
발생한 상황
프로젝트 연관관계 매핑
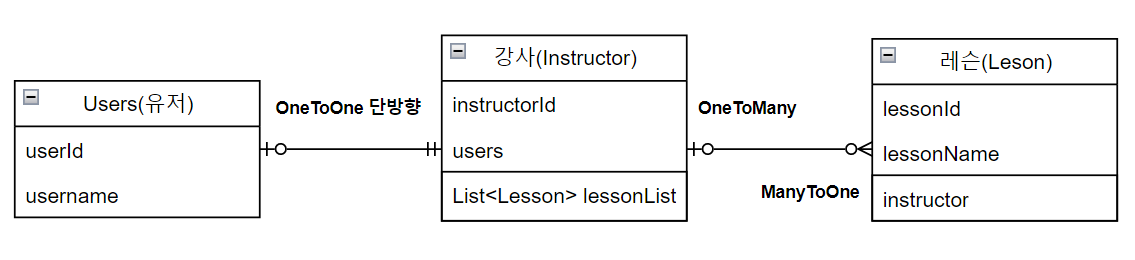
LessonService.java
public LessonInfoResponseDto lessonInfo(Long lessonId) {
Lesson lesson = findLessonByLessonId(lessonId);
Instructor instructor = lesson.getInstructor();
Users users = instructor.getUsers();
return LessonInfoResponseDto.builder()
.username(users.getUsername())
.lessonName(lesson.getLessonName())
.centerAddress(lesson.getCenterAddress())
.centerName(lesson.getCenterName())
.startDateTime(lesson.getStartDateTime())
.endDateTime(lesson.getEndDateTime())
.maxEnrollment(lesson.getMaxEnrollment())
.build();
}위 코드는 단순히 레슨 정보를 조회하는 로직이다.
하지만 아래와 같은 에러가 발생을 했다.
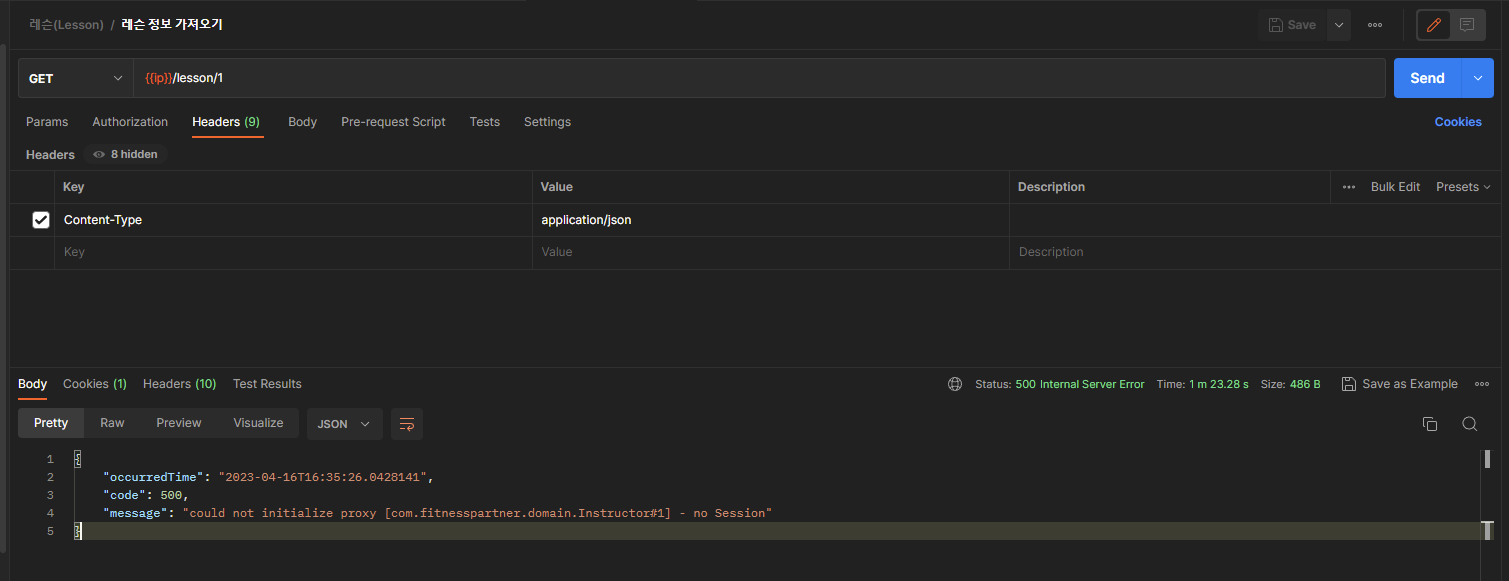
{
"occurredTime": "2023-04-16T16:35:26.0428141",
"code": 500,
"message": "could not initialize proxy [com.fitnesspartner.domain.Instructor#1] - no Session"
}에러를 자세히보면 Instructor 프록시 객체를 initialize 할 수 없는 걸로 보인다.
