
5장 반복문
SQL 레벨업이라는 도서를 정리한 내용입니다.
5장은 개인적으로 어려운 부분이여서 정리를 자세히 하였습니다.
5장을 요약하면 아래와 같습니다.
SQL에서 함부로 반복문을 사용하지 마라.
SQL에는 반복문이 없다
RDB에는 반복문이 없다. 이는 SQL에서 반복문이 없는 게 좋다고 판단했기 때문이다.
내부적으로는 반복문 사용
SQL을 사용하는 사용자들은 반복문이 없다는 사실에 당황하며 아래와 같은 시스템을 만든다.
- 온라인 처리에서 화면에 명세를 출력하기 위해 레코드에 하나 씩 접근하는 SELECT 구문을 반복 사용
- 배치 처리에서 대량의 데이터를 처리할 때 레코드를 하나씩 호스트 언어에서 처리하고 테이블에 갱신
이 방식들이 무조건 잘못된 방식은 아니다. 실제로 SQL에서 내부적으로 반복계 코드를 사용하는 경우도 있다.
다만 생각없이 위와 같은 시스템을 만든다면 큰 문제가 발생할 수 있다.
반복계 코드
아래에 2개의 테이블이 있다. 특정 기업의 매출 변화를 Sales2 테이블의 var 필드에 저장하고자 한다.
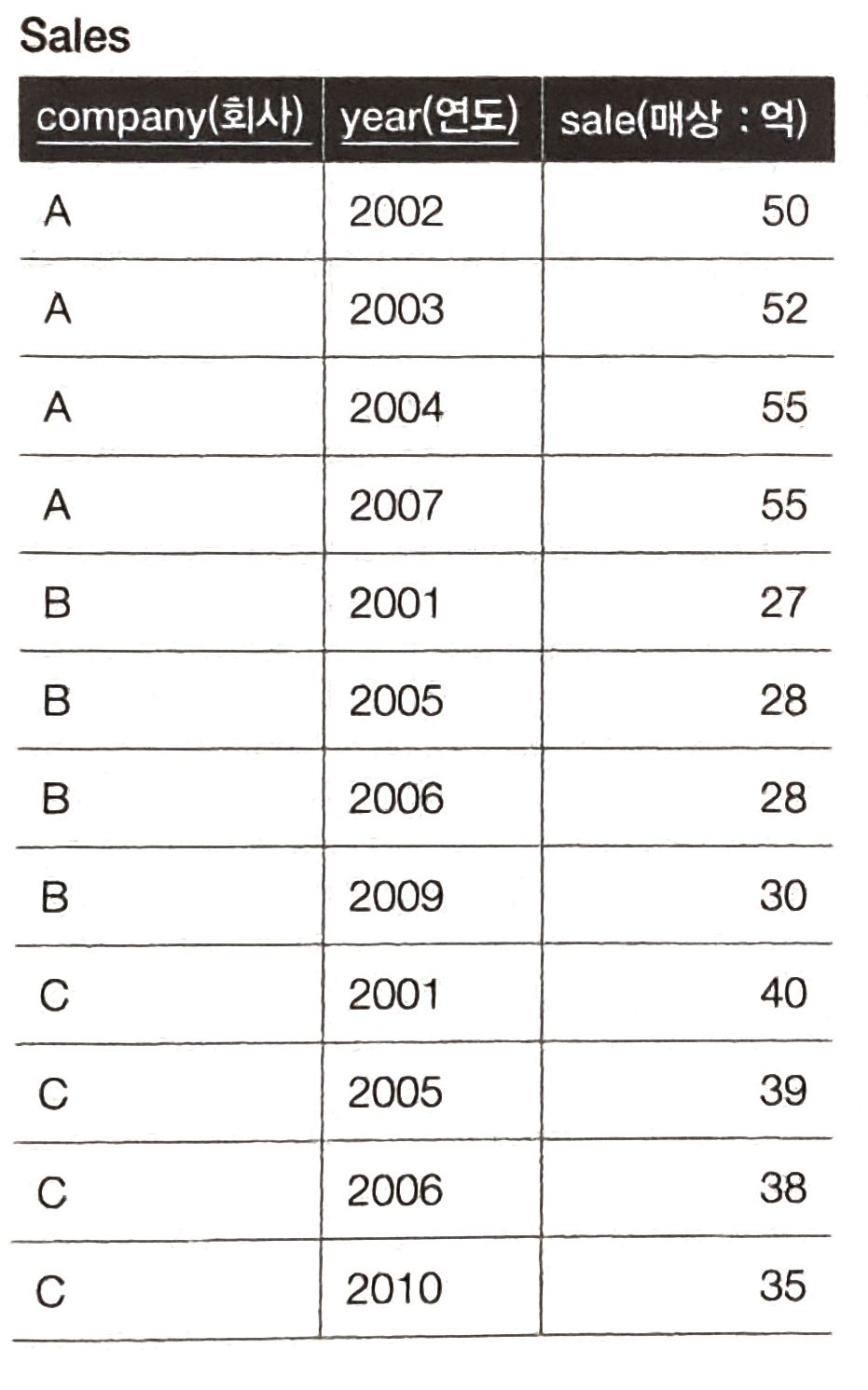
var 필드는 다음과 같은 규칙을 가진다.
- 이전 테이터가 없을 경우 : NULL
- 이전 테이터보다 매출이 오른 경우 : +
- 이전 테이터보다 매출이 내린 경우 : -
- 이전 테이터와 매출이 동일한 경우 : =
따라서 결과는 이처럼 나와야 한다.
