4장 집약과 자르기
SQL 레벨업이라는 도서를 정리한 내용입니다.
4장은 이론적인 내용보다 예제 위주의 내용이기 때문에 예제를 간략하게 정리했습니다.
SQL의 특징적인 사고방식 중 하나인 집합 지향(set-oriented, 레코드 의 '집합'단위로 처리),
집합 지향의 특징이 가장 잘 드러나는 상황은 GROUP BY 구, HAVING 구와 SUM, COUNT와 같은 집약 함수를 사용할 때다. 이를 예제를 통해 알아보자.
집약
SQL에는 집약 합수(aggregate function) 라는 함수가 있다.
- COUNT
- SUM
- AVG
- MAX
- MIN
이 함수들의 이름이 '집약' 함수인 이유는 문자 그대로 여러개의 레코드를 하나의 레코드로 집약하는 기능을 가졌기 때문이다.
절차 지향적인 방법
아래의 테이블에서 한 사람마다 색이 칠해진 부분만 모아서 한 레코드를 얻고 싶다면 어떻게 해야할까?
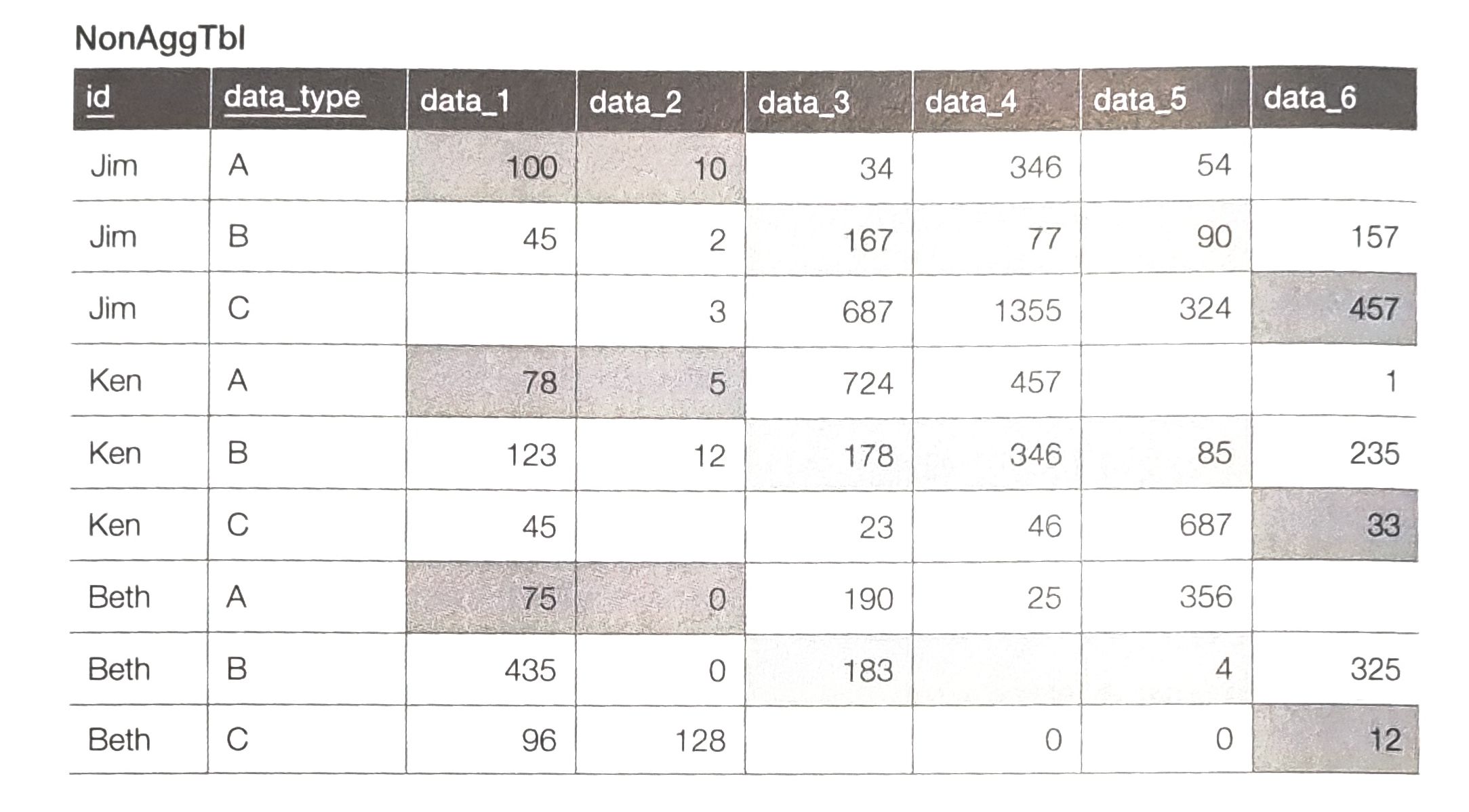
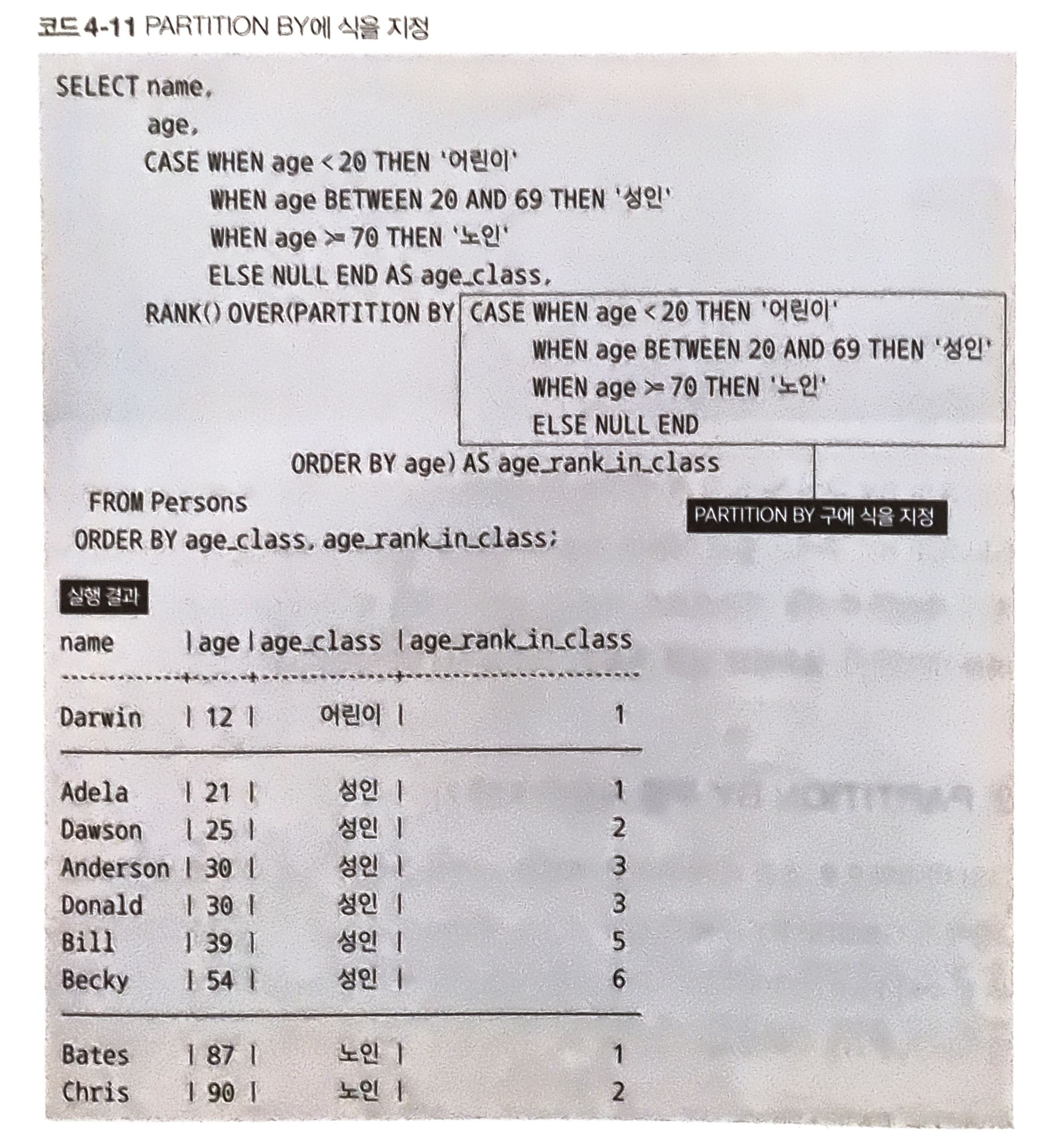
테이블을 보면 data_type이 1~2면 A, 3~5면 B, 6이면 C를 사용한다.