문제에 대해서 고민 해보기 전에 우선 해결할 방법을 구글에 검색해서 해결했다.
해결한 방법
@Transactional
public LessonInfoResponseDto lessonInfo(Long lessonId) {
Lesson lesson = findLessonByLessonId(lessonId);
Instructor instructor = lesson.getInstructor();
Users users = instructor.getUsers();
return LessonInfoResponseDto.builder()
.username(users.getUsername())
.lessonName(lesson.getLessonName())
.centerAddress(lesson.getCenterAddress())
.centerName(lesson.getCenterName())
.startDateTime(lesson.getStartDateTime())
.endDateTime(lesson.getEndDateTime())
.maxEnrollment(lesson.getMaxEnrollment())
.build();
}@Transactional 처리하니까 간단하게 해결되었다.
구글링 해보니까 대부분 @Transactional로 해결 했다고 한다.
❓왜 해결된 걸까?
그냥 적용 후 해결되었다고 끝내지 말고 조금 더 살펴보자.
우선 트랜잭션 처리로 인해서 해결된 쿼리를 직접 확인해보기로 했다.
Hibernate:
select
lesson0_.lesson_id as lesson_i1_1_0_,
....
from
lesson lesson0_
where
lesson0_.lesson_id=?
Hibernate:
select
instructor0_.instructor_id as instruct1_0_0_,
....
from
instructor instructor0_
where
instructor0_.instructor_id=?
Hibernate:
select
users0_.users_id as users_id1_3_0_,
....
from
users users0_
where
users0_.users_id=?해결은 되었지만 위와 같이 select 쿼리만 3 개가 날라간다.
select 쿼리가 3개 날라가는 문제와 해결된 이유를 모르는 것을 보고 아래와 같은 생각을 했다.
- 단순히 조회하는 쿼리에 select 쿼리가 3 개가 날라가는 것은 성능에 좋지 않다고 생각했다.
- ‘해당 로직에 트랜잭션이 필요할까?’ 라는 생각도 했다.
- 연관관계 매핑과 영속성 컨텍스트에 대한 이해도가 아직 부족하다고 생각했다.
차근차근 찾아보고 공부해보자.
🧐오류 메시지를 다시 읽어봤다
could not initialize proxy - no SessionJPA에서 Session은 영속성 컨텍스트를 의미한다.
영속성 컨텍스트는 엔티티 객체들을 관리하고 데이터베이스와의 상호작용을 담당하는 일종의 캐시이다.
- JPA에서 엔티티 객체는 일반적으로 데이터베이스와 연결된 세션(Session) 내에서 관리된다.
- 위 오류는 영속성 컨텍스트가 초기화되지 않아서 발생할 수 있다.
- 엔티티 객체를 로드하려고 할 때 영속성 컨텍스트가 없기 때문에 발생하는 오류이다.
🤔해결된 이유는 뭘까?
JPA가 스프링 컨테이너가 제공하는 전략을 따르고 있는데,
기본 전략으로 트랜잭션 범위의 영속성 컨텍스트 전략을 사용하기 때문이다.
