[1]Install Spark
Overview
- 아직은 미숙하게 배워가는 중임에.. 호기심에 실시한 것.
- 사실 윈도우에서 설치하는게 조금 별로인 부분일 수도 있겠다. 하지만 현재의 목표는 테스팅 성공을 통한 실질적으로 동작시켜보는게 주 이므로. window 10 환경에서 실시한다.
- 현재 이전에 사용했던 개발환경 중 문제가 있었다.
- Hadoop을 이미 먼저 깔아버린점.
- hadoop 3.1.2- scala도 버젼이 있었다.
- sacla = 2.11.12
- 이에 대해서 document를 들여다 볼수 밖에 없었지만.. 내가 써먹을 수 있을것 같은것은 환경에 대한 정보 뿐이었다. 그 정보를 바탕으로 2.4.0 spark버젼을 사용해보기로 결정했다.
- scala도 버젼이 있었다.
- 참조한 사항.
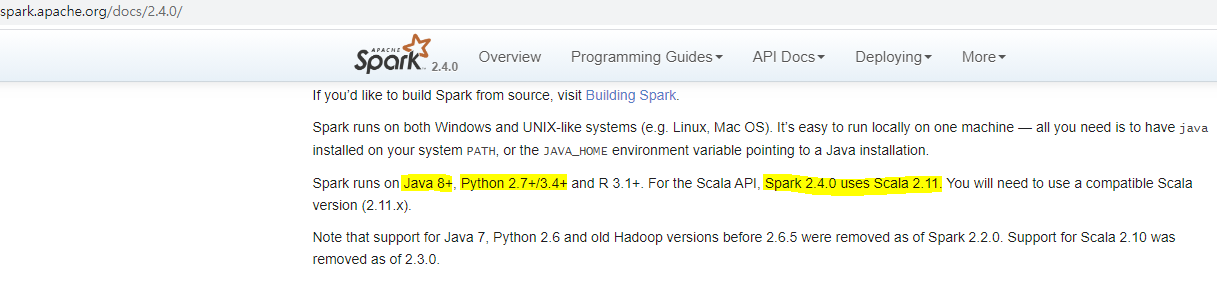
- 해당은 버젼을 받을수 있는 곳으로
- 내가 받은 버젼으로는 2.4.0-bin-hadoop2.7.tgz
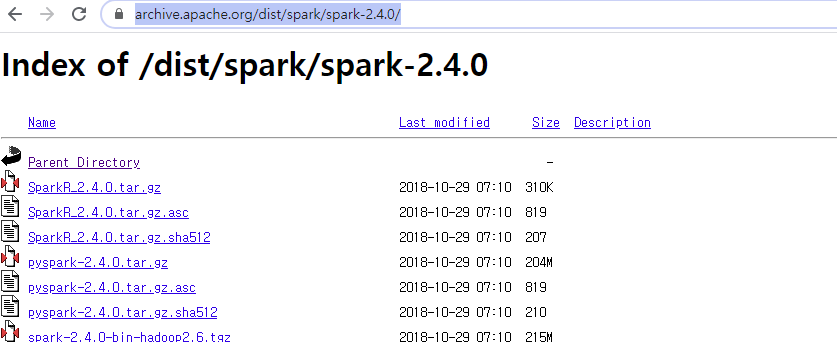
1. Install
- 거창하게 설치! 라고 제목을 붙였으나. 실질적으로 설치하는것은 아니기때문에
- 이른바 압축풀고 환경변수 잡는것.
- 하둡 설정까지는 이미 마친 상태이므로.. 생략한다.
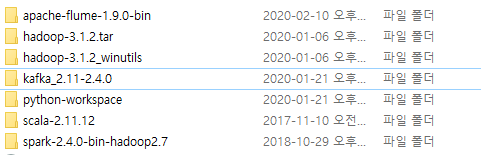
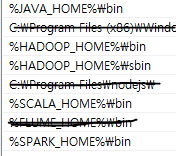
2. 환경변수 설정.
