
이번 포스트에서는 Debezium과 Kafka, 그리고 Docker Compose를 활용해 두 개의 MySQL 데이터베이스를 (CDC: Change Data Capture)를 통해 실시간으로 동기화 하려고 한다.
CDC와 Debezium에 대한 설명은 이전 포스트를 참고하면 좋다.
Docker compose로 환경 구축하기
docker-compose.yaml 설정
services:
zookeeper:
image: confluentinc/cp-zookeeper:7.4.0
container_name: zookeeper
ports:
- "9998:9998"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
kafka:
image: confluentinc/cp-kafka:7.4.0
container_name: kafka
depends_on:
- zookeeper
ports:
- "9092:9092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
mysql:
image: mysql:8.0
container_name: mysql
ports:
- "3306:3306"
environment:
MYSQL_ROOT_PASSWORD: password
MYSQL_DATABASE: user
TZ: Asia/Seoul
volumes:
- ./mysql/db:/var/lib/mysql
command: [
"--server-id=1",
"--log-bin=mysql-bin",
"--binlog-format=ROW",
"--binlog-row-image=FULL"
]
connect:
image: debezium/connect:2.5
container_name: connect
depends_on:
- kafka
- mysql
ports:
- "8083:8083"
- "9999:9999"
environment:
BOOTSTRAP_SERVERS: kafka:9092
GROUP_ID: 1
CONFIG_STORAGE_TOPIC: connect-configs
OFFSET_STORAGE_TOPIC: connect-offsets
STATUS_STORAGE_TOPIC: connect-status
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_REST_ADVERTISED_HOST_NAME: connect
CONNECT_PLUGIN_PATH: /kafka/connect,/usr/share/java
kafka-ui:
image: provectuslabs/kafka-ui:latest
container_name: kafka-ui
ports:
- "8080:8080"
environment:
- KAFKA_CLUSTERS_0_NAME=CDC
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=kafka:9092
- KAFKA_CLUSTERS_0_ZOOKEEPER=zookeeper:2181
depends_on:
- kafka
- zookeeper각 서비스는 다음과 같은 기능을 담당한다:
- Zookeeper: Kafka 브로커의 상태를 관리
- Kafka: 변경 이벤트를 전달하는 메시지 브로커
- MySQL: 변경 이벤트가 발생하는 source DB
Debezium이 binlog를 읽기 위해 반드시 log-bin, binlog-format=ROW 설정이 필요하다. - Debezium Connect: Kafka Source/Sink Connector를 등록하고 실행
- Kafka UI: Kafka 토픽 상태와 메시지를 시각적으로 확인할 수 있는 웹 UI 도구
또 다른 서버에 데이터를 백업하기 위한 MySQL을 추가로 설정한다. (target DB)
services:
mysql:
image: mysql:8.0
container_name: mysql
ports:
- "3306:3306"
environment:
MYSQL_ROOT_PASSWORD: password
MYSQL_DATABASE: user
TZ: Asia/Seoul
volumes:
- ./mysql/db:/var/lib/mysql
command: [
"--server-id=1",
"--log-bin=mysql-bin",
"--binlog-format=ROW",
"--binlog-row-image=FULL"
]Debezium Connector 설정
데이터베이스의 변경 사항을 전송하고 감지하려면, Debezium에 Connector를 등록해야 한다.
Connector는 크게 Source Connector와 Sink Connector로 나뉜다.
- Source Connector는 데이터베이스의 변경 사항을 감지해 Kafka로 전송한다.
- Sink Connector는 Kafka로 전송된 변경 사항을 다른 시스템에 반영하는 역할을 한다.
Connector는 JSON 파일로 설정을 정의할 수 있으며, 보통 다음과 같은 형식으로 작성한다.
1. Source Connector (mysql-source-connector.json)
Source Connector는 MySQL 변경 사항을 Kafka로 전송한다.