집약함수를 사용하지 않는다면 아래처럼 구할 수 있을 것이다.


이러한 쿼리 결과는 개수가 달라서 UNION을 사용할 수 없고, UNION을 사용하면 성능이 떨어진다는 것도 3장에서 설명했다.
따라서 이런 데이터는 아래처럼 만드는 것이 바람직하다.
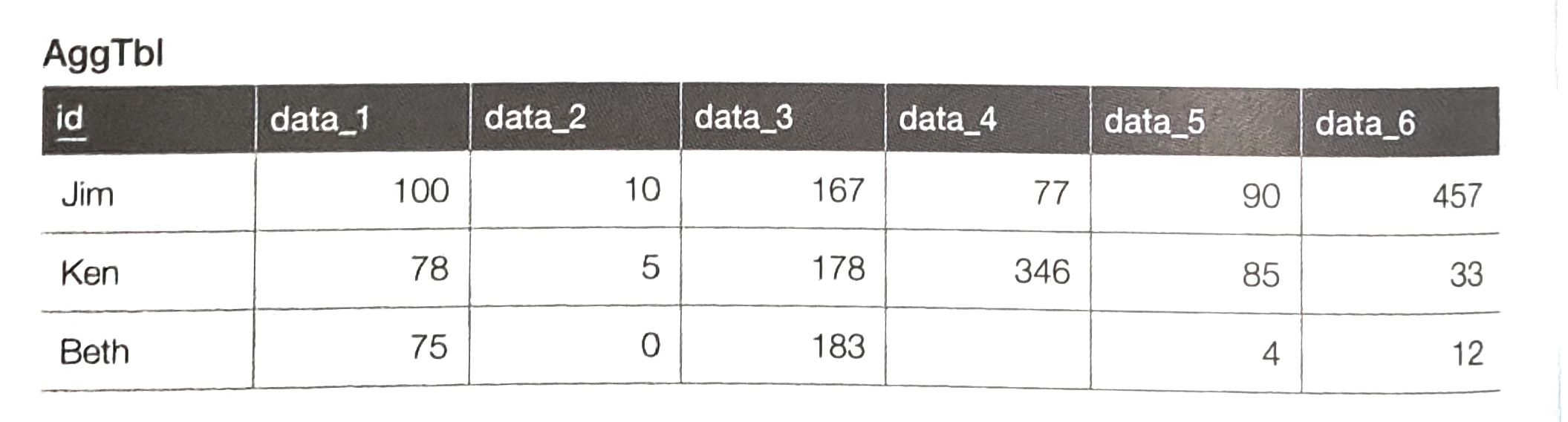
CASE 식과 GROUP BY 구의 응용
CASE 식과 GROUP BY 식을 사용해 위의 문제를 해결하려면 아래처럼 작성하면 된다.
