프로젝트 소개
졸업프로젝트를 음성 인식, 모션 인식, 표정 인식을 이용한 참여형 웹 동화 서비스를 개발하였습니다.
모션 인식과, 표정 인식은 따로 모델을 학습시켜 사용했지만,
음성 인식은 Web Speech API를 이용해 프론트엔드에서 비교적 쉽게 구현할 수 있었습니다.
오늘은 Web Speech API 중 리액트에 적용한 react-speech-kit를 프로젝트의 한 부분을 통해 보여드리겠습니다.
저희는 '토끼와 거북이'의 이야기를 각색하여 첫번째 동화를 만들었습니다.
아래와 같이 동화 중간중간 사용자에게 질문 또는 미션을 줍니다.
각 인식별로 대표적인 예시는 아래와 같습니다.
음성 인식의 경우
- 토끼와 거북이 중 어떤 캐릭터가 되어볼까요?
- 나무 밑에서 잠시 쉬어갈까요?
모션 인식의 경우
- 경주를 하기 전에 준비 운동을 해보아요. (팔벌려뛰기)
- 준비 운동을 하지 않아 쥐가 났어요. 스트레칭을 해볼까요?
표정 인식의 경우
- 경기에서 진 토끼는 어떤 표정을 짓고 있을까요?
질문의 대답, 미션 수행 여부에 따라 동화 내용이 달라지게 되어 사용자는 동화의 내용을 이끌어갈 수 있습니다.
음성인식의 경우, 해당 웹서비스가 아이들을 타겟층으로 하고 있기 때문에 5-7세 정도의 아이들까지 즐길 수 있도록 어려운 발음보다는 "빵빵", "콩콩"이라는 발음하기 쉬운 단어들로 선택할 수 있게 개발하였습니다.
요구 사항
해당 프로젝트의 음성인식 페이지에서 구현해야할 부분은 4가지 입니다.-