{
"name": "mysql-source-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"topic.prefix": "mysql-server",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "debezium",
"database.password": "password",
"database.server.id": "1",
"database.server.name": "mysql-server",
"database.include.list": "user",
"database.connectionTimeZone": "Asia/Seoul",
"table.include.list": "user.users",
"include.schema.changes": "false",
"tombstones.on.delete": "true",
"snapshot.mode": "when_needed",
"schema.history.internal.kafka.bootstrap.servers": "kafka:9092",
"schema.history.internal.kafka.topic": "debezium-schema-history.user-2"
}
} 위의 Json에 있는 설정값은 다음과 같다:
connector.class: 사용할 커넥터 클래스topic.prefix: Kafka에 생성될 토픽 이름의 prefix
최종 토픽 이름은topic.prefix.database.table형식
database.hostname: Debezium이 연결할 MySQL의 호스트 이름database.port: Debezium이 연결할 MySQL의 포트번호database.user: Debezium이 연결할 MySQL의 사용자 이름database.password: Debezium이 연결할 MySQL의 사용자 비밀번호database.server.id: MySQL 복제에서 사용하는 고유한 서버 ID
Debezium은 MySQL의 binary log를 읽기 위해 replica처럼 동작하기 때문에, 이 값은 MySQL replication 설정과 충돌하지 않는 값으로 설정해야 한다.database.server.name: Kafka에 전달될 이벤트의 source 필드나 토픽 이름 등에 사용되는 논리적인 서버 이름database.include.list: Debezium이 감시할 데이터베이스(schema) 목록database.connectionTimeZone: Debezium이 연결할 MySQL의 TimeZone 설정
table.include.list: Debezium이 감시할 테이블 목록
schema.table형식으로 작성해야 한다.include.schema.changes: DDL을 kafka로 보낼지 여부
tombstones.on.delete: 삭제 이벤트 시 Kafka에 tombstone 전송 여부snapshot.mode: Debezium이 초기 스냅샷을 언제 수행할지를 결정
initial: 항상 스냅샷을 먼저 수행 (기본값)
when_needed: binlog 위치가 없을 때만 스냅샷 수행
never: 스냅샷 수행하지 않고 binlog에서만 데이터 처리
schema_only: 데이터는 수집하지 않고 스키마만 로딩
schema_only_recovery: 비정상 종료 후 복구용으로만 사용
schema.history.internal.kafka.bootstrap.servers: 스키마 히스토리를 저장할 Kafka 클러스터 주소schema.history.internal.kafka.topic: 스키마 변경 기록용 토픽 이름
이 토픽은 Debezium 내부에서 스키마 변화를 추적하는 데 사용한다.
2. Sink Connector (mysql-sink-connector.json)
{
"name": "mysql-sink-connector",
"config": {
"connector.class": "io.debezium.connector.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"topics": "mysql-server.user.users",
"connection.url": "jdbc:mysql://localhost:3306/user",
"connection.username": "debezium",
"connection.password": "password",
"db.timezone": "Asia/Seoul",
"insert.mode": "upsert",
"delete.enabled": "true",
"auto.create": "true",
"auto.evolve": "true",
"table.name.format": "${topic}",
"transforms": "topicToTable",
"transforms.topicToTable.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.topicToTable.regex": "mysql-server\\.user\\.(.*)",
"transforms.topicToTable.replacement": "$1",
"primary.key.mode": "record_key",
"primary.key.fields": "id",
"connection.hikari.maximumPoolSize": "10",
"connection.hikari.idleTimeout": "300000",
"connection.hikari.maxLifetime": "1800000",
"connection.hikari.keepaliveTime": "300000",
"connection.hikari.connectionTestQuery": "SELECT 1"
}
} 위의 Json에 있는 설정값은 다음과 같다:
connector.class: 사용할 커넥터 클래스tasks.max: 실행할 병렬 태스크 수
일반적으로 1이면 충분하나, 부하에 따라 조정 가능topics: Kafka에서 데이터를 소비할 토픽 이름
connection.url: Debezium이 sink connector로 데이터를 보낼 대상 데이터베이스(JDBC) URLconnection.username: Debezium이 연결할 MySQL의 사용자 이름connection.password: Debezium이 연결할 MySQL의 사용자 비밀번호