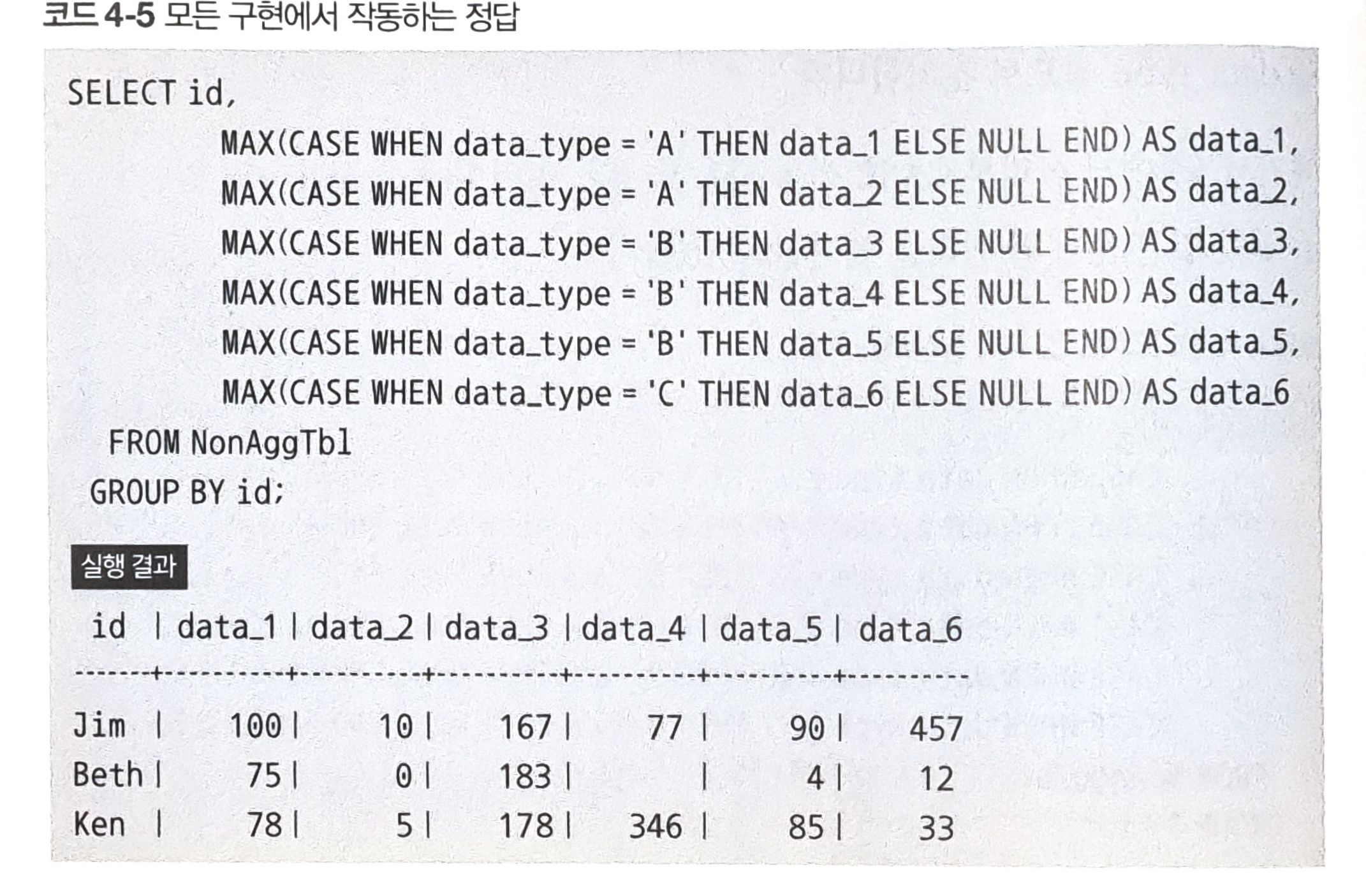
MAX를 사용하는 이유
GROUP BY 구를 사용했을때 SELECT에 입력할 수 있는 것은 3가지다.
- 상수
- GROUP BY 구에서 사용한 집약 키
- 집약 함수
하지만 위 3개에 CASE 식은 포함되지 않는다.
따라서 아래의 식은 정상적으로 작동되지 않는다.

