Tumor Track Project
1.MFC Dialog에 image load
이미지 너비(w), 높이(h), 비트깊이(bpp)를 사용하여 BITMAPINFO 구조체 초기화하고 비트맵 정보를 생성이미지 형태를 BITMAPINFO 형식으로 변환하여 화면에 출력하기 위한 정보 설정을 도움MFC 다이얼로그의 IDC_PC_VIEW에 OpenCV 이미지를
2.OnSize(), OnSizing()

둘 다 C++ MFC에서 창 크기 조정과 관련된 메시지 핸들러그러나 두 함수는 처리하는 메시지와 역할이 다름메시지: WM_SIZE역할: 창의 크기가 조정된 후 발생하는 메시지를 처리사용 목적창 크기가 변경된 후의 작업을 처리컨트롤의 크기나 위치를 재조정하거나, 화면을
3.Dialog 크기 조절

디버깅 시 기존 다이얼로그 크기다이얼로그 크기를 마음대로 조정할 수 있어서 화면이 잘리는 상황이 발생할 수 있음→ 다이얼로그 사이즈를 조정하여도 화면이 다 보였으면 좋겠음사이즈 조절은 가능하되, 비율은 고정시키기너비와 높이를 특정 비율로 유지하도록 처리해야함WM_SIZ
4.Invalid Region(무효화 영역) 복구
다이얼로그 사이즈 변경 전다이얼로그 사이즈 변경 후창의 일부가 변경되었거나 다시 그려야 할 필요가 있는 영역창의 크기를 조정하거나 다른 창이 위로 겹쳤다가 사라질 때 무효화 영역이 생성됨WM_PAINT 메시지를 통해 복구 가능WM_PAINT 메시지 발생 = 무효화 영역
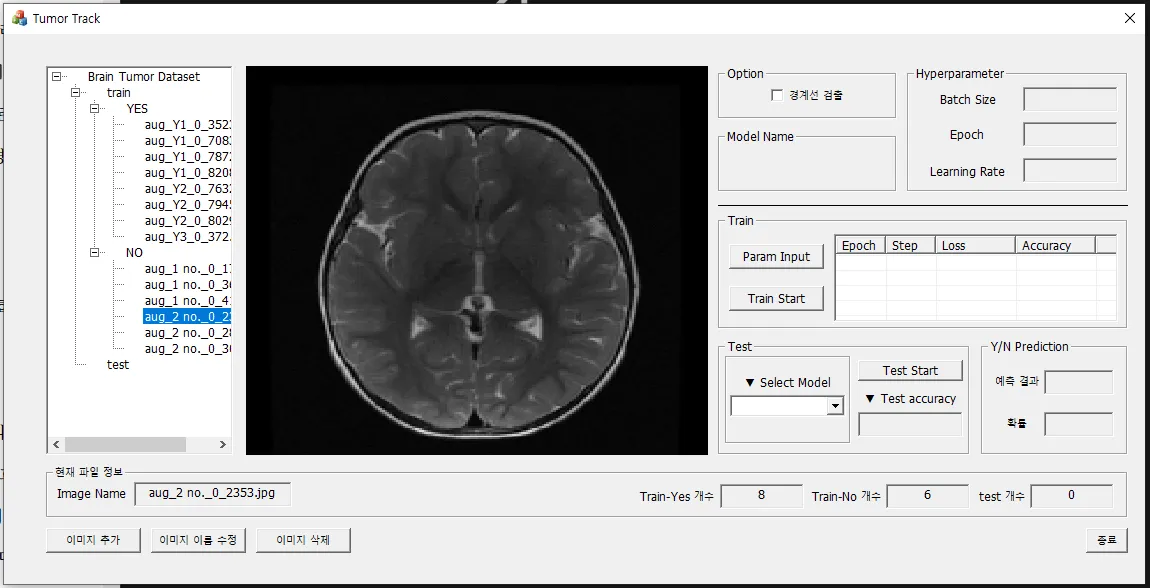
5.내부 컨트롤 크기 조절
다이얼로그 사이즈 변경 시, 내부 컨트롤이 잘림→ 다이얼로그의 크기가 조절될 때, 내부에 위치한 컨트롤의 위치 및 크기도 다이얼로그의 크기에 맞게 함께 조절되도록 수정하고 싶음대화 상자가 resizing 될 때 발생하는 메시지인 WM_SIZE의 핸들러를 추가하여 대화상
