Vision-Language Models (VLM)의 기초
- 본 문서는 2024년 서울대학교 수리과학부에서 Ernest K. Ryu 교수님께서 진행하신 Vision Language Models (VLM) (Generative AI and Foundation Models - Spring 2024) 강의 내용을 정리한 것입니다.
1. CLIP (Contrastive Language-Image Pretraining)
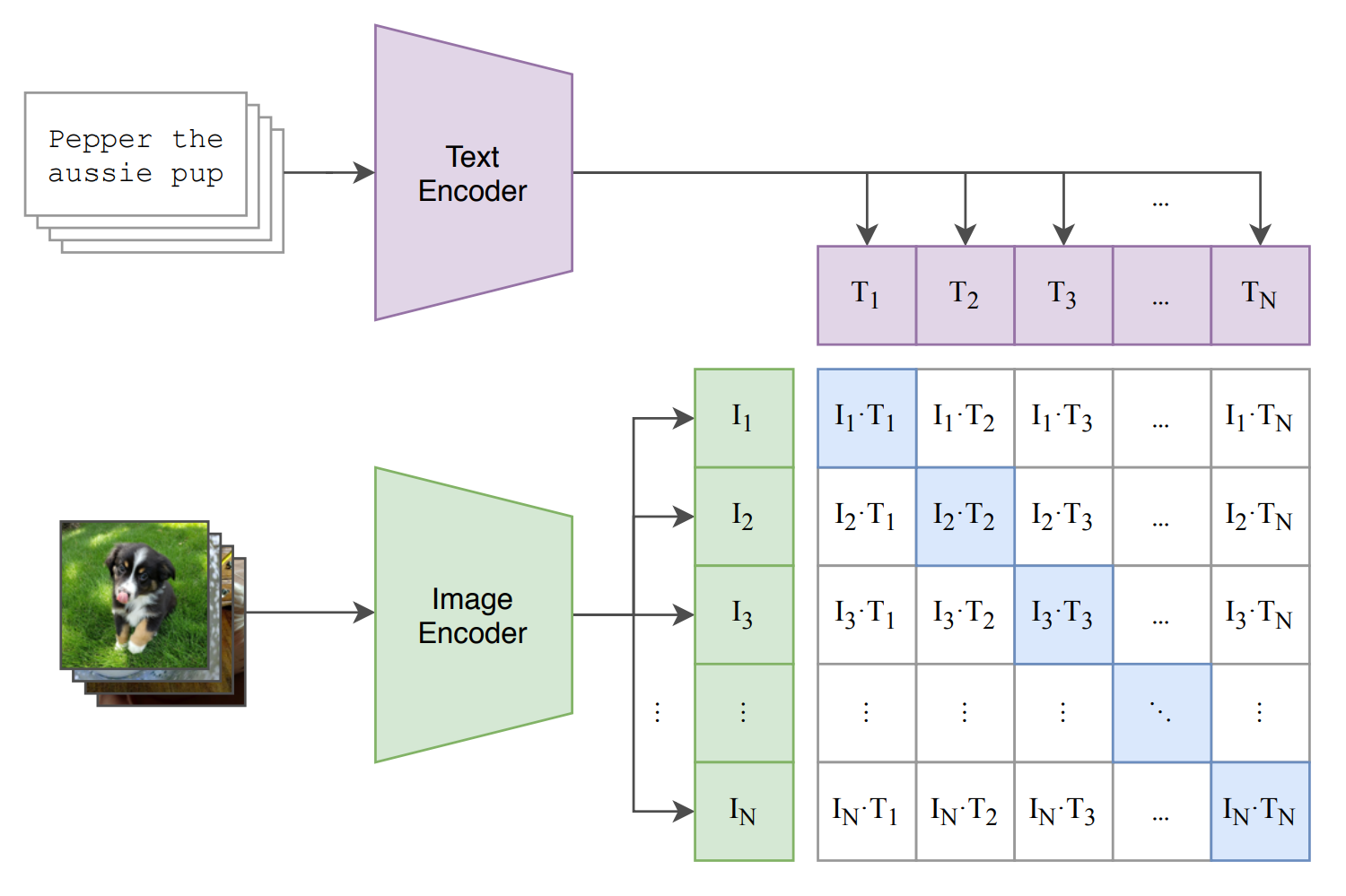