집약, 해시, 정렬
위 코드의 실행 결과
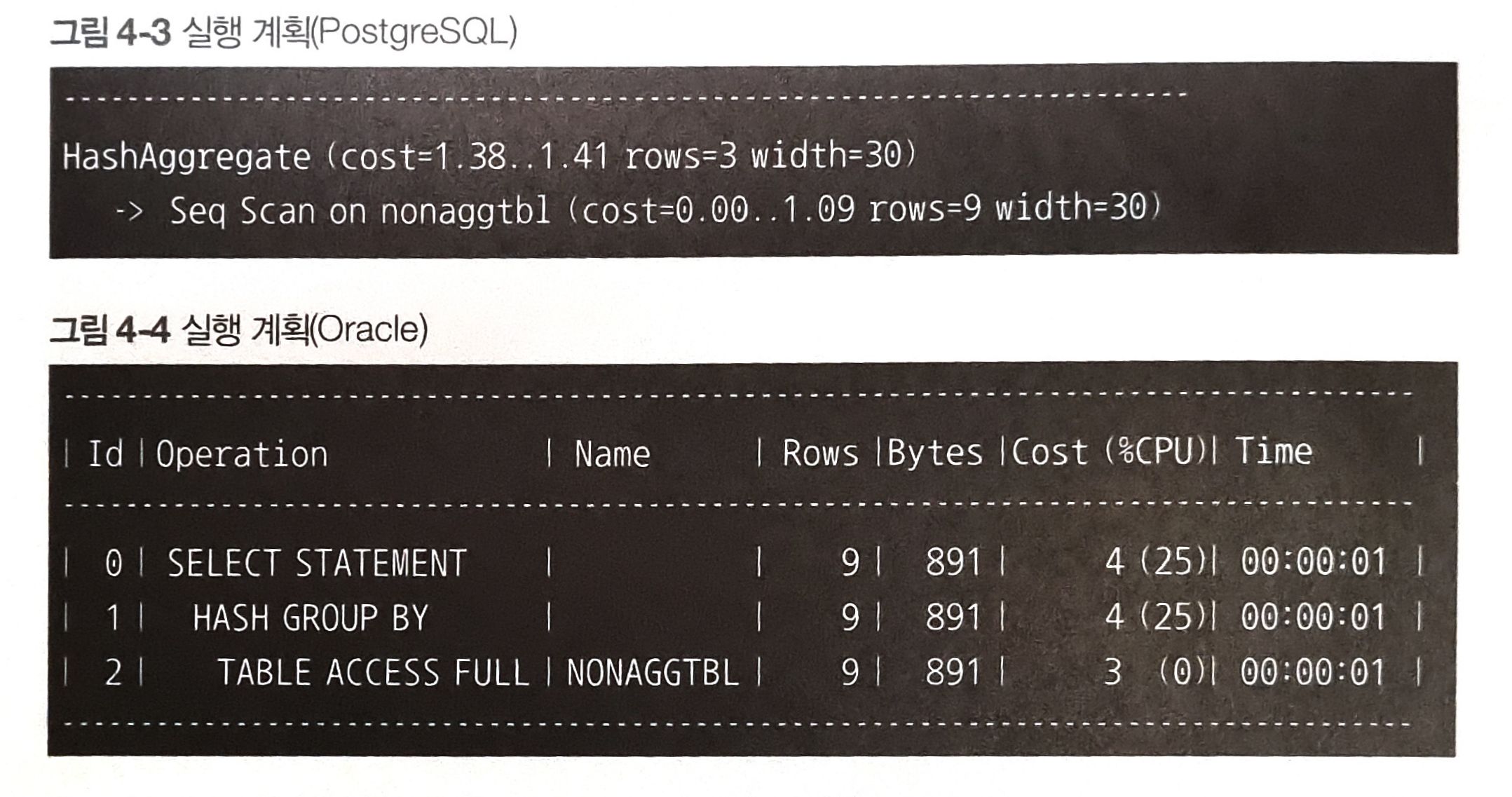
주목해야 할 부분은 '해시'알고리즘을 사용하고 있다는 것이다.
최근에는 GROUP BY를 사용하는 집약에서 정렬보다 해시를 사용하는 경우가 많다.
해시 키를 사용하면 GROUP BY에 지정된 필드를 해시 함수를 이용해 해시 키로 변환하고, 같은 키를 가진 그룹을 모아 집약한다.
정렬을 사용한 것보다 빠르기에 많이 사용되고 있다. 특히 해시의 성질 상 GROUP BY의 유일성이 높을수록 효율적이다.
GROUP BY의 주의점
정렬과 해시 둘다 메모리를 많이 소모하므로, 충분한 워킹메모리가 확보되지 않으면 스왑이 발생한다.
오라클로 예시를 들면 오라클은 정렬(또는 해시)를 위한 PGA라는 메모리 영역을 사용한다. PGA의 크기가 부족해지면 스왑이 일어나는데 이때 극단적으로 성능이 감소한다. 스왑이 일어나면 저장소에 TEMP(임시 영역)을 사용하는데 TEMP까지 부족해지면 SQL 구문이 비정상적으로 종료된다.
따라서 충분한 성능 검증을 통해 스왑이 발생하지 않도록 해야한다.
CASE 식을 사용하기 위해 MAX 혹은 MIN을 사용한다.
