// 체이닝 기법은 단일연결리스트로 찾기
class HashTable
{
private:
struct Node
{
KEY key;
VALUE value;
Node* next;
};
struct Bucket
{
int count;
Node* head;
};
Bucket bucket[SIZE];
public:
HashTable()
{
for (int i = 0; i < SIZE; i++)
{
bucket[i].count = 0;
bucket[i].head = nullptr;
}
}
}HashFunction( ) 함수
키값을 넣으면 해쉬인덱스를 0 ~ 5 사이의 값으로 반환되게 하고싶다!
키 값이 int형(기본 템플릿)
- 매개변수로 key값을 받고 지정해둔 SIZE로 나눈 나머지 값이 hashIndex로 지정된다
- T 타입의 매개변수가 들어오고 강제형변환으로 int형이 된 뒤 계산된다
키 값이 문자열일때
- key값이 문자열이면 value 변수를 선언한 뒤 각 문자열의 값을 value에 누적시키고 SIZE로 나눈 나머지 값이 hashIndex
- template<> : 템플릿 특수화
-> 템플릿 특수화는 템플릿 함수가 특정 타입에 대해 다르게 동작해야 할 경우에 사용된다
-> 여기서 기본 템플릿의 경우는 T타입으로 자료형을 받아 처리하면 되지만, 문자열의 경우는 아스키코드를 모두 합한 뒤 처리해야하기 때문에 다른 처리가 필요하다. 따라서 템플릿 특수화를 선언
// 0 ~ 5 사이의 값 반환 (인덱스)
int HashFunction(T key)
{
// 강제 형변환
int hashIndex = (int)key % SIZE;
return hashIndex;
}
// 템플릿 특수화
template<>
// 문자열 받기
int HashFunction(const char* key)
{
int value = 0;
for (int i = 0; i < strlen(key); i++)
{
value += key[i];
}
int hashIndex = value % SIZE;
return hashIndex;
}CreateNode( ) 함수
- 일반 노드 만드는거랑 비슷하다
- 노드 안에 next 포인터가 있고 기본은 nullptr을 가리키고 있다
- 노드 안에는 키값과 벨류값이 저장되어있다
버킷에 데이터를 삽입할때 사용되는 함수이다
// 새 노드 만들기
Node* CreateNode(KEY key, VALUE value)
{
Node* newNode = new Node;
newNode->key = key;
newNode->value = value;
newNode->next = nullptr;
return newNode;
}Insert( ) 함수
void Insert(KEY key, VALUE value)
{
// 해시 함수를 통해서 값을 받는 임시 변수
int hashIndex = HashFunction(key);
// 새로운 노드를 생성합니다.
Node* newNode = CreateNode(key, value);
// 노드가 1개라도 존재하지 않는다면
if (bucket[hashIndex].head == nullptr)
{
// bucket[hashIndex]의 head 포인터가 newNode를 가리키게 합니다.
bucket[hashIndex].head = newNode;
}
else
{
// 새 노드의 next는 bucket의 head만 주소를 알고있음
newNode->next = bucket[hashIndex].head;
// 새 노드로 head 옮겨주기
bucket[hashIndex].head = newNode;
}
// bucket[hashIndex]의 count를 증가시킵니다.
