
큐 (Queue)
큐에는 여러 정책들이 있다. 여기서 '정책'이란, 쉽게 말하면 데이터를 넣고 추출하는 방식을 말한다. 기본적으로 많이 쓰이는 정책에는 FIFO가 있고, 그 다음으로 많이 쓰이는 LIFO, Priority 등이 있다.
FIFO의 정책을 사용하는 큐의 동작 원리는 줄 서는 행위와 유사하다. 맛집에 줄 서는 행위를 상상해보자. 제일 먼저 줄을 선 사람이 제일 먼저 줄에서 나가 맛집으로 들어갈 수 있다.
큐의 기능
Enqueue
: 큐에 데이터를 넣는 기능
Dequeue
: 큐에서 데이터를 꺼내는 기능
큐의 구조
FIFO 정책을 사용하는 큐는 대기 줄과 같은 원리로 동작한다. 이러한 큐의 구조는 입구와 출구가 모두 뚫려 있는 터널과 같은 형태로 시각화할 수 있다.
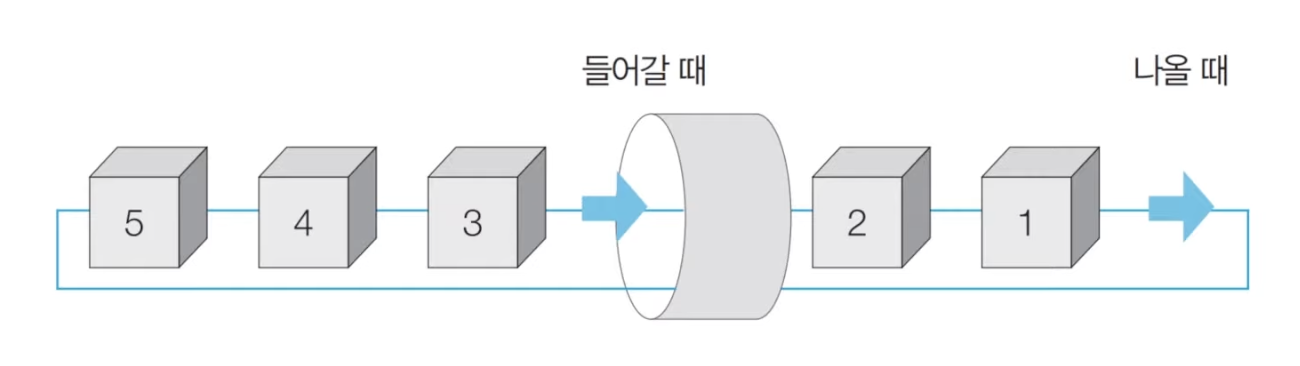
큐의 동작 원리는 아래의 그림을 통해서 좀 더 쉽게 이해해보자.

파이썬으로 큐를 사용하는 방법에는 queue 라이브러리를 활용하는 방법과 리스트를 활용하는 방법, deque를 활용하는 방법 등 여러가지가 있다. 먼저, queue라이브러리로 큐를 사용하는 방법에 대해 알아보자.
1. queue 라이브러리로 큐 사용하기
- multi-threading 환경에서 사용되는 방법으로, 내부적으로 locking을 지원하여 여러 개의 thread가 동시에 데이터를 추가/삭제 할 수 있다.
queue를 사용하기 위해서는from queue import Queue를 통해 모듈에서 호출해야 한다.
FIFO (First In First Out)
: 가장 먼저 넣은 데이터를 가장 먼저 꺼낼 수 있는 정책
## 빈 FIFO 큐 생성
큐이름 = queue.Queue()
## 데이터 넣기
큐이름.put(데이터)
## 데이터 추출 (가장 먼저 넣은 데이터를 가장 먼저 추출)
큐이름.get()
## 현재 큐의 크기 출력
큐이름.qsize()LIFO (Last In First Out)
: 가장 마지막에 넣은 데이터를 가장 먼저 꺼낼 수 있는 정책
## 빈 LIFO 큐 생성
큐이름 = queue.LifoQueue()
## 데이터 넣기
큐이름.put(데이터)
## 데이터 추출 (가장 마지막에 넣은 데이터를 가장 먼저 추출)
큐이름.get()
## 현재 큐의 크기 출력
큐이름.qsize()Priority
: 우선순위를 부여해서 데이터를 넣고, 가장 우선순위가 높은 데이터를 먼저 꺼낼 수 있는 정책
## 빈 Priority 큐 생성
큐이름 = queue.PriorityQueue()
## 데이터 넣기 (우선순위를 매겨서 튜플형태로 데이터를 넣는다)
큐이름.put((우선순위, 데이터))
## 데이터 추출 (우선순위가 가장 높은(=숫자가 가장 낮은) 데이터를 먼저 추출)
## 출력값 형태 : (우선순위, 데이터)
큐이름.get()
## 현재 큐의 크기 출력
큐이름.qsize()2. 리스트로 큐 사용하기
간단한 예제를 통해 살펴보자.