db.timezone: Debezium이 연결할 MySQL의 TimeZone 설정insert.mode: insert 동작 모드
insert: 항상 insert만 수행 (PK 중복 시 오류 발생)
update: 존재할 때만update
upsert: PK가 같은 데이터가 존재 시update, 없으면insert수행delete.enabled: Kafka에서 삭제 이벤트가 왔을 때 실제로 DB에서 삭제 여부auto.create: 테이블이 없을 경우 자동 생성 여부auto.evolve: 테이블 컬럼 구조가 변경되었을 때 자동 반영 여부
table.name.format: Sink DB에서 사용할 테이블 이름 형식
${topic}이면 토픽 이름을 테이블 이름으로 사용transforms: 사용할 변환(transform) 이름transforms.topicToTable.type: transform의 종류 (RegexRouter는 토픽 이름 변경에 사용)transforms.topicToTable.regex: 대상 토픽 이름 regextransforms.topicToTable.replacement: 위의 regex을 대체할 테이블 이름 형식
$1은 (.*) 캡처 그룹을 의미
primary.key.mode: 기본키를 어디서 가져올지 설정
none: primary: key 사용 안 함
record_key: Kafka 메시지의 key 필드에서 가져옴
record_value: 메시지 value에서 특정 필드를 PK로 사용primary.key.fields: Primary Key로 사용할 필드 이름
여러 개일 경우 콤마로 구분하지만,insert.mode가upsert일 경우 하나의 필드만 허용
connection.hikari.maximumPoolSize: 최대 커넥션 수connection.hikari.idleTimeout: idle 상태의 커넥션을 유지하는 시간 (ms)connection.hikari.maxLifetime: 커넥션의 최대 수명 (ms)connection.hikari.keepaliveTime: 커넥션 유지를 위한 keep-alive 주기 (ms)connection.hikari.connectionTestQuery: 커넥션 유효성 확인을 위한 쿼리
3. Debezium에 connector 등록
Debezium에 Connector를 등록하려면 아래 명령어를 실행한다:
curl -i -X POST http://localhost:8083/connectors \
-H "Content-Type: application/json" \
-d @mysql-sink-connector.json ## json 파일 경로정상적으로 등록이 되었다면, 다음과 같은 메시지가 나올것이다.
등록된 connector의 설정과 실행중인 작업 및 connector의 종류가 출력된다.
{
"name": "mysql-sink-connector",
"config": {
"connector.class": "io.debezium.connector.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"topics": "mysql-server.user.users",
"connection.url": "jdbc:mysql://localhost:3306/user",
"connection.username": "debezium",
"connection.password": "password",
"db.timezone": "Asia/Seoul",
"insert.mode": "upsert",
"delete.enabled": "true",
"auto.create": "true",
"auto.evolve": "true",
"table.name.format": "${topic}",
"transforms": "topicToTable",
"transforms.topicToTable.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.topicToTable.regex": "mysql-server\\.user\\.(.*)",
"transforms.topicToTable.replacement": "$1",
"primary.key.mode": "record_key",
"primary.key.fields": "id",
"connection.hikari.maximumPoolSize": "10",
"connection.hikari.idleTimeout": "300000",
"connection.hikari.maxLifetime": "1800000",
"connection.hikari.keepaliveTime": "300000",
"connection.hikari.connectionTestQuery": "SELECT 1",
"name": "mysql-sink-connector"
},
"tasks": [],
"type": "sink"
}4. Debezium connector 목록 확인
Debezium에 등록된 Connector를 확인하려면 아래 명령어를 실행한다:
curl -i -X GET http://localhost:8083/connectors아래는 등록된 Debezium connector 목록 예시 이다.
[
"mysql-source-connector",
"mysql-sink-connector"
]CDC 정상 작동 확인
Debezium connector 상태 확인
Debezium에 등록된 Connector의 상태를 조회하려면 아래 명령어를 실행한다:
curl -i -X GET http://localhost:8083/connectors/mysql-sink-connector/status아래는 정상적인 상태일 때 응답 값이다.
{
"name": "mysql-sink-connector",
"connector": {
"state": "RUNNING",
"worker_id": "172.0.0.1:8083"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "172.0.0.1:8083"
}
],
"type": "sink"
}UI for Apache Kafka 통한 상태 확인
Kafka Topic에 변경 사항이 제대로 적재되고 있는지 UI for Apache Kafka를 통해 확인할 수 있다.
Docker Compose에서 설정한 대로 http://localhost:8080 으로 접속하자.