bucket[hashIndex].count++;
}-
- 매개변수로 Key값과 Value값을 받는다
-
- HashFunction을 통해 매개변수 Key값을 HashIndex로 반환한다
-
- 새 노드를 생성한다
-
- 노드가 하나도 없다면 newNode생성 후 연결
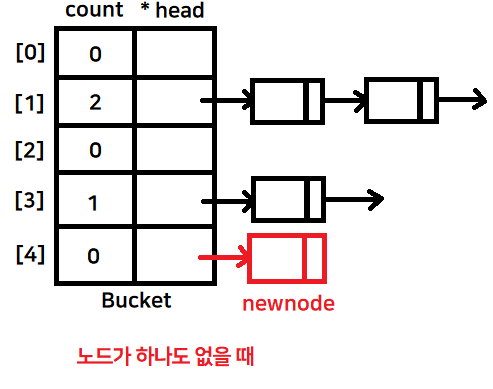
- 노드가 하나도 없다면 newNode생성 후 연결
-
- 노드가 이미 존재한다면 해시 충돌
-
- 체이닝 기법을 통해 연결리스트로 이어준다
-> 우리는 head를 가리키는 거 밖에 모르기 때문에 새로운 노드가 들어오면 head쪽으로 넣어야한다
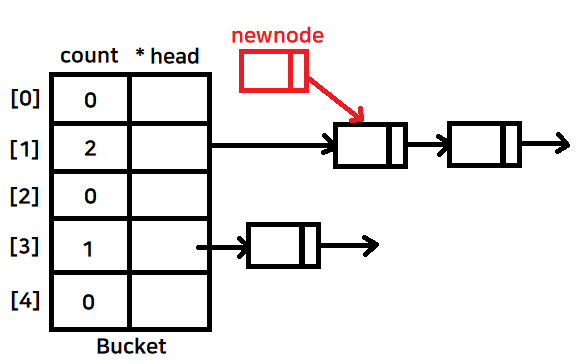
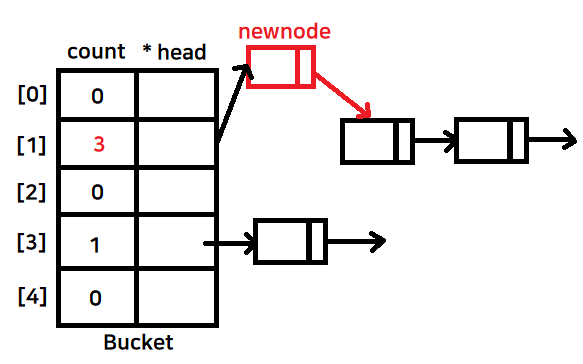
- 체이닝 기법을 통해 연결리스트로 이어준다
해시충돌이란?
서로 다른 키가 같은 해시인덱스 값을 가질때 충돌이 일어난다!
이를 해결하기 위해 체이닝(chaining) 기법을 사용
즉, 버킷을 연결리스트로 만들어서, 충돌이 발생할 때 동일한 해시 버킷에 여러 키값을 저장하는 것이다

Remove( ) 함수
void Remove(KEY key)
{
// 1. 해시 함수를 통해서 값을 받는 임시 변수
int hashIndex = HashFunction(key);
// 2. Node를 탐색할 수 있는 포인터 변수 선언
Node* currentNode = bucket[hashIndex].head;
// 3. 이전 Node를 저장할 수 있는 포인터 변수 선언
Node* previousNode = nullptr;
// 4. currentNode가 nullptr과 같다면 함수를 종료합니다.
if (currentNode == nullptr)
{
cout << "Not Key Found" << endl;
return;
}
else
{
// 5. currentNode를 이용해서 내가 찾고자 하는 Key값을 찾습니다.
while (currentNode != nullptr)
{
if (currentNode->key == key)
{
// head가 찾고하자하는 Key값일때
if (currentNode == bucket[hashIndex].head)
{
bucket[hashIndex].head = currentNode->next;
}
else
{
previousNode->next = currentNode->next; // nullptr
}
bucket[hashIndex].count--;
delete currentNode;
return;
}
else
{
previousNode = currentNode;
currentNode = currentNode->next;
}
}
cout << "Not Key Found" << endl;
}
}우리는 매개변수로 내가 지우고자 하는 key값을 넣어야한다
-
노드를 탐색할 수 있는 currentNode 생성
-
currentNode의 이전노드를 알려주는 previousNode 생성
-
원하는 값을 currentNode가 찾을 때 까지 previousNode 와 currentNode를 갱신 시켜줘야 한다
-> previousNode가 필요 한 이유 !!