6.dialog size 고정
이전에 구현한 코드는 다이얼로그 크기 변경 시 내부 컨트롤의 크기와 위치가 동적으로 조정되도록 구현함. 그러나 일부 컨트롤, 특히 Group Box와 Static Control 같은 특정 컨트롤의 크기와 위치를 제어하는 코드가 예상보다 복잡했음. 이들 컨트롤의 동적 조
7.Canny
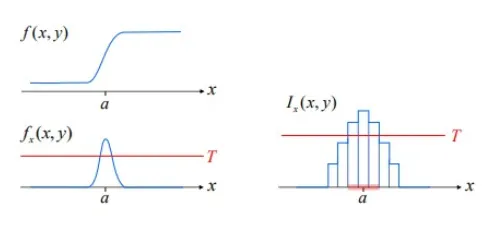
사람: 이미지의 색이나 밝기가 급격하게 변하는 부분컴퓨터: 이미지 픽셀 값의 변화율이 큰 부분픽셀 값의 변화율: 미분으로 구함미분 값(a)이 특정 값(T)보다 크면 엣지로 판단 가능근데 픽셀은 행렬로 저장되어서 미분이 불가능하다.행렬은 이산함수로 취급을 하고 미분은 연
8.Train/Valid/Test dataset
딥러닝 신경망 모델에서 필요한 데이터셋 3가지 Train set Validation set Test set Test set 개념 모델이 학습할 때 사용하는 데이터 모델이 데이터를
9.과적합 방지
복잡한 모델(딥러닝 모델)은 파라미터 수가 많아서 적은 양의 데이터로만 학습하면 훈련 데이터만 과도하게 맞춰지는 경향 … 을 과적합이라고 함그러므로 충분한 양의 데이터를 제공하면 모델이 다양한 패턴을 학습할 가능성이 높아짐 → 과적합(훈련 데이터에만 특화된 학습)이
10.모델 성능 높이기
데이터를 다양하게 변환하여 모델이 더 많은 패턴을 학습할 수 있도록 함이미지 데이터: 회전, 확대/축소, 이동, 플립, 밝기 조정, 노이즈 추가 등텍스트 데이터: 동의어 대체, 문장 순서 변경, 단어 추가/삭제 등데이터의 범위를 동일하게 만들기이미지 데이터: 픽셀 값을
11.gnuplot 환경 설정
