Deep Learning
1.nn.CrossEntropyLoss() 에 softmax 값을 넣지 않는 이유

파이토치에서는 nn.CrossEntropyLoss가 log softmax와 negative log likelihood를 결합하여 구현되어 있습니다. 따라서, 일반적으로 softmax를 거친 결과를 cross entropy에 직접 입력하지 않습니다.그러나 softmax를
2.Gradient Clipping
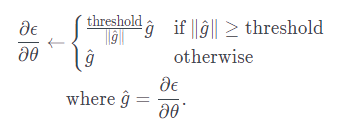
매 time-step마다 RNN의 파라미터에 기울기가 더해지므로, 출력의 길이에 따라 기울기의 크기가 달라집니다. 즉, 길이가 길수록 자칫 기울기가 너무 커질 수 있으므로, 학습률을 조절하여 경사하강법의 업데이트 속도를 조절해야 합니다. 너무 큰 학습률을 사용하면 경사
3.BLEU Score 대략적 지표

BLEU Score 의 대략적 지표라고 합니다...
4.BERT huggingface 사용법
https://heekangpark.github.io/nlp/huggingface-bert
5.zero shot, few shot, fine-tuning, GPT

6.Auto-regressive model, Auto-encoding model
Auto-regressive model : decoder 모듈만 사용함, 자기 자신을 input 으로 넣어 다음 단어를 예측하는 것(generation task 에 유용)ex) GPT, GPT-2Auto-encoding model : encoder 모듈만 사용함, 양방
7.Tokenizer

정규화(normalization) : 불필요한 공백 제거, 대소문자 변환, 악센트 제거
8.Multi-GPU with DP, DDP, FSDP
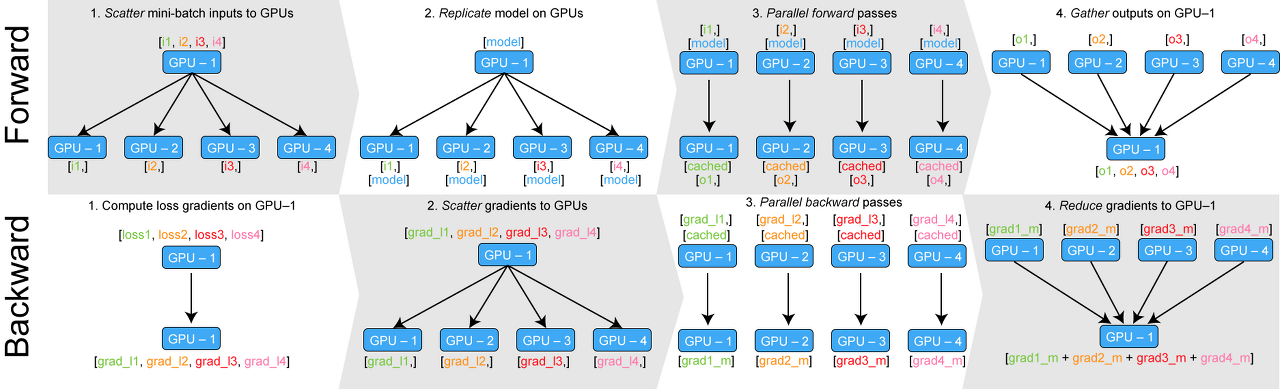
Multi-GPU 로 학습하는 여러 방법들입니다.
