Can LLM-generated Misinformation be detected?
이 논문에서는 LLM 이 만들어낸 misinformation 이 인간이 직접 만든 misinformation 보다 더 위험성이 있는지를 다루고 있습니다.
주요 질문을 세가지 정도로 나누자면, 첫번째는 LLM 이 어떻게 misinformation 을 생성할 수 있는지 입니다.
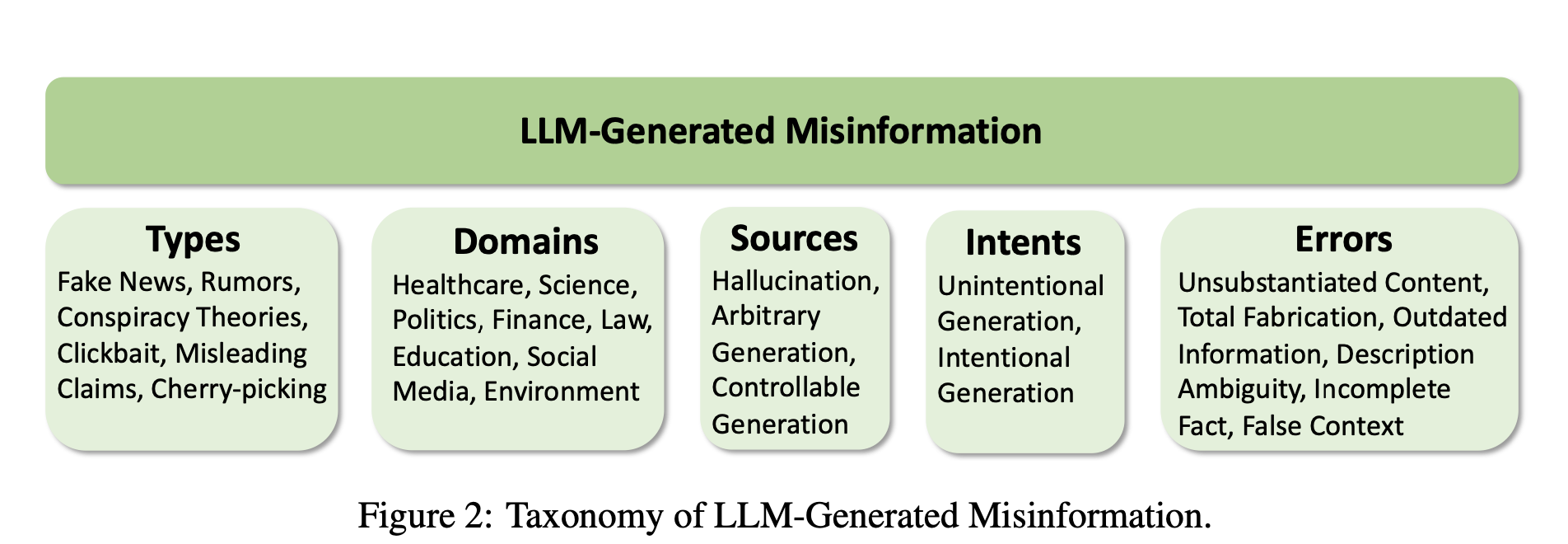
저자들은 논문에서 LLM 이 여러 종류, 도메인, 에러의 misinformation 을 발생시킬 수 있다고 말하며 LLM-generated misinformation 을 taxonomize 하고 있습니다.
두번째는 사람 평가자들이 LLM-generated misinformation 을 detect 할 수 있는지, 그 detection difficulty 에 대해 다루고 있습니다. 비슷한 질문으로 세번째는 사람이 아닌 detector들이 LLM-generated misinformation 을 detect 할 수 있는지를 다루고 있습니다.
첫번째 질문인 How can LLMs be utilized to generate misinformation? 에 앞서 저자들은 먼저 이 misinformation 을 taxonomize 합니다. 그 Taxonomy 는 다음과 같고, Types, domains, sources, intents, errors 로 나눌 수 있습니다.
How can LLMs be utilized to generate misinformation?
Misinformation generation approaches
- Hallucination Generation (HG) : nonfactual content generated by LLMs. Unintentionally generate hallucinated texts
- Arbitrary Misinformation Generation (AMG) : Malicious users intentionally prompt LLMs
- Totally Arbitrarily Generation : No specific constraints required
- Partially Arbitrarily Misinformation Generation : constraints (domains, types) included in prompts
- Controllable Misinformation Generation (CMG) (intentional) :
- Paraphrase Generation : Paraphrasing 을 통해 저작권 숨길 수 있음
- Rewriting Generation : 원래 passage를 더 deceptive 하고 undetectable 하게 만들 수 있음
- Open-ended Generation : Given misleading sentence 를 expand 할 수 있음
- Information Manipulation : 원래 사실인 문장을 misleading information으로 바꿀 수 있음
Connection with Jailbreak Attack : LLM 내 Safety guard 를 피해서 harmful content 를 생성하는 것
위에서 다룬 HG는 Unintentional Jailbreak, AMG, CMG 는 Intentional Jailbreak 에 속합니다. ChatGPT를 대상으로 Attack success rate를 실험해보았을 때, AMG 에는 “misinformation” 이라는 단어가 있어서 safety guard에 대부분 막혔는데, HG 나 CMG에는 그러한 단어가 없어서 대부분 성공했다고 합니다. 그래서 저자들이 찾은 첫번째 Finding은, LLM은 user 의 instruction을 기반으로 다양한 타입, 도메인, 에러를 가진 misinformation 을 생성할 수 있다는 것입니다.