- 트랜잭션이 시작하는 순간 영속성 컨텍스트 생성
- 트랜잭션이 끝나는 순간 영속성 컨텍스트가 종료
위 내용과 오류에 대한 내용으로 추론해보면,
@Transactional 어노테이션을 사용하여 해당 로직을 묶었기 때문에 영속성 컨텍스트가 없는 문제가 해결된 것이다.
- @Transactional 어노테이션이 붙은 메소드 내에서는 EntityManager를 사용하여 엔티티를 조작하는 작업들이 수행되면, 영속성 컨텍스트가 자동으로 열리고, 트랜잭션의 끝까지 유지된다.
- 이를 통해 DB에 대한 일관성을 유지하고, 데이터 변경 시 올바른 순서와 타이밍으로 이루어지도록 보장한다.
이유는 이제 명확하게 알게 되었다.
그렇다면 @Transactional을 사용해서 생기는 문제와 다른 해결 방법을 찾아보자.
😮@Transactional으로 해결하면 안된다?
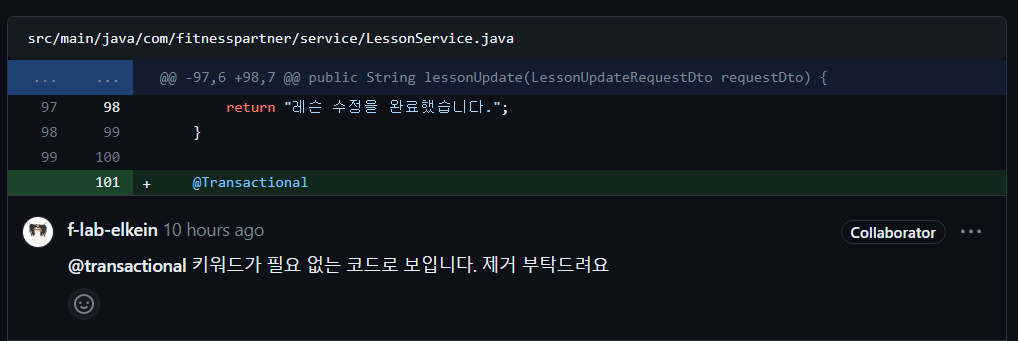
멘토링 시간에 코드 리뷰와 함께 위와 같은 의견을 주셨다.
생각해보니까 레슨 정보를 조회하는데 트랜잭션이 필요가 없었다.
그 이유를 트랜잭션의 특징과 연결 지어서 생각해봤다.
- 원자성(Atomicity) : 해당 로직은 단순히 레슨 정보를 가져오는 로직이다 DB에 모두 반영되거나 반영되지 않게 처리할 게 하나도 없다.
- 일관성(Consistency) : 트랜잭션의 실행이 성공적으로 완료하면 언제나 일관성 있는 DB 상태로 변환한다는 내용은 현재 로직과 전혀 연관성이 없는 내용이다.
- 독립성(Isolation) : 수행중인 트랜잭션이 완전히 완료될 때까지 다른 트랜잭션에서 수행 결과를 참조할 수 없게 독립 시킨다는데, 자주 일어날 수 있는 조회 로직에 트랜잭션을 걸면 오히려 병목 현상이 발생하지 않을까 생각했다.
- 지속성(Durability) : 성공적으로 완료된 트랜잭션의 결과는 시스템이 고장나더라도 영구적으로 반영되거나 롤백 되어야 한다고 하는데, 이 부분도 조회를 하는 중에 시스템 고장이 나면 반영이 성공 혹은 롤백을 보장할 필요가 없다.
트랜잭션의 특징 4가지를 살펴보니,
해당 로직에 @Transactional을 달아야 하지 말아야 할 이유가 더욱 명확해졌다.
그렇다면 단순히 트랜잭션을 지우고 끝나는게 아니라 조금 더 고민해보자.
🤔조회 로직에 트랜잭션을 적용해도 될까?