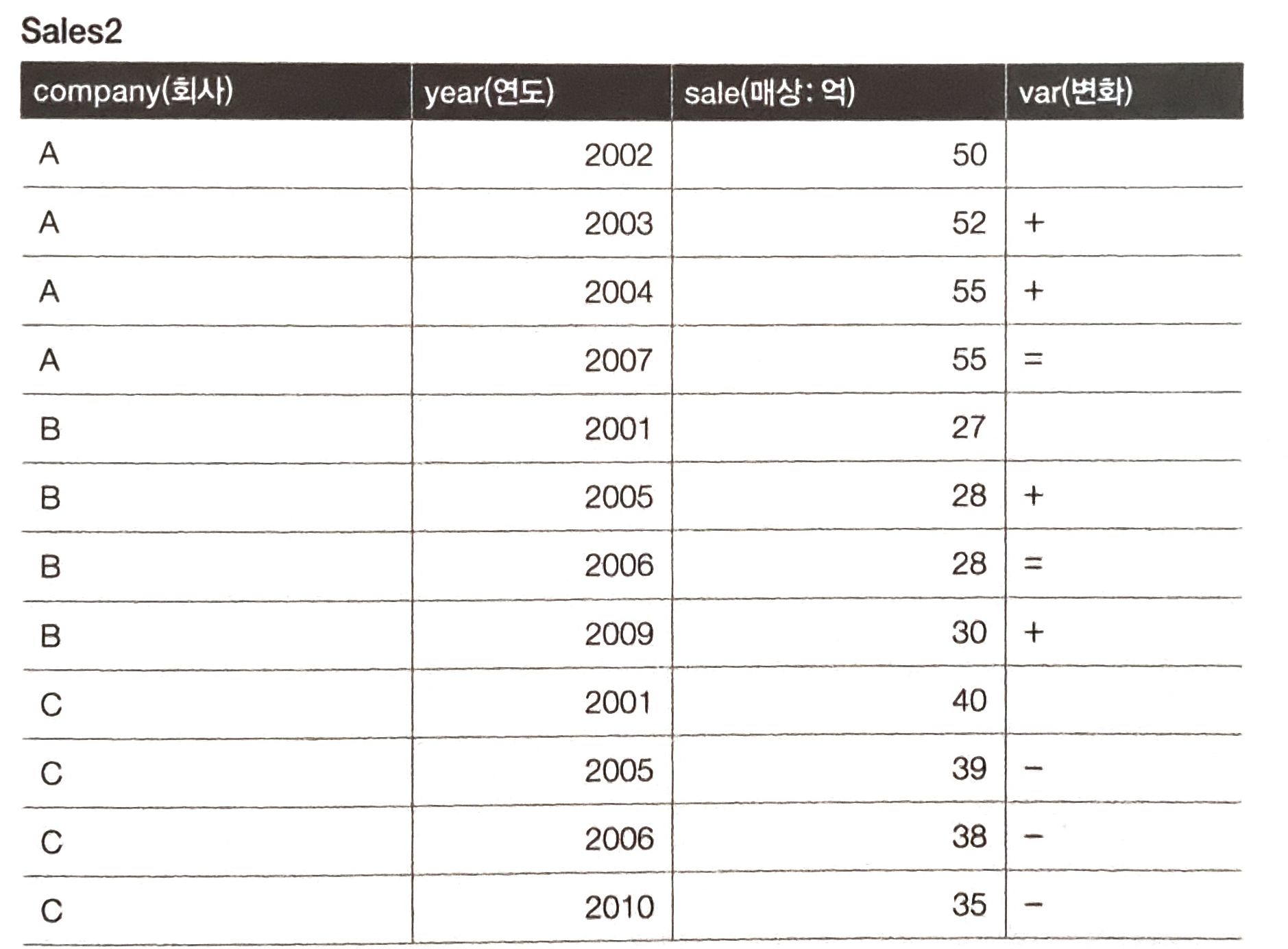
반복계 코드


반복계의 단점
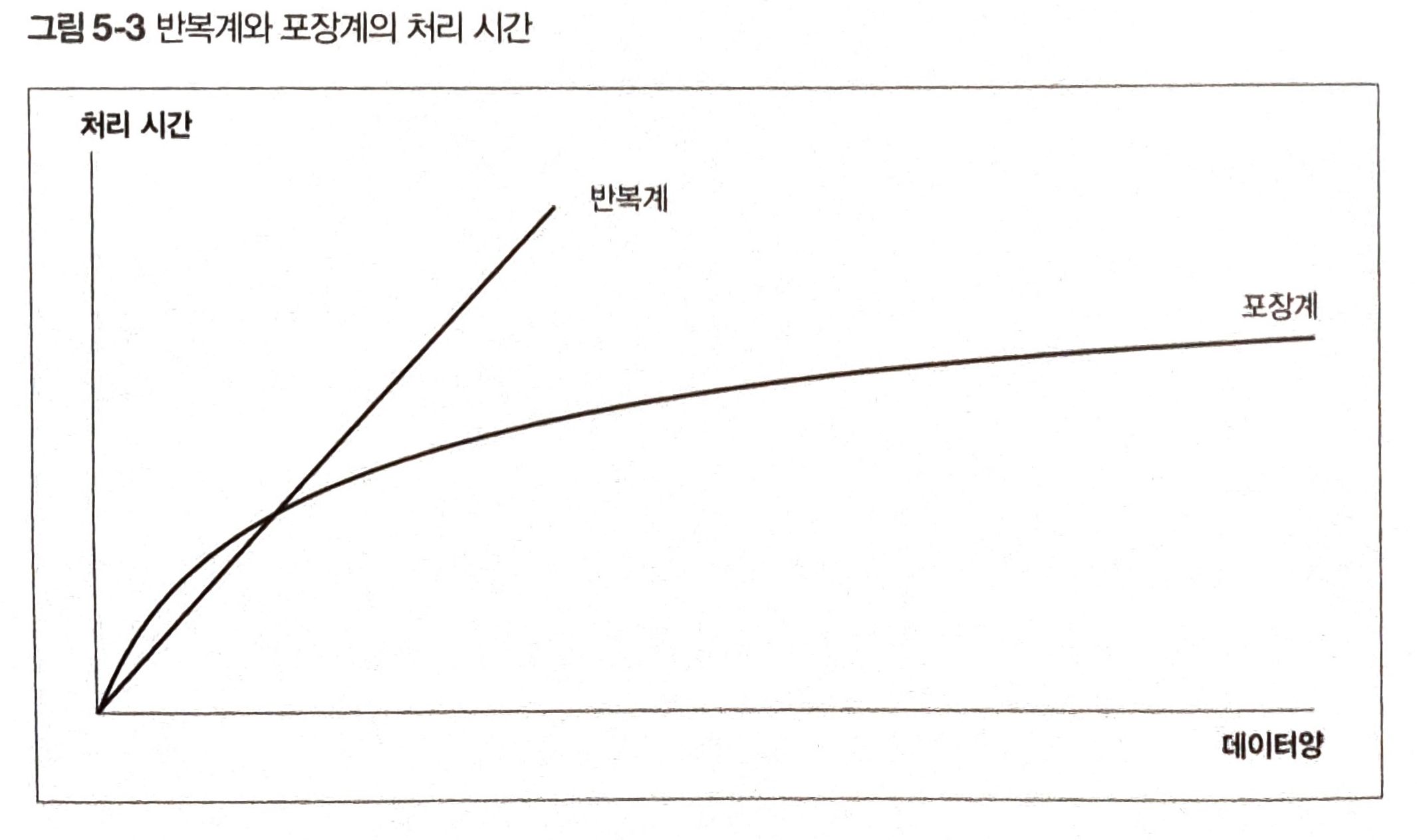
반복계의 가장 큰 문제는 성능이다. 처리량이 적은 경우 반복계가 더 빠를 수 있지만 처리량이 많아질수록 포장계와 차이는 벌어진다.