- 변수들을 설정하고, path에 경로까지 설정은 꼭 필수인 일인것.
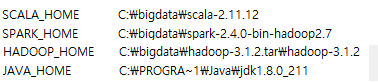
3. Hadoop 남은 잔재를 이용하여
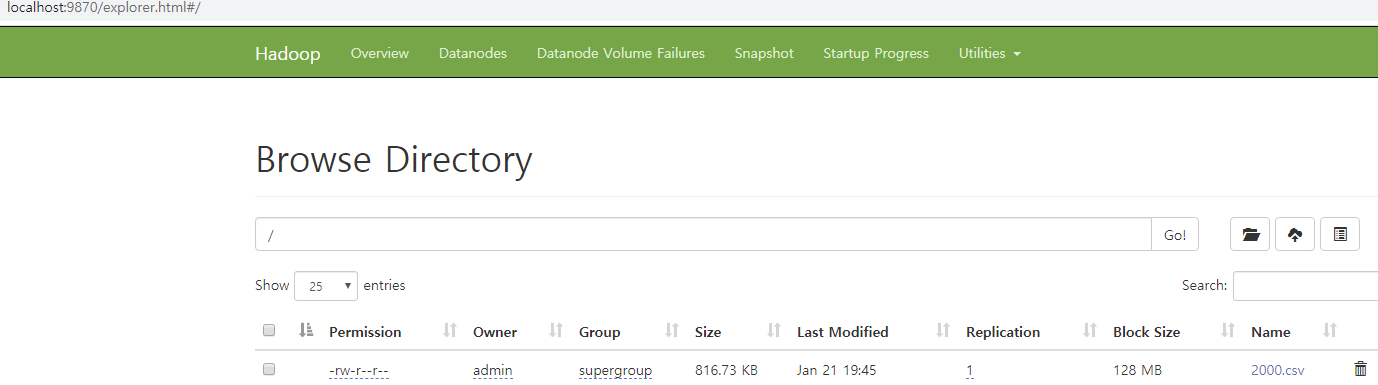
4. Hadoop_Spark Test
- 먼저 명령문들을 줄줄이 실행해야한다.
- 물론 node format을 안했다면
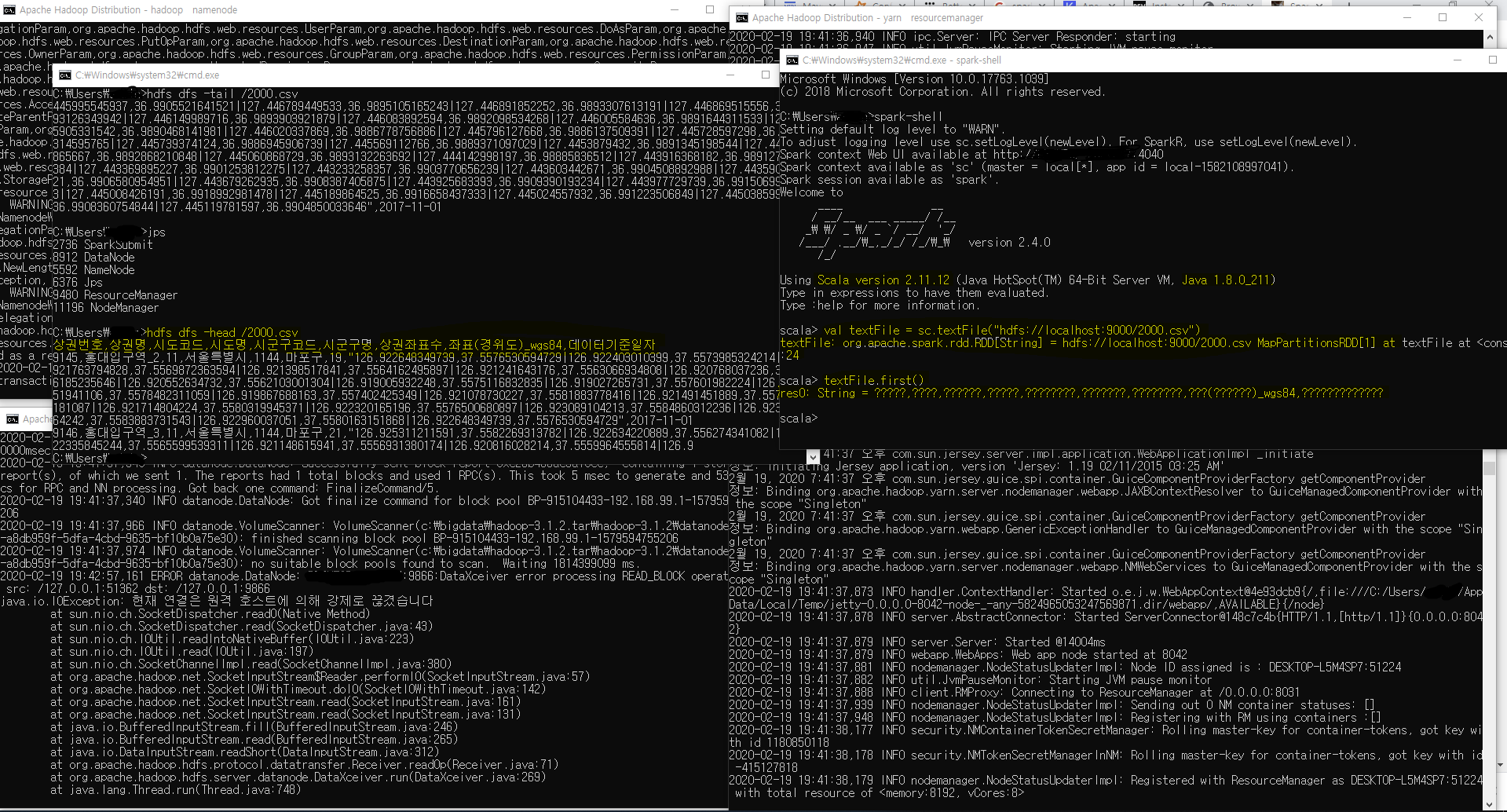
- hdfs namenode -format가 필요하곘지만...- 그리하여 hdfs로도 head로 살짝 정보를 보고
- hdfs dfs -head /2000.csv
- spark에서도 간단하게 실행시켜서 확인해본것,.