-> 내가 지우고자 하는 값이 head가 가리키는 곳이면 상관이 없지만, 만약 내가 지우고 싶은 값이 노드들의 중간쯤에 있다고 하면, currentNode로 내가 지우고 싶은 값에 접근하여서 지우면 currentNode의 이전노드가 가리킬 수 있는 곳이 없다(정보가 없기 때문)
-
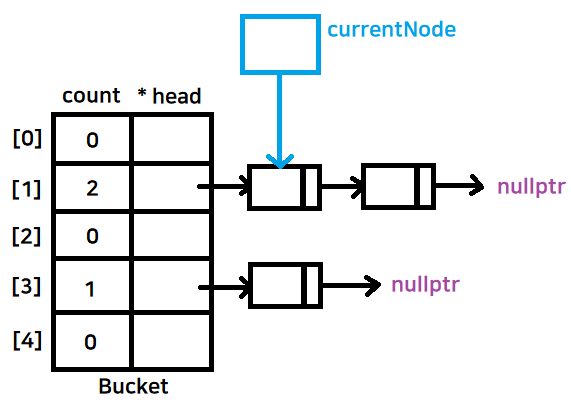
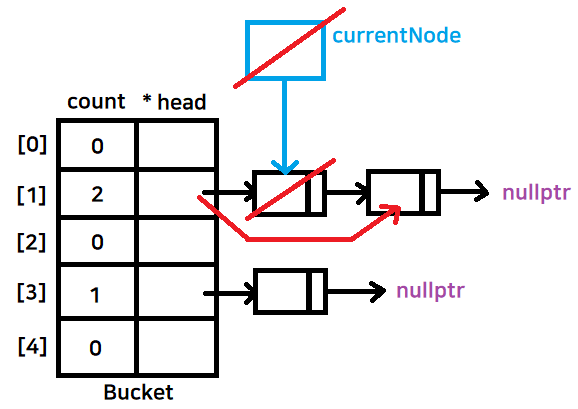
만약 currentNode가 가리키는 값이 head이고, 내가 지우고자 하는 값일때
head를 currentNode의 next로 옮겨주고 delete
-
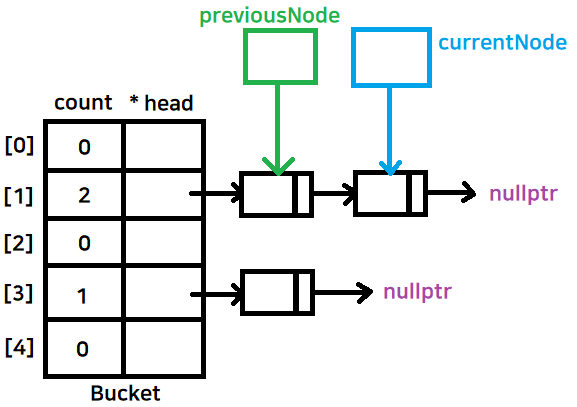
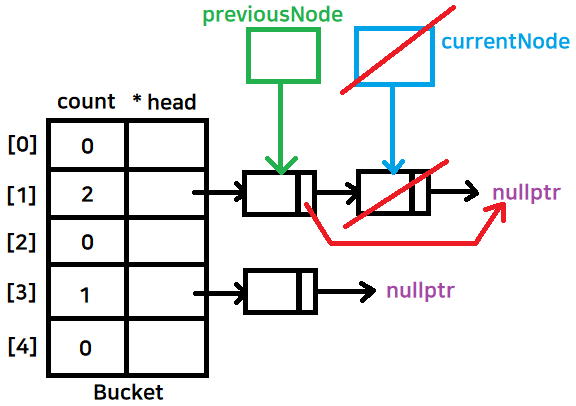
만약, 내가 지우고자 하는 값이 currentNode에 왔고, head가 아닐경우
previousNode->next를 nullptr로 가리킨다
while문이 currentNode != nullptr조건이기 때문에 currentNode의 next는 nullptr이다
- 만약, 모든 노드를 다 순회했는데도 내가 원하는 키 값이 없으면 "Not Found" 출력
Show( ) 함수
- 데이터 값을 순회해줄 currentNode 포인터 생성하고 head를 가리킴
- 반복문을 사용해서 모든 bucket안의 노드들을 순회해서 데이터를 출력할 것 이다
- currentNode가 nullptr이면 노드의 끝인 것
-> nullptr에 도달하면 while문을 탈출한 뒤 다시 for문으로 이동해서 다음 bucket의 노드 탐색
void Show()
{
// 1. currentNode 생성 0~ 5까지 bucket.head == nullptr이면 노드 출력
for (int i = 0; i < SIZE; i++)
{
Node* currentNode = bucket[i].head;
while (currentNode != nullptr)
{
