FANG/ Leveraging Social Context for Fake News Detection Using Graph Representation
Misinformation
Introduction
오늘날 Fake news (다른 말로 disinformation) 은 매우 심각해져 WHO 에서 전염병과 약에 관한 fatal disinformation 을 infodemic 으로 규정짓기도 했습니다. Manual fact-checking 방식이 여러 웹사이트에서 사용되었지만 정보의 양이 갈수록 늘어나면서, 이에 맞춰 fake news 를 찾는데도 external knowledge database 가 필요해졌습니다. 성능이 좋긴 하지만, 사람의 노력이 너무 많이 들어가야 하고 image 나 video 의 경우 textual evidence 가 적용되기 힘들기도 합니다.
최근 연구에서 fake news 와 real news 가 전파되는 과정에서 사람들의 반응 패턴을 관찰한 결과가 있는데, 가짜 뉴스의 경우 처음에는 negative sentiment, 그 이후에는 news 의 신뢰성을 의심하는 글들, 그리고 점차 stance distribution 이 stabilize 됩니다. 진짜 뉴스의 경우에는 supportive post with neutral sentiment 가 점차 stabilize 됩니다. 이렇게 user perception 이 fake news 를 구분하는 데 도움을 줄 수 있습니다.
뉴스 전파에서의 사회적 문맥 (social context) 은 node (social entities) 와 edge (interactions between them) 의 heterogeneous network 로 표현될 수 있습니다. Network representation 은 Euclidean 방식 접근과 달리 echo chamber (비슷한 생각을 가진 사람들하고만 소통하면서 편향적 사고를 하게 되는 것) 나 polarization ( 집단극화 - 개인보다 그룹에 있을 때 더 극단적인 주장을 지지하게 되는 것) 을 반영할 수 있다는 장점이 있습니다.
Graphical model 에서는 user- user, source-source 의 Homogeneous edge 를 통한 정보 교환, user-news (stance expression), source-news (news publication) 등의 heterogeneous edge 간 정보 교환이 있을 수 있습니다.
즉, 이러한 dependent 한 entities 의 representation 을 나타낼 수 있고, 이는 fake news detection 뿐만 아니라 다른 연관된 social analysis tasks (malicious user detection, source factuality prediction) 등까지 가능하게 합니다.
결론은, 저자들은 이 논문에서 Social entities 간의 representation을 향상시켜 fake news detection을 더 잘 해결하려 합니다. 논문을 요약하자면
1. 먼저 Major social actor 와 interaction 을 모델링하는 새로운 Graph representation 을 소개합니다.
2. Social structure 와 engagement pattern 을 반영하는 Inductive graph learning framework 인 Factual News Graph (FANG) 를 소개합니다.
3. FANG을 사용했을 때, fake news detection 성능이 매우 좋아졌고 training data 가 한정되어 있어도 robust 한 모델임을 보입니다.
4. 이 FANG 을 통한 representation 을 이용해 다른 연관된 task를 할 수 있습니다. (뉴스의 사실성 예측 등)
5. Recurrent aggregator 의 attention mechanism 을 통해 FANG 의 explainability 를 설명할 수 있습니다.
Methodology
1. Fake News Detection Using Social Context

다음과 같은 entities 와 interactions 로 social context graph G를 생성합니다. 쉽게 말해서,
A 는 뉴스 기사들,
S 는 뉴스를 publish 한 sources,
U 는 뉴스를 읽고 전파하는 social users,
E 는 A, S , U 안에 있는 entities 간의 상호작용 (article - source, article - user, source - user, user - user, etc)
을 말합니다.
Interaction 에는 여러 타입이 존재하는데, 그 예시는 다음과 같습니다.
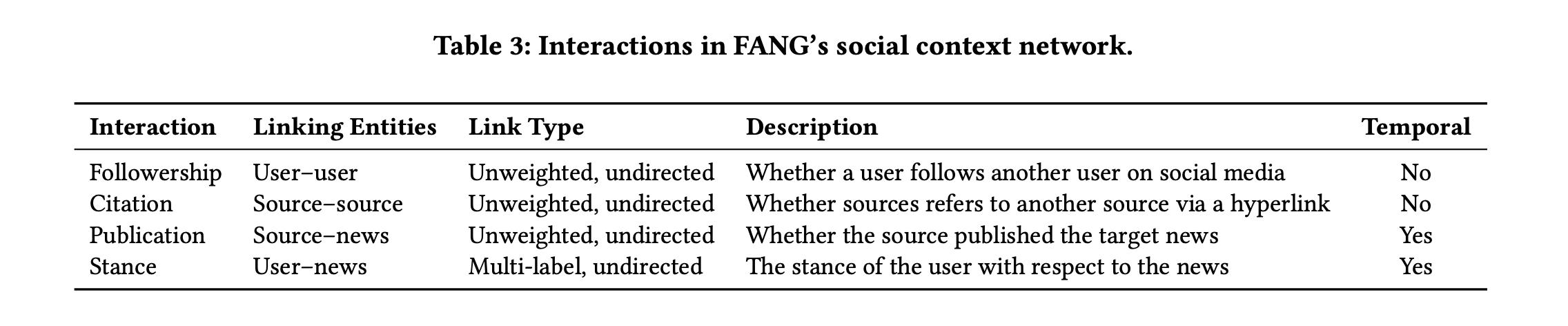
그 중 특별한 것은 Stance 인데, 시간이 반영되고 neutral support, negative support, deny, report 등의 레이블이 있습니다. Report 는 단순히 user 가 기사를 읽고 의견 표출 없이 전파하는 경우를 말합니다.