gnuplot 페이지에서 다운로드 후, 추가적으로 해줘야하는 것기본적으로 gnuplot은 cmd창에서 실행 가능C:\\Users\\user>gnuplot → 이렇게 gnuplot을 입력해주면 해당 화면이 떠야함 gnuplot을 입력했을 때,'gnuplot'은(는)
12.CNN
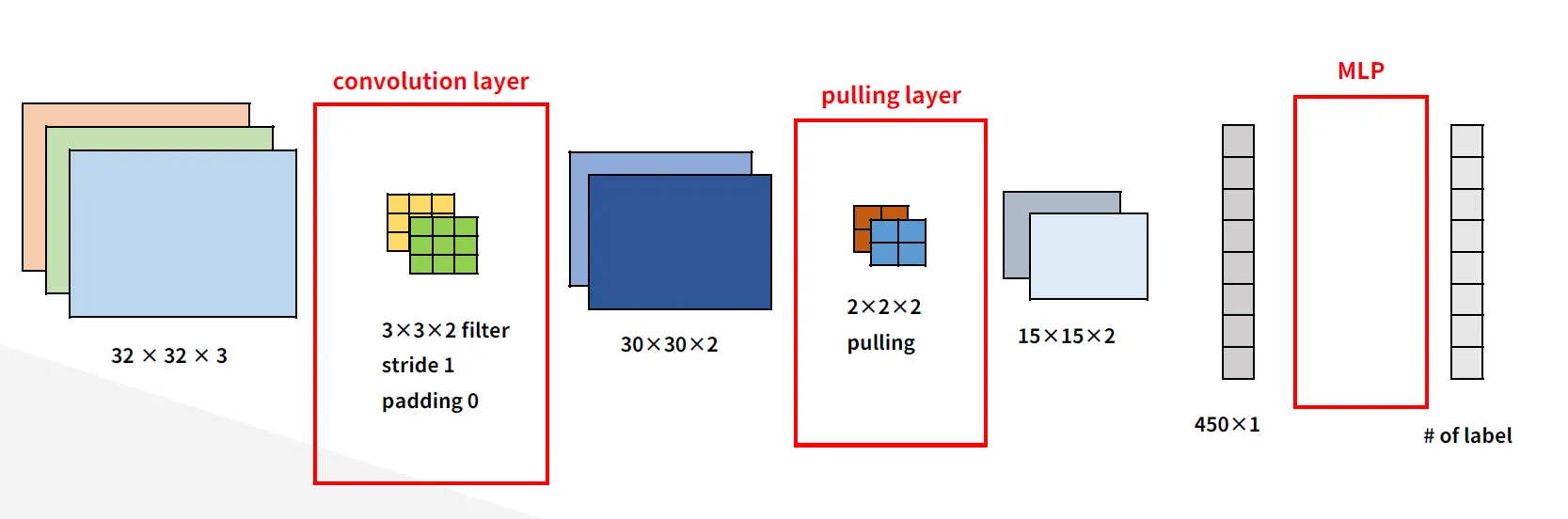
주로 이미지 처리와 컴퓨터 비전에 특화된 딥러닝 모델공간적 구조를 고려하여 연산 → 이미지, 시각적 데이터에서 유의미한 패턴 추출 가능필터 크기: 3x3, 5x5필터 수: 각 합성곱 레이어에서 학습할 특징의 수를 결정스트라이드 (stride): 필터가 슬라이딩할 간격
13.CNN Layer 별 출력 크기 계산하기
Flatten과 FC Layer의 크기 결정FC Layer는 Flatten 된 벡터를 입력으로 받는다.CNN의 마지막 피처맵 크기가 정확히 계산되지 않으면 FC 레이어의 입력 크기가 맞지 않아 에러가 발생한다.메모리 사용량 관리각 레이어 출력 크기는 모델이 사용하는 메
14.CNN Model 구현
CNN CNN Layer 별 출력 크기 계산하기conv Layer: CNN 특징 추출 부분. 4개의 합성곱 층과 풀링 층으로 구성각 층의 구성Conv2d: 입력 데이터를 필터로 합성곱해 특징을 추출BatchNorm2d: 학습 안정화를 위해 배치 정규화를 수행ReLU:
15.C++과 gnuplot 연동하기
train을 할 때마다 terminal 창을 켜서 그래프를 그릴 수는 없기에 .. 연동을 해야했음해당 블로그에서 그누플랏 명령어를 수정없이 그대로 사용할 수 있게 소스코드를 올려주셔서 .. 조금만 수정하고 사용했어요. ^ . ^블로그에 올려주신 압축파일을 다운받고 압축
16.Train acc, loss history graph print - in terminal env.