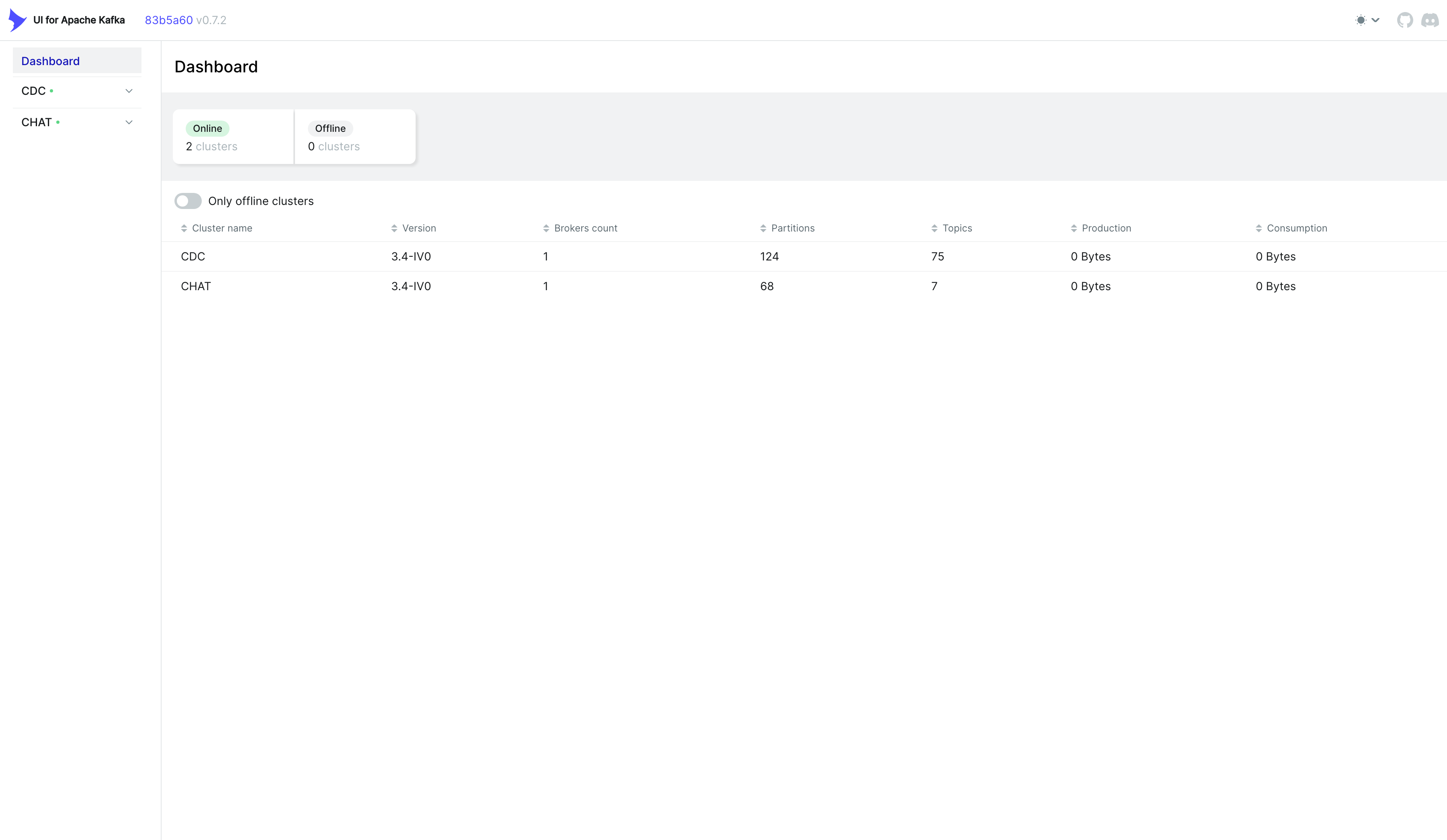
필자는 하나의 서비스를 더 등록해두었기 때문에 두 개의 Kafka 인스턴스가 보인다.
정상적으로 설정했다면 CDC 하나만 보일 것이다.
여러 개의 Kafka 클러스터를 동시에 모니터링하고 싶다면, 아래와 같이 환경 변수를 추가하자 (NUM은 클러스터 번호).
- KAFKA_CLUSTERS_(NUM)_NAME=CDC
- KAFKA_CLUSTERS_(NUM)_BOOTSTRAPSERVERS=kafka:9092
- KAFKA_CLUSTERS_(NUM)_ZOOKEEPER=zookeeper:2181왼쪽 상단의 Kafka 클러스터 이름(CDC)을 클릭하면 Brokers, Topics, Consumers 등의 메뉴가 보인다.
Topics를 선택하면 생성된 Topic 목록을 확인할 수 있다.