처리시간 차이
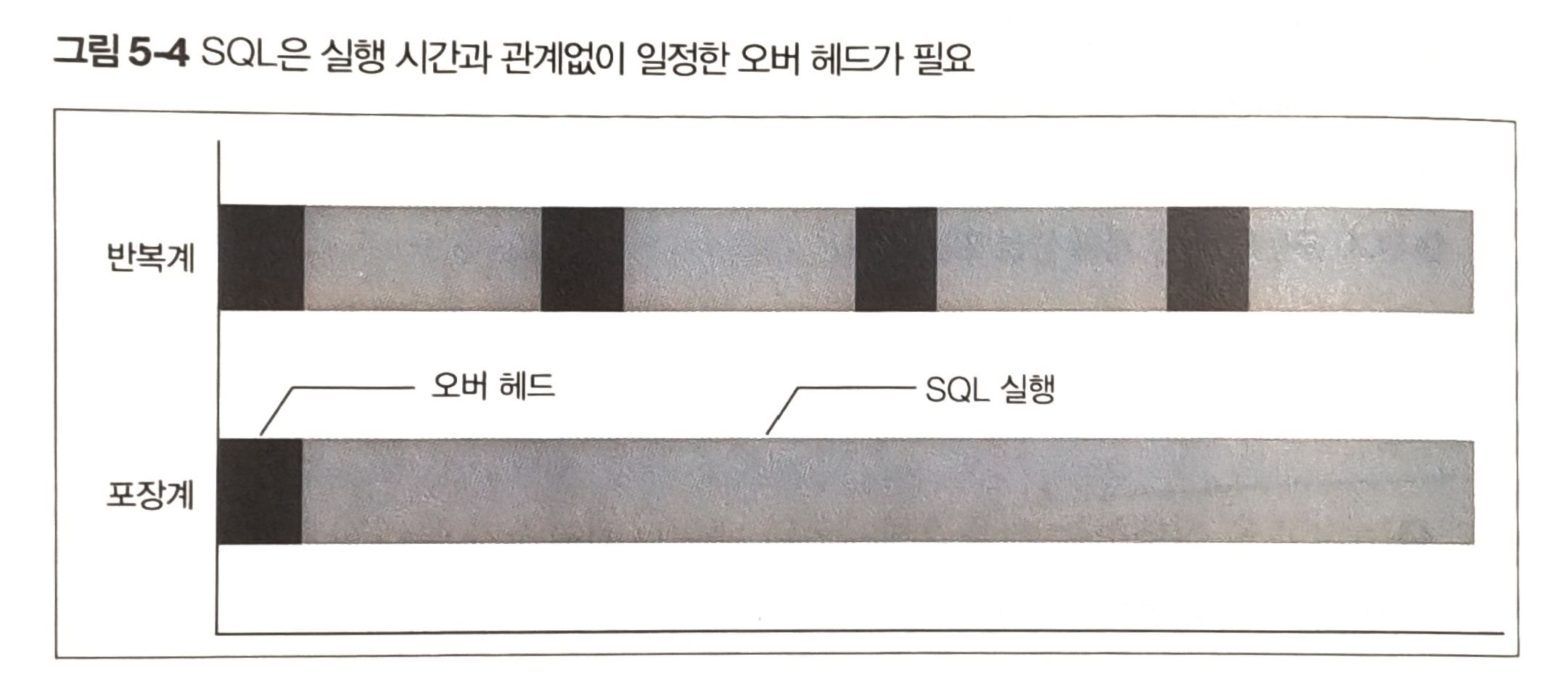
SQL 실행의 오버헤드
SQL을 실행할때는 검색,연산하는 실제의 SQL처리 말고도 다양한 처리가 일어난다.
전처리
- SQL구문을 네트워크로 전송
- 데이터베이스 연결
- SQL 구문 파스
- SQL 구문의 실행 계획 생성 또는 평가
후처리
- 결과 집합을 네트워크로 전송
1과 5는 SQL을 실행하는 애플리케이션과 데이터베이스가 동일한 서버에 있다면 발생하지 않는다.
2는 데이터베이스에 SQL 구문을 실행하기 위한 작업이다.
오버헤드 중 가장 영향이 큰 것은 3과 4이다. 특히 파스(구문 분석) 부분인데 파스는 DBMS마다 방식도 다르고 종류도 다양하다. 특히 느린 부분은 0.1~1초 정도 걸린다. 이는 다른 오버헤드가 밀리세컨드 단위로 처리되는 것에 비하면 굉장히 크다.
파스는 SQL을 받을 때마다 수행되므로 작은 SQL을 반복하는 반복계에서는 오버헤드 소모가 크다.
병렬 분산이 힘들다.
반복계는 반복 1회마다 처리가 단순하기 때문에 리소스를 분산해 I/O를 부하를 분산하는 병렬 처리하는 최적화가 불가능하다.