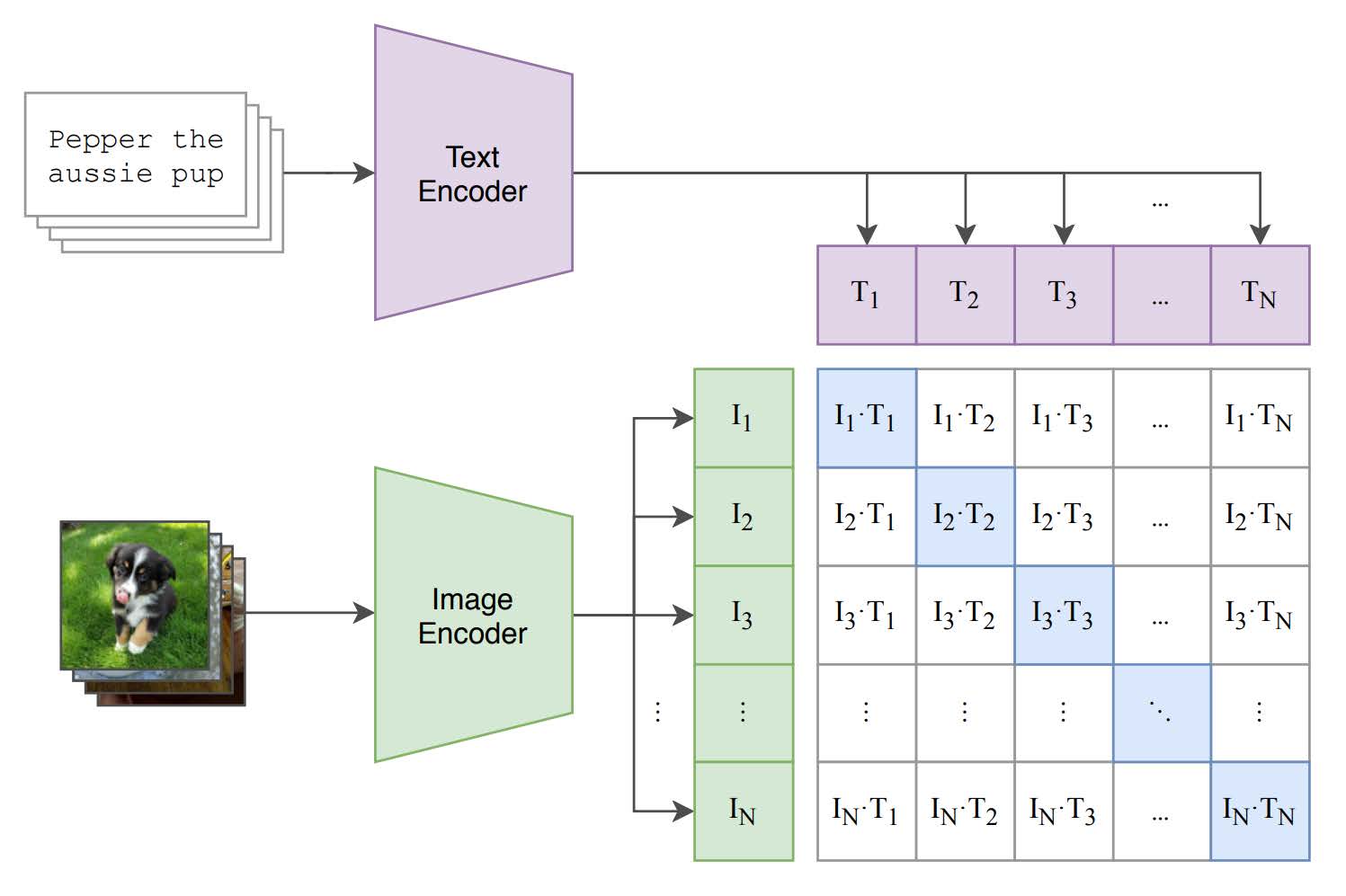
CLIP 모델은 이미지-캡션 쌍 (Xi,Ci)을 이용하여 훈련됩니다.
(cf. Rd: 잠재공간)
1.1 InfoNCE 손실 함수
InfoNCE (Noise Contrastive Estimation) 손실 함수는 다음과 같이 정의됩니다:
LNCE=−N1i=1∑NlogN1∑j=1Nef(Xi,Yj)ef(Xi,Yi)
손실 함수는 다음과 같은 방식으로 해석할 수 있습니다:
-
분자 ef(Xi,Yi): i-번째 데이터 쌍 (Xi,Yi)가 서로 연관될 때의 유사도 점수를 나타냄.