- val textFile = sc.textFile("hdfs://localhost:9000/2000.csv")
- textFile.first()
- 나타내는 2개의 정보에서 일치하는 부분이 보인다. 물론 현재 인코딩 문제가 있지만..
- 그리하여 hdfs로도 head로 살짝 정보를 보고
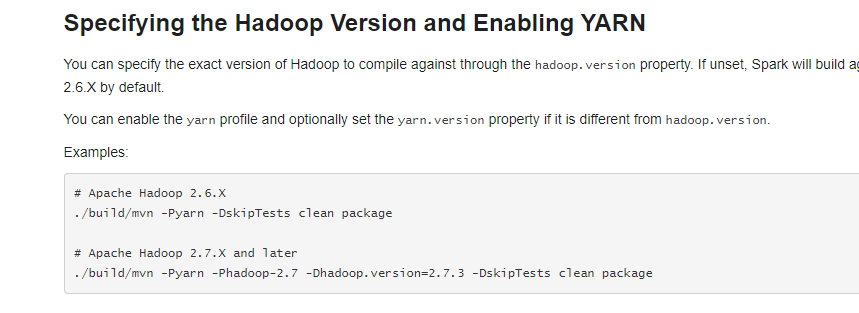
배운 곳 : https://dev.to/awwsmm/installing-and-running-hadoop-and-spark-on-windows-33kc
쩌리 같은 사항
- 여기서는 뭔가 원하는 하둡버젼으로 할수 있다 어쩌고 이야기하는거 같긴한데..
- 아무래도 설치사항일까...

Record My daily life. Then, feedback yourself.