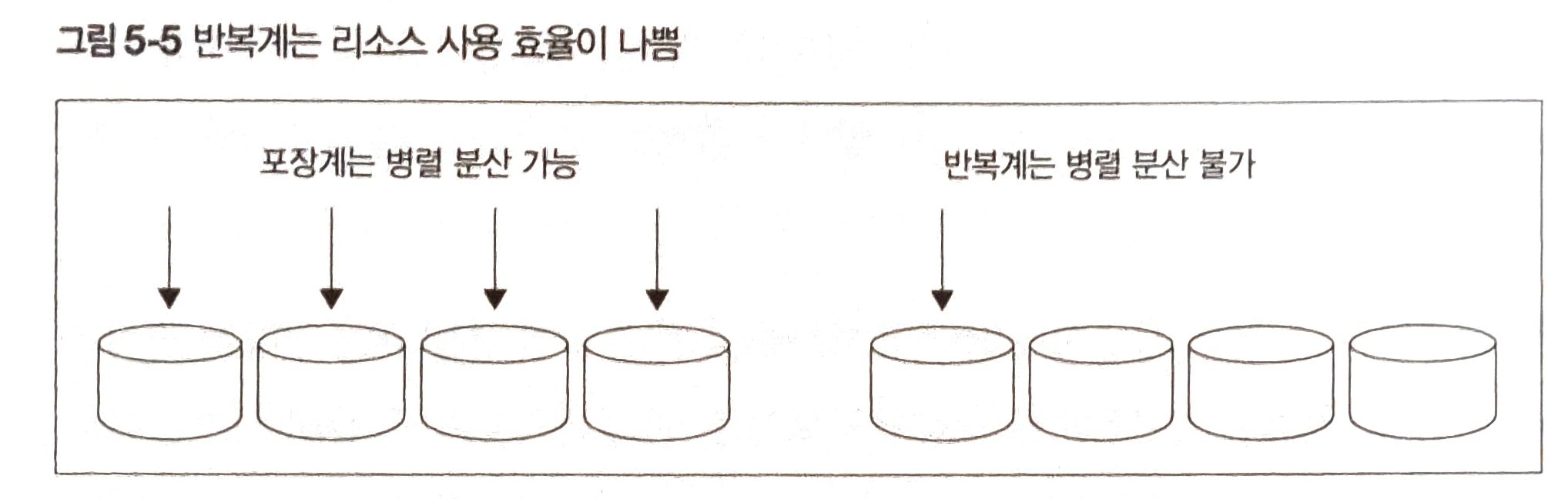
데이터베이스의 진화로 인한 혜택을 받을 수 없다
DBMS는 SQL을 어떻게 하면 빠르게 할 수 있을지 계속 연구하고 있다. 하지만 이러한 노력은 '대규모 데이터를 다루는 복잡한 SQL 구문'을 대상으로 한다. 반복계에 사용되는 '간단한 SQL 구문'을 빠르게 하는 것은 고려하고 있지 않다.
따라서 반복계를 사용하면 미들웨어나 하드웨어의 진화에 따른 혜택을 받을 수 없다.
튜닝이 불가능 하다
반복계는 단순한 SQL 구문을 여러 번 실행하는 방식이기에 튜닝할 부분이 없다.
반복계를 빠르게 만드는 방법
반복계는 튜닝의 선택지가 한정적이다.
수백 개 정도의 요청정도는 성능이 괜찮게 나온다. 하지만 수백, 수천 개의 처리가 기본인 일괄 처리(batch)같은 경우는 절대로 사용하면 안된다. 따라서 무조건 반복계를 적대시하기보단 상황에 따라서 사용해야 한다.
반복계를 포장계로 수정
이는 애플리케이션 수정을 의미한다. 하지만 실제 상황에서는 여러 이유로 불가능한 경우가 많다.
각각의 SQL을 수정
반복계에서 사용하는 SQL 구문을 수정하는 것인데, SQL 구문이 단순한 편이라 튜닝의 효과를 받기 어렵다.
다중화 처리
CPU 또는 디스크와 같은 리소스에 여유가 있고 처리를 나눌 키가 명확하다면, 성능을 선형에 가깝게 스케일할 수 있다.
반복계의 장점
반복계도 다양한 장점이 있다. 따라서 처리 방식을 선택할 때는 장점과 단점의 트레이드오프에 대한 신중한 고려가 필요하다.
실행 계획의 안정성
실행 계획이 단순하기 떄문에 실행 계획의 변동의 위험이 거의 없다.
예상 처리 시간의 정밀로
실행 계획이 단순하고 성능이 안정적인 반복계는 예상 처리 시간의 정밀도가 높다.
<처리 시간> = <한 번의 실행 시간> x <실행 횟수>
포장계는 실행 계획에 따라 성능이 전혀 달라지므로 사전에 예상하기 힘들다.
트랜잭션 제어의 편리성
트랜잭션의 정밀도를 미세하게 제어할 수 있다.
만약 중간에 오류가 발생한다면 중간에 커밋을 했으므로 이어서 진행하면 된다. 하지만 포장계는 오류가 발생하면 처음부터 다시해야 한다.
SQL에서는 반복을 어떻게 표현할까? - 반복계 코드
포인트는 CASE 식과 윈도우 함수
SQL에서 반복을 대신하는 수단은 CASE 식과 윈도우 함수다. CASE 식은 IF-THEN-ELSE에 대응한다.
위의 반복계 코드를 포장계로 작성하면 아래와 같다.

SQL에는 변수가 없으므로 SIGN 함수를 이용해 보완한다.
상관 서브쿼리
윈도우 함수가 나오기 전 사용하던 방식으로 성능계획이 복잡해 성능적인 리스크가 발생하므로 사용을 추천하지 않는다.