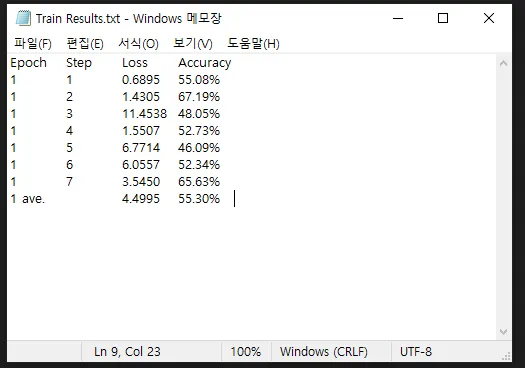
step마다 변화하는 Loss, Accuracy 값을 그래프로 그려서 png 파일로 저장하기loss,acc 따로 생성하기
17.acc, loss 동시에 출력하기
출력 설정터미널 형식 설정출력 파일 경로 설정multiplot 설정하나의 파일 안에서 여러 그래프로 나눠서 출력하기 위함개별 그래프 그리기plot 명령을 사용하여 각 그래프를 데이터와 함께 작성multiplot 종료출력 닫기출력 설정multiplot 설정개별 그래프 그
18.Maximum Likelihood Estimator (MLE)
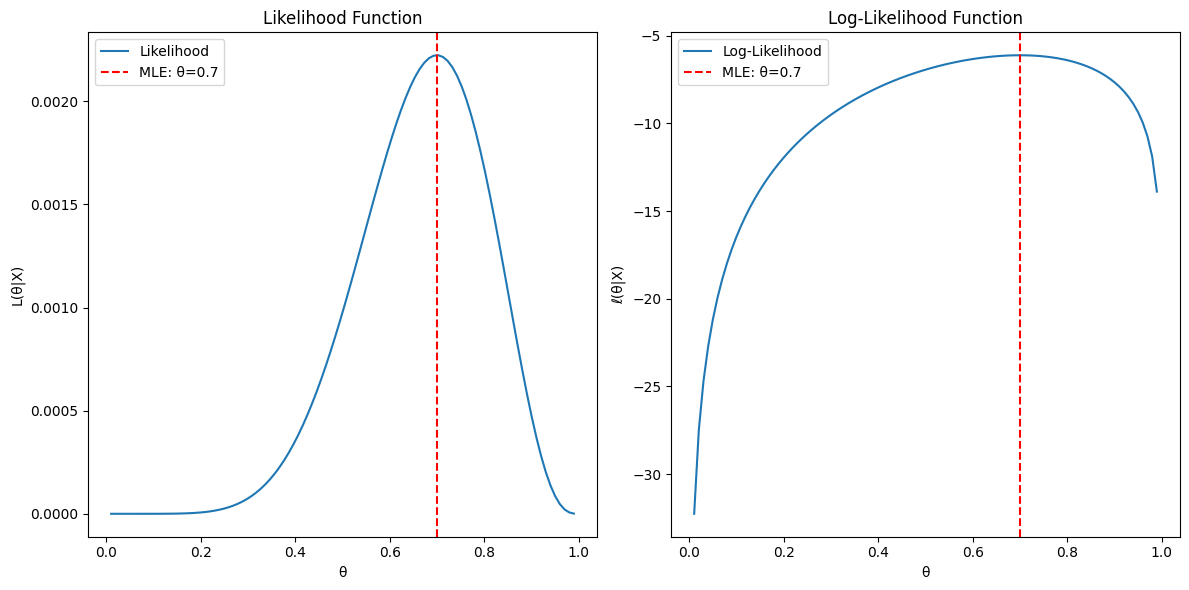
MLE는 무엇이고, 왜 중요한가? 데이터를 가장 잘 설명하는 확률 분포의 파라미터 값을 찾는 것이 목적이다. ⇨ 중요한 이유 실생활 문제 해결에 유용하다. 현실세계에서의 문제는 정확한 규칙을 알 수 없기 때문에 관찰된 데이터를 통해 가장 가능성이 높은 가설을 만들
19.Loss Function
머신러닝 및 딥러닝 모델의 성능을 평가하는 데 사용되는 함수모델의 예측값(^y)과 실제값(y) 간의 차이를 수치적으로 나타냄 (우리가 직관적으로 알 수 있다)모델의 학습 목표: 손실 함수를 최소화하는 가중치와 편향(파라미터)를 찾는 것손실 함수가 작을수록 모델의 예측이
20.Dataset, Dataloader 개념
효율적이고 유연한 데이터 관리를 위해서데이터와 모델 간 인터페이스 제공딥러닝 모델은 배치 단위로 데이터를 받아야 함데이터셋 클래스는 데이터를 효율적으로 전처리하고 모델이 학습할 수 있도록 배치 단위로 데이터를 반환해줌Pytorch의 DataLoader와 통합하여 학습
21.Dataset 구현
