1. 데이터 열기
import pandas as pd
route1 = '/Users/Downloads/market.csv'
df = pd.read_csv(route1)UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbb in position 0: invalid start byte
위와 같은 에러가 발생하였다.
위의 오류는 주로 파일의 인코딩이 'UTF-8'이 아니라서 발생하는데, 이 경우 utf-8 대신에 다른 인코딩 방식을 사용하여 파일을 읽어야 한다. 예를 들어, 한글 Windows 환경에서 생성된 CSV 파일의 경우 cp949 인코딩을 사용할 수 있다.
반면에, UnicodeDecodeError: 'cp949' codec can't decode byte 0xed in position 23: illegal multibyte sequence 오류는 CP949 인코딩으로 디코딩할 때 문제가 발생하는 경우이다. 이 경우에는 UTF-8 인코딩을 시도해보는 것이 좋다.
따라서, 인코딩 관련 오류가 발생할 때는 해당 오류 메시지를 살펴보고, 파일이 생성된 환경 및 인코딩 방식에 맞는 인코딩 옵션을 지정하여 파일을 읽어야 한다.
예를 들어:
# UTF-8 인코딩을 사용하여 파일 읽기
df = pd.read_csv(route1, encoding='utf-8')
# 또는
# UTF-8 BOM 인코딩을 사용하여 파일 읽기
df = pd.read_csv(route1, encoding='utf-8-sig')df = pd.read_csv(route1, encoding='cp949')
df.head()다음과 같이 데이터가 정확하게 읽힌것을 확인할 수 있다.
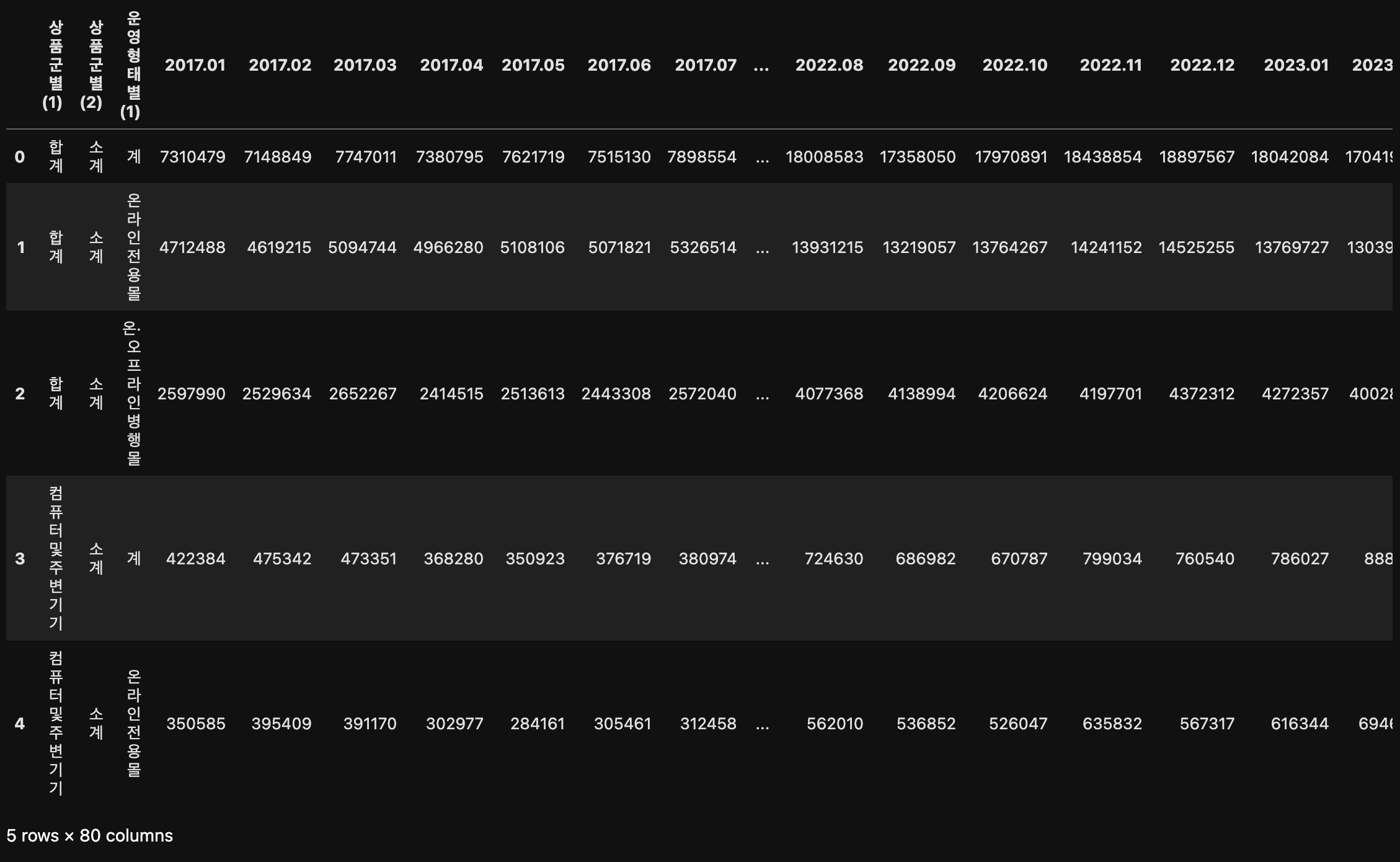
2. 데이터 탐색
df.info()
# 결과값:
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 78 entries, 0 to 77
# Data columns (total 80 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 상품군별(1) 78 non-null object
# 1 상품군별(2) 78 non-null object
# 2 운영형태별(1) 78 non-null object
# 3 2017.01 78 non-null object
# 4 2017.02 78 non-null object
# 5 2017.03 78 non-null object
# 6 2017.04 78 non-null object
# ...
# dtypes: int64(41), object(39)
# memory usage: 48.9+ KB위의 데이터프레임(df)의 정보를 확인할 결과, 2017년 1월 부터 2019년 12월까지의 날짜별로 기록된 거래액 데이터가 문자열(object) 형식이다.
따라서 해당 데이터를 정수형으로 변환하는 작업이 필요하다.