그래서 저자들은 Fake news detection task 를 G = (A, S, U, E) 에서 A의 원소인 news article a 가 fake 인지 real 인지 구별하는 binary classification task 로 정의합니다.
2. Graph Construction from Social Context
본격적으로 Representation learning 을 진행하기 위해서, 그 전에 먼저 그래프를 생성해야 합니다.
News Articles 의 경우, 저자들은 unsupervised textual representation 을 사용해 news article representation 을 얻어냅니다. 구체적으로 TF-IDF 벡터와 GloVe 에서 pre-trained 된 embeddings (semantic vector) 를 사용합니다.
News Sources 의 경우, 그 source 의 특성을 홈페이지와 about us section 에서 가져옵니다. 마찬가지로 TF-IDF 벡터와 semantic vector 를 사용합니다.
Social Users 의 경우 fake news 를 전파하는 가장 주요한 존재인데, 이전에는 인구 통계, 정보 선호도, 사회 활동, 친구나 팔로워 수 같은 network structure 를 attribute 로 사용했습니다. 그 중 Profile description 과 timeline content 의 중요성을 주장하는 논문도 있었고, 이 논문에서 저자들은 TF-IDF 벡터와 user profile description 에서 sematic vector 를 가져와 합쳐서 user vector 로 사용합니다.
Social interactions 의 경우 간단하게 A, S, U 에 있는 entities 간의 edge를 추가합니다. 이때 user1 이 user2를 팔로우하는지, 기사 a1 을 source1 이 작성한 것인지, 한 source 가 다른 source 를 인용한 것인지 등등을 체크해서 interaction type 을 매깁니다. 시간이 고려되는 publication 이나 stance 는 timestamp 또한 기록합니다.
Stance Detection 의 경우 앞서 말했듯이 article 을 보고 난 후 user 의 반응인데, neutral support (support with neutral sentiment), negative support (support with negative sentiment), deny, report 로 총 4가지 stance 로 나눕니다. 만약 post 를 전처리했는데 (이모티콘, 불용어 등 제거) 기사의 제목과 같다면 그냥 기사를 전파했다 (Report) 고 classify 합니다. 나머지 posts 에 대하여 support 인지, deny 인지 구별하는 stance detector 를 train 합니다.
이때 기존의 유명한 stance detection dataset 들은 target text 에 대한 구체적 설명이 없거나 숫자가 제한되어 있는 등 문제가 있어서, 저자들은 social media post 와 news article 이 담긴 stance detection dataset 을 새로 직접 만들었습니다. 구체적으로는 어떤 news events 들과 그에 맞는 reference headline 이 있는데, 그로부터 생성된 related headlines 와 posts 들이 어떤 스탠스를 가지는지, 또 이 둘이 reference headline 과 스탠스가 같다면 related headlines 와 post 간의 스탠스도 support 로 정하는 등 이러한 것들을 전부 label 합니다.
Stance classifier model 로는 사전학습된 여러 대규모 Transformers 를 이 데이터셋에 fine-tune 해보았는데 RoBERTa 가 가장 성능이 좋아서 이걸 사용했다고 합니다. 또 support 의 경우 negative, neutral 을 구별하기 위해 비슷한 구조의 모델을 sentiment classifier 로 사용했다고 합니다.
3. Factual News Graph (FANG) Framework
앞서 이야기가 길었는데, 가장 중요한 FANG 의 Framework 은 다음과 같습니다.