간단한 예제
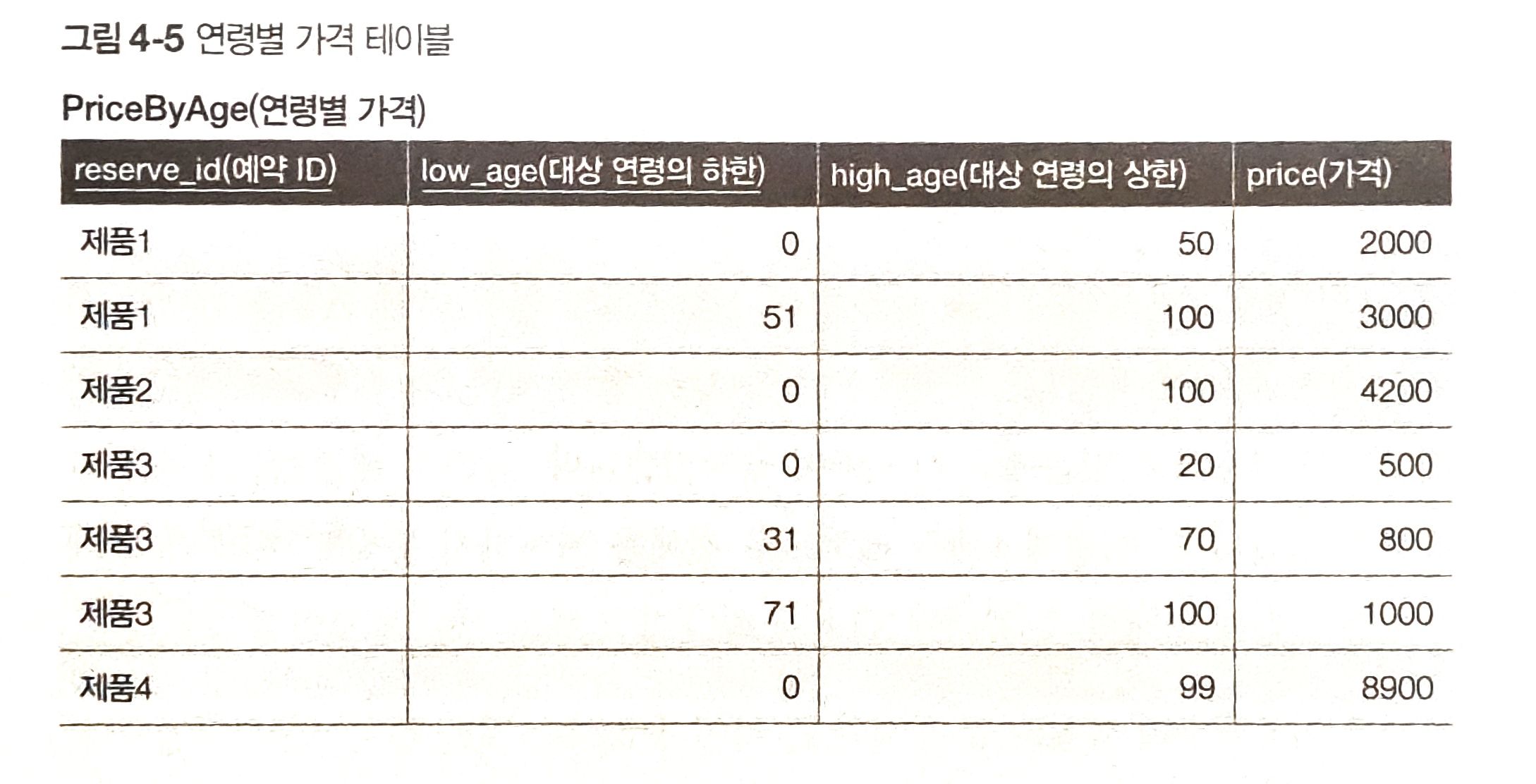
제품의 대상 연령별 가격을 관리하는 테이블이 있고 0~100세까지 이용할 수 있는 제품을 구해보자.

호텔 방마다 도착일과 출발일을 기록하는 테이블이 있고 숙박한 날이 10일 이상인 호실을 구해보자.


자르기
이 부분에서는 집약 보다는 자르기에 집중한다.