df.columns
# Index(['상품군별(1)', '상품군별(2)', '운영형태별(1)', '2017.01', '2017.02', '2017.03',
# '2017.04', '2017.05', '2017.06', '2017.07', '2017.08', '2017.09',
# '2017.10', '2017.11', '2017.12', '2018.01', '2018.02', '2018.03',
# '2018.04', '2018.05', '2018.06', '2018.07', '2018.08', '2018.09',
# '2018.10', '2018.11', '2018.12', '2019.01', '2019.02', '2019.03',
# '2019.04', '2019.05', '2019.06', '2019.07', '2019.08', '2019.09',
# '2019.10', '2019.11', '2019.12', '2020.01', '2020.02', '2020.03',
# '2020.04', '2020.05', '2020.06', '2020.07', '2020.08', '2020.09',
# '2020.10', '2020.11', '2020.12', '2021.01', '2021.02', '2021.03',
# '2021.04', '2021.05', '2021.06', '2021.07', '2021.08', '2021.09',
# '2021.10', '2021.11', '2021.12', '2022.01', '2022.02', '2022.03',
# '2022.04', '2022.05', '2022.06', '2022.07', '2022.08', '2022.09',
# '2022.10', '2022.11', '2022.12', '2023.01', '2023.02', '2023.03',
# '2023.04 p)', '2023.05 p)'],
# dtype='object')# 상품군 카테고리
df.columns[0]
# 결과: '상품군별(1)'df.columns[0]은 첫 번째 열의 이름을 가져온다. 따라서 해당 컬럼명을 df로 한번 더 감싸주면 '상품군별(1)' 열에 해당하는 모든 데이터를 가져올 수 있다.
# 상품군별(1)
df[df.columns[0]]