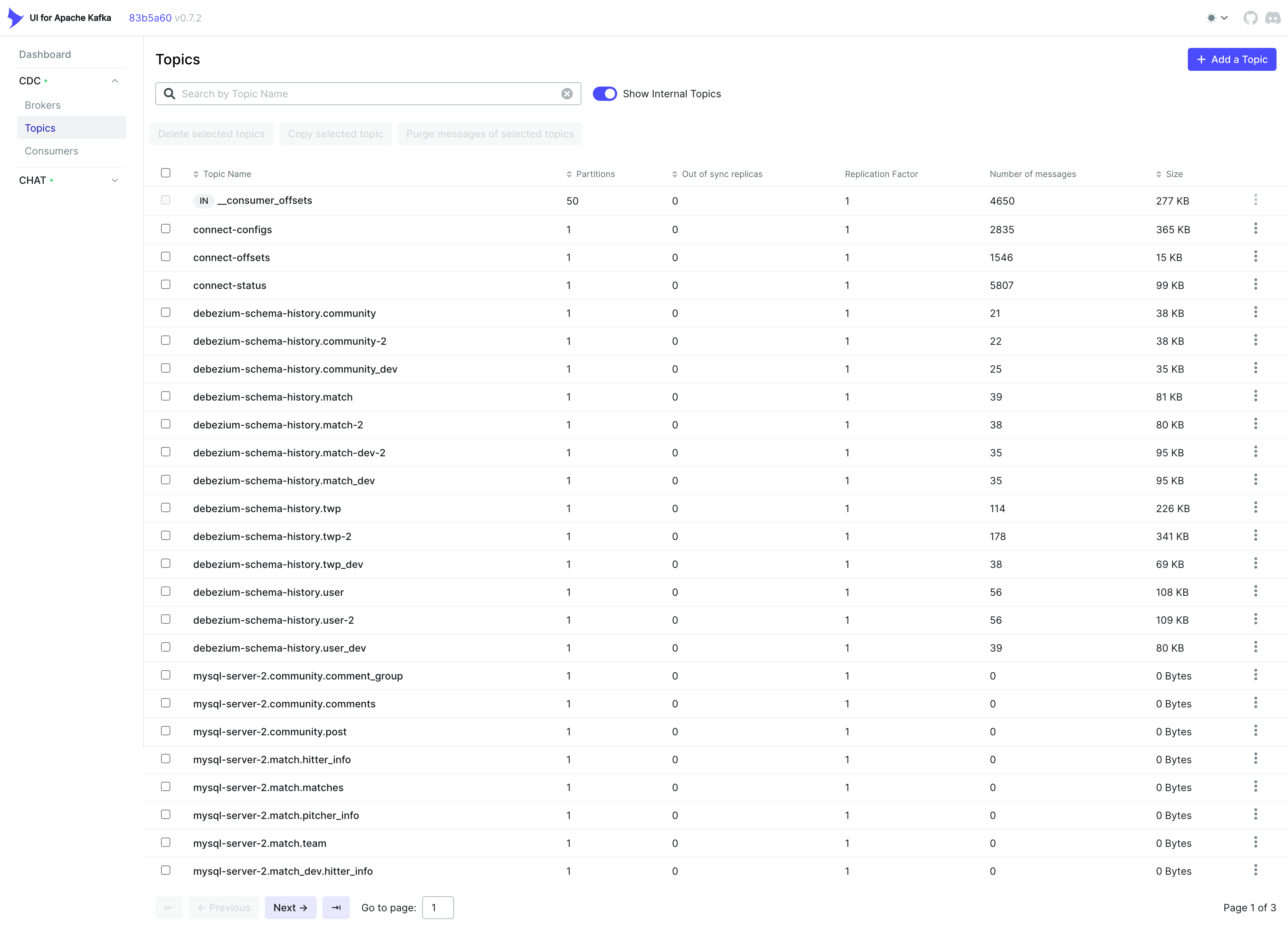
필자는 사전에 구성해둔 설정이 있기 때문에 다른 Kafka Topic들도 함께 표시되고 있다.
등록된 Topic을 클릭하면 상세 정보가 표시된다.
Messages 탭으로 이동하면, Debezium Source Connector가 Kafka Topic으로 전송한 메시지를 직접 확인할 수 있다.
전송된 메시지는 Debezium의 Envelope 포맷을 사용하여 구성되어 있다.