Pytorch C++ API (libtorch)로 작성한 데이터셋 클래스: Datasetyes와 no라는 두 개의 클래스로 구성된 이미지 데이터를 로드이를 파이토치의 데이터셋 형식으로 변환해주는 역할주요 구성 요소생성자데이터 가져오기데이터셋 크기 반환이미지 정규화주어진
22.Data Augmenation
last update 24.12.05기존의 데이터를 변형하거나 가공하여 새로운 데이터를 생성하는 기술딥러닝/머신러닝에서의 데이터 부족 문제 완화모델의 일반화 성능 향상컴퓨터 비전, 자연어 처리, 시계열 데이터 등 다양한 도메인에서 사용 가능데이터 부족 문제 해결딥러닝
23.Data Augmentation 구현
last update 24.12.06colab 환경에서 진행함 https://drive.google.com/file/d/1KQk5kqjK0LnkZhwabkhYQUHTXOTynz2x/view?usp=sharing Keras 사용뇌종양 데이터셋의 이미지 데이터
24.GetSelectedItem()과 pNMTreeView의 차이점
last update 24.12.09트리 컨트롤에서 현재 선택된 노드를 가져옴특징현재 선택된 노드의 핸들을 가져오고 싶을 때 사용트리 노드 선택 변경과 관련된 이벤트와는 독립적TVN_SELCHANGED와 같은 이벤트와는 상과없이, 현재 트리 컨트롤에서 사용자가 선택한
25.학습 시간 출력
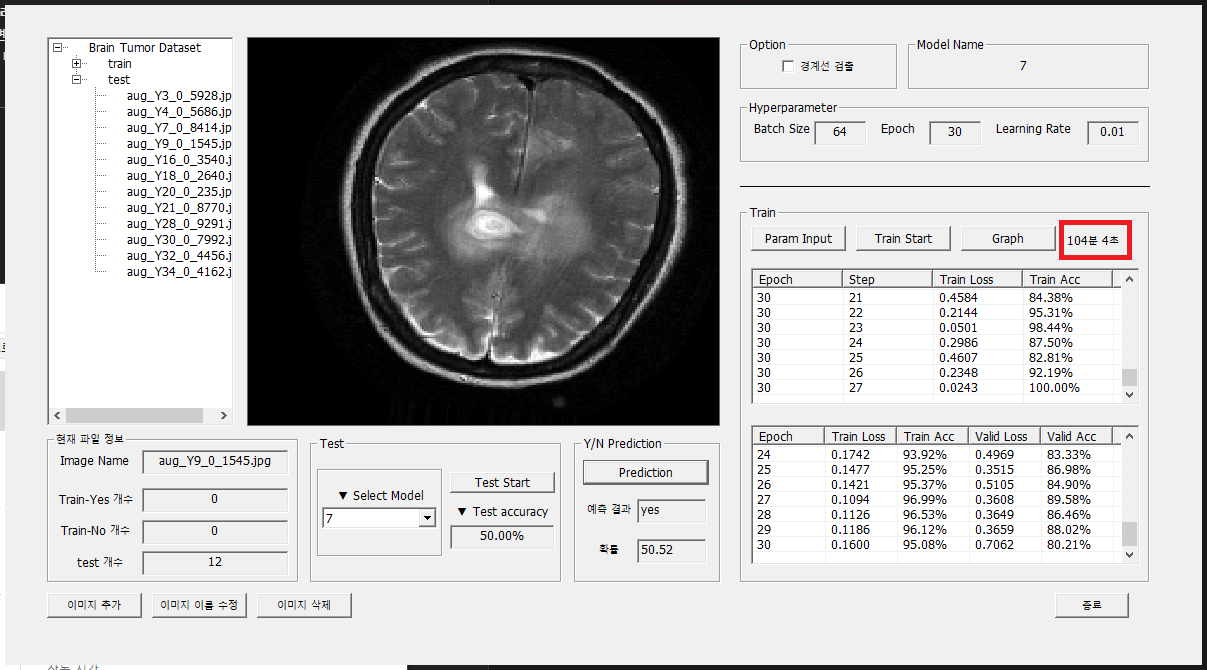
last update 24.12.09시작 시간과 종료 시간 기록 후 → 두 시간 차이 계산하기 라이브러리 사용high_resolution_clock 대신에 steady_clock 또는 system_clock 클래스를 사용해도됨image.png참고자료https: