1. Python with MySQL
Python으로 MySQL 접속 후 사용하는 방법이다.
1.1 MySQL Driver 설치 및 확인
1) MySQL Driver 설치
Python에서 MySQL을 사용하기 위해서는 먼저 MySQL Driver를 설치
ds_study 활성화한 후, MySQL Driver 설치
pip install mysql-connector-python

2) MySQL Driver 설치 확인
MySQL Driver 설치 확인
import mysql.connector
1.2 Connection 생성
MySQL 연결 생성
mydb = mysql.connector.connect( host = "<hostname>", user = "<username>", password = "<password>" )
1) Local database 연결
import mysql.connector
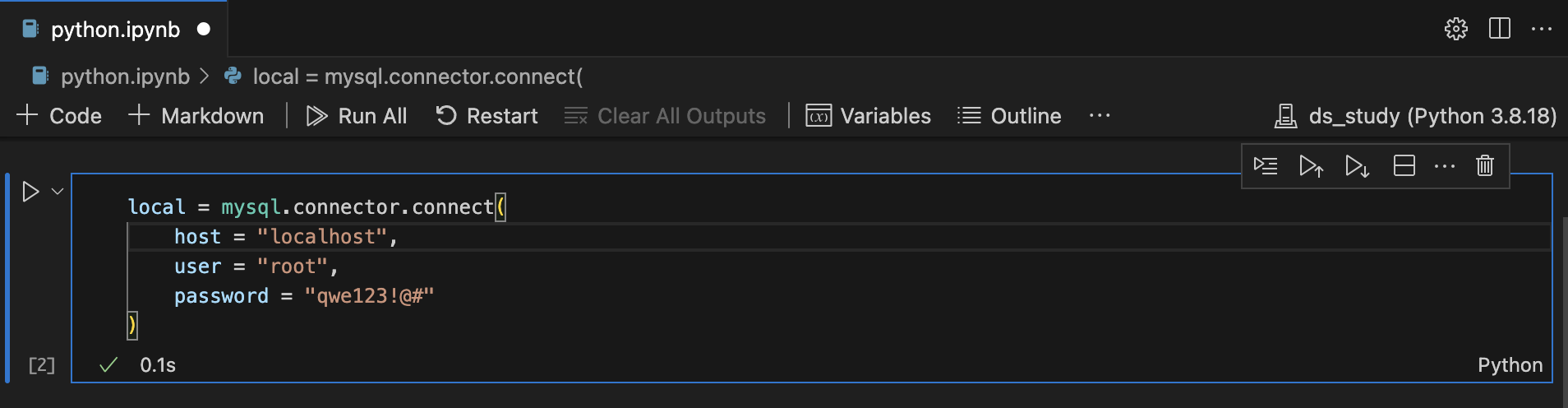
local = mysql.connector.connect(
host = "localhost",
user = "root",
password = "qwe123!@#"
)
2) AWS RDS (database-1) 연결
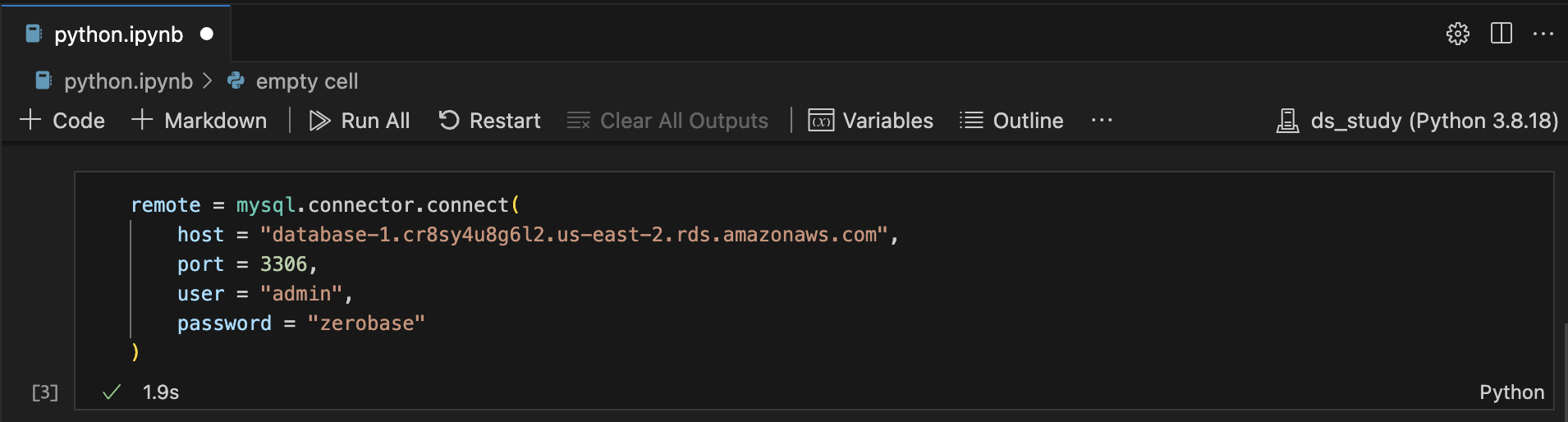
remote = mysql.connector.connect(
host = "database-1.cr8sy4u8g6l2.us-east-2.rds.amazonaws.com",
port = 3306,
user = "admin",
password = "zerobase"
)
1.3 Connection 종료(close)
MySQL 접속 종료
# import mysql.connector # local = mysql.connector.connect( # host = "<hostname>", # user = "<username>", # password = "<password>", # database = "<databasename>" # ) local.close() # local database 연결 종료 remote.close() # remote database 연결 종료
1) Local database 연결 종료
local.close()
2) 원격 database 연결 종료
remote.close()
1.4 특정 database 연결
특정 Database 연결
import mysql.connector mydb = mysql.connector.connect( host = "<hostname>", port = "<port>", user = "<username>", password = "<password>", database = "<databasename>" )
1) Local MySQL의 database(zerobase) 연결
local = mysql.connector.connect(
host = "localhost",
user = "root",
password = "qwe123!@#",
database = "zerobase"
)
local.close()
# 바로 Local MySQL 연결을 종료하는 이유는 종료하지 않으면 연결이 많아지기 때문
2) AWS RDS (database-1)의 database(zerobase) 연결
remote = mysql.connector.connect(
host = "database-1.cr8sy4u8g6l2.us-east-2.rds.amazonaws.com",
port = "3306",
user = "admin",
password = "zerobase",
database = "zerobase"
)
remote.close()
1.5 SQL Query 실행(execute)
SQL query 실행
import mysql.connector mydb = mysql.connector.connect( host = "<hostname>", user = "<username>", password = "<password>", database = "<databasename>" ) mycursor = mydb.cursor() # MySQL 데이터베이스와 상호 작용하기 위한 커서 객체 생성 mycursor.execute(<query>) # 지정된 SQL 쿼리 실행
1) AWS RDS (database-1)에 sql_file 테이블 생성
remote = mysql.connector.connect(
host = "database-1.cr8sy4u8g6l2.us-east-2.rds.amazonaws.com",
port = "3306",
user = "admin",
password = "zerobase",
database = "zerobase"
)
cur = remote.cursor()