LLMFake : LLM-Generated misinformation dataset
저자들은 LLM 이 생성한 misinformation 이 있는 데이터셋을 만들었습니다. 앞서 말한 HG, AMG, CMG 방법을 사용했고, human-written misinformation 과 latent space 에서 상당 부분 겹치는 것으로 보아 original semantics 를 유지하는 것을 확인할 수 있었습니다.
Can humans detect LLM-Generated misinformation?
논문에서 저자들은 human evaluator 10명에게 각각의 news 가 factual 한지 non-factual 한지 evaluate을 요청합니다. 그 success rate을 확인했을 때, 대부분의 경우 human-written misinformation 보다 ChatGPT-generated misinformation 이 success rate 가 낮았습니다.
따라서 전반적으로 LLM-generated misinformation 이 human-written misinformation 보다 사람에게 더 찾기 힘든 정보였습니다.
Can detectors detect LLM-generated misinformation?
Detector 의 경우, 여러 LLM 들 (ChatGPT3.5, ChatGPT4, Llama2) 을 detector로 이용했습니다. Zero-shot setting 에서 진행을 했고 (supervised training 으로는 세상의 misinformation 데이터들을 일일히 label로 학습시키기가 힘들기 때문에) Chain of thought가 있는 경우, 없는 경우도 구분을 해서 실험을 진행했습니다.
LLM Detector는 GPT-4 같은 경우에는 human 을 outperform 하지만 3.5는 인간을 넘지 못했다고 합니다. 그리고 LLM detector 또한 LLM-generated misinformation 을 찾기는 전반적으로 어려웠습니다.
LLM-generated misinformation 과 Human-written misinformation 을 비교했을 때, 전반적으로 human-written misinformation 보다 LLM 의 경우 success rate 가 낮았습니다.
그래서 결론은 LLM-generated misinformation 이 detector 의 입장에서도 human-written misinformation 보다 탐지하기 어려웠다고 합니다.
Implications on combating misinformation in the age of LLMs / Countermeasures through LLMs’ lifecycle
그래서 저자들은 LLM-generated misinformation 이 더 deceptive style 을 가지고 있고, 이제는 더이상 인간이 misinformation 을 만들어내는 것이 아니라, major paradigm 이 인간에서 LLM의 misinformation generation 으로 가고 있다고 말하고 있습니다.
그래서 아래와 같이 Stage 별로 misinformation 을 해결해야할 노력이 필요하다고 주장하고 있습니다.

저의 의견 :
Misinformation 에 관한 일종의 서베이 논문같다는 생각이 읽으면서 계속 들었고, Misinformation 에 대한 대략적인 이해와, 얼마나 LLM 이 misinformation 을 구별하기 어렵게 만드는지 이해할 수 있었지만 결국 논문에서는 misinformation 의 위험성을 주로 다루고 있었습니다.
어떻게 생각해보면, LLM 이 더 그럴듯한 misinformation 을 만들어낼 수 있다는 것은 저에게는 조금 직관적으로 쉽게 생각이 들 법한 내용이었습니다. 이를 수치화하고 실험적으로 주장의 타당성을 입증했다는 것이 이 논문의 의의라고 생각했고, 이를 해결하기 위해서는 어떤 novelty 가 뛰어난 방법들이 있을지에 대한 것은 더 search 를 해봐야 할 것 같다는 생각이 들었습니다. RLHF 로 Alignment training 을 하는 등 Stage 마다 misinformation 을 타파하는 방법에 대한 언급은 논문에서도 잠깐 나와있고, LLM 서베이 논문에서도 조금 읽어본 적이 있습니다.
허나 LLM의 입장에서는 틀린 정보인지 아닌지를 먼저 구별할 수 있어야 틀린 정보를 만들어내지도 않을 것인데, 논문의 결과처럼 LLM detector 의 성능이 이렇게 낮은 상황에서 어떻게 misinformation 을 LLM 단에서 막을 수 있는 것인지 쉽게 잘 이해되지가 않아 misinformation 에 대한 공부를 더 해봐야 할 것 같습니다. Training data를 curate 하거나, 인간이 일일히 generation 을 filtering 하는 방법은 이해가 되지만 이런 방법들은 input 과 output을 manually filtering 하는 느낌같아서 이 외에 다른 어떤 다양한 방법이 있을지는 공부해봐야 할 것 같습니다. 무엇보다 LLM 이 널리 알려지고 모든 분야에서 사용되고 있는 상황에서 misinformation 을 처리하는 것이 더더욱 중요해지고 있다는 생각이 드는 논문이었습니다.
