매 time-step마다 RNN의 파라미터에 기울기가 더해지므로, 출력의 길이에 따라 기울기의 크기가 달라집니다. 즉, 길이가 길수록 자칫 기울기가 너무 커질 수 있으므로, 학습률을 조절하여 경사하강법의 업데이트 속도를 조절해야 합니다. 너무 큰 학습률을 사용하면 경사하강법에서 한 번의 업데이트 스텝의 크기가 너무 커져, 자칠 잘못된 방향으로 학습 및 발산해버릴 수 있기 때문입니다.
이처럼 기울기 gradient의 크기인 norm이 너무 큰 경우, 가장 쉬운 대처 방법은 학습률로 아주 작은 값을 취하는 것입니다. 하지만 작은 학습률을 사용할 경우 평소 정상적인 기울기 크기를 갖는 상황에서 지나치게 적은 양만 배우므로 훈련 속도가 매우 느려질 것입니다. 즉, 길이는 가변이므로 학습률을 매번 알맞게 최적의 값을 찾아 조절해주는 것은 매우 어려운 일이 될 것입니다. 이때 그래디언트 클리핑 gradient clipping이 큰 힘을 발휘합니다.
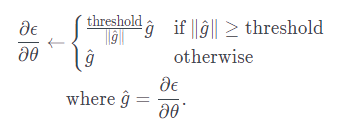
수식을 보면, 기울기 norm이 정해진 최대값(역치)threshold보다 클 경우 기울기 벡터를 최댓값보다 큰 만큼의 비율로 나누어줍니다. 따라서 기울기는 항상 역치보다 작습니다. 이는 학습의 발산을 방지함과 동시에 기울기의 방향 자체가 바뀌지 않고 유지되므로, 모델 파라미터 가 학습 해야 하는 방향을 잃지 않게 합니다. 즉, 손실 함수를 최소화하기 위한 기울기의 방향은 유지한 채로 크기만 조절합니다. 덕분에 이후 소개할 신경망 기계번역과 같은 문제를 풀 때 학습률을 1과 같은 큰 값으로 학습에 사용할 수 있습니다.
다만, 기존의 확률적 경사하강법(SGD)가 아닌, 아담Adam[31]과 같은 동적인 학습률을 갖는 옵티마이저optimizer를 사용할 경우라면 굳이 그래디언트 클리핑을 적용하지 않아도 괜찮습니다. 물론 안전장치로 적용하는 것은 괜찮은 생각입니다.
출처: https://kh-kim.gitbook.io/natural-language-processing-with-pytorch/00-cover-6/05-gradient-clipping