cout << "[" << i << "]" << " " << "{KEY : " << currentNode->key
<< "VALUE : " << currentNode->value << "} ";
currentNode = currentNode->next;
}
cout << endl;
}
}소멸자
- 데이터를 하나씩 해제해주어야 하는데, 우리는 head가 가리키는 값만 알고있기 때문에 head가 마지막에 nullptr을 가리키게 하려면 다음노드의 정보를 알 수 있는 포인터가 필요하다
-> 따라서, 삭제시키기 위한 deleteNode 포인터와 다음 노드 정보를 가지는 nextNode 포인터를 생성
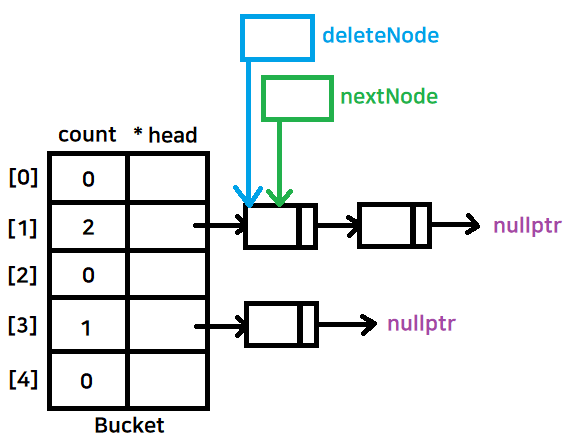
- nextNode 가 먼저 다음 노드로 이동하고 deleteNode가 가리키는 곳을 delete
- deleteNode를 nextNode쪽으로 이동
- 앞쪽부터 뒤로 하나씩 삭제
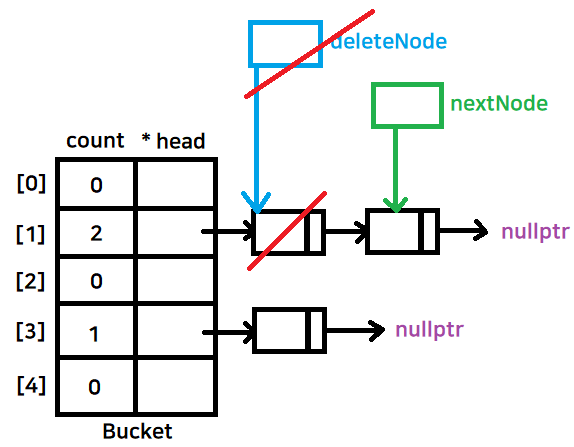
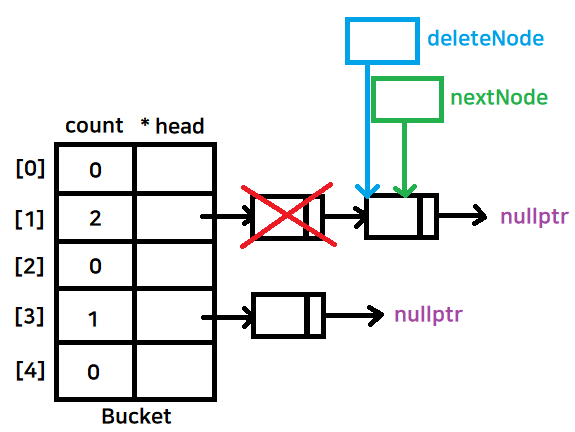
// 소멸자
~HashTable()
{
for (int i = 0; i < SIZE; i++)
{
Node* deleteNode = bucket[i].head;
Node* nextNode = bucket[i].head;
if (bucket[i].head == nullptr)
{
continue;
}
else
{
while (nextNode != nullptr)
{
nextNode = deleteNode->next;
delete deleteNode;
deleteNode = nextNode;
}
}
}
}코드를 보고 그림을 그려봤을때, nextNode가 이동하고 deleteNode가 가리키는 곳의 데이터를 해제하였을때, head가 데이터를 해제한 부분을 가리키고 있어서 문제가 될 거 라고 생각했다
-> 소멸자에서 구현하는 거기 때문에 추후 다른 걸 사용하는 게 아니어서 이대로도 상관이없긴 하다.