반복 횟수가 정해진 경우
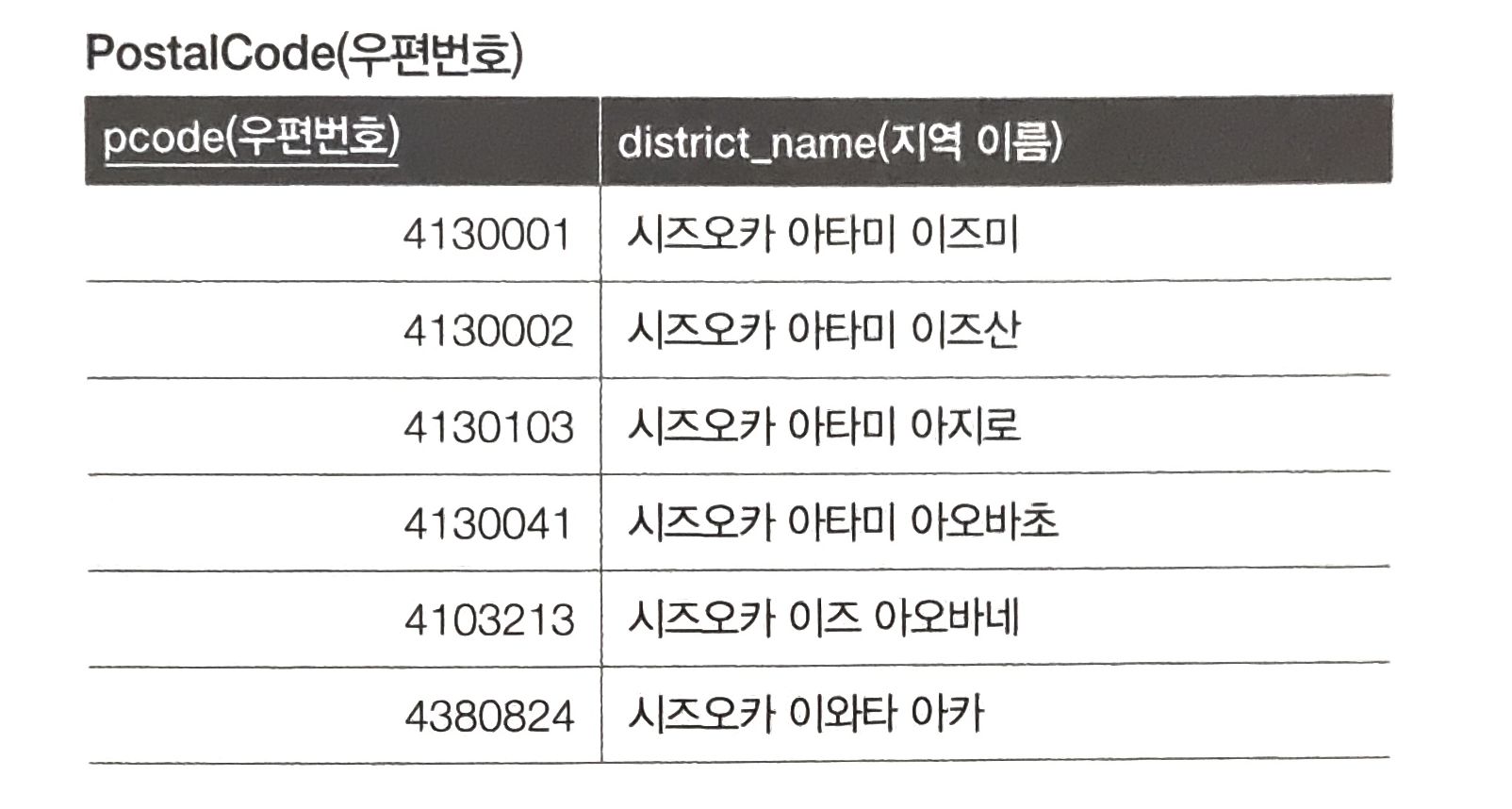
우편번호 테이블이 있고 입력받은 우편번호와 가장 가까운 지역의 우편번호를 찾아보자.

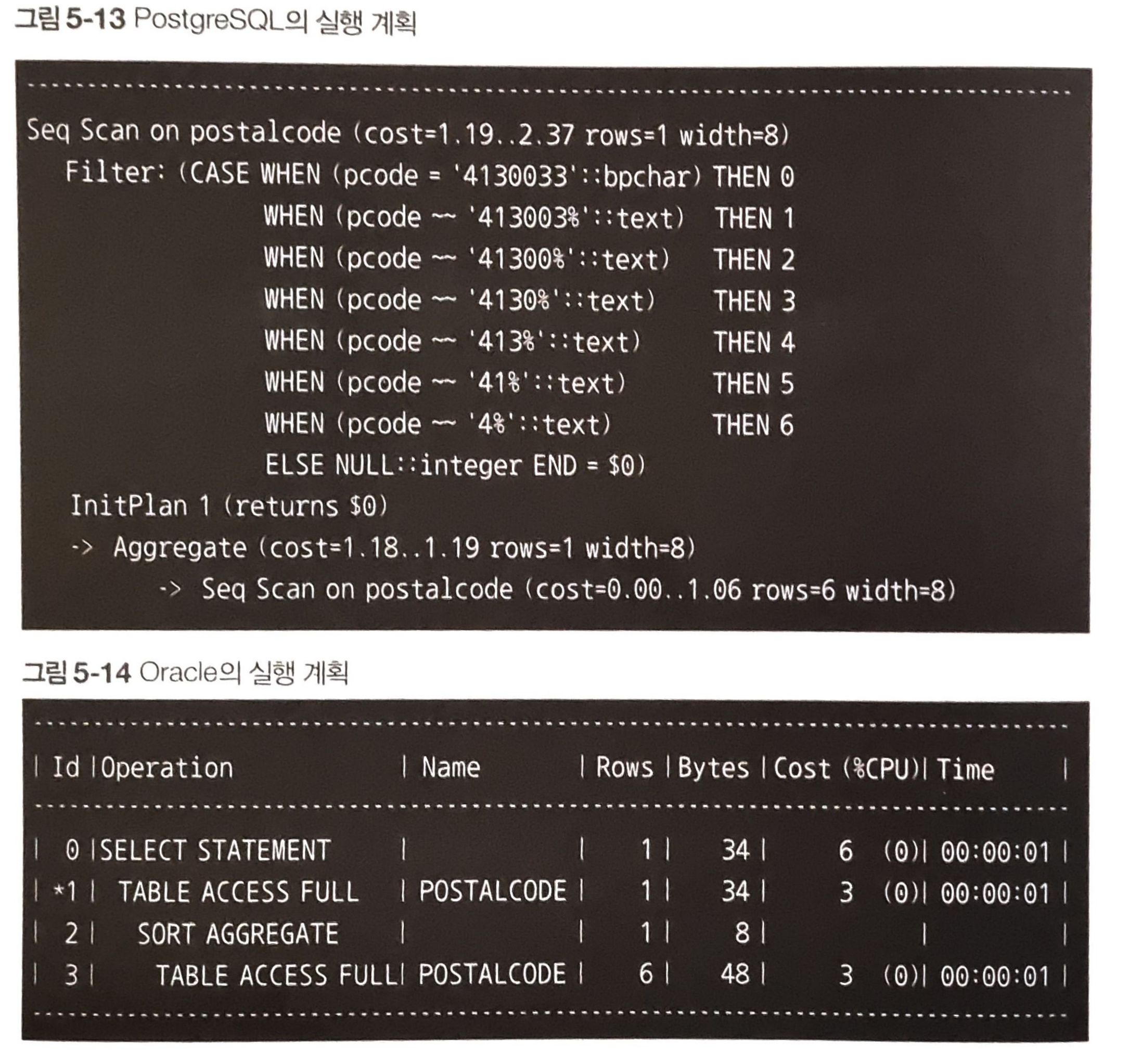
하지만 서브쿼리를 사용하기 때문에 테이블 스캔이 2번 발생한다.