-
분모 N1∑j=1Nef(Xi,Yj): Xi와 모든 Yj (정답 및 오답 포함)의 유사도 점수 합의 평균.
- 이 함수는 기준 샘플 i에 대해 정답 쌍 (Xi,Yi)의 유사도를 최대화하고, 다른 샘플 Yj와의 유사도를 최소화하도록 학습
-
f: 유사도 예시
- f(X,Y)=X⋅Y
- f(X,Y)=∥X∥∥Y∥X⋅Y
- f(X,Y)=logpX(X)pY(Y)p(X,Y)+constant
1.1.1 InfoNCE의 간소화된 정의
InfoNCE 손실은 다음과 같이 간소화될 수 있습니다:
LNCE=i=1∑Nlog∑j=1Nef(Xi,Yj)ef(Xi,Yi)
- 이는 상수 계수 N1 및 상수 항 logN 만큼의 차이를 제외하면 동일한 손실 함수
1.1.2 InfoNCE의 역할
- 기준 샘플 i: 학습 중 현재 선택된 데이터 샘플.
- 비교 대상 샘플 j: 전체 데이터셋에서 모든 샘플을 포함 (정답 쌍 j=i 및 오답 쌍 j=i).
- 손실 함수는 모델이 정답 쌍 ((X_i, Y_i))의 유사도를 더 높이고, 오답 쌍 ((X_i, Y_j))의 유사도를 낮추도록 학습을 유도합니다.
MI는 두 확률변수 X,Y의 상호 정보를 나타내며, 다음과 같이 정의됩니다:
I(X;Y)=∫p(x,y)logpX(x)pY(y)p(x,y)dxdy
2.1 MI와 InfoNCE의 관계
MI≥LNCE
- 이 정리는 변분 바운드(Variational Bound)를 이용하여 증명됩니다.
2.1.1 대략적인 증명 flow (증명은 생략)
- p(x,y), q(x∣y)를 정의
- Jensens's inequality을 적용하여 바운드를 얻음
- logx≤x/e를 활용하여 추가적인 근사
2.2 최적화
Theorem
LNCE→I(X;Y)as N→∞
즉, N이 충분히 크면 InfoNCE 손실 함수를 통해 mutual information을 정확히 근사할 수 있음
[Proof]
Let f∗(x,y)=logpX(x)pY(y)p(x,y)+constant
WTS: LNCE→I(X;Y)as N→∞
LNCE=N1i=1∑NlogN1∑j=1Nef∗(Xi,Yj)ef∗(Xi,Yi)
- 분모를 따로 계산하면,
N1j=1∑Nef∗(Xi,Yj)=econstantN1j=1∑NpX(Xi)pY(Yj)p(Xi,Yj) =econstant⎝⎜⎛N1pX(Xi)pY(Yi)p(Xi,Yi)+N1j=i∑pX(Xi)pY(Yj)p(Xi,Yj)⎠⎟⎞ =O(1/N)+econstantNN−1N−11j=i∑pX(Xi)pY(Yj)p(Xi,Yj) →econstantEX∼pX,Y∼pY[pX(X)pY(Y)p(X,Y)](as N→∞)
≈econstantEX∼pX,Y∼pY[pX(X)pY(Y)p(X,Y)]
=econstant∫x∫yp(x,y)dxdy
LNCE=N1i=1∑NlogN1∑j=1Nef∗(Xi,Yj)ef∗(Xi,Yi)
≈N1i=1∑NlogpX(Xi)pY(Yi)p(Xi,Yi)
≈E(X,Y)∼p[logpX(X)pY(Y)p(X,Y)]
Thus, the proof is complete. ■
3. InfoNCE loss와 Cross Entropy loss
-
InfoNCE loss는 다중 클래스 classification task에서 Cross Entropy (CE) loss과 동일한 구조를 가짐.
-
InfoNCE loss의 각 항 ℓNCE(Y:,Xi)를 다음과 같이 정의
LNCE=i=1∑Nlog∑j=1Nef(Xi,Yj)ef(Xi,Yi)
ℓNCE(Y:,Xi)=log∑j=1Nef(Xi,Yj)ef(Xi,Yi)
- 각 항목 ℓNCE(Y:,Xi)는 Xi를 N개의 클래스로 분류하는 cross entropy 손실로 볼 수 있음.