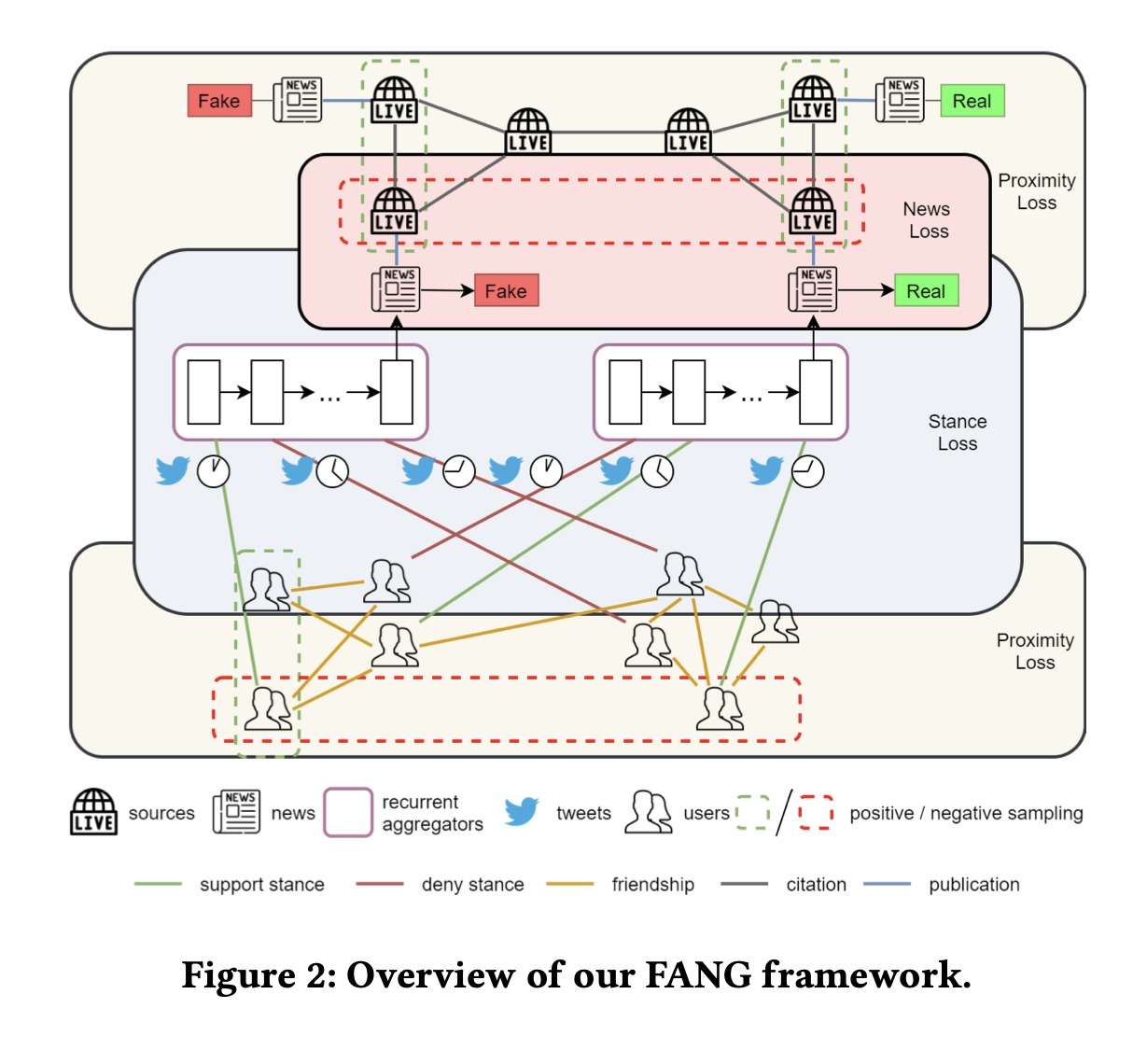
Fake news dectection objective 도 optimize 하지만 FANG 은 social entities 간 generalizable representation 도 학습합니다. 총 세가지 loss 를 optimize 하는데,
Unsupervised Proximity Loss, self-supervised Stance Loss, supervised Fake News Detection Loss
이 세가지를 optimize 합니다. Proximity loss 가 무엇인지 잘 몰라 찾아보니, Graph network 에서 근접한 node 를 가까운 위치에 임베딩하려고 훈련하기 위한 loss 를 말하는 것으로 이해했습니다. edge 의 가중치를 노드 사이의 유사도 측정값으로 매기는 것 같습니다.
Representation Learning
먼저 entities 의 representation 을 정의합니다. 기존에는 Deep Walk 나 node2vec 등을 이용해서 node 의 neighborhood 를 sampling 해서 proximity loss 를 최적화했는데, 이 neighborhood 는 graph structure 에 의해 정해지는 거라, neighborhood structure 에서만 사용하는 방법이고 또 auxiliary node 를 사용할 수 없지만, GraphSage 를 통해서 auxiliary node feature 도 같이 sampling 해서 representation learning 을 진행할 수 있습니다.