고민되는 부분을 chatGPT에게 한번 물어봤다.

조금만 생각해보면 당연한 것이였다.
구현을 하고, 작동 하는데만 집중 하다보니까 위와 같은 결과가 나왔다.
그러면 @Transactional이 아니라 다른 해결 방법에는 무엇이 있을까?
해결방법1 : FetchType을 Lazy ⇒ Eager
문제는 아래의 코드에 있었다.
// 변경 전(Instructor 엔티티)
@OneToOne(fetch = FetchType.Lazy)
@JoinColumn(name = "users_id", nullable = false)
private Users users;
// 변경 후(Instructor 엔티티)
@OneToOne(fetch = FetchType.Eager)
@JoinColumn(name = "users_id", nullable = false)
private Users users;
-------------------------------------------------------------------------------
// 변경 전(Lesson 엔티티)
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "instructor_id", nullable = false)
private Instructor instructor;
// 변경 후(Lesson 엔티티)
@ManyToOne(fetch = FetchType.Eager)
@JoinColumn(name = "instructor_id", nullable = false)
private Instructor instructor;Lazy에서 Eager로 번경하면, 연관 관계 설정이 되어있는 Entity까지 모두 가져온다.
(ManyToOne은 디폴트가 Eager이지만, 적어 놓는게 헷갈리지 않고 도움이 되어서 작성 중)
- Lesson 객체를 findById로 가져오면 Eager로 설정되어 있기 때문에 Lesson, Instructor, Users 까지 DB에 조회하는 방식으로 변경된다.
Eager로 변경 전 쿼리
Hibernate:
select
lesson0_.lesson_id as lesson_i1_1_0_,
....
instructor1_.users_id as users_id7_0_1_
from
lesson lesson0_
inner join
instructor instructor1_
on lesson0_.instructor_id=instructor1_.instructor_id
where
lesson0_.lesson_id=?Eager로 변경 후 쿼리
select
lesson0_.lesson_id as lesson_i1_1_0_,
....
instructor1_.instructor_id as instruct1_0_1_,
....
users2_.users_id as users_id1_3_2_,
....
from
lesson lesson0_
inner join
instructor instructor1_
on lesson0_.instructor_id=instructor1_.instructor_id
inner join
users users2_
on instructor1_.users_id=users2_.users_id
where
lesson0_.lesson_id=?Eager로 처리하지 않고 다른QueryDSL을 사용해서 Join 쿼리를 날리는 방법도 있다.
해결방법2 : QueryDSL 사용
Eager가 현재의 로직에서는 필요한 데이터를 가져오는 장점도 있다.
하지만 다른 로직에서는 불필요한 데이터를 가져오는 것으로 인해,
성능 및 로직에 혼란을 줄 수 있다고 해서 Lazy로 변경했다.
FetchType을 Lazy로 사용했기 때문에 Join을 하기 위해 QueryDSL을 아래와 같이 사용했다.
public LessonInfoResponseDto lessonInfo(Long lessonId) {
QLesson qLesson = QLesson.lesson;
QInstructor qInstructor = QInstructor.instructor;
QUsers qUsers = QUsers.users;
Lesson lesson = jpaQueryFactory.selectFrom(qLesson)
.leftJoin(qLesson.instructor, qInstructor).fetchJoin()
.leftJoin(qInstructor.users, qUsers).fetchJoin()
.where(qLesson.lessonId.eq(lessonId))
.fetchOne();
Users users = lesson.getInstructor().getUsers();
return LessonInfoResponseDto.builder()
.username(users.getUsername())
.lessonName(lesson.getLessonName())
.centerAddress(lesson.getCenterAddress())
.centerName(lesson.getCenterName())
.startDateTime(lesson.getStartDateTime())
.endDateTime(lesson.getEndDateTime())
.maxEnrollment(lesson.getMaxEnrollment())
.build();
}위 로직을 실행하면 아래와 같아 Select 쿼리가 나간다.