P(class of Xi=j)∝ef(Xi,Yj)
ℓCE(F(x),i)=−log∑j=1kexp(Fj(x))exp(Fi(x))
-
F: model의 pre-softmax 출력
F(x;Y)=(f(x,Y1),f(x,Y2),…,f(x,YN))
-
따라서, 결론적으로,
ℓCE(F(x),i)=−log∑j=1keFj(x)eFi(x)
Thus, the proof is complete. ■
- CLIP은 MI를 근사하여 이미지와 텍스트를 동일한 잠재 공간(Rd)에 매핑.
- 데이터 처리 불평등(Data Processing Inequality)에 의해 MI의 하한을 얻음.
4.1 InfoNCE 손실 함수
:
CLIP 학습은 다음 InfoNCE (Noise Contrastive Estimation) loss를 최대화:
CLIP Loss Definition
LNCE(θ,ϕ)=N1i=1∑NlogN1∑j=1Nexp(fθ(Xi)⋅gϕ(Cj)/τ)exp(fθ(Xi)⋅gϕ(Ci)/τ)+N1i=1∑NlogN1∑j=1Nexp(fθ(Xj)⋅gϕ(Ci)/τ)exp(fθ(Xi)⋅gϕ(Ci)/τ)
Thus,
LNCE(θ,ϕ)≈i=1∑Nlog∑j=1Nexp(fθ(Xi)⋅gϕ(Cj)/τ)exp(fθ(Xi)⋅gϕ(Ci)/τ)+i=1∑Nlog∑j=1Nexp(fθ(Xj)⋅gϕ(Ci)/τ)exp(fθ(Xi)⋅gϕ(Ci)/τ)
여기서:
-
fθ(Xi): 이미지 Xi의 embedding vector
-
gϕ(Cj): 텍스트 Cj의 embedding vector
-
τ: 온도 매개변수(Temperature Parameter)
-
τ→0⇒ 분포가 sharper해지며, 가장 큰 유사도 값에 더 높은 확률을 할당.
-
τ→∞⇒ 분포가 smoother해지며, 확률이 고르게 분산.
- cf. CLIP에서 InfoNCE 손실 함수를 두 번 정의하는 이유는?
- 텍스트-이미지 간 대칭성(symmetry)을 고려하여 양방향으로 유사성을 학습하기 위함(이미지에서 텍스트로, 텍스트에서 이미지로)
CLIP은 Mutual Information (MI)을 근사하여 학습됩니다.
Mutual Information은 다음과 같이 정의됩니다:
I(X;C)=∫p(x,c)logpX(x)pC(c)p(x,c)dxdc
4.2.2 CLIP에서의 MI 근사
- CLIP은 임베딩 벡터 fθ(X)와 gϕ(C)를 학습하여, 두 벡터의 내적 fθ(X)⋅gϕ(C)가:
- X와 C가 연관될 때 최대화.
- 연관되지 않을 때 최소화되도록 합니다.
데이터 처리 부등식(Data Processing Inequality)에 따르면:
I(X;C)≥I(fθ(X);C)≥I(fθ(X);gϕ(C))
이 부등식은 CLIP 모델이 Mutual Information의 하한을 학습한다는 것을 보여줍니다.
4.3 InfoNCE와 MI의 관계
이전 분석에 따르면 다음이 성립합니다:
I(X;C)≥E[LNCE]=I(fθ(X);gϕ(C))≥21LNCE
- N→∞일 때, I(X;C)=21LNCE의 상한에 도달
또한, 최적의 임베딩 함수 fθ∗(X)와 gϕ∗(C)는 다음과 같이 표현됩니다:
fθ∗(X)⋅gϕ∗(C)+constant=τlogp(X)p(C)p(X,C)=τlogp(C∣X)−τlogp(C)
- (이는 Mutual Information의 직접적인 근사로 볼 수 있음)
5. CLIP의 이론적 기반: Joint Embedding의 보편성 (Universality of Joint Embeddings)
- 임의의 함수 h(X,C)를 근사하는 embedding fθ(X),gϕ(C)를 찾을 수 있는가?