(사실 GraphSage를 알기 전에 Transductive setting 과 Inductive setting 을 알아야 하는데, 쉽게 말하자면
Transductive setting : 주어진 데이터셋에만 prediction 진행, 학습하는 방법 / 그래프 node classification 문제에서 보자면 일부 label 이 없는 노드들이 있는 그래프에서는 잘 작동하지 못함
Inductive setting : 관측되지 않은 데이터들 (label 이 없는) 에도 잘 작동하는 모델 학습, train data 만이 아니라 test data 에도 잘 작동/ 그래프에서 보면 새로운 형태의 그래프나 label 이 없는 노드들이 있더라도 잘 예측 가능
인 것 같습니다. 그래서 GraphSage 는 기존의 Graph Convolutional Network(GCN) 등이 다루지 못한 이 Inductive setting 에서의 node classification을 가능하게 한 방법이라고 합니다.)
그래서 GraphSage 를 이용해 user 와 source node 를 structural representation 으로 나타낼 수 있습니다.
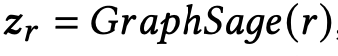
또한, 유저의 특정 news 에 대한 engagement 를 news node 의 structural representation 에 추가하는데 이는 aggregation function 을 학습시키면 가능합니다. 이 function 은 유저의 특정 뉴스에 대한 engagement pattern 을 포착하고, time-sensitive 하다는 특징이 있기 때문에 RNN, 또 더 긴 sequence 를 다룰 수 있는 Bi-LSTM 등이 aggregating model 로 적합합니다. 저자들은 이 Bi-LSTM 을 기반으로 하고 추가로 Attention mechanism 을 사용해 성능도 올리고, explainability 도 보여줍니다. 즉 모델의 attention 행렬을 보면서 어떤 social profile 이 decision 에 영향을 주는지를 분석해볼 수 있습니다.
Bi-LSTM encoder 에 engagement sequence (유저들의 특정 article engagement) 를 input 으로 넣어서 나온 hidden state (forward, backward sequence) 를 이용해 attention weight 을 formulate 합니다. 이는 hidden state 와 news features 의 유사도를 구하기 위해 만들어진 식입니다. 이렇게 weight을 이용해서 forward 와 backward weighted feature vectors 를 구하고 concatenate 후 (이것이 temporal representation) GraphSage 로 구한 structural representation 과 합친 것이 news node 의 최종 representation 이 됩니다.
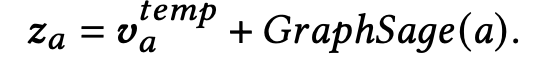
이제 이러한 Representation 을 학습하기 위해 loss 를 정의해봅시다.
Unsupervised Proximity Loss
첫번째로 representation 을 학습하기 위한 proximity loss 를 저자들은 echo chamber phenomenon 과 비슷한 가설에서 가져옵니다. 쉽게 말해 가까운 social entities 는 비슷한 행동을 한다는 가설입니다. 이는 서로 cite 하는 뉴스 sources 가 비슷한 content 를 만들어낸다거나, social friends 가 비슷한 스탠스를 가진다는 점에서 꽤 직관적으로 합당합니다. 또 특정 집단 (좌파/ 우파) 등에 속한 entity 는 스탠스가 비슷하지 않고 확연하게 차이가 보여질 수 있다(집단극화)라는 가설을 추가합니다.
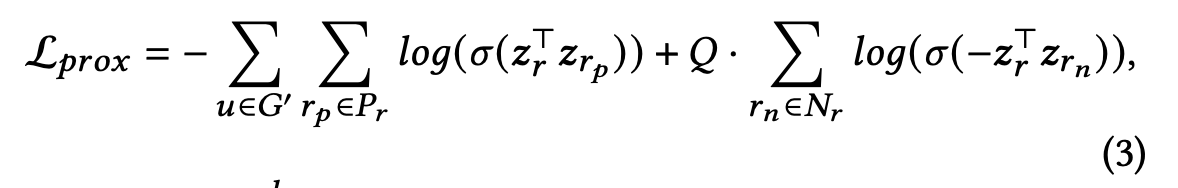
따라서 loss function 이 다음과 같이 정의되는데, 먼저 news-source sub-graph 와 user sub-graph 로 그래프를 나눠서 각각 sub-graph G’ 마다 loss를 구합니다. Zr 은 user entity representation, Pr 은 자신 근처 node 집합 (positive set), Nr 은 아예 떨어져있는 node 들 집합 (negative set) 을 말합니다. 따라서 근처 node 와의 유사성을 최대화하고 멀리 떨어진 node 와는 차이를 극대화하는 것이 이 loss 라고 말할 수 있습니다.