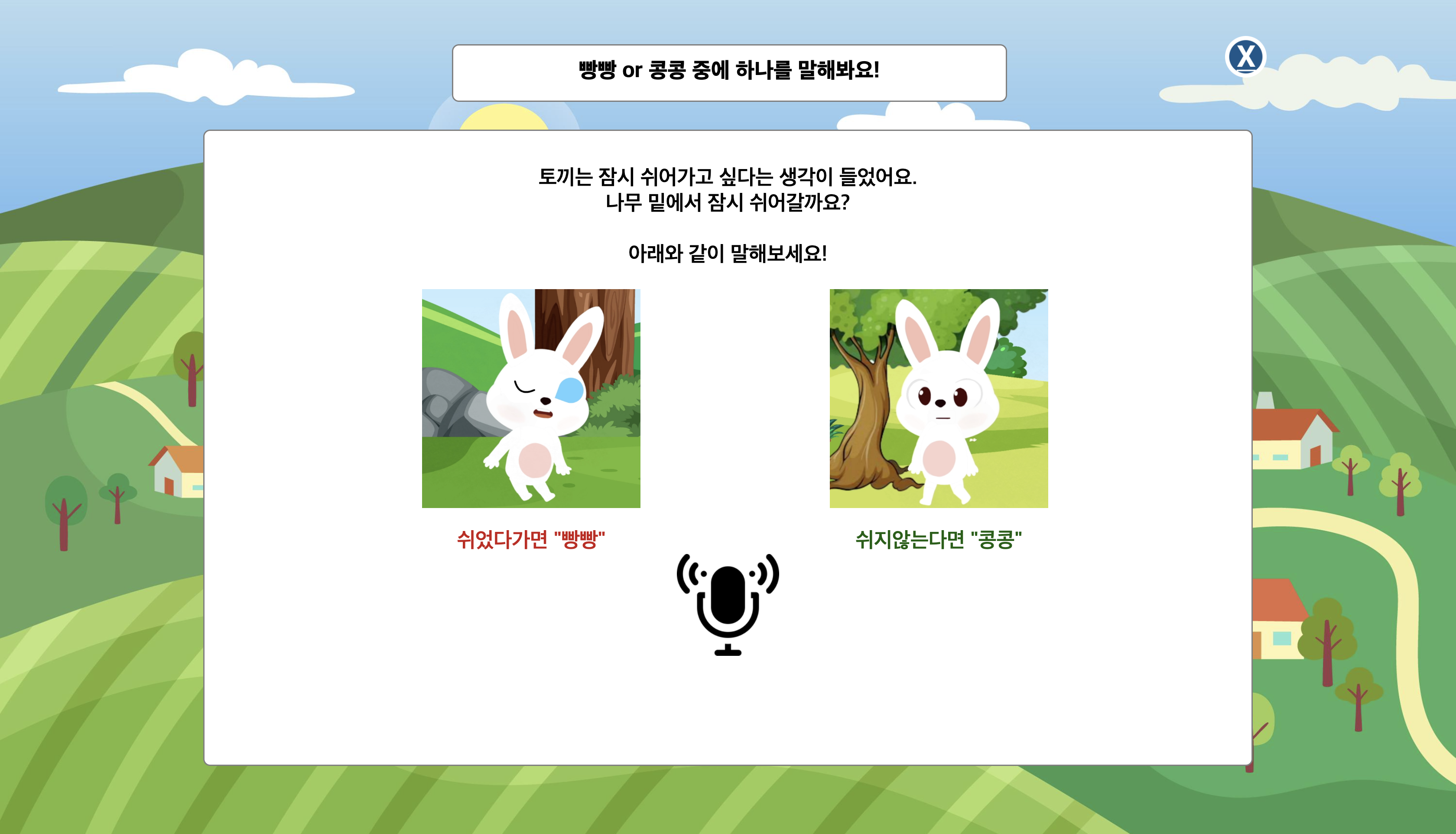
사용자에게 해당 페이지에서 요구하는 내용을 음성으로 말해줍니다.
"토끼는 잠시 쉬어가고 싶다는 생각이 들었어요. 나무 밑에서 잠시 쉬어갈까요?" 로 시작하는 음성이 나오고 이때는 사용자의 음성을 인식하지 않도록 합니다.
-
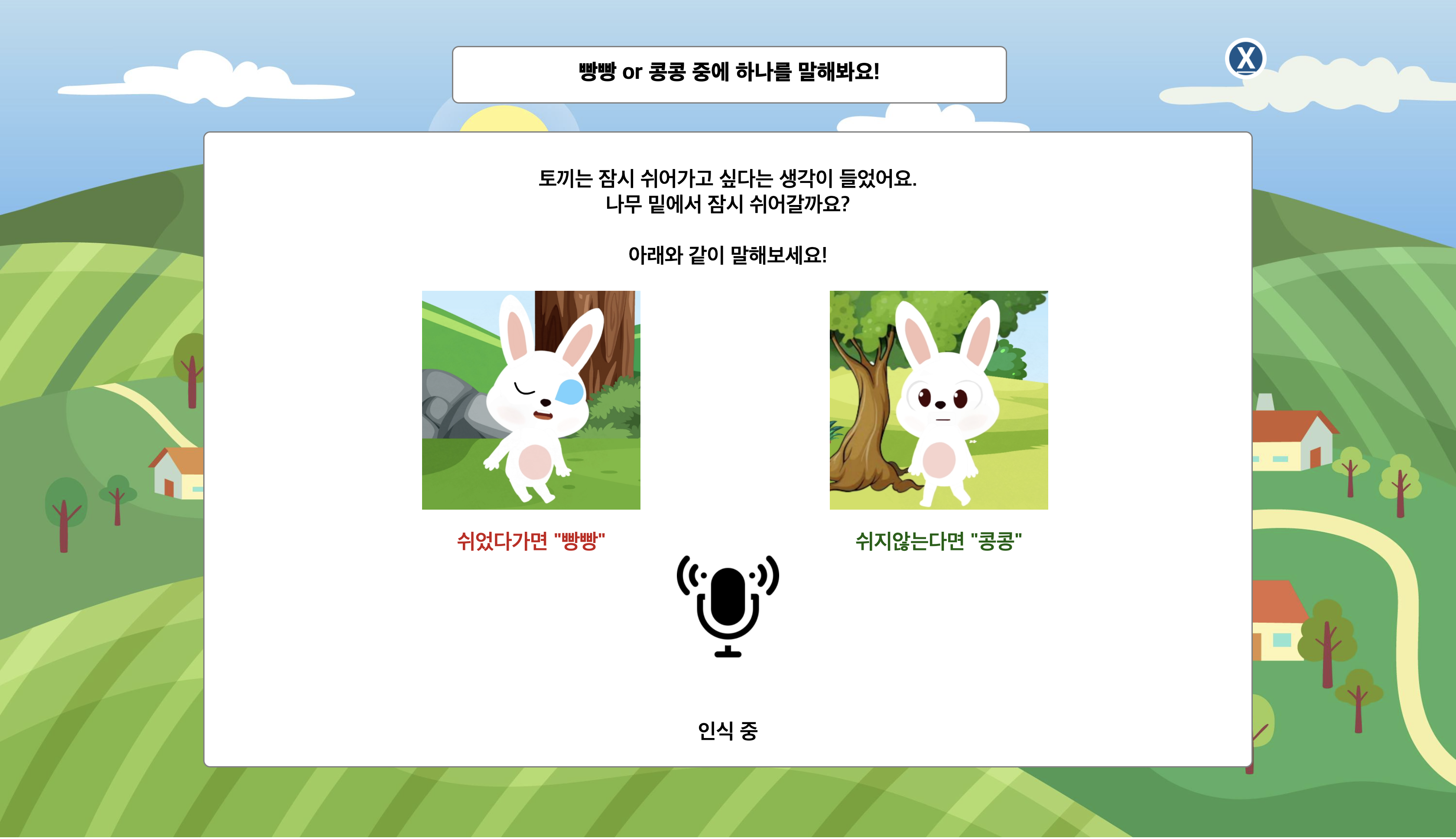
안내 음성이 끝난 뒤 사용자의 음성을 입력받습니다.
이 때 사용자에게 현재 인식 중이라는 것을 알려주어야합니다.
-
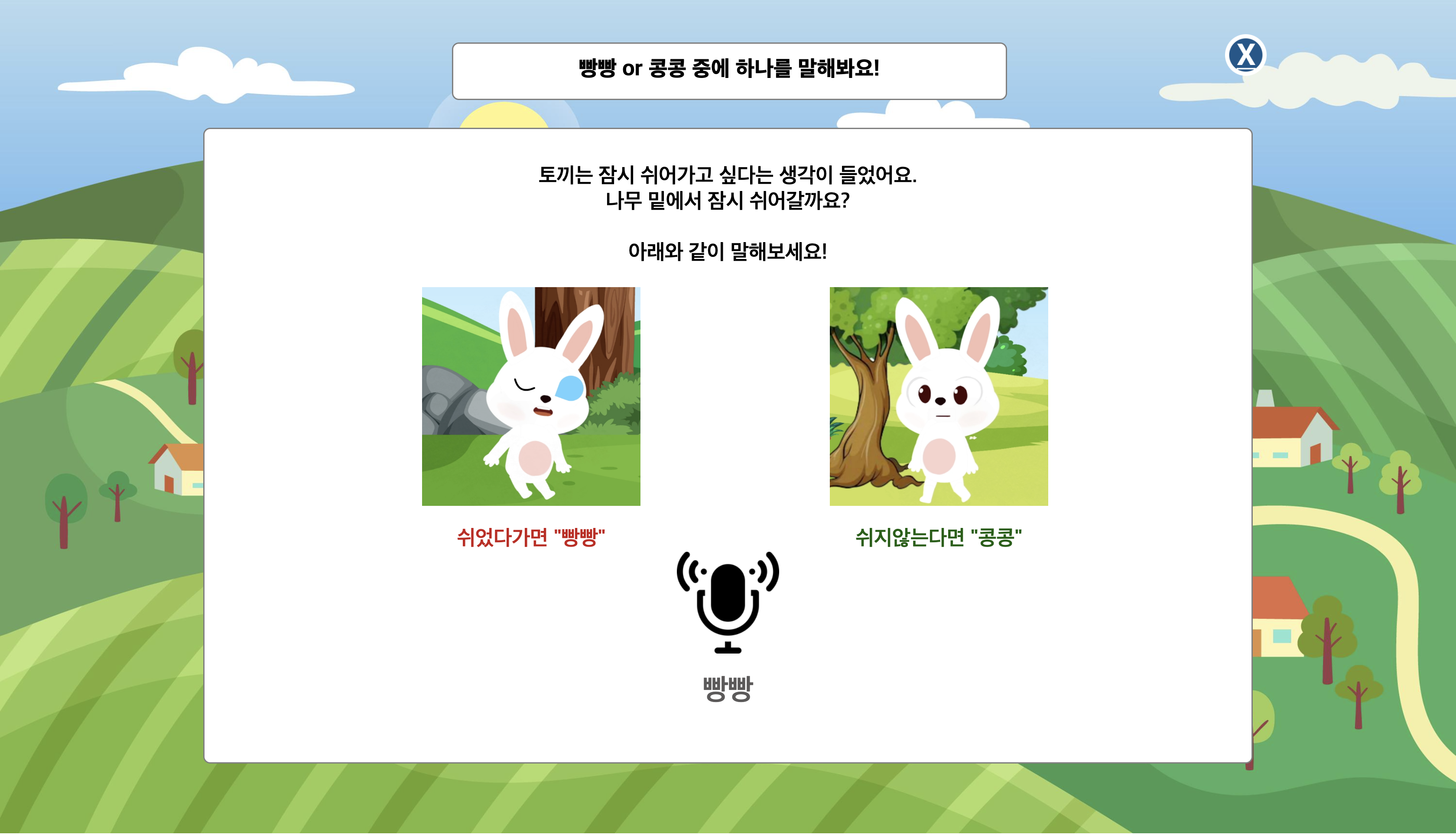
인식한 내용을 화면에 표시합니다. 이 때 말하는 도중이 아닌 말이 끝난 뒤에, 내용을 표시해야합니다.