cur.execute("create table sql_file (id int, filename varchar(16))")
remote.close()
2) Terminal에 AWS RDS 접속 후 sql_file 테이블 생성 결과 확인
mysql -h database-1.cr8sy4u8g6l2.us-east-2.rds.amazonaws.com -P 3306 -u admin -p
use zerobase;
show tables;
desc sql_file;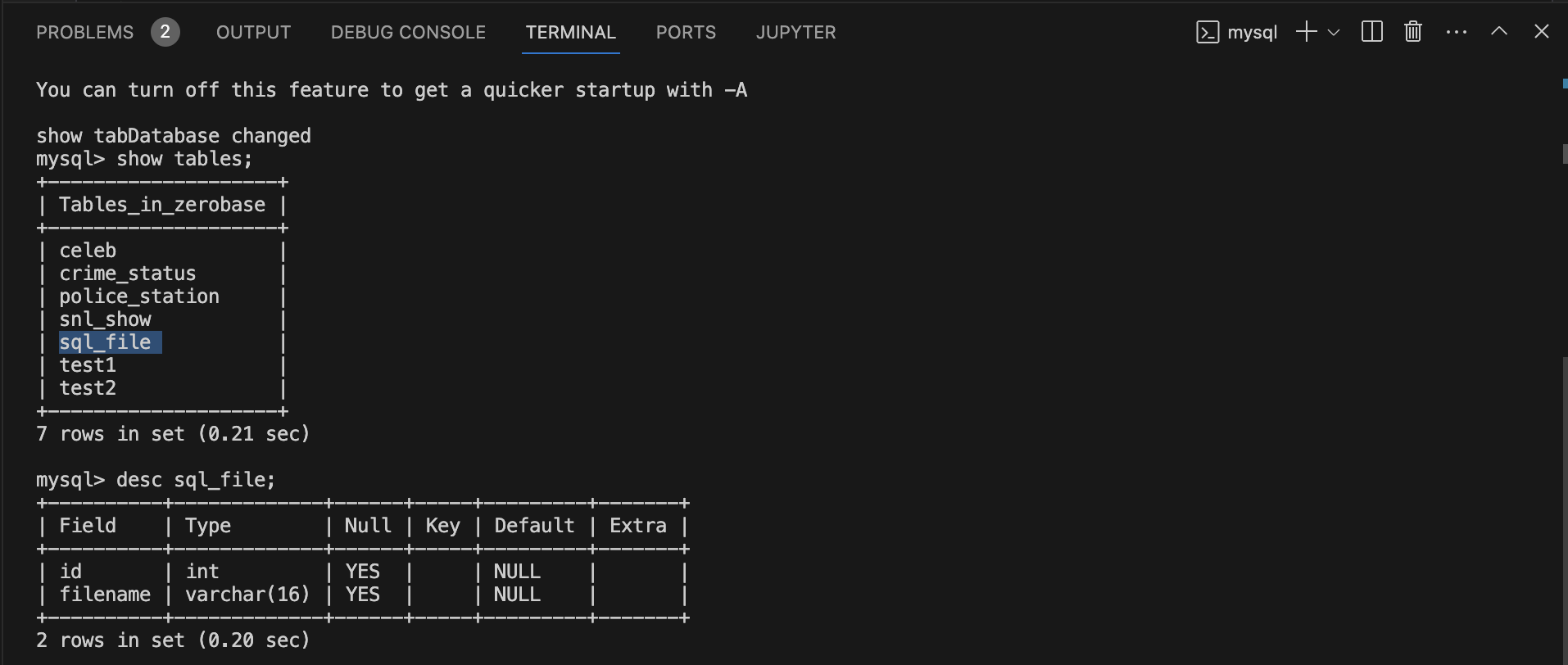
3) 생성한 sql_file 테이블 삭제
remote = mysql.connector.conenct(
host = "database-1.cr8sy4u8g6l2.us-east-2.rds.amazonaws.com",
port = "3306",
user = "admin",
password = "zerobase",
database = "zerobase"
)
cur = remote.cursor()
cur.execute("drop table sql_file")
remote.close()
4) Terminal에 sql_file 테이블 삭제 결과 확인
desc sql_file;
show tables;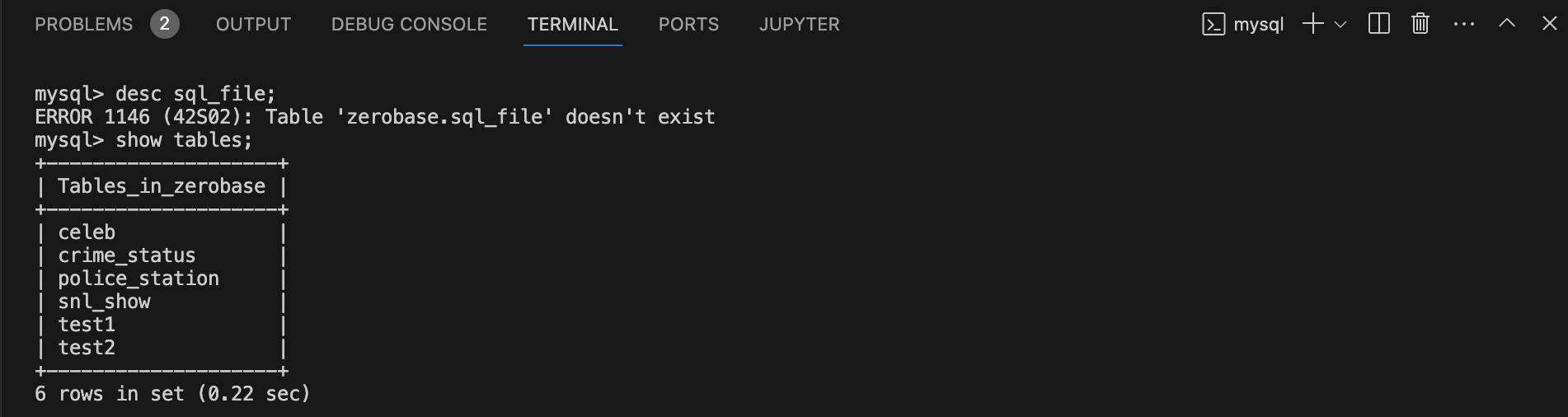
1.6 SQL File 실행(execute)
SQL File 실행
mydb = mysql.connector.connect( host = "<hostname>", user = "<usernmae>", password = "<password>", database = "<databasename>" ) mycursor = mydb.cursor() sql = open("<filename>.sql").read() mycursor.execute(sql)
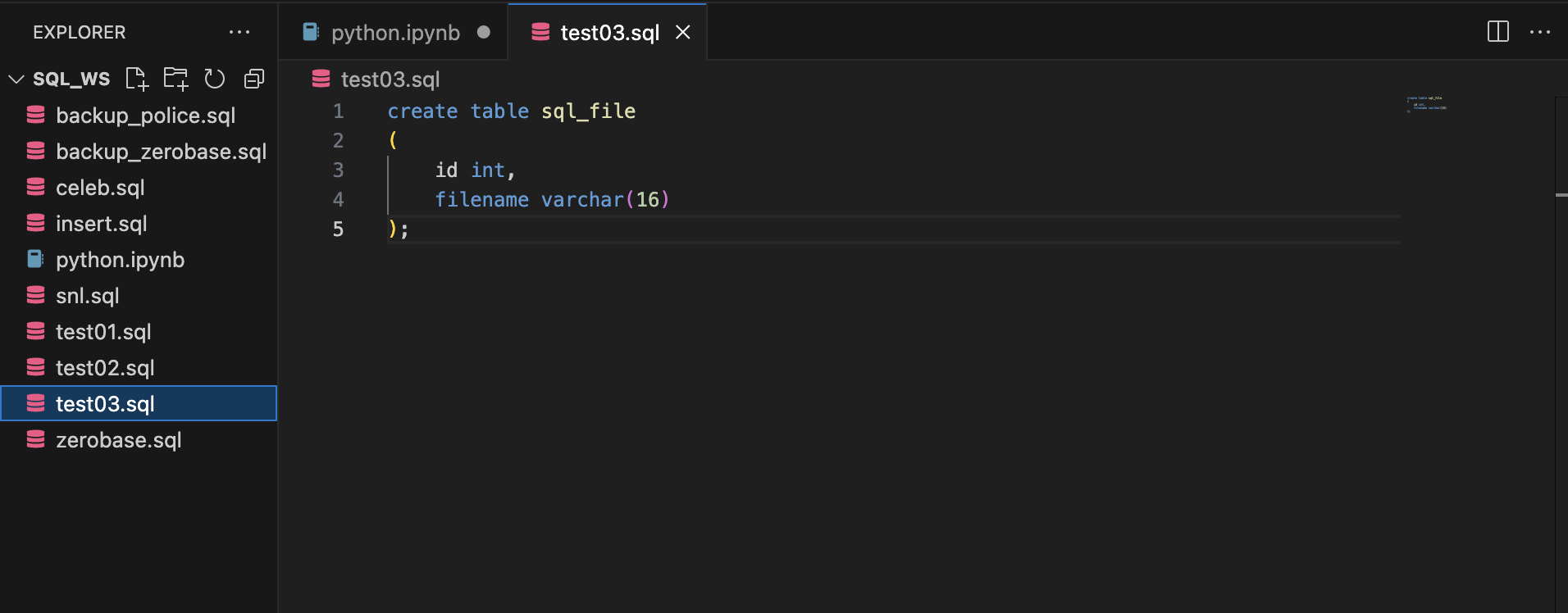
1.6.1 SQL file(test03.sql) 생성
1) VSCode에서 sql_ws 폴더 내 새파일(test03.sql) 생성
create table sql_file
(
id int,
filename varchar(16)
);
2) test03.sql 실행
remote = mysql.connector.connect(
host = "database-1.cr8sy4u8g6l2.us-east-2.rds.amazonaws.com",