- d→∞일 때 보편 근사 (Universal Approximation) 가능.
5.1 Universality of Joint Embeddings의 정의 및 배경
-
X와 Y는 국소 콤팩트 하우스도르프(LCH, Locally Compact Hausdorff) 공간이다.
- X: 이미지 공간 (보통 Rn으로 표현).
- Y: 문장 공간 (이산 공간 V∗로 표현).
-
F⊂C(X;R), G⊂C(Y;R)는 각각 X와 Y에서 정의된 연속 함수의 벡터 공간에서 조밀한 부분 공간(dense sub-vector space)이다.
5.2 Stone-Weierstrass 정리
Stone-Weierstrass 정리에 따르면, 다음 집합은 C(X×Y;R)에서 균등 수렴 위상(uniform convergence topology) 하에 조밀하다:
{k=1∑dfk(x)gk(y) ∣∣∣∣∣∣ fk∈F,gk∈G,d∈N}⊂C(X×Y;R).
따라서, X×Y에서 정의된 임의의 연속 함수 h(x,y)는 충분히 큰 d에 대해:
h(x,y)≈k=1∑dfk(x)gk(y),
형태로 근사 가능.
5.3 Hilbert 공간에서의 보편성
Hilbert 공간 L2(X;R)와 L2(Y;R)가 분리 가능(separable)할 때:
L2(X;R)⊗L2(Y;R)=L2(X×Y;R),
다음 집합은 조밀하다:
{k=1∑dfk(x)gk(y) ∣∣∣∣∣∣ fk∈L2(X;R),gk∈L2(Y;R),d∈N}⊂L2(X×Y;R).
즉, hθ,ϕ(x,y)=fθ(x)⋅gϕ(y)는 d→∞일 때 보편 근사기로 작동한다.
5.4 Joint Embedding의 보편성
- 주어진 fθ와 gϕ가 보편 근사기(universal approximators)일 때, 다음이 성립한다:
hθ,ϕ(x,y)=fθ(x)⋅gϕ(y)=k=1∑d(fθ(x))k⋅(gϕ(y))k.
- 충분히 큰 d에 대해, hθ,ϕ(x,y)는 임의의 함수 h(x,y)를 근사할 수 있다.
5.5 결론
- X와 Y의 joint embedding을 통해 정의된 fθ(x)⋅gϕ(y)는 보편 근사 성질을 가지며, 이를 통해 임의의 복합적 함수 h(x,y)를 표현할 수 있다.
- d→∞와 fθ(x),gϕ(y)의 깊이(depth)가 충분할 경우 이 보편 근사 성질이 성립한다.
6. 결론
- CLIP과 같은 Vision-Language 모델은 Mutual Information을 근사하도록 학습됨.
- InfoNCE 손실은 Mutual Information의 하한을 제공하며, N→∞일 때 정확한 근사 가능.
- Joint Embedding 구조가 보편 근사 능력을 가지기 때문에 가능한 모델.
필자의 궁금증
f⋅g/τ로 유사도를 정의하고, 그걸로 LNCE를 정의한 뒤 극한을 보내면 MI가 되는가?**
-
InfoNCE 손실 함수:
InfoNCE는 f⋅g/τ를 사용해 데이터 간 유사도를 측정하고, 이를 바탕으로 정답 쌍과 오답 쌍 간의 구별 능력을 학습함.
LNCE=−N1i=1∑Nlog∑j=1Nexp(fθ(Xi)⋅gϕ(Cj)/τ)exp(fθ(Xi)⋅gϕ(Ci)/τ).
-
Mutual Information으로의 수렴:
- 결론:
p(x,y)는 X와 Y 간의 결합 확률을 나타내며, 이를 CLIP에서는 내적 fθ(X)⋅gϕ(C)로 정의한 것임:
- 왜 이러한 모델링이 가능한가? 자세한 증명: #5의 Universality of Joint Embeddings 파트와 관련이 있음.
- 모델링 선택:
- fθ(X)⋅gϕ(C)가 p(X,C)를 근사한다고 가정하지만, 이를 증명하려면:
fθ(X),gϕ(C),p(X,C) 의 함수 공간, 학습 과정, 데이터 분포 등을 포함한 엄밀한 분석이 필요함.
- 이 가정은 경험적 근사에 기반을 둠. + Universality of Joint Embeddings 이론 기반 설명