# 결과값:
# 0 합계
# 1 합계
# 2 합계
# 3 컴퓨터 및 주변기기
# 4 컴퓨터 및 주변기기
# ...
# 73 기타서비스
# 74 기타서비스
# 75 기타
# 76 기타
# 77 기타
# Name: 상품군별(1), Length: 78, dtype: object'상품군별(1)' 열에 있는 중복되지 않는 값들을 확인하려면 아래과 같이 코드를 작성할 수 있다.
# 상품군별(1)
df[df.columns[0]].unique()
# 결과값:
# array(['합계', '컴퓨터 및 주변기기', '가전·전자·통신기기', '서적', '사무·문구', '의복', '신발', '가방',
# '패션용품 및 액세서리', '스포츠·레저용품', '화장품', '아동·유아용품', '음·식료품', '농축수산물',
# '생활용품', '자동차 및 자동차용품', '가구', '애완용품', '여행 및 교통서비스', '문화 및 레저서비스',
# '이쿠폰서비스', '음식서비스', '기타서비스', '기타'], dtype=object)# 운영형태별
df[df.columns[2]].unique()
# 결과: array(['계', '온라인 전용몰', '온·오프라인 병행몰'], dtype=object)# 상품군별 음식서비스
df[df["상품군별(1)"] == "음식서비스"]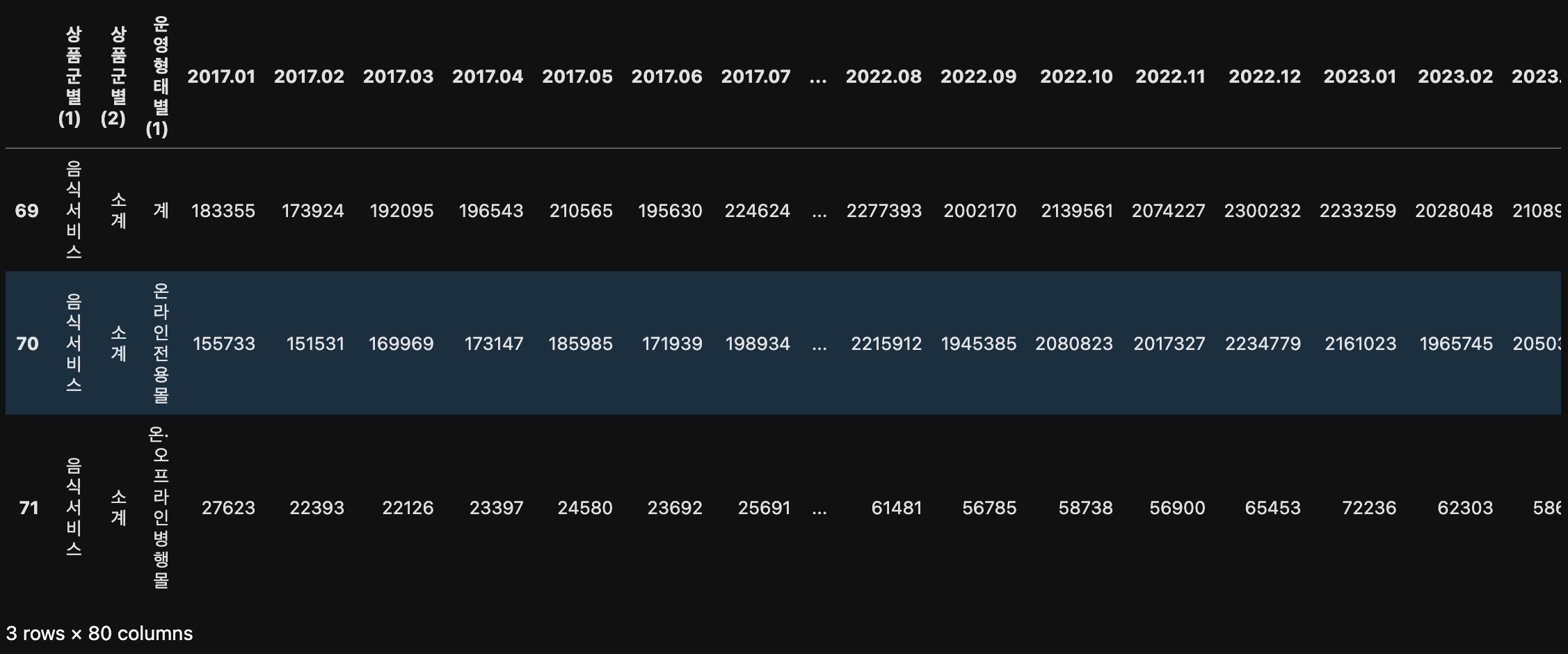
# 운영형태별(1) 온라인 전용몰
df[df["운영형태별(1)"] == "온라인 전용몰"]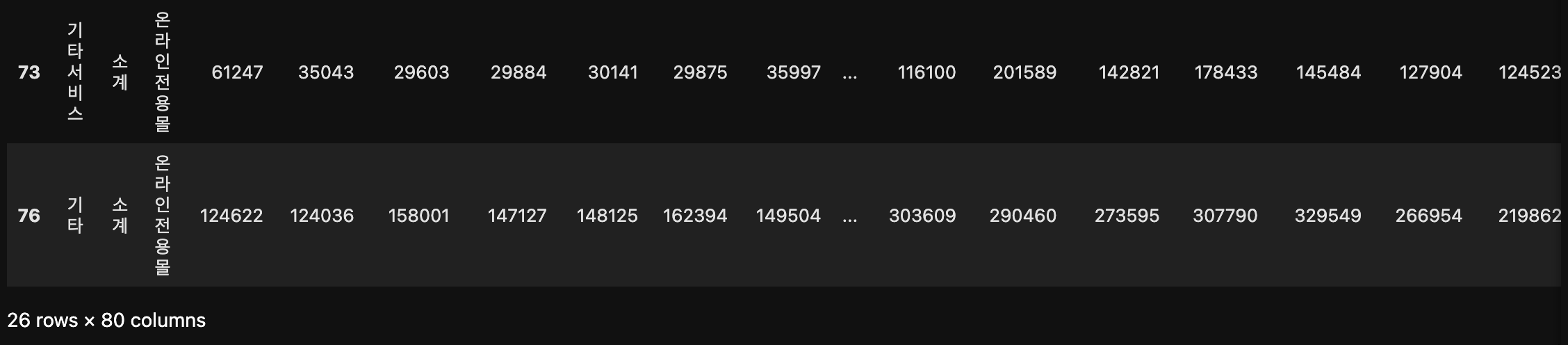
2.1 데이터 재구조화 - pd.melt()
df.melt()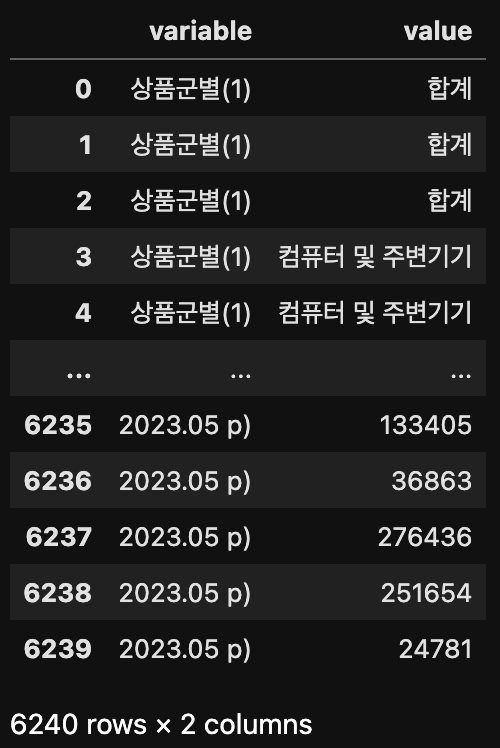
melt() 함수를 사용하면 데이터프레임(df)을 넓은 형식(wide format)에서 긴 형식(long format)으로 변환할 수 있다. 모든 데이터 값들이 새로운 열로 긴 형태로 재구조화된다.
len(df)
# 결과: 78데이터프레임(df)의 데이터 행이 총 78개 였지만, melt() 함수를 통해 데이터프레임을 재구성하여 행의 수가 6,240으로 증가하였다.
melt() 함수를 사용할 때, 특정 열을 기준으로 나머지 데이터를 길게 펼치는데, 이 때 기준이 되는 열을 설정할 수 있다.
예를 들어, 아래와 같이 df.melt('상품군별(1)')은 '상품군별(1)' 열을 기준으로 나머지 데이터를 새로운 열로 길게 펼치게 된다. 이렇게 되면 기준 열의 값들이 새로운 열로 이동하고, 이에 따라 행의 수가 증가하게 된다.
df.melt("상품군별(1)")df.columns[:3]
# 결과: Index(['상품군별(1)', '상품군별(2)', '운영형태별(1)'], dtype='object')df.melt(id_vars=df.columns[:3])
# 또는
df.melt(id_vars=['상품군별(1)', '상품군별(2)', '운영형태별(1)'])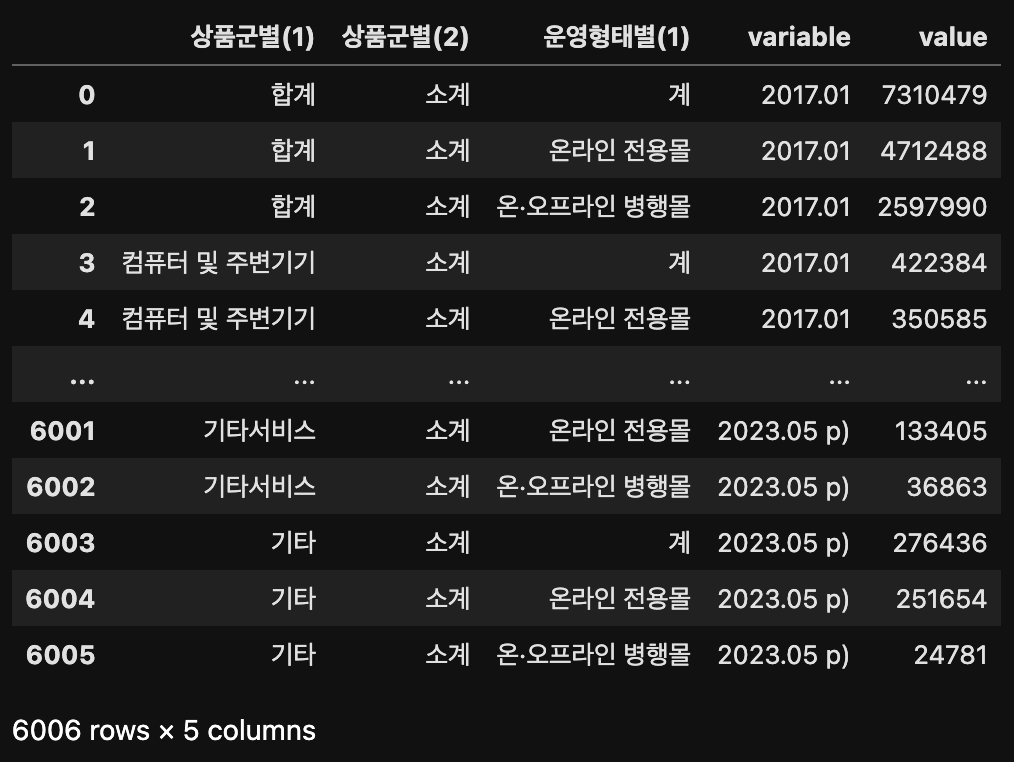
'상품군별(1)', '상품군별(2)', '운영형태별(1)' 열은 살아남고, 나머지 열들 중 '날짜' 열은 variable로 지정이되고, '거래액'이 value로 지정된 것을 확인할 수 있다.
위의 이미지와 동일한 결과값이지만 아래와 같이 melt() 함수의 매개변수를 지정한면 var_name 매개변수를 '날짜'로, value_name 매개변수를 '거래액'으로 지정된 것을 확인할 수 있다.
df.melt(id_vars=['상품군별(1)', '상품군별(2)', '운영형태별(1)'],
var_name='날짜',
value_name='거래액')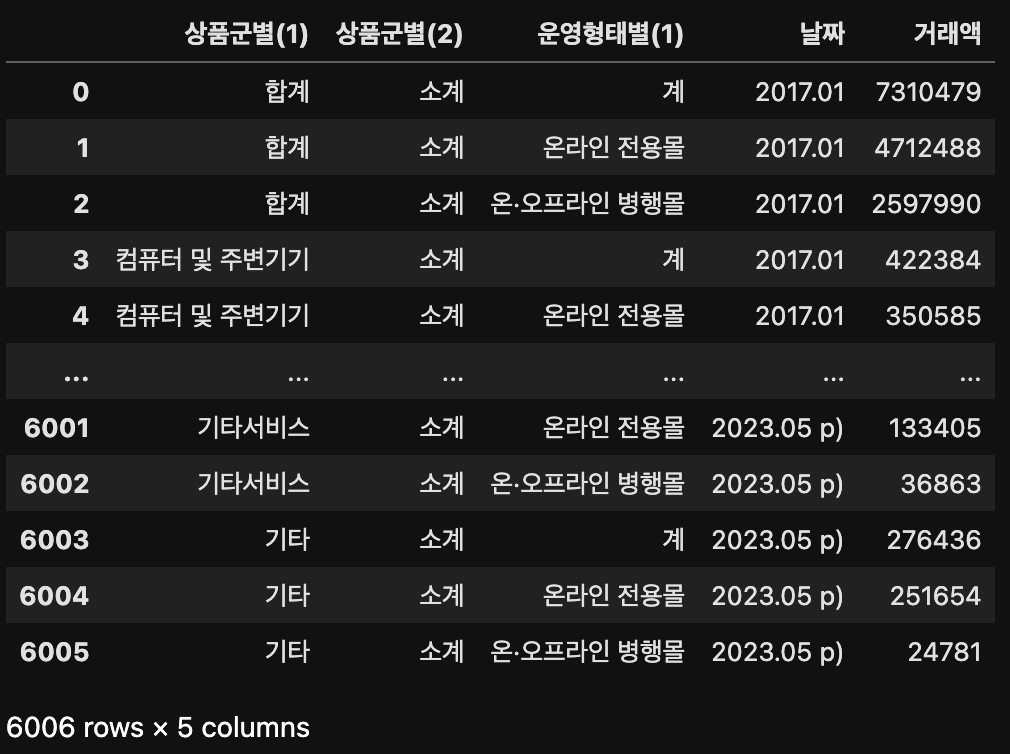
result = df.melt(id_vars=['상품군별(1)', '상품군별(2)', '운영형태별(1)'],
var_name='날짜',
value_name='거래액')
result.head()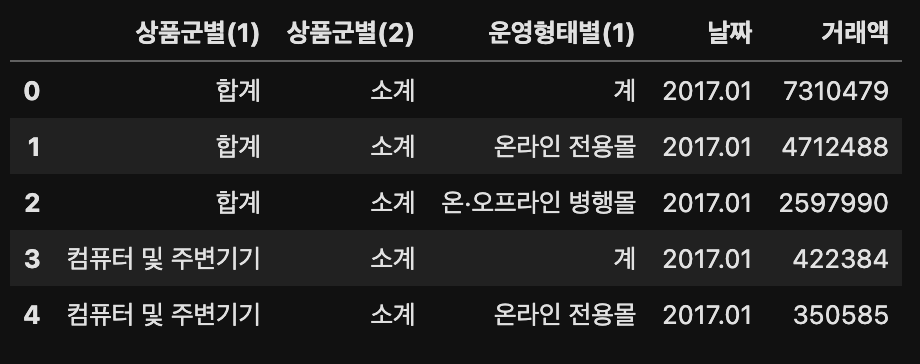
2.2 데이터 재구조화 - pd.pivot_table()
# pivot 변수에 result 데이터 복사하기
pivot = result.copy()
pivot.head()pivot.pivot_table(index=['상품군별(1)', '상품군별(2)', '운영형태별(1)'])
# DataError: No numeric types to aggregateNo numeric types to aggregate와 같은 에러가 발생하였다. 거래액이 숫자인데 왜 집계를 못할까? 이유를 찾아봐야겠다. 우선 pivot의 데이터타입을 알아보자.
pivot.info()