port = "3306",
user = "admin",
password = "zerobase",
database = "zerobase"
)
cur = remote.cursor()
sql = open("test03.sql").read()
cur.execute(sql)
remote.close()
3) Terminal에서 sql_file 테이블 생성 결과 확인
show tables;
desc sql_file;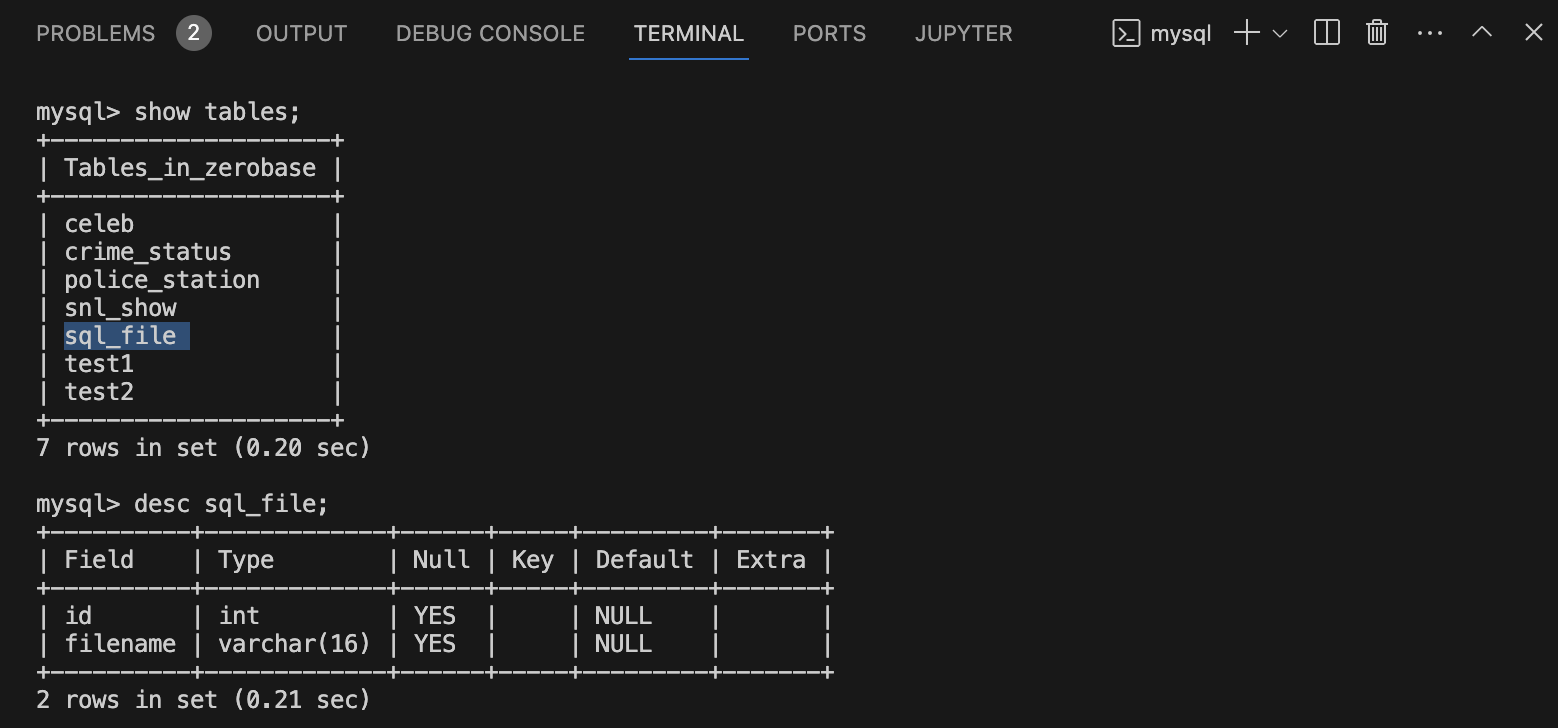
1.6.2 SQL File 내 여러가지 query가 존재할 경우
SQL File 내 여러가지 query가 존재할 경우
mydb = mysql.connector.connect( host = "<hostname>", user = "<username>", password = "<password>", database = "<databasename>" ) mycursor = mydb.cursor() sql = open("<filename>.sql").read() result = mycursor.execute(sql, multi=True)
1) VSCode에서 sql_ws 폴더 내 새파일(test04.sql) 생성
insert into sql_file values (1, "test01.sql");
insert into sql_file values (2, "test02.sql");
insert into sql_file values (3, "test03.sql");
insert into sql_file values (4, "test04.sql");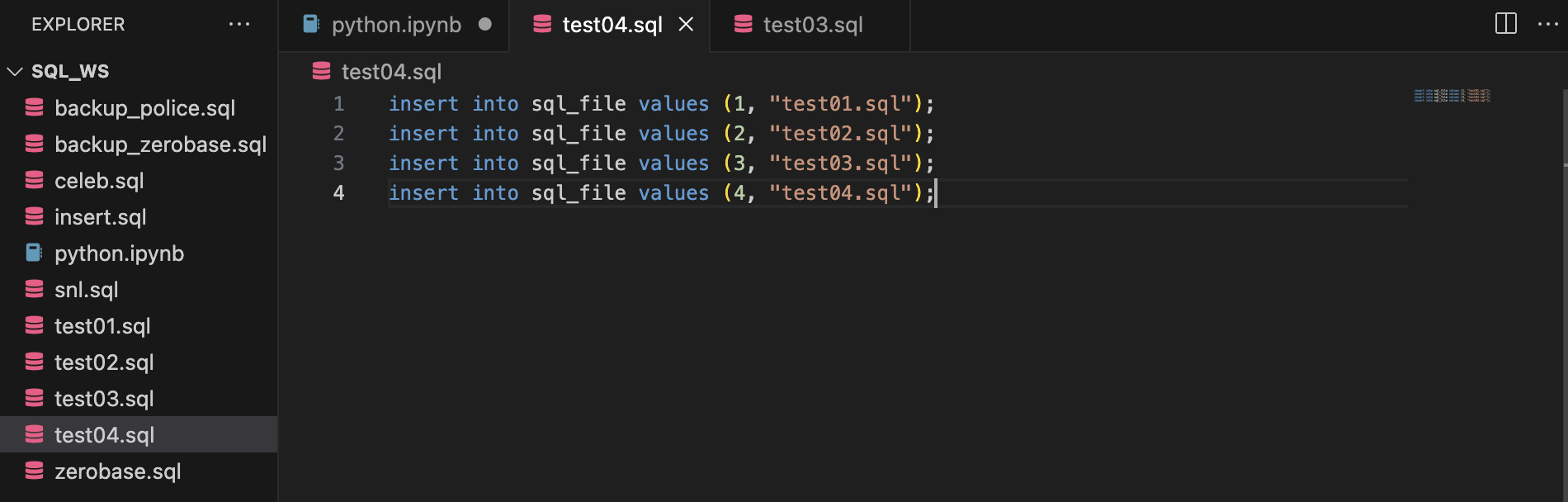
2) test04.sql 실행
remote = mysql.connector.connect(
host = "database-1.cr8sy4u8g6l2.us-east-2.rds.amazonaws.com",
port = "3306",
user = "admin",
password = "zerobase",
database = "zerobase"
)
cur = remote.cursor()
sql = open("test04.sql").read()
cur.execute(sql)
remote.close()
#결과: 에러(InterfaceError)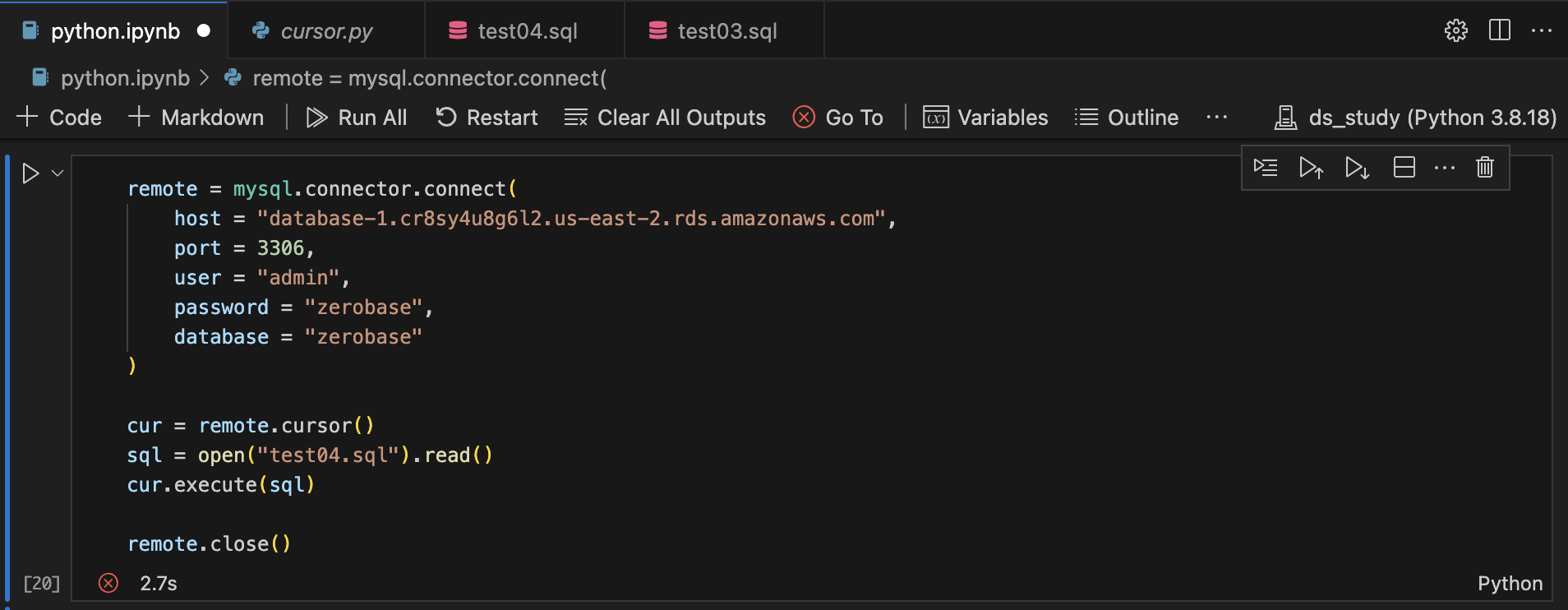