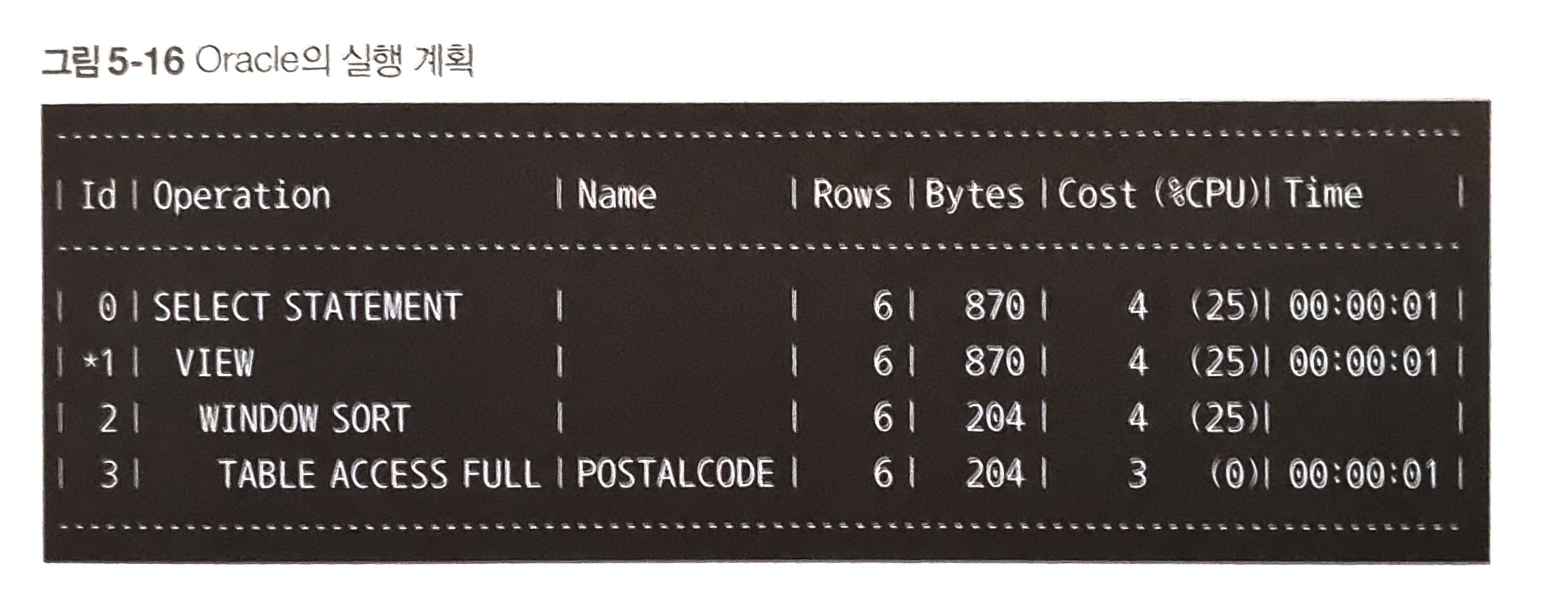
윈도우 함수 사용

반복 횟수가 정해지지 않은 경우
SQL에서 계층 구조를 나타내는 방법은 크게 3가지가 있다.
- 인접 리스트 모델
- RDB 탄생 전에도 쓰였던 고전적인 방식
- 중첩 집합 모델
- 각 레코드의 데이터를 원(집합)으로 봄
- 계층 구조를 집합의 중첩 관계로 나타냄
- 경로 열거 모델 (이 책에서는 생략 됨)
- 갱신이 거의 발생하지 않은 테이블에서 사용함
인접 리스트 모델과 재귀 쿼리
현재 주소뿐만 아니라 과거의 주소까지 관리하는 테이블이 있다.