Hibernate:
select
lesson0_.lesson_id as lesson_i1_1_0_,
instructor1_.instructor_id as instruct1_0_1_,
users2_.users_id as users_id1_3_2_,
lesson0_.center_address as center_a2_1_0_,
....
instructor1_.address_details as address_2_0_1_,
....
users2_.created_at as created_2_3_2_,
....
from
lesson lesson0_
left outer join
instructor instructor1_
on lesson0_.instructor_id=instructor1_.instructor_id
left outer join
users users2_
on instructor1_.users_id=users2_.users_id
where
lesson0_.lesson_id=?QueryDSL로 해결은 했지만,
과연 QueryDSL을 사용하는게 최고의 선택일까?
우선 Fetch Join에 대해서 알아보자.
Fetch Join 이란?
FetchJoin은 JPA에서 제공하느 기능으로, 엔티티를 조회할 때 연관된 엔티티도 함께 조회하는 방법 중 하나이다. Fetch Join을 사용하면 즉시 로딩(Eager Loading)을 수행하며, 지연로딩(Lazy Loading)을 사용하는 경우에는 N+1 문제가 발생하지 않도록 해결 할 수 있다.
- Fetch Join은 JPQL에서 사용되며, SQL의 JOIN문과 유사하다.
- Fetch Join을 사용하기 위해서는 엔티티간 연관관계가 설정되어 있어야 한다.
- Fetch Join은 연관관계를 지정하는 기존의 조인 방식과는 달리, 연관된 엔티티도 함께 조회하기 때문에 한 번의 쿼리로 데이터를 가져올 수 있어 성능상 이점이 있다.
- 위 이점은 반대로 의도와 맞지 않으면 불필요한 데이터를 로딩하는 문제가 있다.
QueryDSL Fetch Join의 단점
- 데이터 중복 문제
- 연관된 엔티티를 함께 로드하는데, 이 때 같은 엔티티가 중복 로드 될 수 있다.
- 불필요한 데이터 로딩
- 연관된 엔티티를 함께 로드한 데이터에서 실제로 필요한 데이터가 일부일 수 있다.
- 쿼리 결과의 불확실성
- 연관된 엔티티들이 어떤 순서로 로드될 지는 보장하지 않는다.
- 불필요한 DB I/O
- 연관된 엔티티들을 모두 로드하기 위해 불필요한 DB I/O가 발생할 수 있다.
(성능 저하 및 DB 부하 증가)
- 연관된 엔티티들을 모두 로드하기 위해 불필요한 DB I/O가 발생할 수 있다.
- 메모리 부족 문제
- 로드되는 데이터가 많으면 메모리 부족 문제가 발생할 수 있다고 한다.
(위 문제는 학습 단계의 프로젝트에서는 발생하기 힘들 것 같다.)
- 로드되는 데이터가 많으면 메모리 부족 문제가 발생할 수 있다고 한다.
느낀 점
- 어떤 문제에 대해서 정답은 없다는 것을 알게 되었다.
- 차선책은 있지만, 이것이 정답이라는 생각 버려야 한다고 생각했다.
- 지금 도입한 기술의 문제점은 무엇인지 파악하고 해당 문제에 대해 고민해보기
- 도입한 방법이 지금의 문제를 해결했다고 해서 그냥 끝내지 말자.
- 나중에 그 방법으로 인해 발생하는 문제에 대해서 대비하기 힘들다.
- 문제가 발생한 시점에서 공부하면 이미 다른 문제가 꼬여서 발생하기 때문에
학습 하는데도 오랜 시간이 걸린다.
🔗참고자료
- [2019] Spring JPA의 사실과 오해 ⇒ **링크
- JPA 프록시 객체에 대한 이해 부족 ⇒ **JPA Hibernate 프록시 제대로 알고 쓰기**
- 이유가 잘 정리되어 있는 글 ⇒ Spring Data JPA - LazyInitialization 에러
- LazyInitializationException: could not initialize proxy - no Session Error ⇒ **링크
- [JPA] 일반 Join과 Fetch Join의 차이 ⇒ 링크