자르기와 파티션
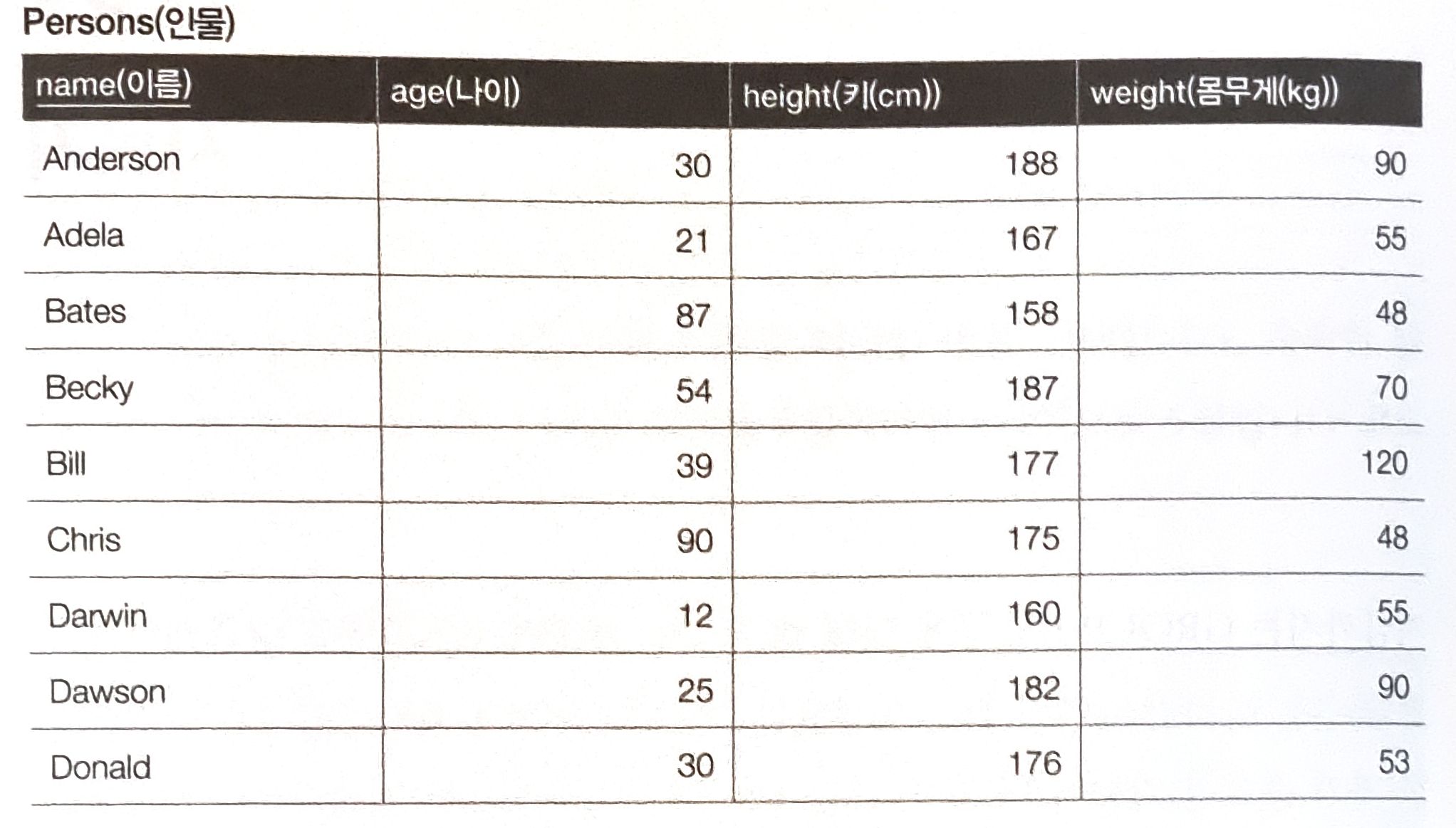
회사 직원들의 정보를 저장한 테이블이 있고 이름별로 몇명의 직원이 있는지 구한다고 해보자.
내부적으로 진행되는 처리를 예상해 보면 위와 같이 나누어지고 각 그룹의 합을 구할 것이다.