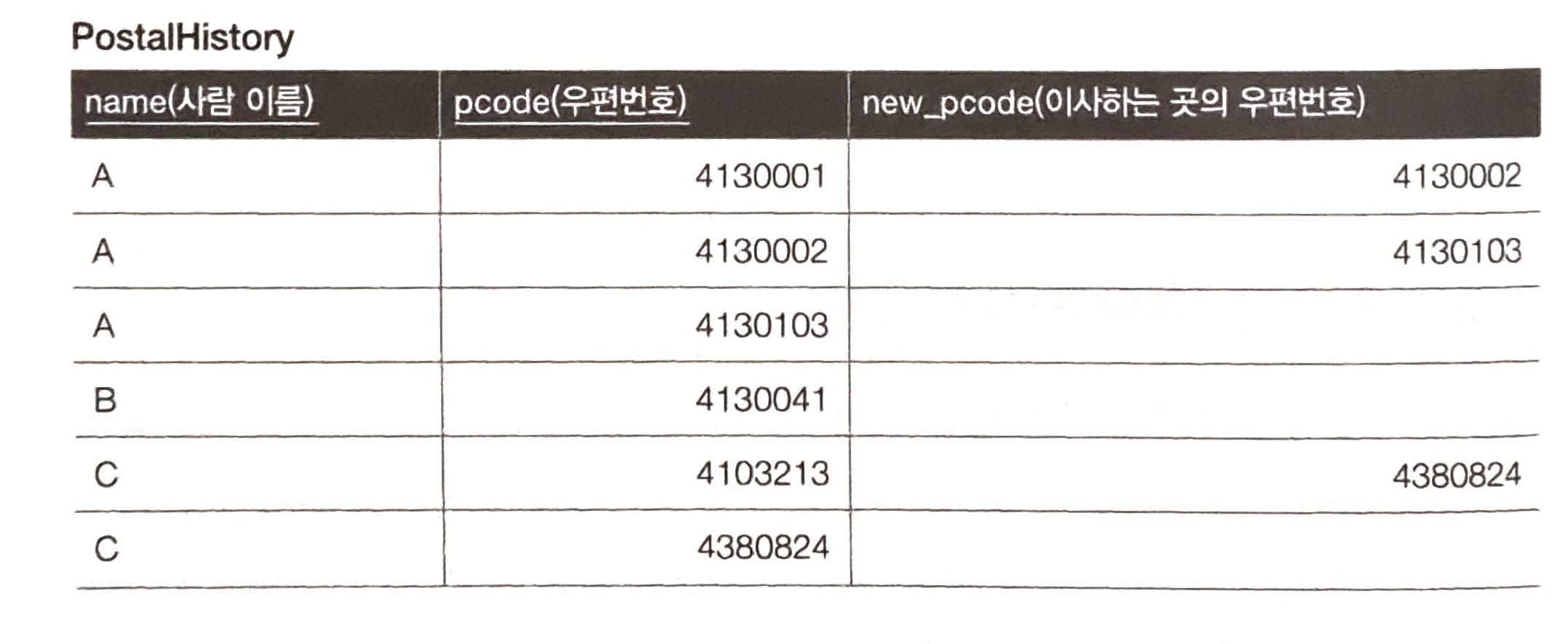
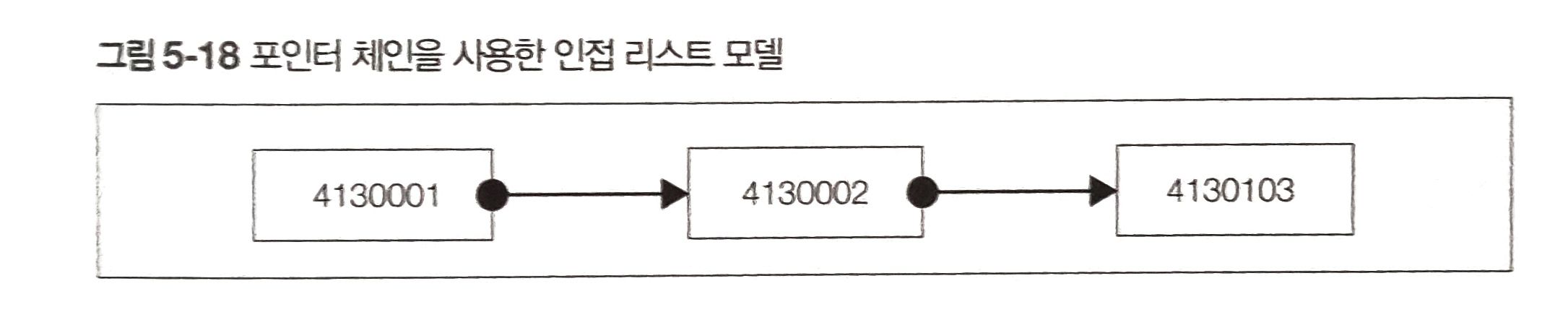
이처럼 우편번호를 키로 삼아 데이터를 연결한 것을 포인터 체인이라고 합니다. 그리고 포인터 체인을 사용하는 테이블을 인접 리스트 모델이라고 한다.
SQL에서 계층 구조를 찾는 방법 중 하나는 재귀 공통 테이블 식(recursion common table expression)을 사용하는 것이다. (2014년 기준 