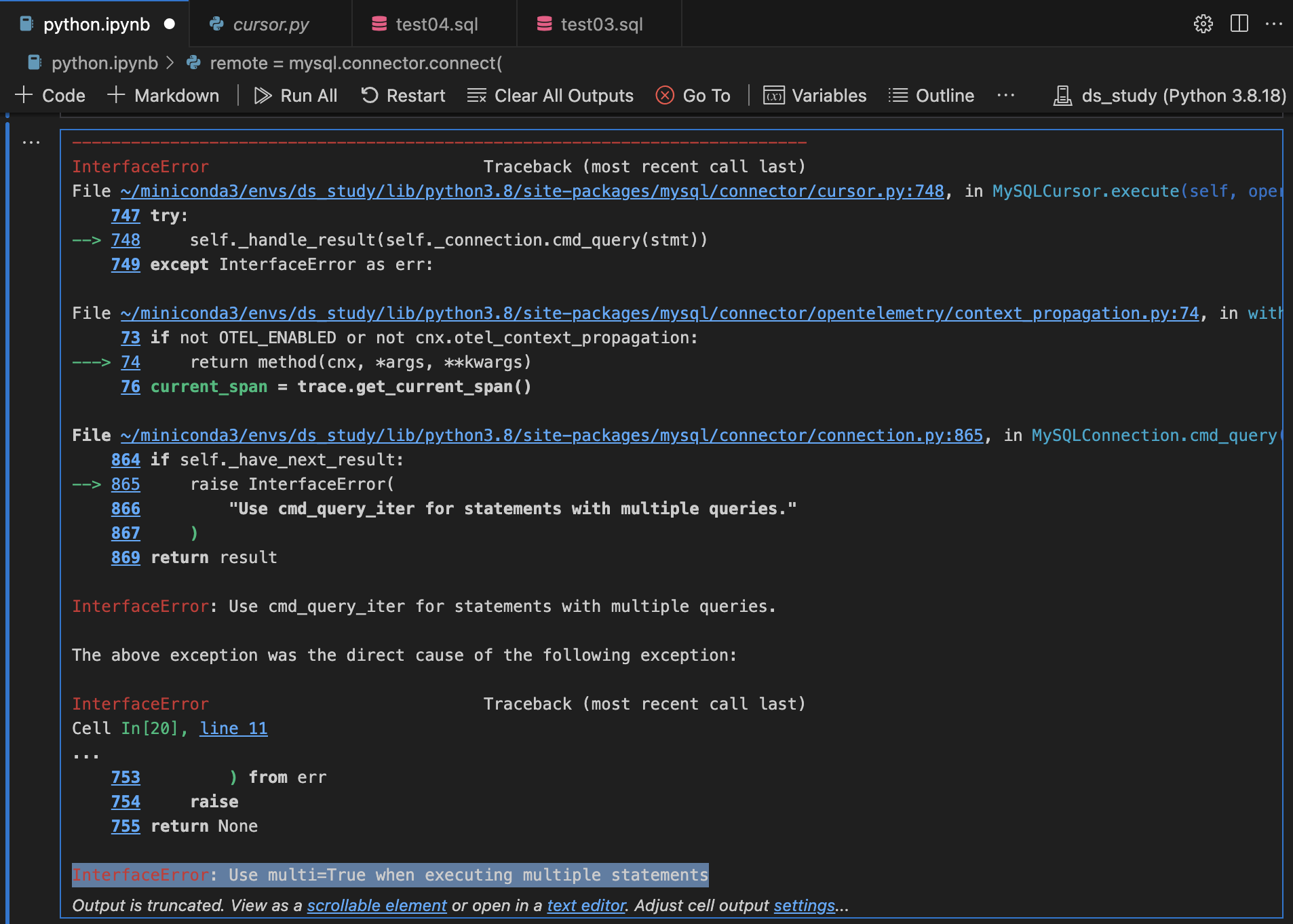
# multi=True 사용 시
remote = mysql.connector.connect(
host = "database-1.cr8sy4u8g6l2.us-east-2.rds.amazonaws.com",
port = "3306",
user = "admin",
password = "zerobase",
database = "zerobase"
)
cur = remote.cursor()
sql = open("test04.sql").read()
for result_iterator in cur.execute(sql, multi=True):
if result_iterator.with_rows: # 현재 실행된 쿼리가 결과를 반환하는지 확인
print(result_iterator.fetchall()) # 현재 실행된 쿼리의 모든 결과 행 출력
else:
print(result_iterator.statement) # 현재 실행된 쿼리 출력
remote.commit() # 데이터베이스에 대한 모든 변경 사항을 영구적으로 저장
remote.close()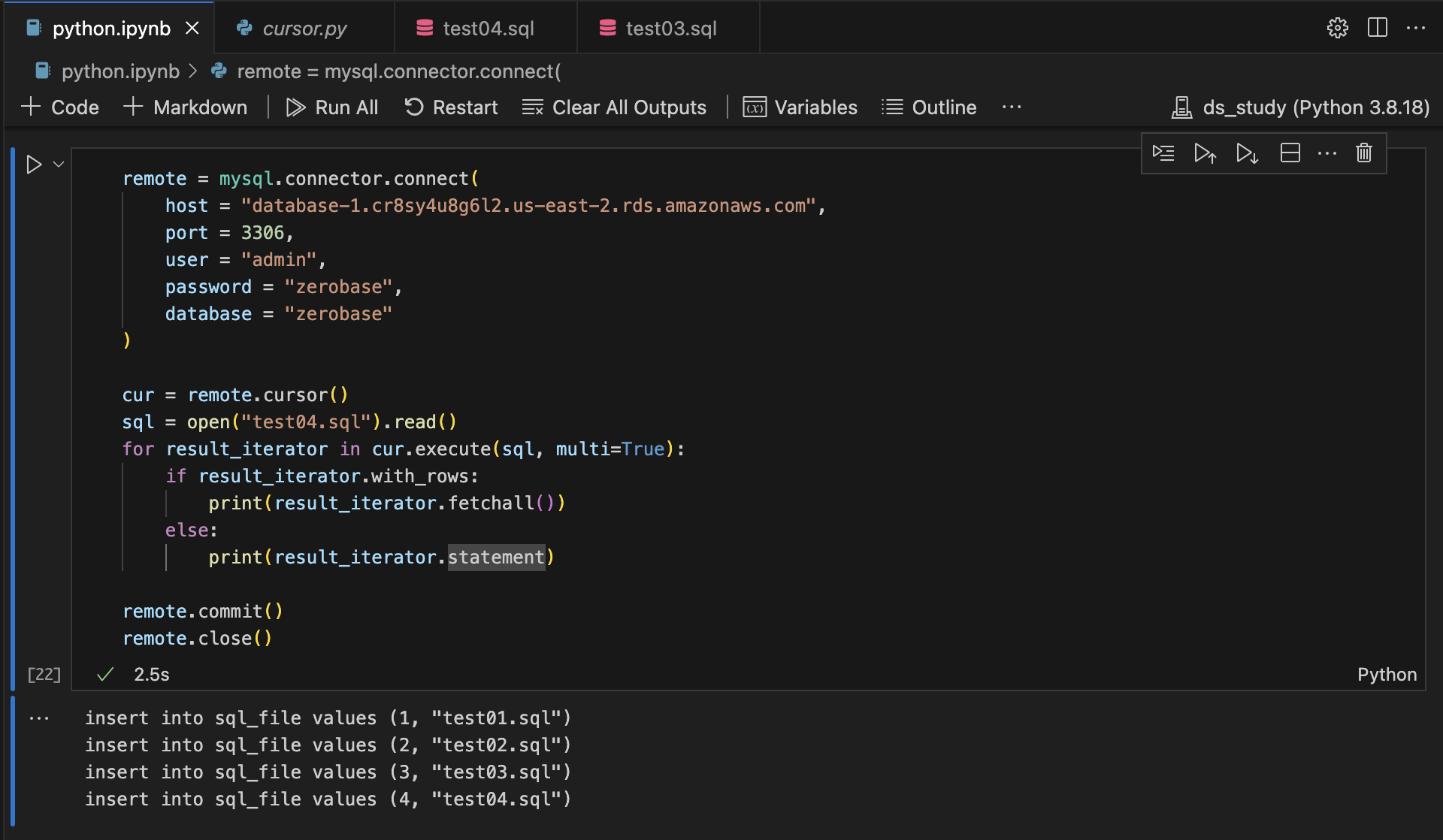
3) Terminal에 sql_file 테이블 생성 결과 확인
show tables;
desc sql_file;
select * from sql_file;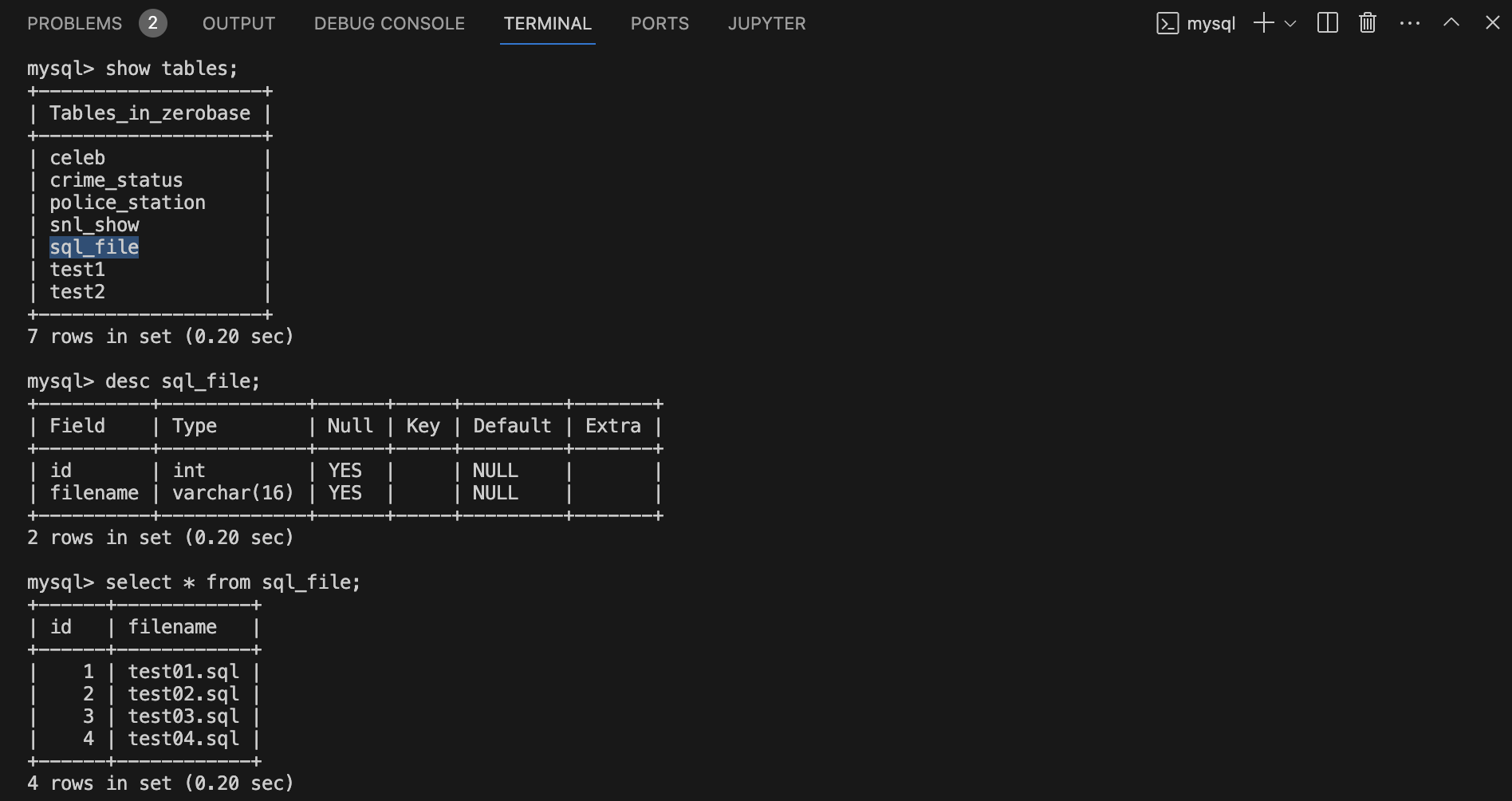
1.7 Fetch All
Fetch All
mycursor.excute(<query>) result = mycursor.fetchall() # fetchall() 메서드를 사용하여 실행된 쿼리의 모든 결과 가져오기 for data in result: # 결과 리스트를 순회하면서 각 행(row)을 data 변수에 대입 print(data) # 각 행의 데이터 출력
1) sql_file 테이블 조회
- 읽어올 데이터 양이 많은 경우
buffered=True
Query를 실행한 다음에 결과 값이 혹시 row를 포함하고 있으면 fetch를 해서 print
remote = mysql.connector.connect(
host = "database-1.cr8sy4u8g6l2.us-east-2.rds.amazonaws.com"
port = 3306,
user = "admin",
password = "zerobase",