9.Chain-of-thought, Zero-shot Chain-of-thought, instruction tuning
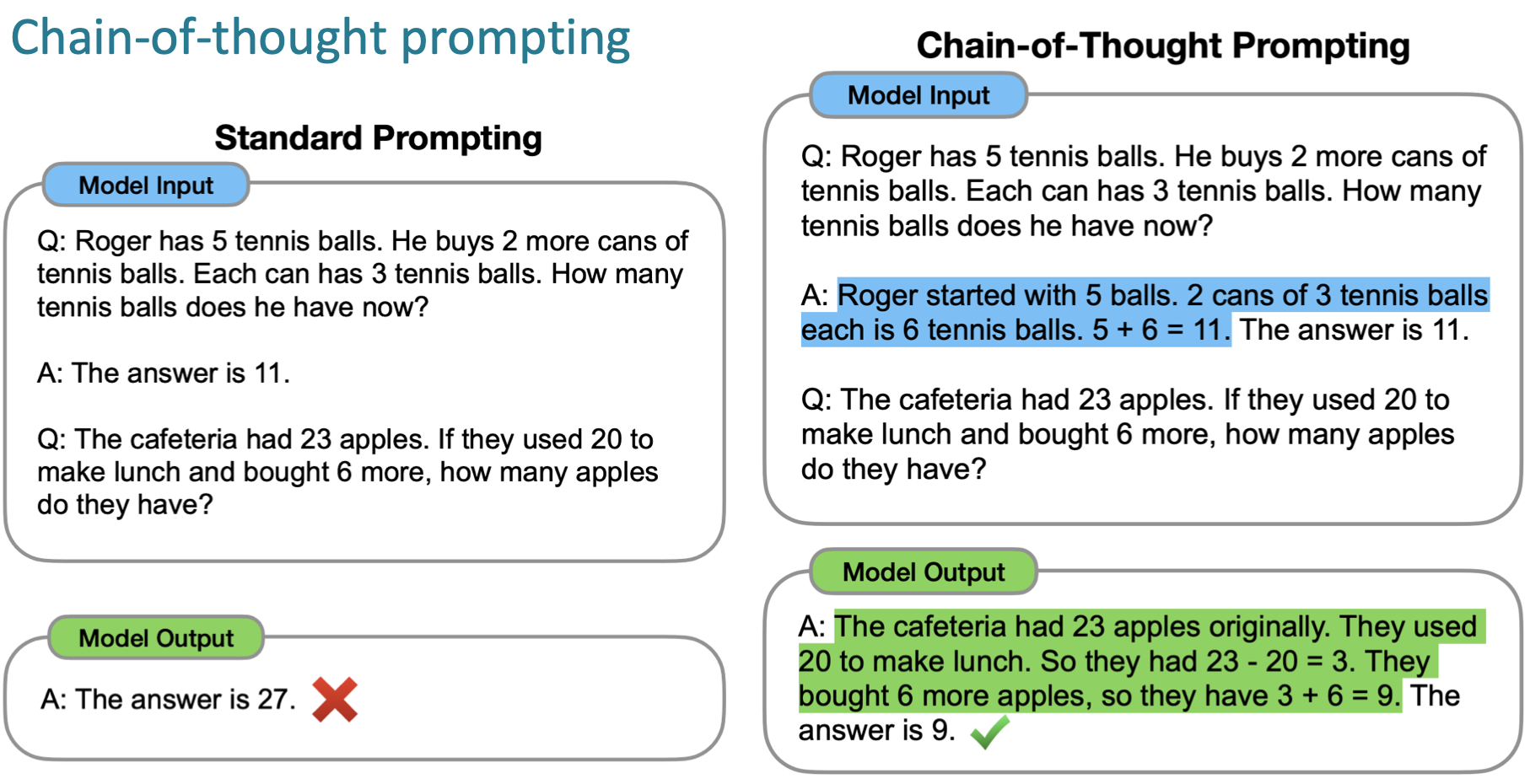
기존 zero shot 에서는 task 만 주어지고 결과 값을 얻을 수 있었고 few-shot 에서는 prompt에 예시를 몇개 주면 결과 값을 얻을 수 있었다.이러한 가중치 조정 없이 prompt를 이용하는 in-context learning 이 대두되면서 여러 st
10.RLHF(reinforcement learning from human feedback)
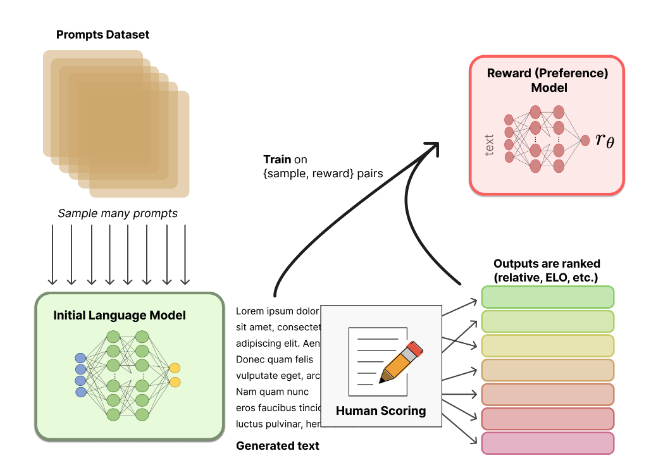
RLHF: RL을 이용하여 human feedback으로부터 LM을 optimize하는 방식1) LM 을 pretrain! (fine-tuning 까지 한 모델 사용할 수도 있음)2) 이 LM 을 통해 reward 모델을 학습같은 query 에 대해 이 LM 을 이용해