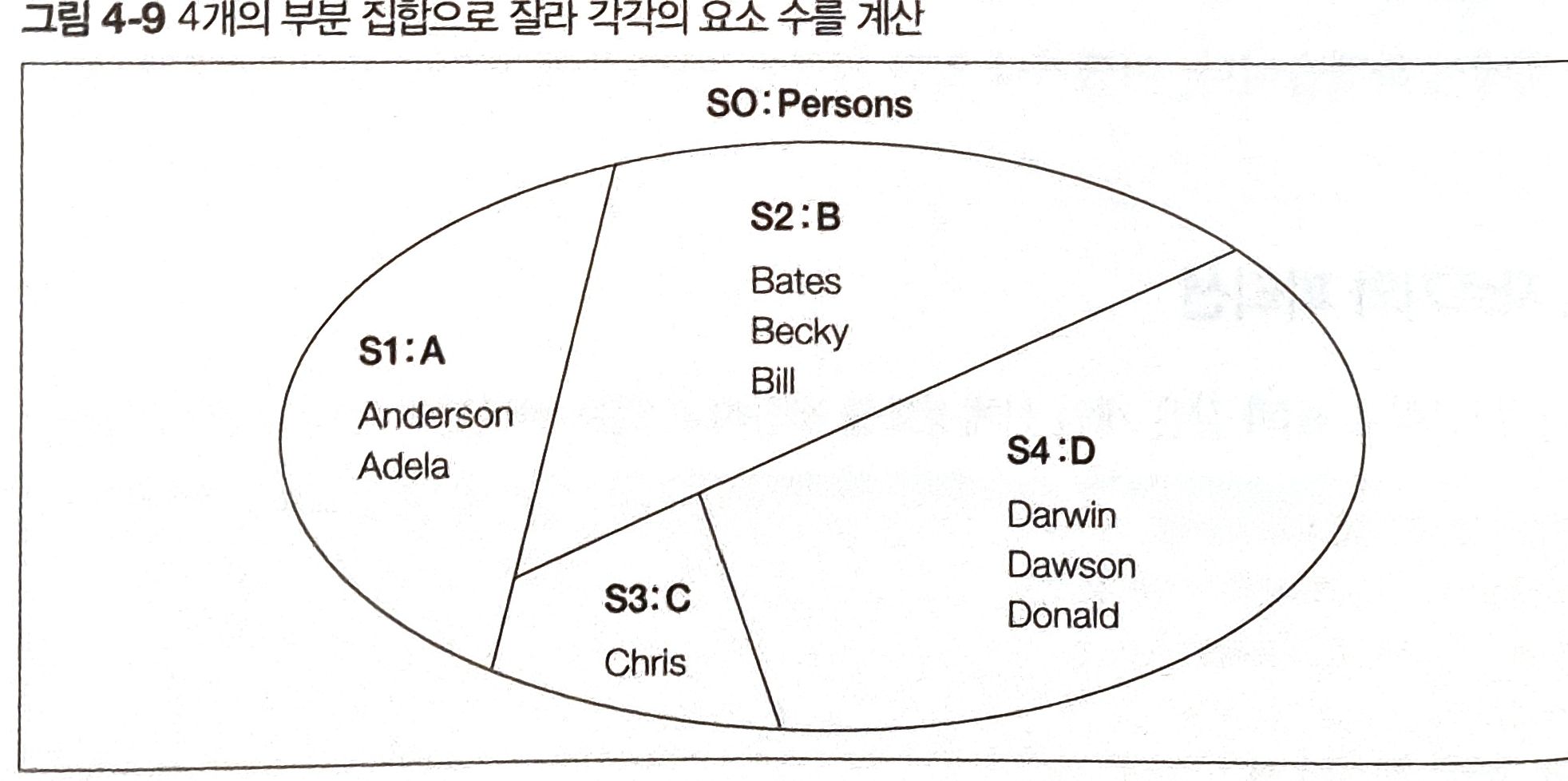
위의 이미지처럼 GROUP BY로 자른 하나하나의 부분 집합을 파티션(partiton) 이라고 부른다.
같은 모집합이라도 여러개의 파티션을 구할 수 있다. (위 테이블에서도 키가 170~180인 사람의 수, 이름의 길이 등으로 여러 파티션을 만들 수 있다.)
PATITION BY 구를 사용한 자르기
PATITION BY 구는 자르기 부분에서는 GROUP BY와 별다른 부분 없이 동작한다.