-
사용자가 빵빵 혹은 콩콩이라고 대답했다면 대답에 따라 다음 내용의 애니메이션이 재생됩니다.

코드
다음은 위의 내용을 구현한 코드입니다.해당 내용을 구현하기 전 먼저 react-speech-kit를 설치해줍니다.
npm i react-speech-kit
(디펜던시 이슈시 npm i --force react-speech-kit)
- 안내 음성 출력
import { useState, useEffect } from "react";
import { useSpeechRecognition } from "react-speech-kit";
import Q3 from "./sounds/B1Q3.mp3";
const B1Q3 = () => {
//안내 음성을 출력하기 위한 오디오 함수
const useAudio = url => {
const [audio] = useState(new Audio(url));
const [playing, setPlaying] = useState(false);
const toggle = () => setPlaying(!playing);
useEffect(() => {
//playing 값에 따라 오디오 재생 / 오디오 정지
playing ? audio.play() : audio.pause();
}, [playing]);
useEffect(() => {
//오디오가 끝나면 playing 변수의 값을 false로 바꿈
audio.addEventListener("ended", () => setPlaying(false));
return () => {
audio.removeEventListener("ended", () => setPlaying(false));
};
}, []);
return [audio, playing, toggle];
};
const [audio, playing, toggle] = useAudio(Q3);
useEffect(() => {
toggle();
}, []);
return (
''' 생략 '''
);
};
export default B1Q3;
- 안내 음성이 끝난 후 사용자 음성 인식
import { useState, useEffect } from "react";
'''생략'''
const B1Q3 = () => {
const [value, setValue] = useState("");
const { listen, listening, stop } = useSpeechRecognition({
onResult: result => {
// 음성인식 결과가 value에 저장
setValue(result);
}
});
useEffect(() => {
// 안내 음성이 끝났을 때 인식
if (!playing) {
// 말하는 도중이 아닌 말이 끝난 뒤(말 사이 텀이 생기면) 출력
listen({ interimResults: false });
}
}, [playing]);
return (
''' 생략 '''
// 대답 출력
<div className="answer">{value}</div>
// 인식 중이라면 "인식 중"이라는 것을 표시
{listening && <div>인식 중</div>}
);
};
export default B1Q3;
- 대답에 따라 다음 장면으로 이동
import { useNavigate } from "react-router-dom";
const navigate = useNavigate();
useEffect(() => {
if (value.includes("빵빵")) {
stop(); // 마이크 off
setTimeout(function() { //사용자가 결과를 확인할 수 있도록 2초 뒤 이동
navigate("/B1Q3_R"); // 다음 페이지로 이동
}, 2000);
} else if (value.includes("콩콩")) {
stop();
setTimeout(function() {
navigate("/B1Q3_L");
}, 2000);
}
}, [value]);

안녕하세요 리액트 음성인식 기술 잘봤습니다.! 다름이 아니라 비슷한 기능을 구현중인데 혹시 토끼가 걸어가는 애니메이션을 단순히 CSS 만으로 하셧는지 아니면 다른 툴을 이용하셨는지 알 수 있을까요!!?