# 결과값:
# <class 'pandas.core.frame.DataFrame'>
# RangeIndex: 6006 entries, 0 to 6005
# Data columns (total 5 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 상품군별(1) 6006 non-null object
# 1 상품군별(2) 6006 non-null object
# 2 운영형태별(1) 6006 non-null object
# 3 날짜 6006 non-null object
# 4 거래액 6006 non-null object
# dtypes: object(5)
# memory usage: 234.7+ KB보시다시피 pivot 테이블의 '거래액' 열은 숫자형이 아닌 문자형이다. 왜 이러한 현상이 발생하는지 자세히 알아보자.
# list comprehension
[type(i) for i in pivot["거래액"]]
# 결과값:
# [str,
# str,
# str,
# str,
# ...,
# str]set([type(i) for i in pivot["거래액"]])
# 결과: {int, str}위의 pivot 테이블에서 '거래액'을 확인할 때는 숫자형으로 보이지만 위의 결과를 확인하니 '거래액'의 데이터타입이 숫자형과 문자형으로 뒤섞여있는 것을 확인할 수 있다.
[i for i in pivot["거래액"]]
# 결과값:
# ['7310479',
# '4712488',
# ...,
# '-',
# '-',
# '-']# pivot 테이블의 '거래액'의 데이터타입이 정수가 아닌 경우
[i for i in pivot["거래액"] if type(i) != int]
# 결과값:
# ['7310479',
# '4712488',
# ...,
# '-',
# '-',
# '-']각 숫자 값 주위에 따옴표가 붙어 있고, 대쉬(-) 값도 포함되어 있는 것으로 보아, 해당 열의 데이터는 문자열(object)로 인식되고 있다.
숫자 값 및 대시(-) 값이 따옴표로 둘러싸여 있으면 파이썬은 이를 문자열로 취급한다.