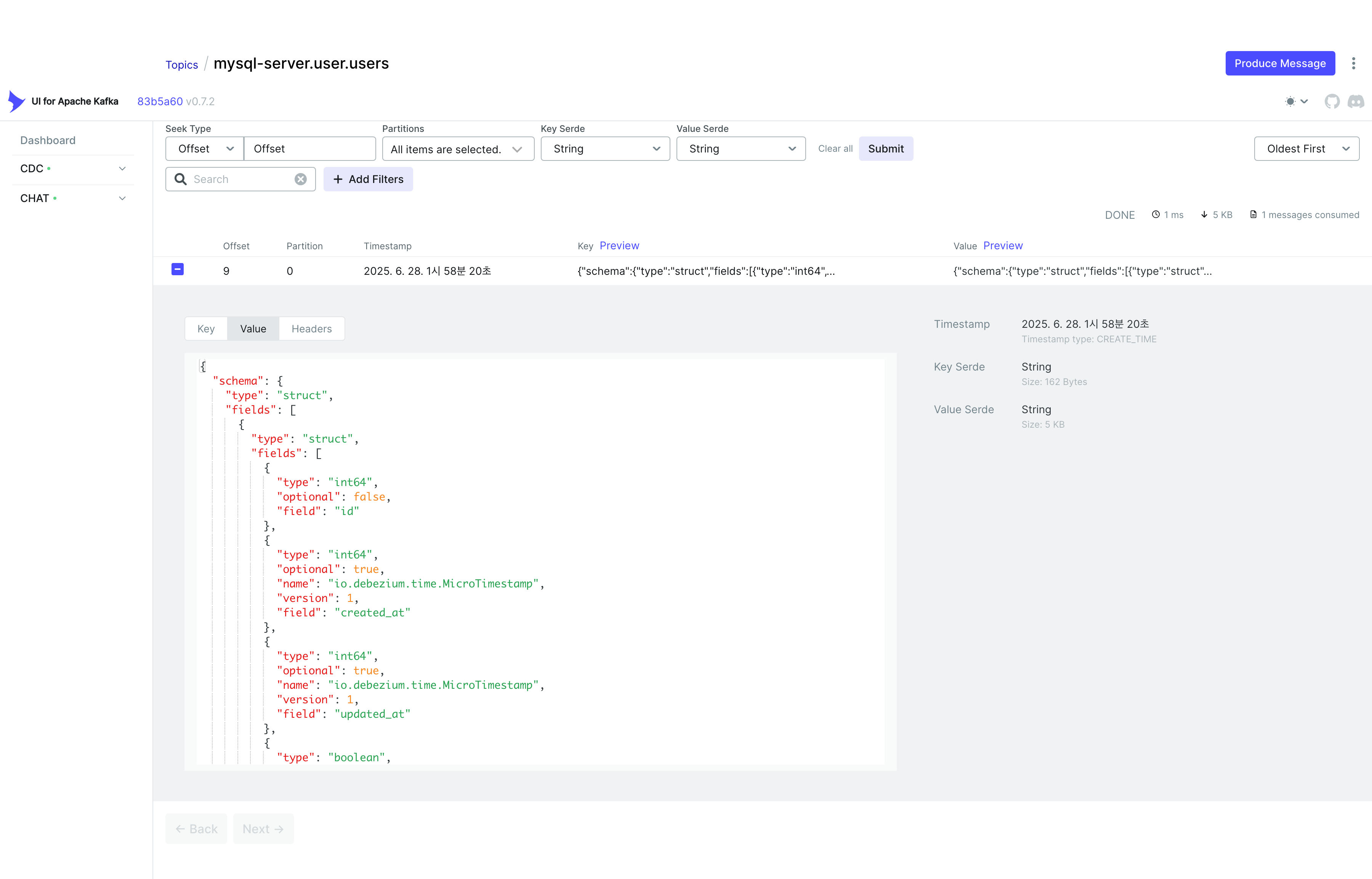
변경 사항의 핵심만 살펴보면 다음과 같다:

before는 null이고, after에 users 테이블에 새로 삽입된 데이터가 나타난다.
이는 새로운 데이터가 삽입되었음을 의미하며, 해당 변경 사항이 Target DB에도 반영된다.
DB 변경 사항 확인
Source DB에 데이터를 삽입하면:

Target DB에도 동일한 데이터가 자동으로 반영된다.

Debezium connector 삭제
Debezium에 등록된 Connector를 삭제하려면 아래 명령어를 실행한다:
curl -i -X DELETE http://localhost:8083/connectors/mysql-sink-connector정상적으로 삭제되면 별도의 메시지는 출력되지 않는다.
삭제가 완료되었는지 확인하려면 Connector 목록을 다시 조회하여 사라졌는지 확인하면 된다.
마무리
이번 글에서는 Debezium과 Kafka를 활용해 MySQL 간 실시간 CDC 파이프라인을 구축해봤다.
다음 포스트에서는 MySQL과 MongoDB, 그리고 Elasticsearch 간의 데이터 동기화를 CDC로 구현하겠다.
