1. List Comprehension
List comprehension은 리스트를 간결하게 생성해내는 문법이다.
예를 들어 아래와 같이 짝수로 이루어진 리스트를 필요로 한다고 가정을 한다면,
[2, 4, 6, 8, 10, ..., 20]
list comprehension 대신에 반복문을 사용하면 아래와 같다.
test = [] # test라는 빈 리스트 생성
for i in range(1, 11):
i = i * 2
print(i)
test.append(i) # append를 추가하여 i 요소 추가아래와 같이 결과값이 짝수로 나열되어 있는걸 확인할 수 있다.
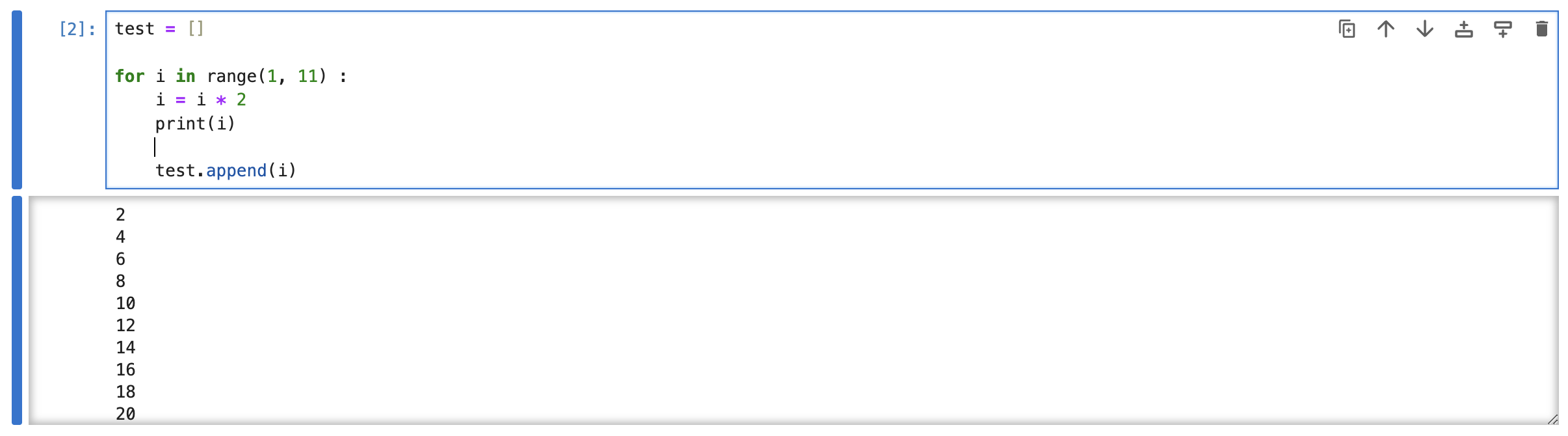
테스트를 확인해보면, 10개의 숫자가 잘 들어간걸 확인할 수 있다.
test
# 결과: [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]단순히 10개의 숫자를 얻기 위해서 위에서 test라는 빈 리스트를 생성하는 것부터 반복문을 돌려서 test 요소를 하나하나 추가하는 것까지 4줄이 되는 코드를 작성했다.
이러한 과정을 획기적으로 줄여줄 수 있는 것이 list comprehension이다.
위와 같은 반복문을 list comprehension 문법을 써서 아래와 같이 단 한줄로 코드 작성을 끝낼 수 있다.
[i * 2 for i in range(1, 11)]
# 결과: [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]예시:
[i * i for i in range(1, 11)] # 제곱근 구하기
# 결과: [1, 4, 9, 16, 25, 36, 49, 64, 81, 100][i * 2 -1 for i in range(1, 11)] # 홀수 구하기
# 결과: [1, 3, 5, 7, 9, 11, 13, 15, 17, 19][i % 2 for i in range(1, 11)] # 2로 나눈 나머지 값 구하기
# 결과: [1, 0, 1, 0, 1, 0, 1, 0, 1, 0]set([i % 2 for i in range(1, 11)]) # unique한 값 구하기
# 결과: {0, 1}위의 list comprehension에 set()을 씌워주게 되면 set()은 중복을 제거해주는 집합이기 때문에 중복값을 제거한 unique 값만 보여준는 것을 확인할 수 있다.
2. List Comprehension의 if문
[i for i in range(0, 20)]
# 결과: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]0부터 19까지의 정수 중에서 홀수만 있는 리스트를 만들어야 한다면 다음과 같은 반복문 코드를 작성할 수 있다.
test = []
for i in range(0,20):
if i % 2 == 1:
test.append(i)
test
# 결과: [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]위의 반복문을 list comprehension으로 표현한다면 다음과 같이 코드를 작성할 수 있다.
[i for i in range(0,20) if i % 2 == 1]
# 결과: [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]위의 코드를 실행하면 반복문의 결과값과 동일하다는걸 확인할 수 있다.
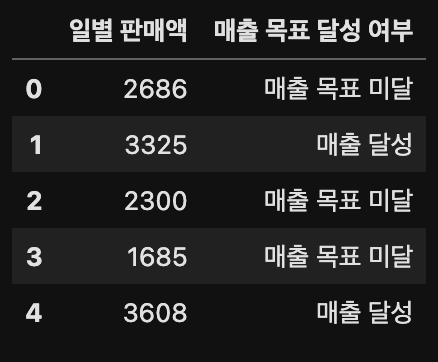
예시 1: 30일간 매출
import random # python에 내장되어 있는 모듈로 random 숫자 생성
sales = [random.randint(1500, 4500) for i in range(0, 30)] # 30번만큼 1500부터 4500사이에서 무작위로 번호 뽑기
print(sales)
# [2686, 3325, 2300, 1685, 3608, 2921, 2505, 3077, 3733, 2987, 3165, 2042, 2547, 3418, 3199, 4037, 1537, 1943, 3057, 4403, 2544, 3923, 4243, 4370, 2777, 2773, 4402, 2602, 2568, 1850]예시 2: 30일간 평균 매출에서 매출의 평균을 넘어서는 값만 리스트에 남기기
avg = sum(sales) / len(sales)
print(avg)
# 3007.5666666666666List comprehension을 사용하여 위에서 구한 매출으이 평균을 넘어서는 값들만 리스트로 남기겠다.
[i for i in sales if i > avg]
# 결과값:
# [3325,
# 3608,
# 3077,
# 3733,
# 3165,
# 3418,
# 3199,
# 4037,
# 3057,
# 4403,
# 3923,
# 4243,
# 4370,
# 4402]예시 3: if~else문
['매출 달성' if i > avg else '매출 목표 미달' for i in sales]
# 결과값:
# ['매출 목표 미달',
# '매출 달성',
# '매출 목표 미달',
# '매출 목표 미달',
# '매출 달성',
# '매출 목표 미달',
# ...,
# '매출 달성',
# '매출 목표 미달',
# '매출 목표 미달',
# '매출 달성',
# '매출 목표 미달',
# '매출 목표 미달',
# '매출 목표 미달']위의 if~else문을 통해 어떠한 값이 매출을 달성했는지 또는 매출 목표 미달인지에 대해서 확인할 수 있다.
위의 데이터를 데이터프레임에 붙여 넣어보겠다.
import pandas as pd
df = pd.DataFrame()
df["일반 판매액"] = sales
df["매출 목표 달성 여부"] = ['매출 달성' if i > avg else '매출 목표 미달' for i in sales]
df.head()