왜 이러한 결과값이 나왔는지 데이터프레임(df)의 테이블로 돌아가보자.
df[df["2017.01"] == '-']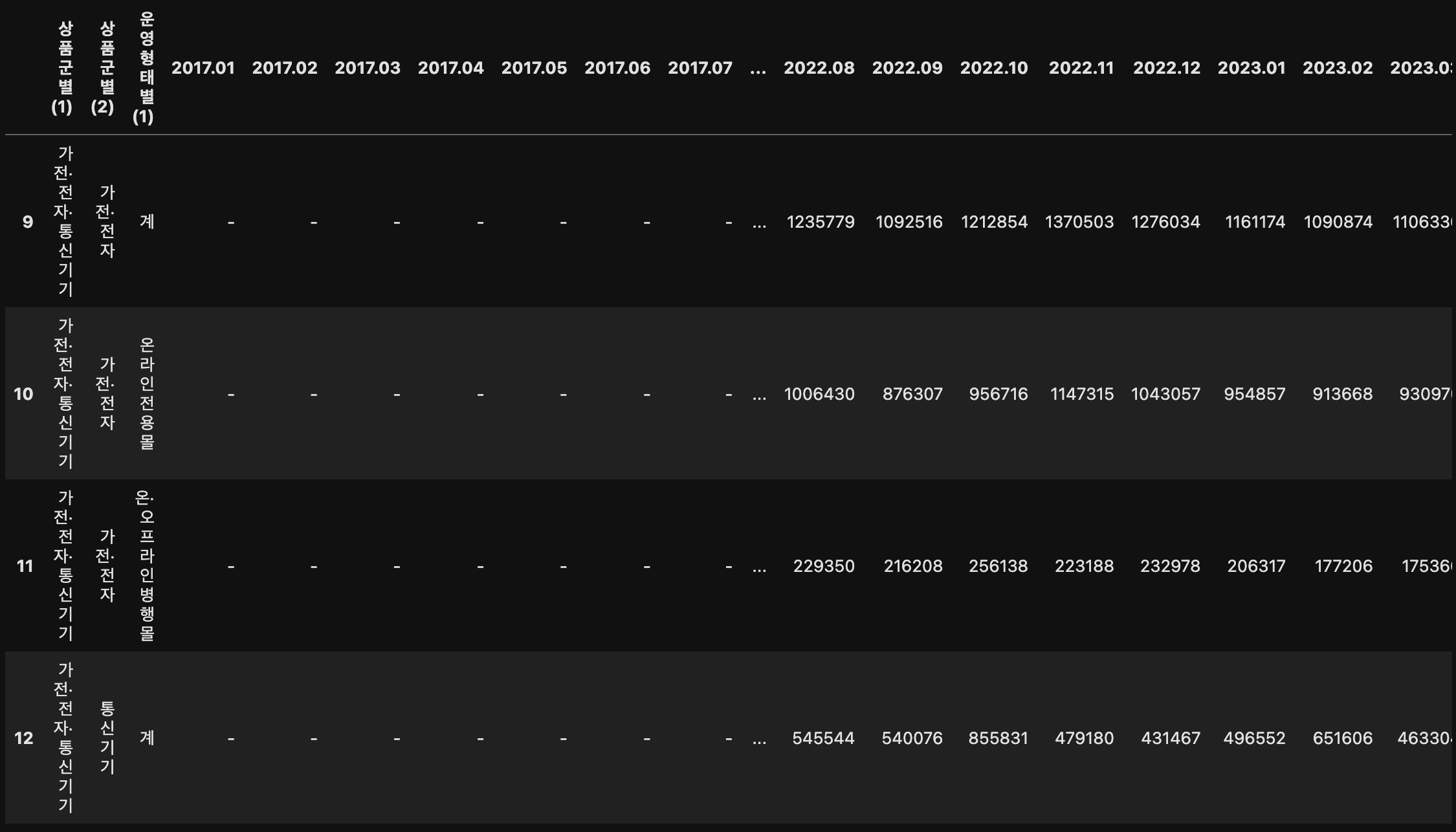
따라서 위와 같이 pivot 테이블은 집계할 숫자형 데이터와 문자형 데이터가 뒤섞여 집계 작업이 제대로 수행되지 않아 DataError: No numeric types to aggregate 에러가 뜬 것이다.