Oracle, MySQL, SQL Server, DB2, PostgreSQL에서 지원)

중첩 집합 모델
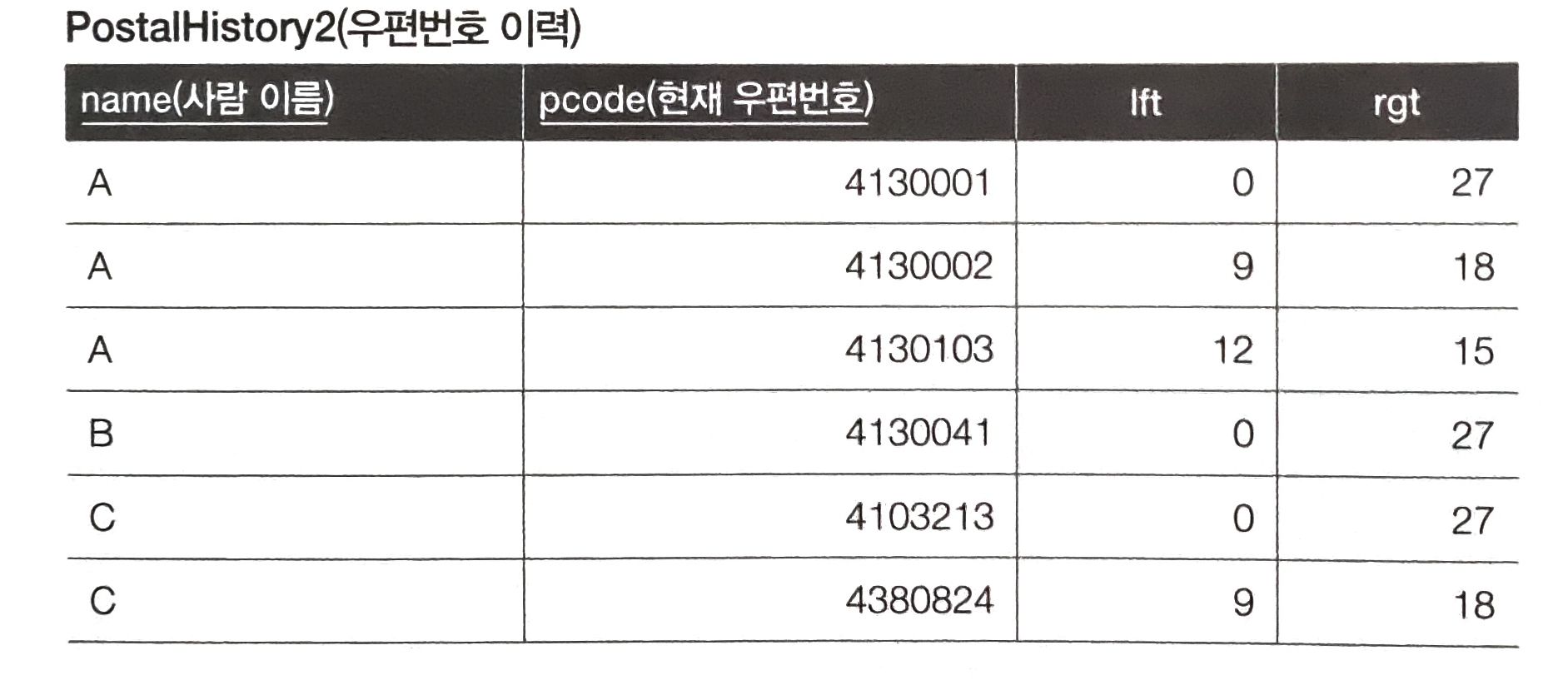
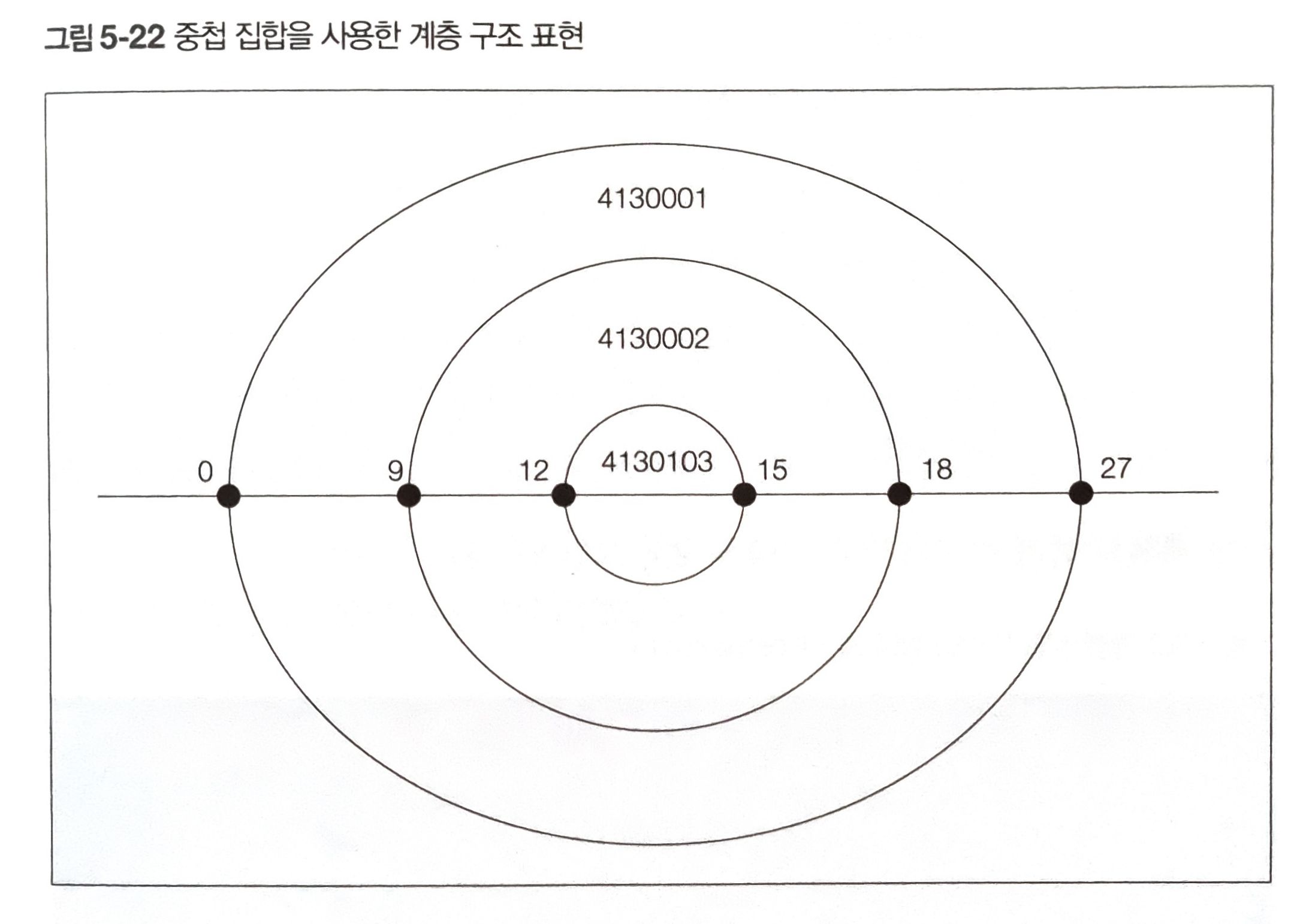
- 추가되는 노드의 왼쪽 끝 좌표 = ( plft * 2 + prgt ) / 3
- 추가되는 노드의 오른쪽 끝 좌표 = ( plft + prgt * 2 ) / 3
- plft : 현재 노드의 왼쪽, prgt : 현재 노드의 오른쪽