database = "zerobase"
)
cur = remote.cursor(buffered=True)
cur.execute("select * from sql_file")
result = cur.fetchall()
for result_iterator in result:
print(result_iterator)
remote.close()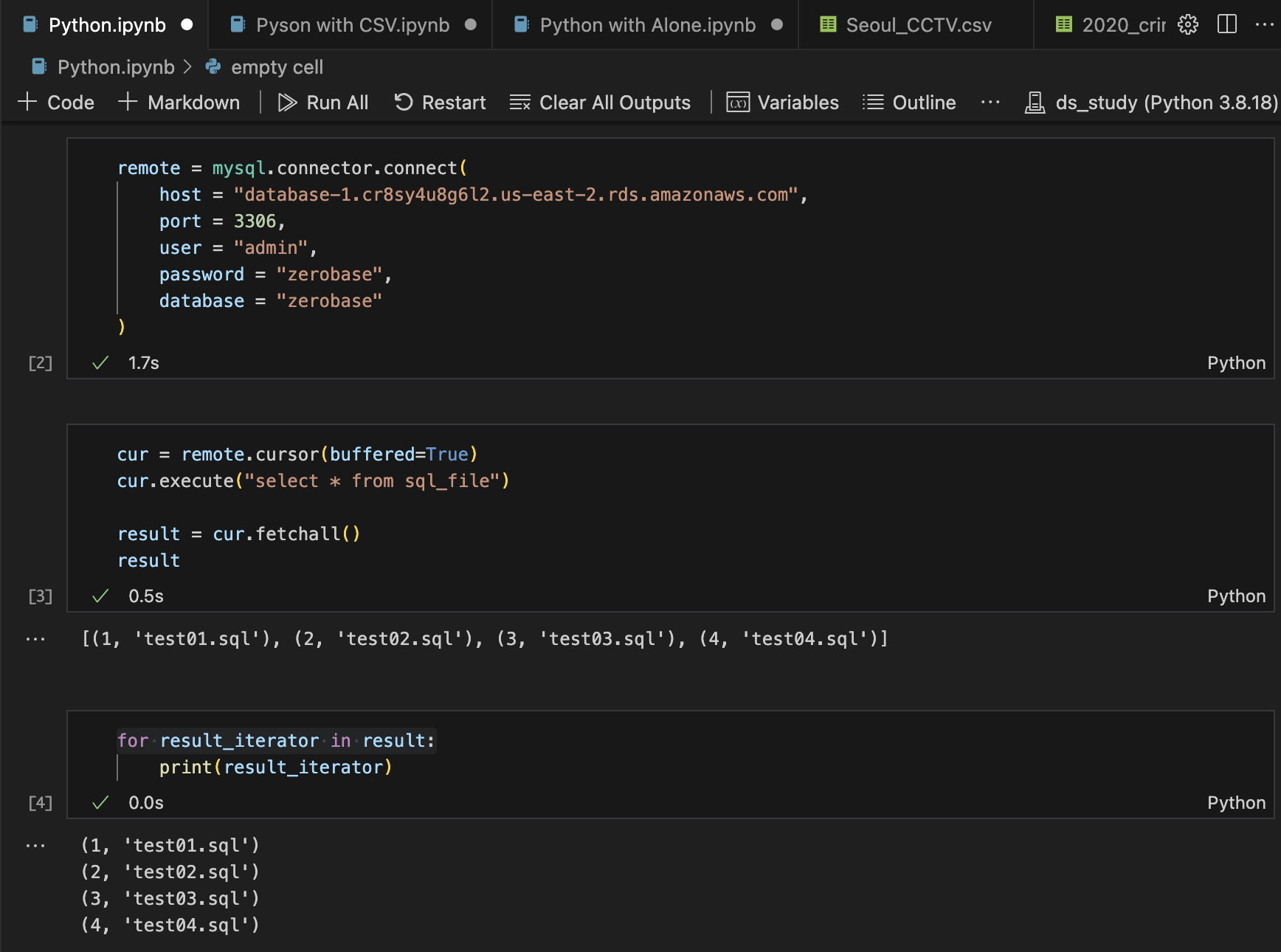
cursor를 통해서 query를 실행한 다음에 가져오는 결과값이 데이터인 경우에 사이즈가 크다. 기본 cursor를 생성했을때 실행이 안될 수 있기에 읽어올 데이터 양이 많은 경우 buffered 옵션을 Ture로 줘야한다 (buffered=True).
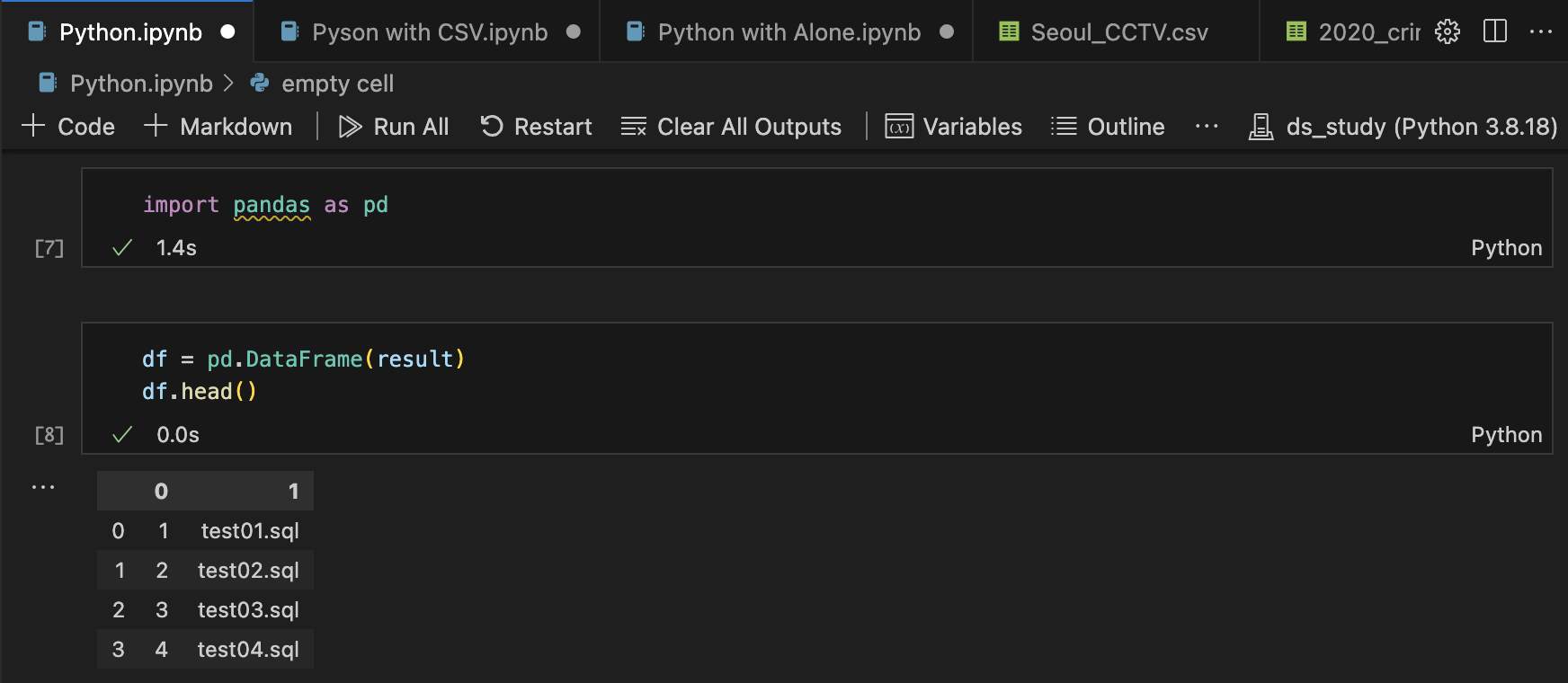
참고: 검색결과를 Pandas로 읽기
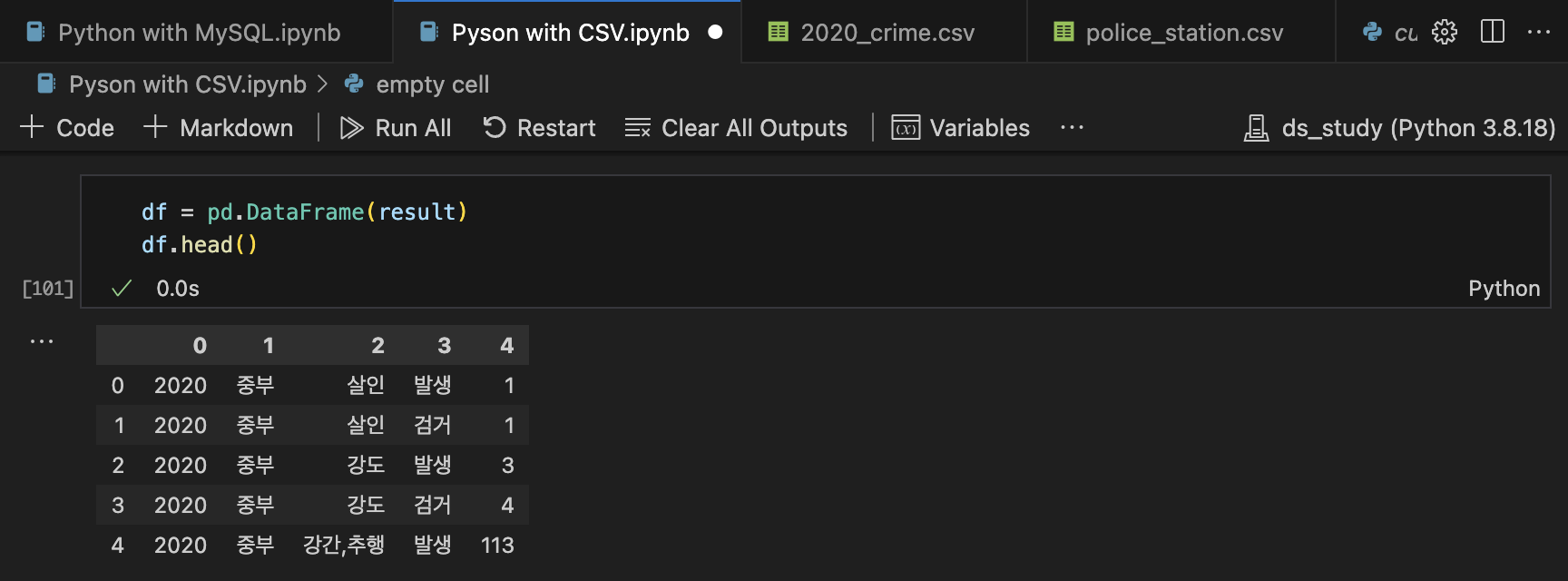
import pandas as pd df = pd.DataFrame(result) df.head()
2. Python with CSV
CSV에 있는 데이터를 Python 코드로 테이블에 추가(insert)
2.1 CSV 읽기(read)
police_station.csv를 pandas로 읽어와서 데이터를 확인
import pandas as pd
df = pd.read_csv("police_station.csv")
df.head()
# df: dataframe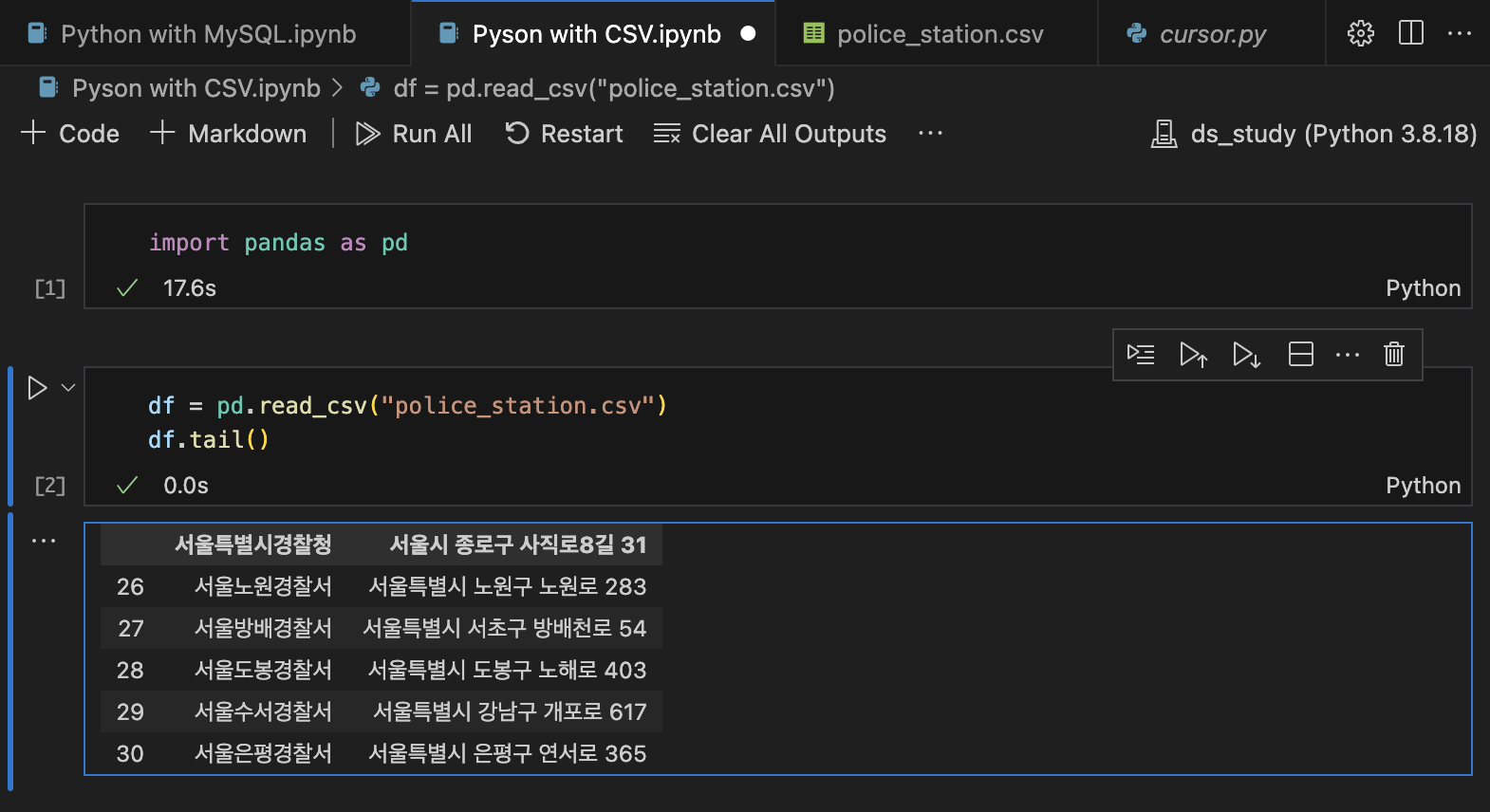
2.2 Database(zerobase) 연결
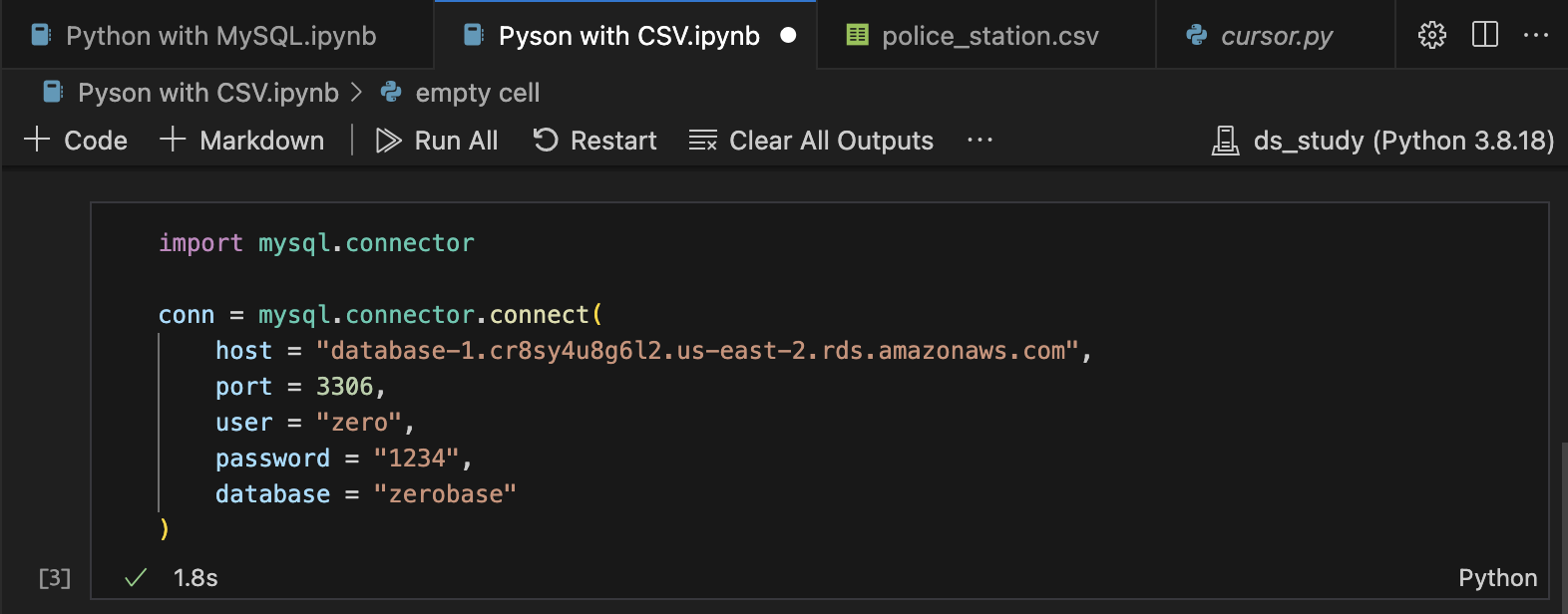
import mysql.connector
conn = mysql.connector.connect(
host = "database-1.cr8sy4u8g6l2.us-east-2.rds.amazonaws.com",
port = 3306,
user = "zero", # 실습때 만들어 두었던 zero 사용자 사용
password = "1234",
database = "zerobase"
)
2.3 Cursor 생성
읽어올 양이 많은 경우, cursor 생성 시 buffer 설정을 해준다.
cursor = conn.cursor(buffered=True)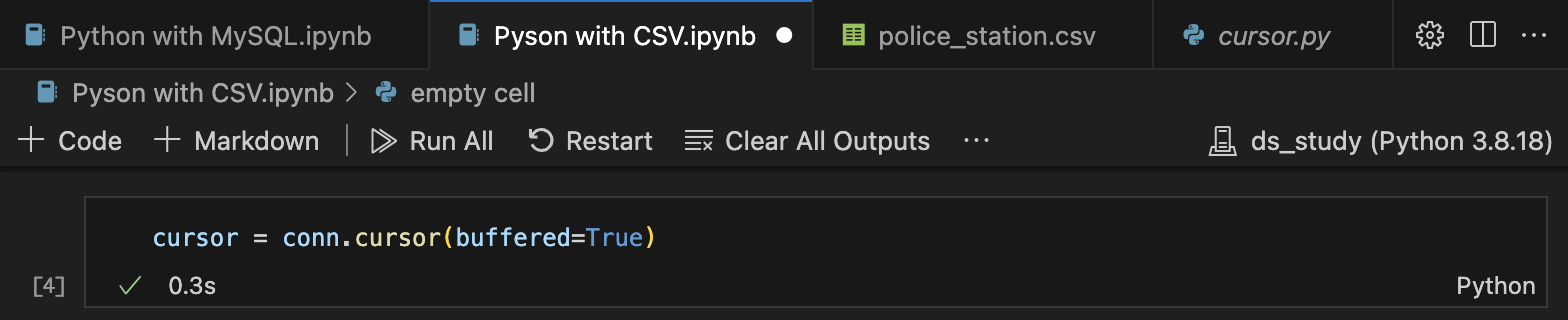