Self-supervised Stance Loss
또한 user 와 news 간의 상호작용에서 또 다른 가설과 loss 를 이끌어낼 수 있습니다. 이는 만약 user 가 특정 news 에 stance 를 보였다면, user 와 news 의 representation 은 stance space 에 project 했을 때 가까워야 한다는 것입니다. user u 와 article a 가 있다면 그 stance space 에서의 representation 의 similarity score 를 구하고 만약 u가 a 에 stance 를 표출했다면 그 score 를 극대화, 아니라면 최소화하는 방식으로 Stance Loss를 정의합니다. 수식은 다음과 같습니다.
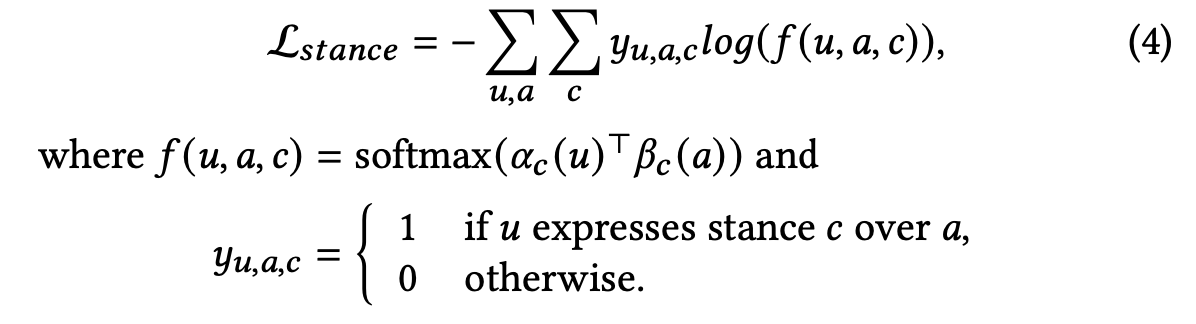
Supervised Fake News Loss
마지막으로 article 이 fake news 인지 predict 하기 위한 loss 를 추가합니다. 먼저 article 의 contextual representation 으로 article 자체의 representation 과 그 article의 source 의 representation 을 concatenate 해서 사용합니다. 이거를 fully connected layer 에 한번 넣고 sigmoid activation을 적용 후에 cross-entropy loss 를 구해서 fake news 인지 아닌지 학습합니다. binary classification task 와 같은 방법이라고 이해했습니다.
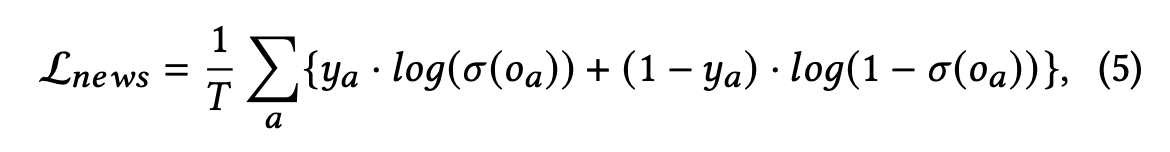
이렇게 3가지 loss 를 정의 후에 다 더해서 total loss 를 만들고 학습을 진행합니다.
Experiments
Data 는 Twitter dataset 에서 news, source, users, tweets, profile 등을 가져올 수 있었고, 추가로 media sources 를 추가하기 위해 source homepage 와 about us page 를 찾아 추가했습니다. Fake news 인지 아닌지는 fact-checking websites 에서 기반했고, 이러한 데이터들을 가져와 정제해서 Stance detection dataset 와 FANG 의 source code 를 공개했습니다.
FANG 의 성능을 여러 모델들과 비교했는데, 첫번째로 news content 만 다루는 content-only model (ex. SVM) 과 비교했습니다. 그 다음은 Euclidean contextual model(ex. CSI) 과 비교했고, 마지막으로 Graph learning model (ex. GCN) 과 비교했습니다. 또한 시간 변수의 중요성을 확인하기 위해 FANG without time 과 FANG with time 모델을 둘 다 사용해보았습니다.