queue = [1, 2, 3] # 큐 생성하기
queue.append(4) # 큐의 마지막에 데이터 추가하기
queue[1, 2, 3, 4]
queue.pop() # 큐의 가장 마지막 원소 추출하기
queue.pop(0) # 큐의 0번째 인덱스에 해당하는 원소 추출하기
queue[2, 3]
queue.insert(0, 6) # 큐의 0번째 인덱스에 원소 추가하기
queue.insert(2, 7) # 큐의 2번째 인덱스에 원소 추가하기
queue[6, 2, 7, 3]
사실 파이썬의 리스트는 인덱스를 통해서 무작위로 접근하는데 최적화된 자료구조이기 때문에, 리스트를 통해 큐를 사용하는 방법은 성능측면에서 좋지 않은 방법이다. 특히, .pop() 함수나 .insert( , ) 함수의 인자로 0을 넘기는 것은 시간복잡도가 O(N)이기 때문에, 담고있는 데이터의 개수가 늘어날수록 성능 측면에서 매우 비효율적이다.
3. deque로 큐 사용하기
✅ deque 자료구조
- "Double-ended queue"의 약자로, 앞뒤로 데이터를 처리할 수 있는 양방향 자료형이다.
collections모듈에서 제공하는 자료구조이다.
(사용법 :from collections import deque)- 스택과 큐의 장점을 모두 갖고있는 자료구조로, 데이터를 넣고 빼는 속도가 리스트에 비해 효율적이며
queue라이브러리를 이용하는 것보다 훨씬 간단하다. deque에서는 내부적으로 '링크드리스트'를 사용하고 있기 때문에 인덱스를 통해서 무작위 접근을 하려고 하면 시간복잡도 O(N)으로 비효율적이다.
간단한 예제를 통해 살펴보자.
from collections import deque # collections 모듈에서 deque 불러오기
queue = deque([1, 2, 3]) # deque 객체 생성하기
queue.append(4) # 데이터 추가하기
queue.append(5)
queuedeque([1, 2, 3, 4, 5])
queue.popleft() # deque 객체의 가장 왼쪽(첫번째) 데이터 추출하기1
queue = deque([4, 5, 6])
queue.appendleft(3) # 리스트에서 insert함수를 사용하는 것과 같은 효과
queuedeque([3, 4, 5, 6])
queue.pop()6
from collections import deque
queue = deque([1, 2, 3, 4, 5])
queue.rotate(2) # rotate(양수) : 오른쪽으로 회전
print(queue)
queue.rotate(-1) # rotate(음수) : 왼쪽으로 회전
print(queue)[4, 5, 1, 2, 3]
[5, 1, 2, 3, 4]
리스트 변수로 enqueue, dequeue 기능 구현
모범답안
## 빈 리스트 생성
>>> queue_list = list()
## 1. enqueue 구현 (매개변수로 들어갈 데이터가 필요하다.)
>>> def enqueue(data):
queue_list.append(data)
## 2. dequeue 구현 (첫번째 요소를 꺼내기만 하면 되기 때문에 매개변수가 필요 없다.)
>>> def dequeue():
data = queue_list[0] # 꺼낼 데이터를 data라는 변수에 지정
del queue_list[0] # 삭제해주지 않으면 계속해서 같은 값이 return 된다
return data## 0부터 9까지의 수로 큐를 생성해보자.
>>> for index in range(10):
enqueue(index)
## 생성된 큐의 크기를 출력
>>> len(queue_list)
10## 첫번째 요소를 꺼내보자.
>>> dequeue()
0내 풀이
처음에 내가 풀었던 풀이도 올려보겠다. 처음에는 왜 내 풀이가 정답이 아닐까 고민하느라 머리 터지는줄 알았다... 근데 코드는 계속해서 쳐다보면 뭐가 보이는게 맞는 듯 싶다 ㅋㅋㅋ
## 빈 리스트 생성
>>> queue_list = list()
## 1. enqueue 구현
>>> def enqueue(data):
queue_list.append(data)
## 2. dequeue 구현
>>> def dequeue():
del queue_list[0]
return queue_list[0]잘 보면 dequeue 구현 부분이 잘못되었다. 내 풀이에서 dequeue() 메소드의 리턴값은 '꺼낸 데이터'를 리턴하는 것이 아니라, 꺼낸 후 queue_list의 첫번째 요소를 리턴한다. 그래서 dequeue()를 호출하게 되면 모범답안과는 달리 '1'부터 출력했던것이다.
🔗 References