select 해줄게 아니여서 buffer 설정 비활성화 해도 됨
2.4 INSERT문 생성
sql = "INSERT INTO police_station VALUES (%s, %s)"
# police_station 테이블에 두가지의 string 값 넣기
# %s에서 s는 string을 뜻함
2.5 데이터 입력
for i, row in df.iterrows(): # DataFrame의 각 행에 대해 반복
cursor.execute(sql, tuple(row)) # SQL 쿼리 실행 (sql은 실행할 쿼리, tuple(row)는 현재 행의 데이터를 튜플 형태로 전달)
print(tuple(row))
conn.commit() # 데이터베이스에 변경사항 적용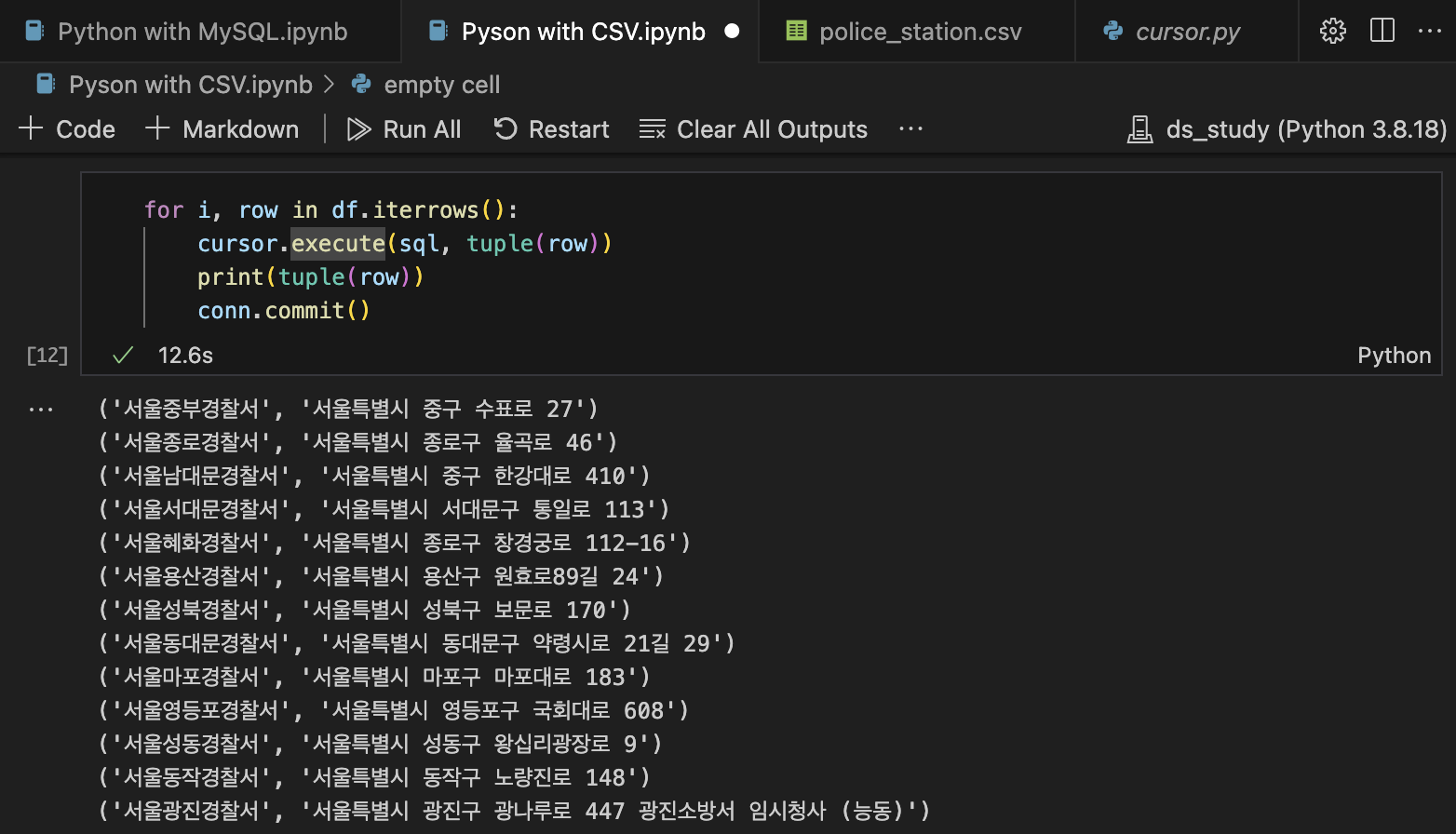
for i, row in df.iterrows():
print(row)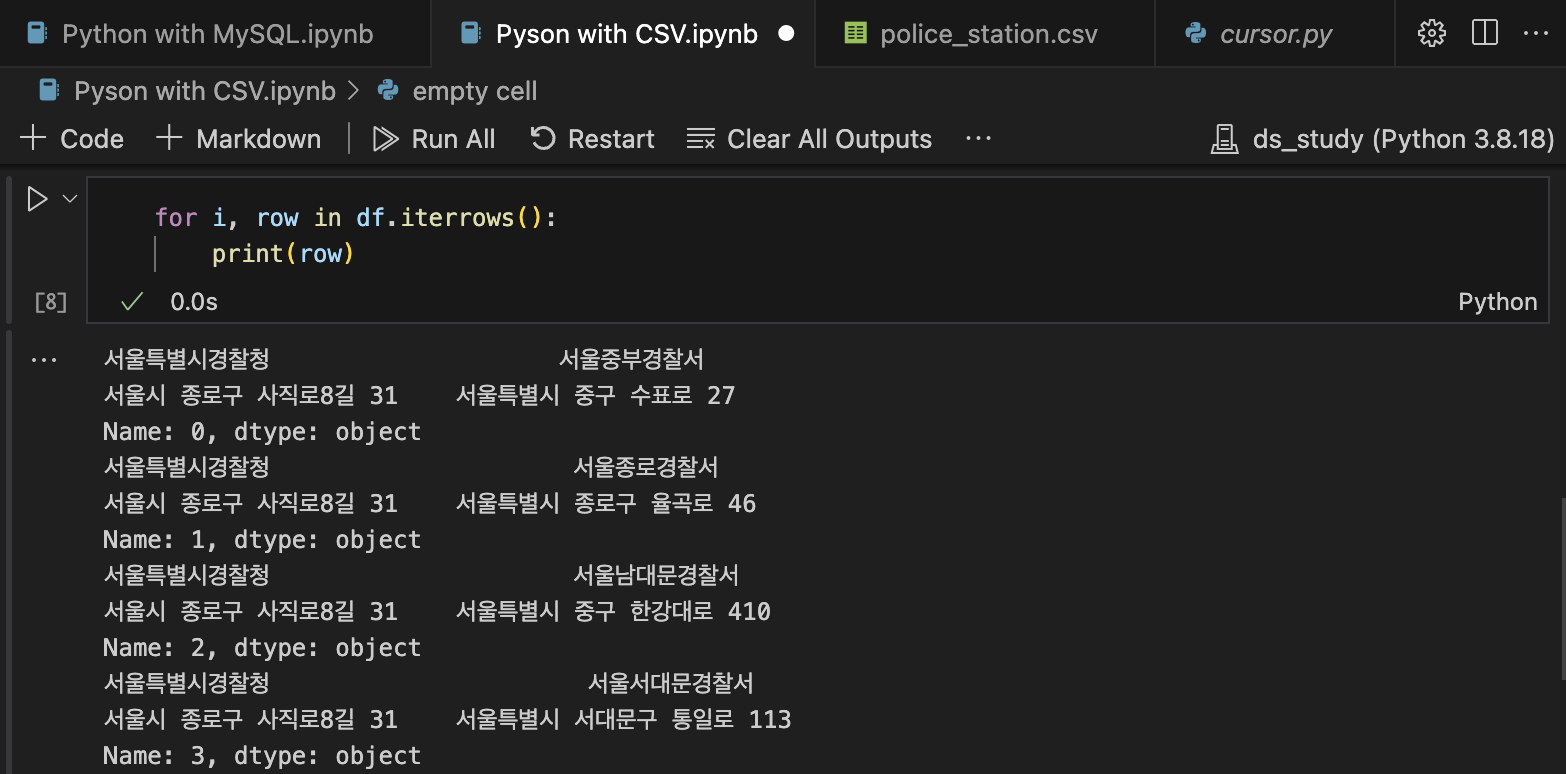
for i, row in df.iterrows():
print(tuple(row))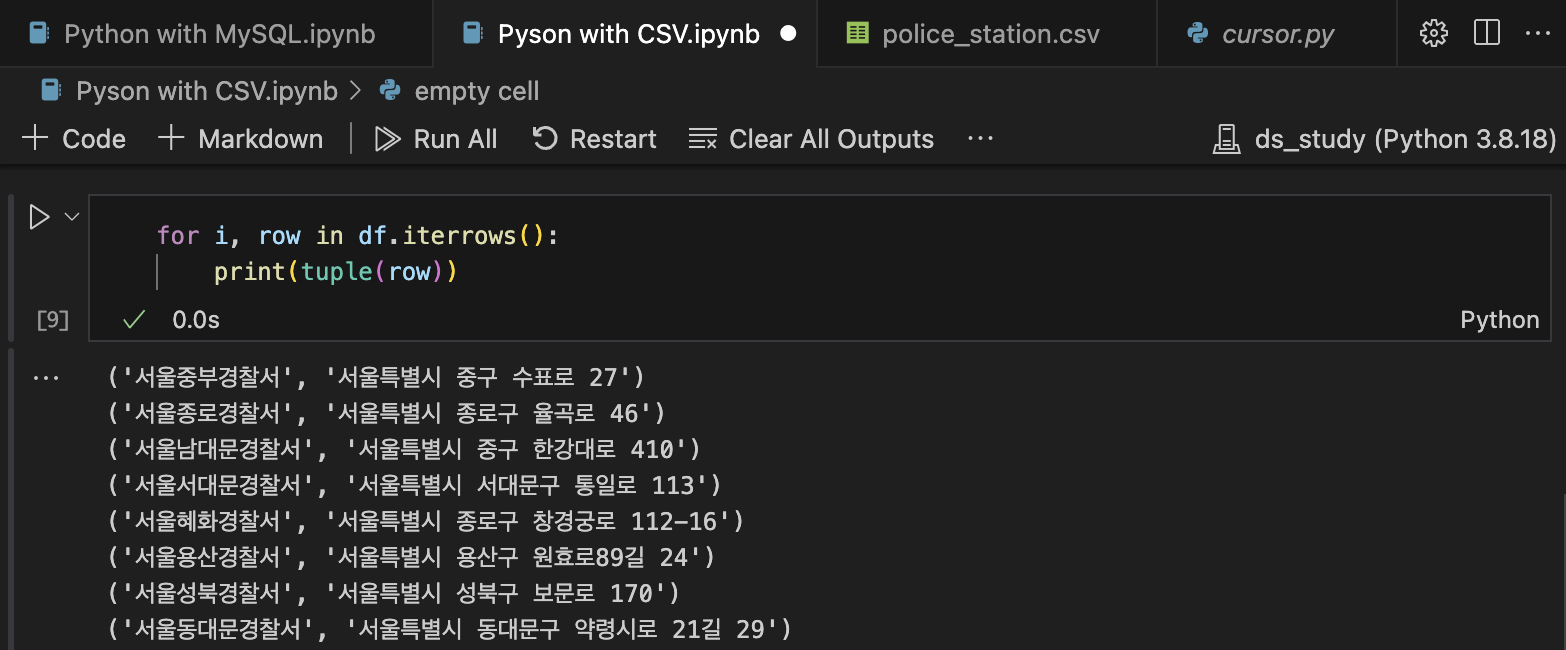
2.6 Cursor 실행하여 데이터 입력 결과 확인
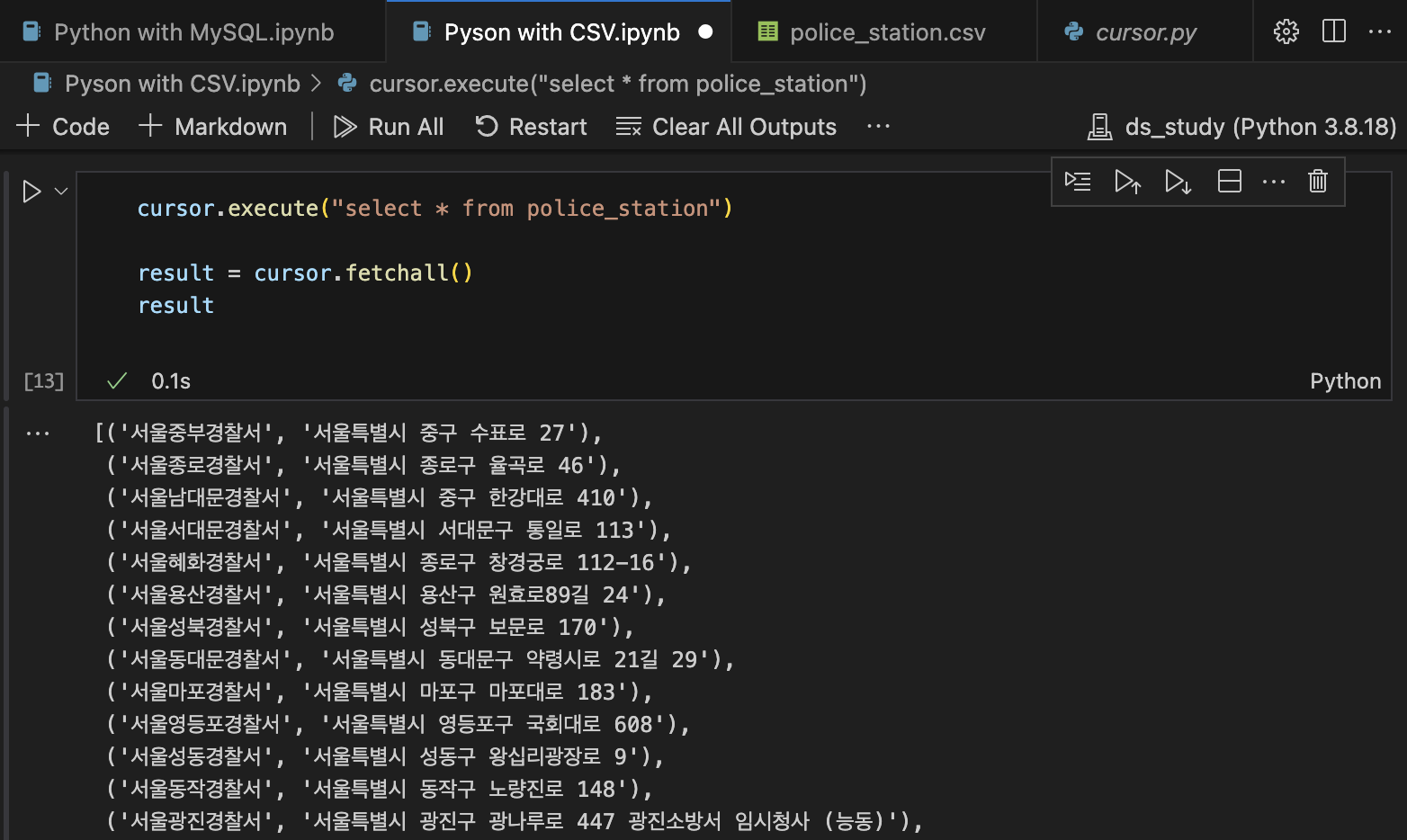
cursor.execute("SELECT * FROM police_station")
result = cursor.fetchall()
for row in result:
print(row)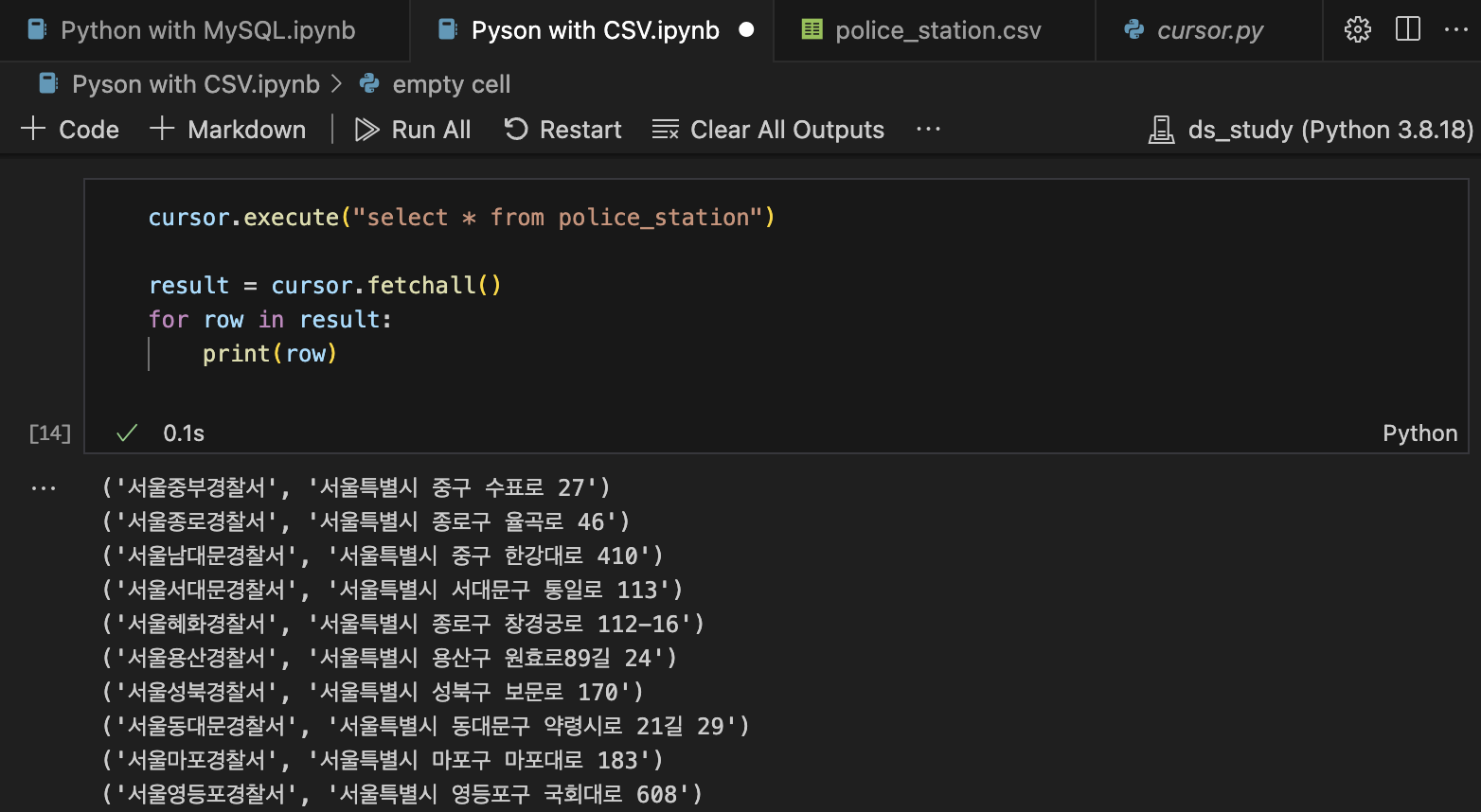
2.7 검색 결과를 Pandas로 읽기
df = pd.DataFrame(result)
df.tail()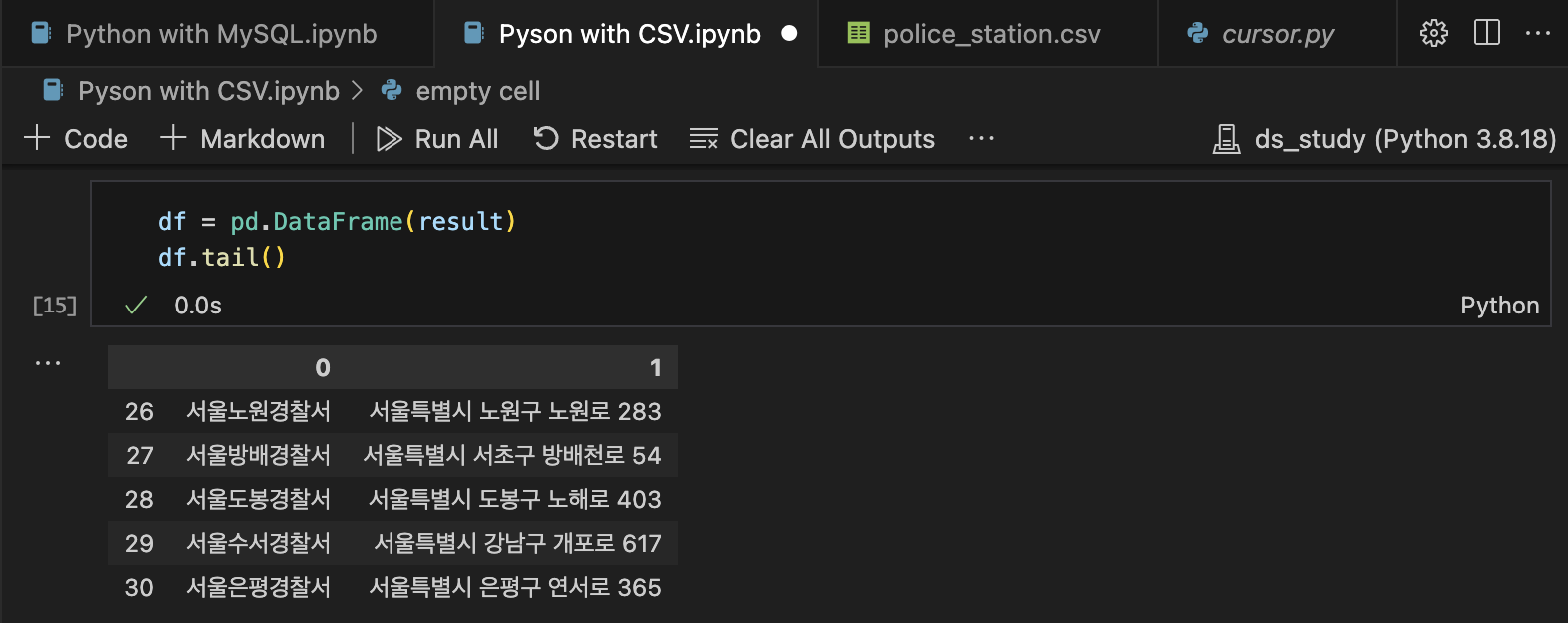
여기서 Tip, 특히 우리나라 사이트에서 제공받은 CSV 파일들이 한글이 깨지는 경우, encoding 값을 'euc-kr'로 설정하기
import pandas as pd
df = pd.read_csv('2020_crime.csv', encoding='euc-kr')
df.head()Example 1: crime_status 테이블에 2020_crime.csv 데이터를 입력하는 코드를 작성하기
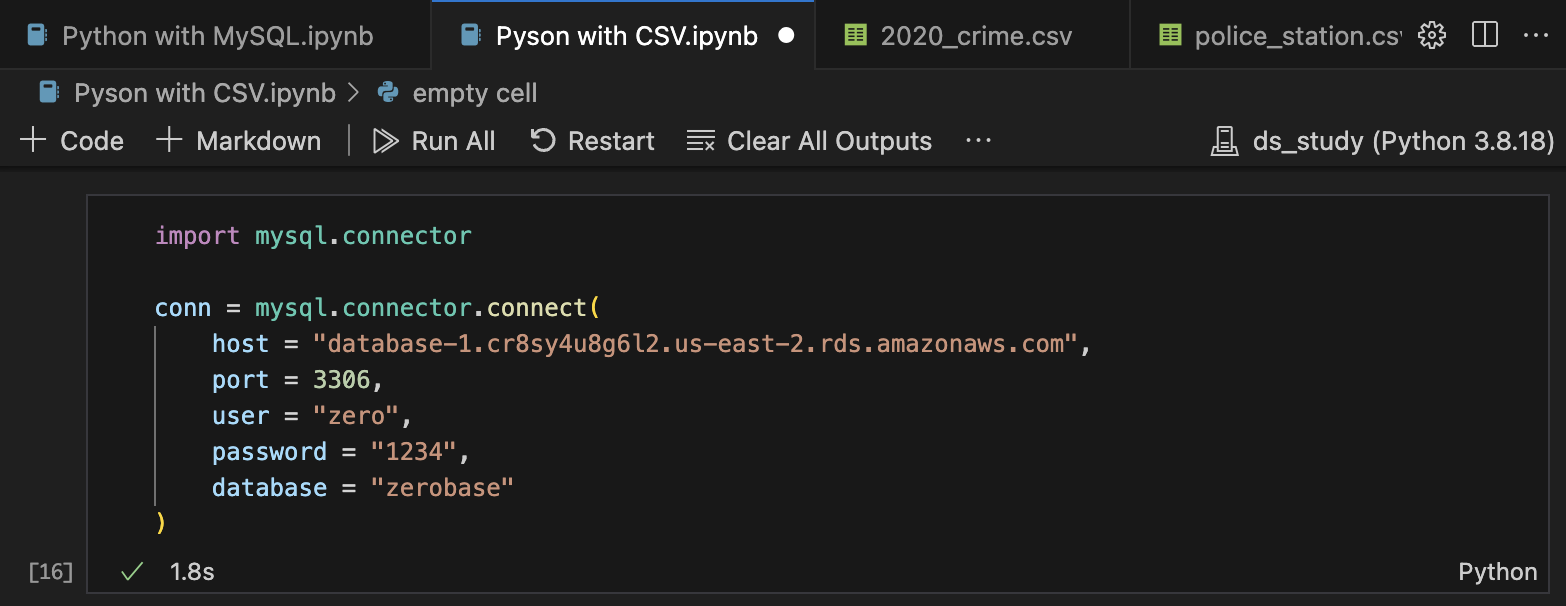