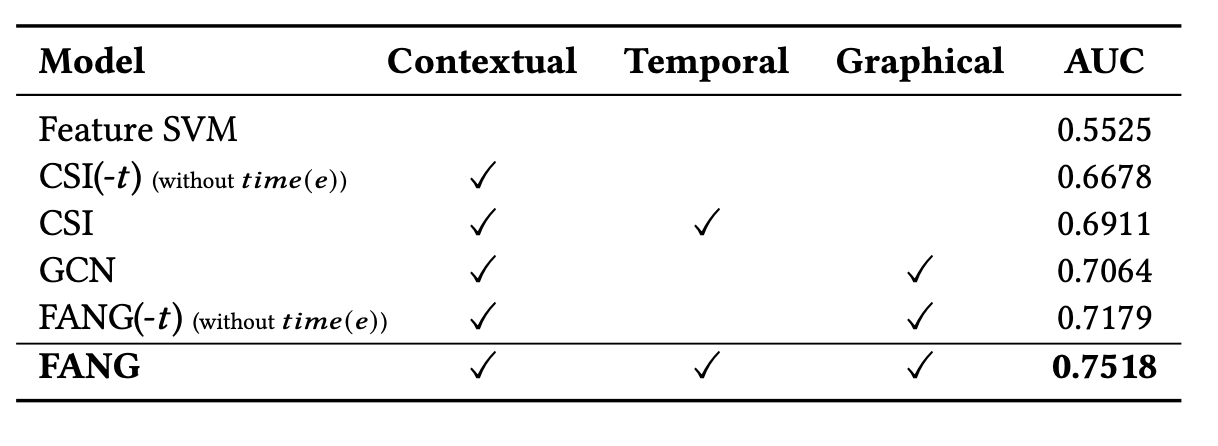
결과는 다음과 같이 FANG 이 다른 모델들보다 성능이 우세했고, 시간적 요소를 추가한 것이 더 성능이 좋았습니다.
Discussion
저자들은 여러 상황에 따른 FANG 의 성능을 보다 잘 이해하기 위해 질문 3가지를 던졌습니다.
RQ1 : Does FANG work well with limited training data?
학습 데이터가 적은 경우로도 다른 baseline model 과 비교하며 실험을 해보았는데, 다른 모델들보다 학습 데이터가 적어져도 성능이 많이 떨어지지 않았습니다. 데이터가 적어도 다른 모델들보다 성능이 좋다는 걸 알 수 있습니다.
RQ2 : Does FANG differentiate between fake and real news based on their contrastive engagement temporality?
Fake news 와 Real news 의 시간별 engagement 가 model 의 decision 에 각각 영향을 어떻게 주고 있는지를 확인해보기 위해 저자들은 앞서 말한 attention weight 를 분석해보았습니다. Fake news 의 경우 publish 되고 12시간까지의 user engagement 가 decision 에 영향을 많이 주고(68.08%) 그 이후로는 점점 낮아졌습니다. 반면 Real news 의 경우 처음 12시간까지는 engagement 가 영향이 더 적었는데(48.01%) 그 이후는 fake news 보다 engagement 의 영향력이 커졌습니다. 도표로 보면 다음과 같습니다.
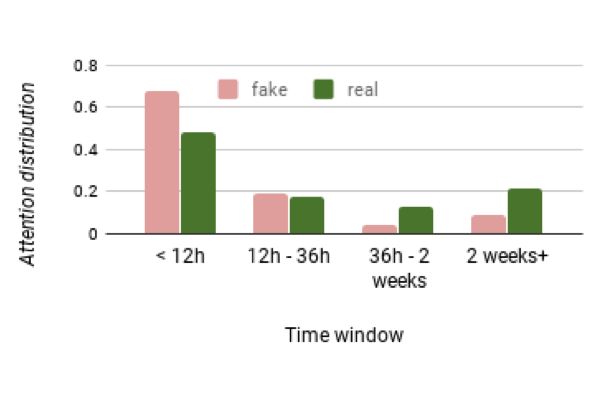
이러한 결과는 실제 현상과 유사합니다. Fake news 가 나오고 짧은 몇시간동안 수많은 crucial engagement 가 발생하고, 이것에 모델이 더 집중해서 decision 을 이끌어내는 것이 합리적이라고 볼 수 있습니다. 반면 Real news 는 나오고 짧은 시간 동안은 engagement 에 영향을 덜 받고, fake news 보다 길게 볼 때 engagement 의 영향이 크다는 것을 알 수 있습니다.
이렇게 모델의 결정이 engagement temporality 에 어떻게 영향을 받고 있는지를 Attention mechanism 을 통해 분석할 수 있었습니다.
RQ3 : How effective is FANG’s representation learning?
얼마나 FANG 을 통한 Representation 이 Generalizable 한지, 그 quality 를 알아보기 위한 실험을 진행했습니다.
Intrinsic evaluation : Unsupervised clustering algorithm 인 OPTICS 를 이용해서 GCN 과 FANG 의 representation 을 clustering 하고 homogeneity score 를 측정했습니다. 이 score 는 쉽게 말해서 같은 factuality label 의 뉴스들이 얼마나 뭉쳐있는지 (가까이 있는지) 를 나타내는 점수입니다.