-> 걱정되면 head 를 nullptr로 가리키게 해주자
메인함수
- Key값과 Value값을 매개변수로
int main()
{
HashTable<const char*, int> hashTable;
hashTable.Insert("Sword", 10000);
hashTable.Insert("Armor", 30000);
hashTable.Insert("Potion", 70000);
hashTable.Remove("Sword");
hashTable.Remove("Gloves");
hashTable.Show();
return 0;
}출력값: Gloves는 없는 키 값

해시테이블 장/단점
해시테이블 장점
- 빠른 검색,삽입,삭제가 가능하다. 시간복잡도 O(1) 상수시간
-> 상수시간인 이유!! - HashFunction함수를 사용하여 바로 bucket에 매핑하기 때문이다
- 해쉬함수를 거치면서 Key 값이 해쉬인덱스로 변환하여 바로 접근이 가능해진다
- 하지만 해시충돌이 일어나서 체이닝 기법을 사용하게 되면 연결리스트로 이어진 노드들 중에서 원하는 값을 찾아야 하는경우 (최악의 경우 시간복잡도 O(n) )
해시테이블 단점
- 해시 충돌이 많이 생기면 성능이 저하된다
- 해시테이블의 크기를 너무 많이 설정하거나 하면 빈 공간이 많이 남아 충돌이 더 많이 발생한다
- 만약, 자료 구조에 삽입한 N개의 키가 모두 동일한 해시값을 가지면 탐색에 O(N) 시간복잡도가 걸린다
해시테이블 사용 경우
해시 함수가 충분히 괜찮은 성능을 보일 때, 임의의 키값에 대한 해시값이 어떤 특정한 값이 될 확률은 1/M 이다 (해시충돌이 일어날 확률이 1/M 이라는 것)
-> 단순 균일 해시 가정을 만족한다면 O(1) 시간복잡도가 지켜진다
단순 균일 해시 가정: 해시 함수가 키를 균등하게 분포시킨다고 가정하는 것
🔹 해시함수는 역함수가 존재하지 않는다.
-
입력값을 알 때는 출력값을 쉽게 구할 수 있지만, 출력값만 가지고는 입력값을 되찾는 게 계산적으로 불가능해야 한다.
-
입력 공간에 비해 출력 공간(고정된 해시 값 크기)은 훨씬 작기 때문에 여러 입력이 같은 해시 값으로 충돌하기 때문이다.
해시충돌 시 이중 해싱 방법
해시 충돌이 발생하면 해결방법으로 위에서 사용한 체이닝 기법도 있지만, 개방주소법도 사용할 수 있다
개방주소법 (Open Addressing) : 해시 충돌이 발생하면 충돌이 일어난 버킷을 피해서 다른 버킷에 데이터를 저장하는 방식
- 선형탐색
-> 돌이 발생하면, 해당 버킷에서 한 칸씩 차례로 이동하며 빈 공간을 찾습니다. (클러스터링 현상 발생) - 2차 탐색
-> 충돌이 발생하면 한 칸씩이 아니라 제곱수 만큼 이동하여 새로운 빈 공간을 찾습니다. - 이중해싱
-> 두 번째 해시 함수 값을 이용해 충돌을 해결하는 방법입니다. 두 번째 해시 함수는 첫 번째
해시값과 관계 없이 새로운 해시값을 생성하여 이를 기반으로 이동
- 첫 번째 해시 함수: h1(k) = (k % m) - 주 해시 함수로 테이블의 인덱스를 결정합니다.
- 두 번째 해시 함수: h2(k) = 1 + (k % (m - 1)) - 충돌 해결을 위한 추가 해시 함수입니다.
충돌이 발생한 경우, i = (i0 + j * h2(k)) % m
- 리사이징
-> 해시테이블의 크기가 일정 비율 이상 차면 크기를 증가시켜, 충돌을 줄이고 성능을 향상시키는 방법입니다.
