1. Python HTML Parser
HTML을 파싱할 때 사용할 수 있는 여러 가지 파서가 있다. 각 파서는 장단점이 있으며, 다음은 대표적인 세 가지 파서다.
1.1 BeautifulSoup
- 장점:
- 사용하기 쉬움
- 문서가 잘 작성되어 있고 커뮤니티 지원이 좋음
- 깨진 HTML을 잘 처리할 수 있음
- 단점:
- 속도가 상대적으로 느림
from bs4 import BeautifulSoup
soup = BeautifulSoup('<html><body>Hello</h1></body></html>')
print(soup.h1.string)
# 결과물: Hello1.2 lxml
- 장점:
- 매우 빠르고, XPath 같은 고급 쿼리를 지원
- 단점:
- 문서가 비교적 부족
from lxml import etree
tree = etree.fromstring('<html><body><h1>Hello</h1></body><html>')
print(tree.find('.//h1').text)
# 결과물: Hello1.3 html.parser
- 장점:
- Python 표준 라이브러리에 포함된 모듈, 빠르고 신뢰성이 있음
- 단점:
- 기능이 상대적으로 제한적
- 덜 직관적일 수 있음
from html.parser import HTMLParser
class MyParser(HTMLParser):
def handle_starttag(self, tag, attrs):
print("Start tag:", tag)
parser = MyParser()
parser.feed('<html><body><h1>Hello</h1></body></html>')2. BeautifulSoup 라이브러리

2.1 BeautifulSoup 객체와 Tag 객체
2.1.1 BeautifulSoup 객체
Beautiful 객체는 파싱된 문서 전체를 나타낸다. 대부분의 목적으로 Tag 객체와 비슷하게 사용할 수 있다. 이 의미는 트리 탐색과 트리 검색 기능을 제공한다.
2.1.2 Tag 객체
Tag 객체는 원본 문서 안에 특정 XML 또는 HTML 태그 요소에 대한 객체이다.
soup = BeautifulSoup('<b class="boldest">Extremely bold</b>')
tag = soup.b
type(tag)
# <class 'bs4.element.Tag'>3. BeautifulSoup 사용
pip install bs4from bs4 import BeautifulSoup
- 사용할 parser를 명시하지 않아도 작동이 된다. parser를 명시하지 않을 시 현재 환경에 설치된 parser 중에서 자동으로 하나를 선택해서 사용하게 된다.
코드가 실행되는 환경마다 선택되는 parser가 달라질 수 있기 때문에 실제로 배포되는 코드 또는 공유하는 코드에서는 명시적으로 parser를 선택하는 것이 좋다.
별도 설치 없이 사용 가능한 Python 내장 모듈 html.parser를 사용할 수 있다.
4. BeautifulSoup/Tag 기능
4.1 prettify()
prettify() 메서드는 HTML 문서를 보기 좋게 들여쓰기된 형태로 반환한다.
html = '<html><head><title>Title</title></head><body><p>Paragraph</p></body></html>'
soup = BeautifulSoup(html, 'html.parser')
print(soup.prettify())4.2 find() & find_all()
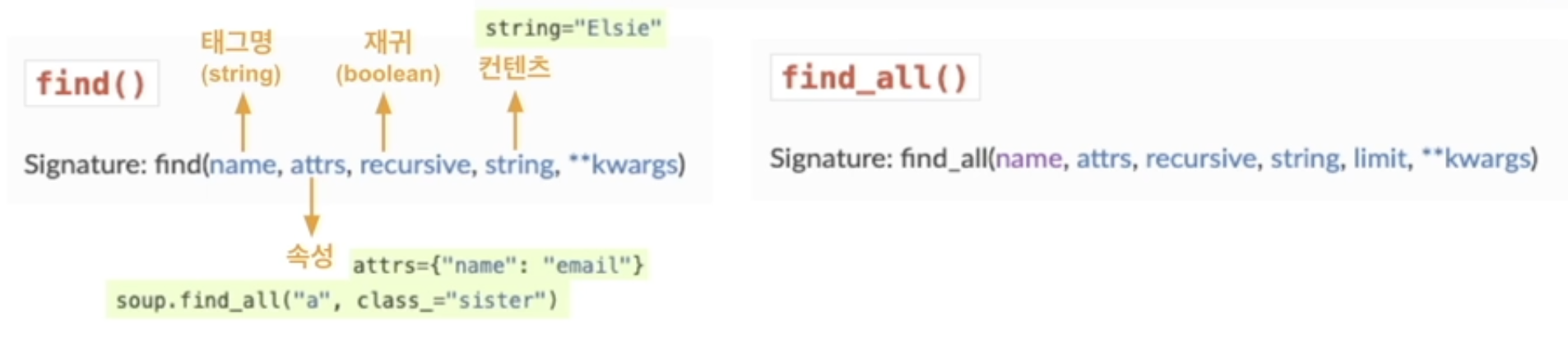
find() 메서드는 조건에 맞는 첫 번째 태그를 반환한다.
find()는 조건에 부합하는 요소를 찾지 못할 경우 None을 반환한다.
soup.find_all('title', limit=1)
# [<title>The Dormouse's story</title>]find_all() 메서드는 조건에 맞는 모든 태그를 리스트 형태로 반환한다. limit 인자를 사용하여 반환할 요소의 개수를 제한할 수 있다.
find_all()은 조건에 부합하는 요소를 찾지 못할 경우 빈 리스트[]를 반환한다.
soup.find('title')
# <title>The Dormouse's story</title>
거북선통통통통