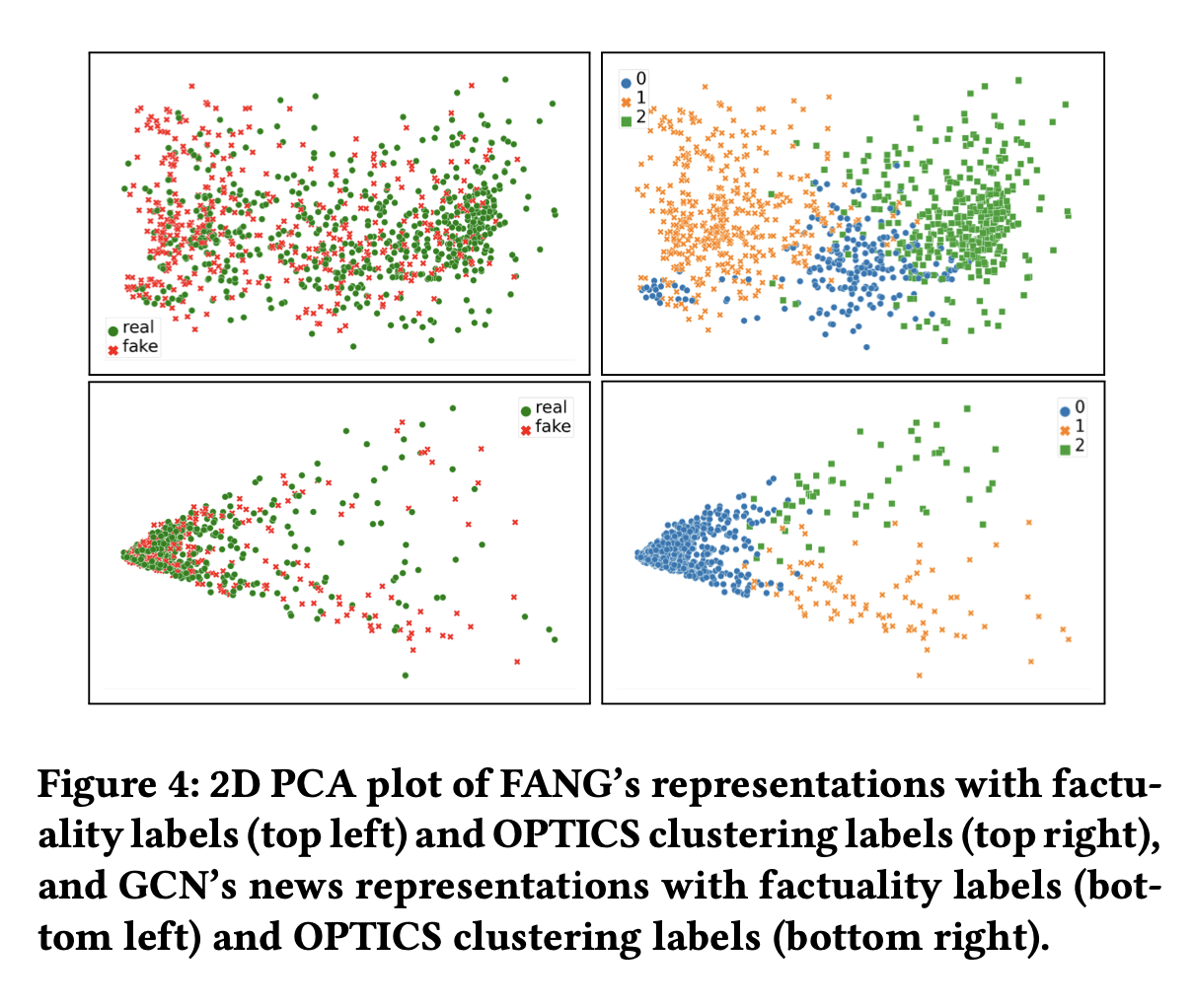
결과는 위 도표처럼 FANG 의 경우가 GCN 보다 더 잘 그룹화되기도 하고, OPTICS 점수도 더 높은 것으로 확인되었습니다.
Extrinsic evaluation : 새로운 task 에 얼마나 generalizable 한지를 직접 확인해보았습니다. 새로운 task 인 Source factuality prediction 을 진행했습니다. 기존의 FANG 을 통해 만든 source representation 과 source content 를 고려하지 않은 representation 을 SVM 에 train 해보았습니다.
그 결과 FANG 을 통해 만든 source representation 을 적용한 context-aware model 이 baseline 모델보다 더 높은 성능을 보였습니다.