1) AWS RDS (database-1) zerobase 접속
import mysql.connector
conn = mysql.connector.connect(
host = "database-1.cr8sy4u8g6l2.us-east-2.rds.amazonaws.com",
port = 3306,
user = "zero",
password = "1234",
database = "zerobase"
)
2) 2020_crime.csv 데이터(encoding='euc-kr') 읽기
import pandas as pd
df = pd.read_csv('2020_crime.csv', encoding='euc-kr')
df.head(2)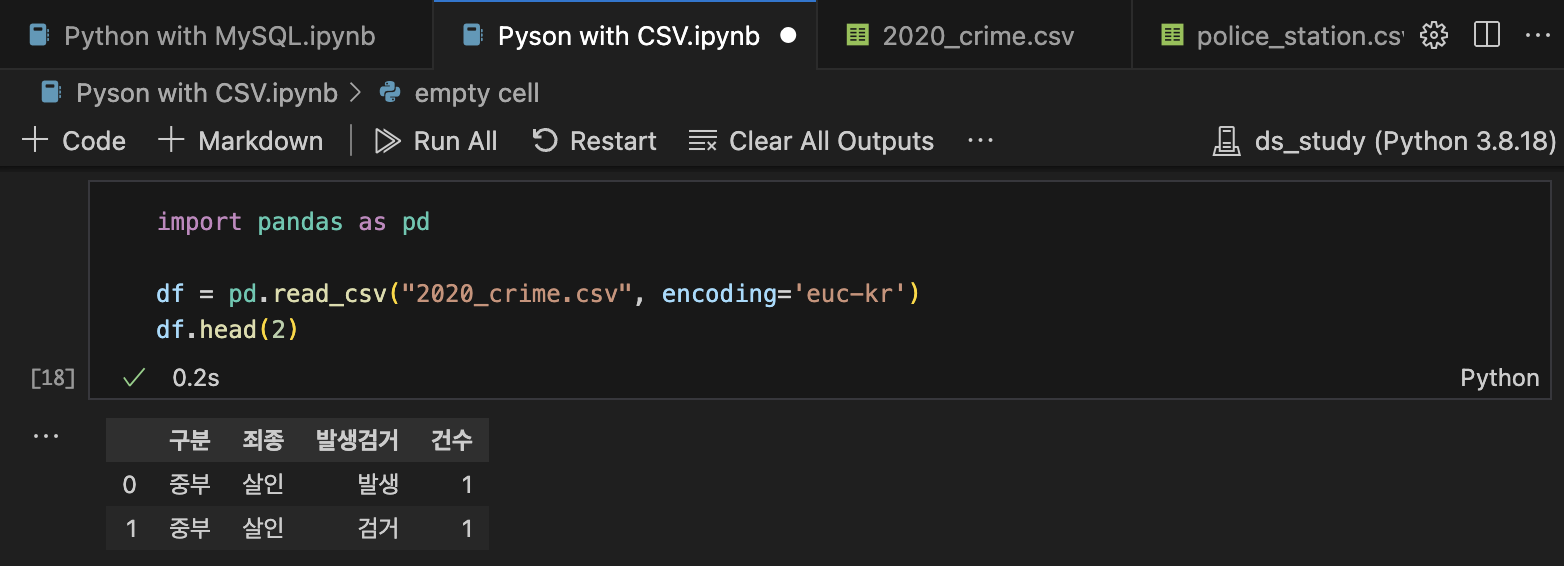
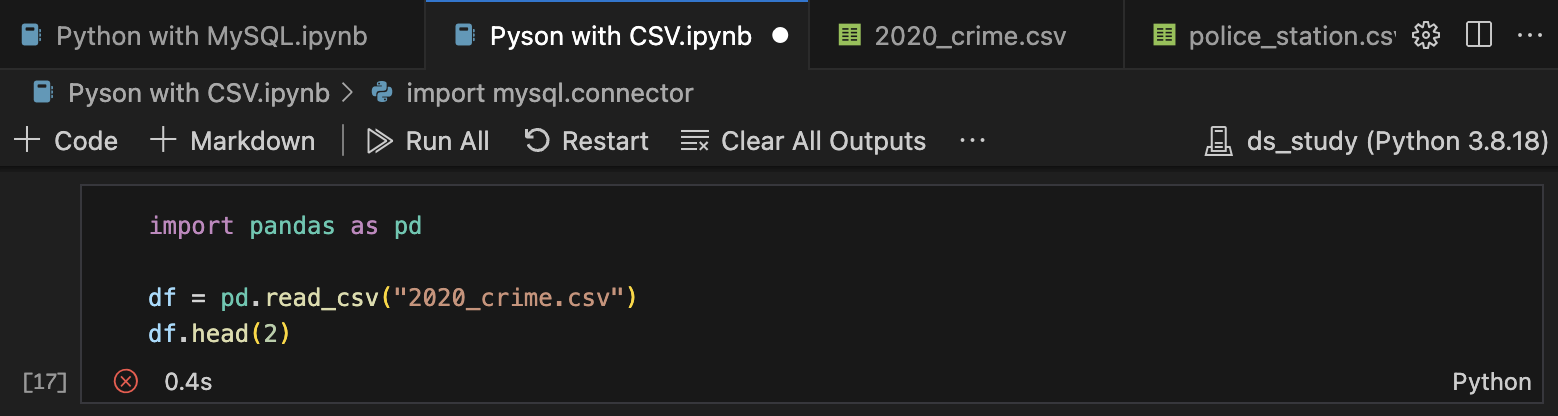
import pandas as pd
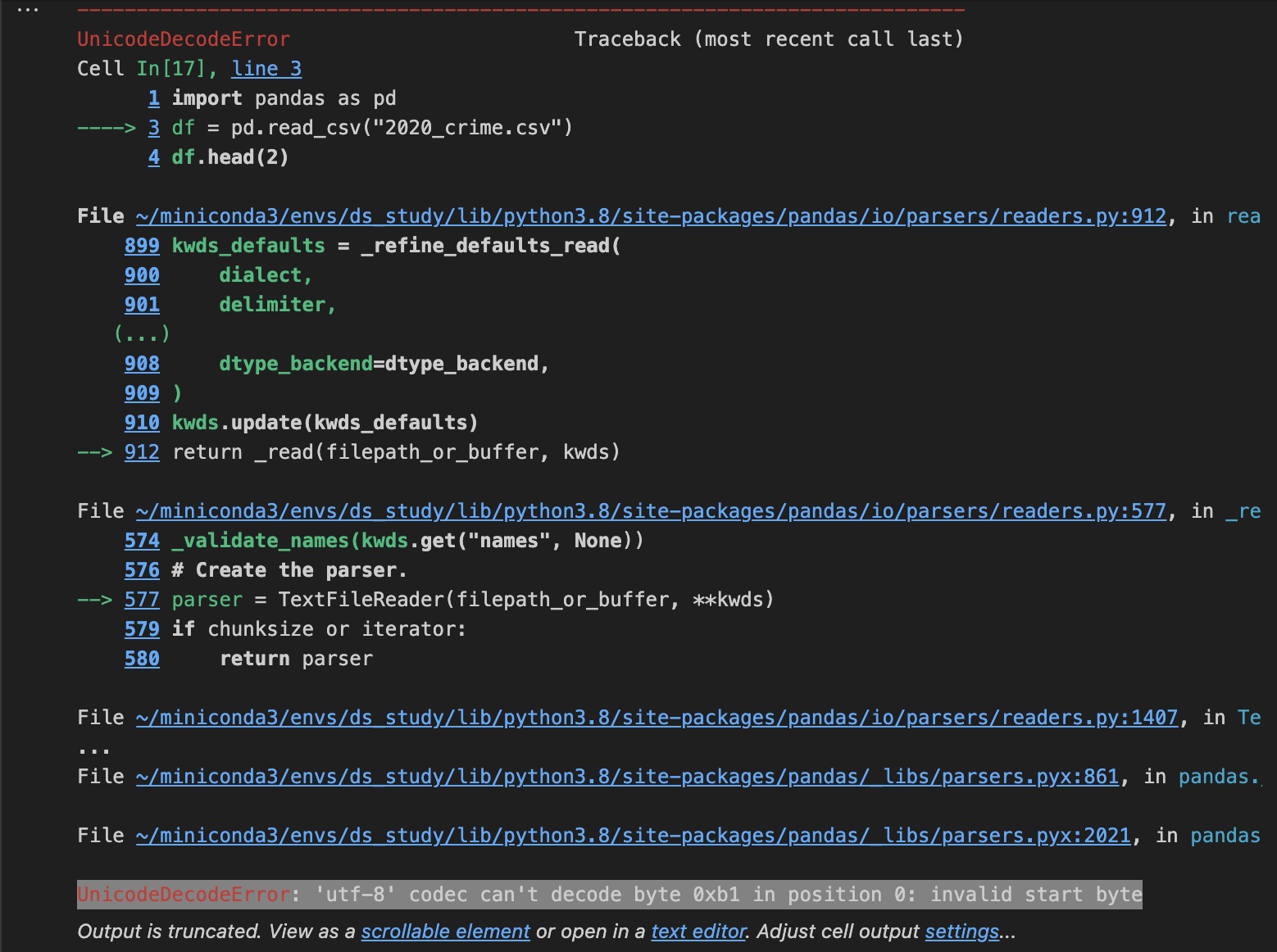
df = pd.read_csv("2020_crime.csv")
df.head(2)위와 같은 query를 입력하니 'utf-8'이라고 하면서 에러가 뜨는걸 확인할 수 있다.
3) INSERT문 query 작성
sql = """INSERT INTO crime_status VALUES ("2020", %s, %s, %s, %s)"""
cursor = conn.cursor(buffered=True)
/*2020년도는 해당 파일이 2020년도 데이터이기 때문에 데이터에 없어
일괄적으로 파일에 들어가야하기 때문에 고정으로 2020 넣기*/
4) 데이터를 crime_status 테이블에 INSERT
for i, row in df.iterrows():
cursor.execute(sql, tuple(row))
print(tuple(row))
conn.commit()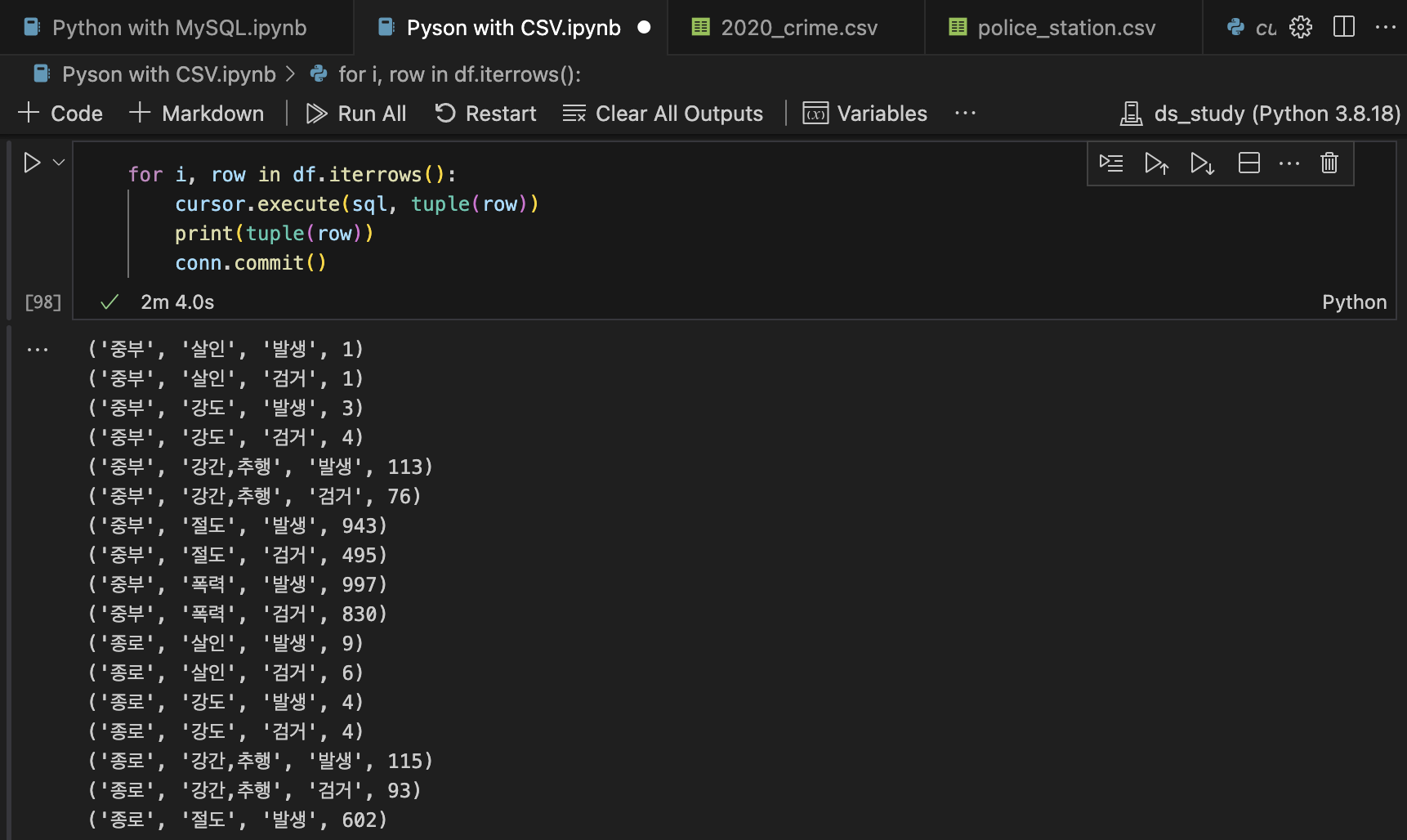
5) crime_status 테이블의 데이터 조회
cursor.execute("SELECT * FROM crime_status")
result = cursor.fetchall()
for row in result:
print(row)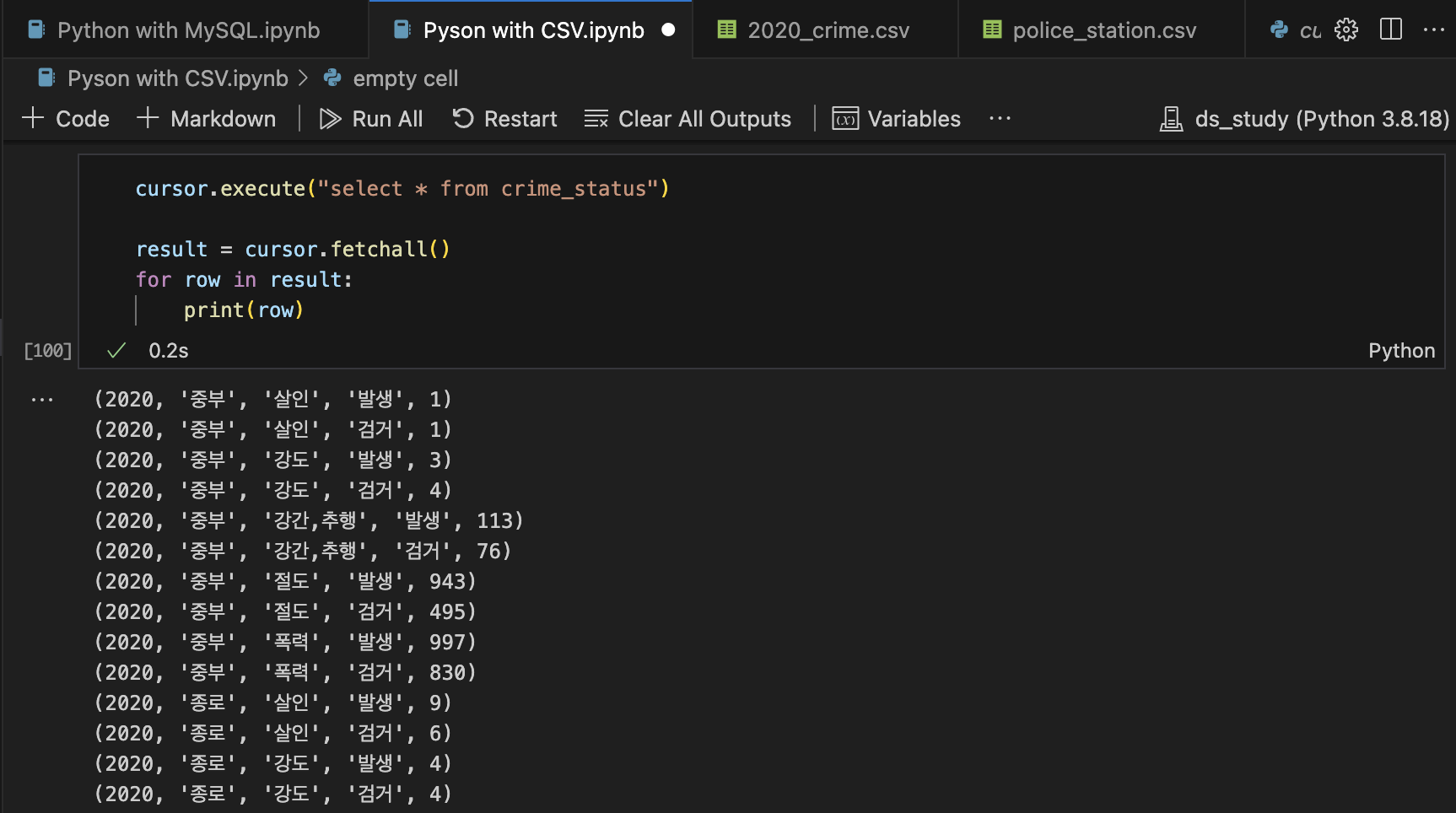
6) 조회한 데이터 결과를 Pandas로 변환해서 확인
df = pd.DataFrame(result)
df.head()