11.WandB
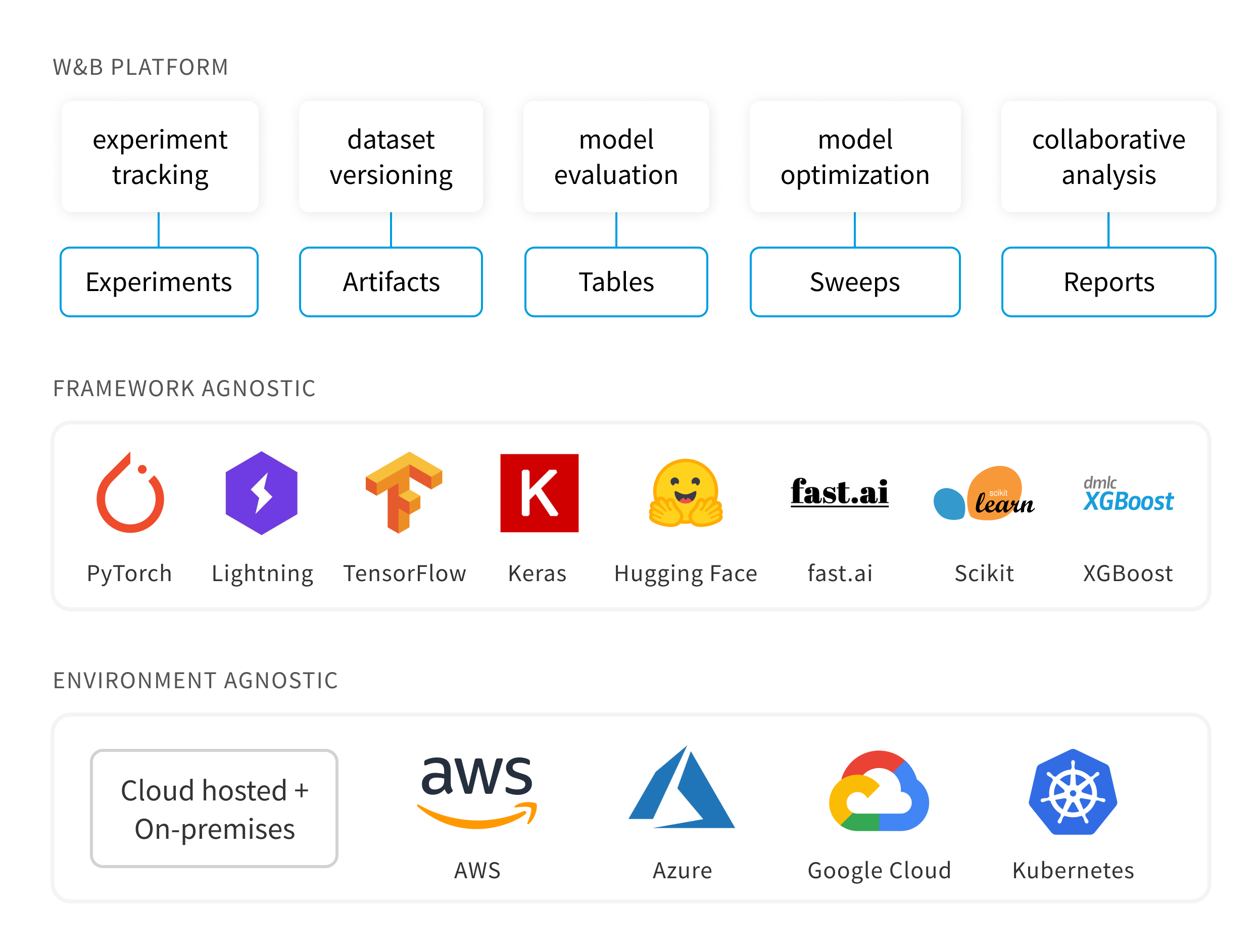
WandB: 머신러닝 실험 toolW&B PlatformExperiments머신러닝 모델 실험을 추적하기 위한 Dashboard 제공.ArtifactsDataset version 관리와 Model version 관리.TablesData를 loging하여 W&B로 시각화
12.PEFT(parameter efficient fine-tuning)
LORA
13.BPE, Sentencepiece
BPE : byte pair encodingSentencepiece: BPE + alpha
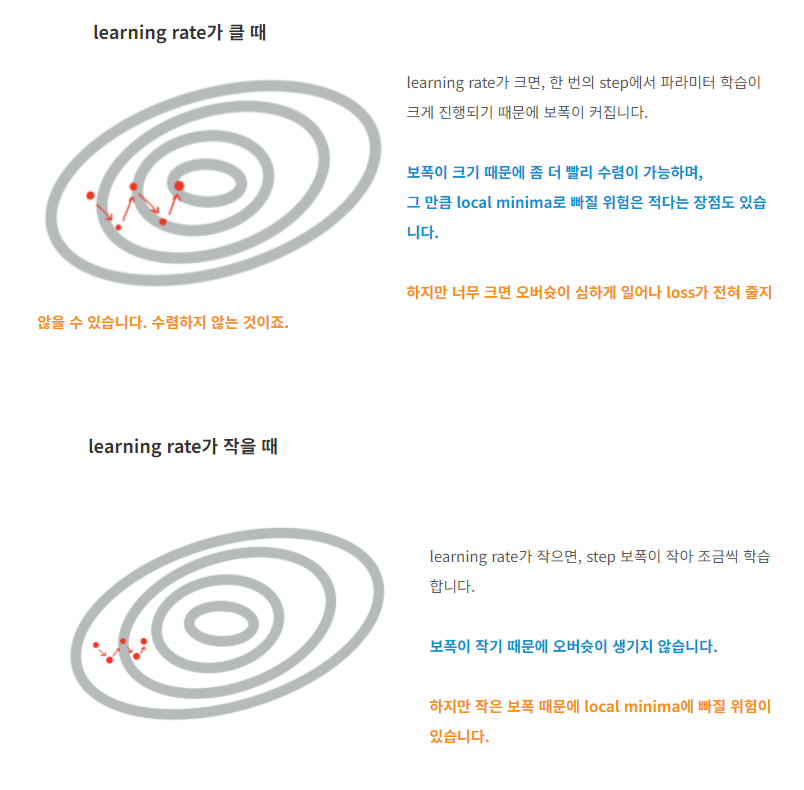
14.Batch size & learning rate
15.gradScaler, Autocast
부동소수점(숫자를 표현하는 방식)이 FP32 인 경우 많은 메모리를 차지해 학습 속도가 느려질 수 있음그렇다고 FP16 만 쓰자니 학습 성능이 낮아짐(loss 높아짐)이를 해결하기 위해 FP16 으로 연산하면 빨라지는 부분들(linear layer, conv layer
16.gradient checkpointing
gradient checkpointing : gpu에 한번에 안올라가는 모델을 처리하기 위한 방법, 연산량이 늘어나는 대신 차지하는 메모리 양이 줄어든다.사용방법 : model.gradient_checkpointing_enable()출처 : https://di
17.Information retrieval
Sparse retrieval : 빠름 idf : 얼마나 이 단어가 흔치 않게 등장하는가? tf-idf : 그냥 tf 곱하기 idf Doc2Query : document expansion COIL : query 와 문서 공통 단어 유사도 이용 BM25 Dense passage retrieval (DPR) query 와 candidate...