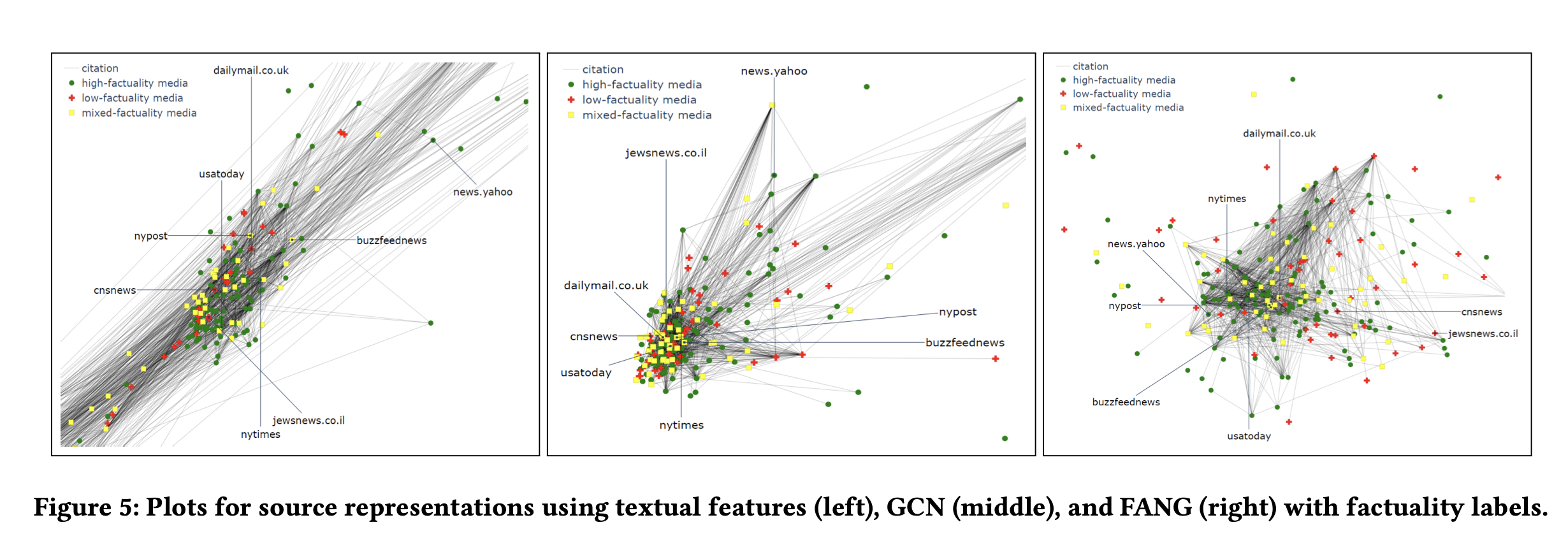
시각적으로 보았을 때도 FANG 의 경우가 더 source 들이 구별되어 보입니다.
이렇게 FANG 은 앞서 말했듯 unseen nodes 에 대해 추론할 수 있다는 장점이 있고, user 의 post, user 간의 관계, source 간 citation 등등 을 기반으로 Fake news 인지 아닌지를 예측합니다.
저의 생각 : 먼저 처음 논문을 보았을 때 FANG 이 굉장히 획기적인 방법으로 느껴졌습니다. user 와 news, sources, 그리고 engagement 를 나타내는 Graph network 를 통해 fake news 를 detect 할 수 있다는 것이 흥미로웠습니다.
그런데 논문에서는 user의 profile description 을 사용했다고 하는데, 쉽게 해결하기는 힘들겠지만 만약 user 의 profile 을 자신이 마음대로 거짓말해서 올렸을 경우에 이거를 representation 에 참고하게 되면 좀 정확도가 떨어질 수도 있지 않을까 싶었습니다.
물론, 유저의 engagement 들이 news representation 에 영향을 주기 때문에 만약 유저가 틀린 engagement 를 자주 올린 경우 supervised fake news loss 에서 어차피 걸러지겠지만, 어쨌든 그렇게 되면 유저의 정보는 추가하는 게 큰 의미가 없어질 수 있다고 생각합니다(이 경우 supervised loss 에 많이 의존되는 것이 아닌가 싶습니다).
결국 Textual 한 방법으로 사실 여부를 구별하는 게 아닌, 사람들의 사회적 관계와 반응 등을 기반으로 만든 느낌을 받아서(제가 이해를 잘 못한 거일수도 있지만), 그래서 유저의 정보를 참고하는 건 좋은데, 그 유저들의 데이터의 신뢰성이 많이 보장돼야 하지 않을까 (Twitter profile description 이 신뢰도가 높은지는 잘 모르겠습니다) 라는 생각이 들었습니다. 아니면 이 논문에서는 그러한 것들까지 다 고려를 하고 있는 것인가요? 제가 잘 이해를 못해서 혹시 틀린 점이 있으면 말씀해주시면 감사할 것 같습니다.
또 궁극적으로 ‘사실’ 이란 무엇인가, 많은 사람들이 맞다고 주장하면 사실인 것일까, 또 공신력있는, 신뢰도가 높은 사람이 맞다고 하는 것은 다 사실일까, 통계적인 면에서는 통상 맞을 것 같지만 그래도 예외도 있을 수 있지 않을까, 여러 생각을 해보게 되는 논문이었습니다.
