Data Analysis with Python
1.판다스 기초 Pandas

1. 판다스(Pandas) 판다스(Pandas)는 파이썬에서 사용되는 데이터 조작과 분석을 위한 라이브러리이다. 이름인 판다스는 Panel Data에서 따온 것으로, 처음에는 시계열 데이터와 교차되는 다차원 데이터를 다루기 위해 설계되었다. 그러나 현재는 댜앙한 형태
2.판다스 기초 Series와 DataFrame
1. Series와 DataFrame 시리즈(Series)와 데이터프레임(DataFrame)은 판다스에서 제공하는 자료구조이다. 1.1 Series(시리즈) 시리즈(Series)는 인덱스(index)와 값(value)으로 이루어진 순서가 있는 형태이고, 1차원 데
3.판다스 기초 Series와 DataFrame 인덱싱
1. 시리즈와 데이터프레임 속성 - 인덱서(Indexer) 인덱서(Indexer)는 판다스(Pandas)에서 시리즈(Series)나 데이터프레임(DataFrame) 안에 있는 특정 데이터를 선택하거나 조작하는 역할을 한다. 판다스에서는 인덱서를 사용하여 데이터를 더
4.판다스 기초 Series의 속성과 기능
1. 시리즈의 속성 1.1 index index 속성은 시리즈의 인덱스(라벨)를 조회한다. > 예시: 1.2 values values 속성은 시리즈의 값들을 numpy 배열로 반환한다. > 예시 1: 예시 2: 1.3 dtype dtype 속성은 시
5.판다스 기초 Series의 속성과 기능 2
2.8 idxmax() & idxmin() idxmax() 메서드는 시리즈에서 최대값을 가진 첫 번째 항목의 인덱스를 반환하며, idxmin() 메서드는 시리즈에서 최소값을 가진 첫 번째 항목의 인덱스를 반환한다. > 반환값(Returns): 최대값 또는 최소값
6.Pandas 기초 Random Seed (랜덤 시드)
1. random.seed() 함수 random.seed() 함수는 난수 생성을 위한 초기화 값으로 사용된다. 일반적으로 컴퓨터 프로그래밍에서 "무작위"한 결과를 얻기 위해 난수를 사용한다. 그러나 컴퓨터는 사실상 완벽한 무작위를 생성할 수 없다. 대신에, 난수 생성
7.Pandas 기초 DataFrame의 속성과 기능
1. DataFrame의 속성 1.1 index index는 데이터프레임의 인덱스(행의 라벨)를 조회한다. > 1.2 columns columns는 데이터프레임의 컬럼(열의 라벨)을 조회한다. > 1.3 values values는 데이터프레임의 값들을 2
8.Python 환경설정
1. 환경설정 이론 데이터 분석에는 파이썬이라는 프로그래밍 언어가 널리 사용된다. 이는 파이썬이 다양한 데이터 분석 도구와 라이브러리를 포함하고 있으며, 사용이 간편하고 확장성이 뛰어나기 때문이다. 파이썬을 통해 데이터 분석 작업을 수행하기 위해 Jupyter Not
9.아나콘다 가상환경
1. 가상환경(Virtual Environment)이란? 가상환경은 다음과 같은 특징을 가지고 있다. 작은 가상의 컴퓨터를 만드는 것: 가상환경은 실제 컴퓨터 안에 작은 가상의 컴퓨터를 만드는 것으로, 해당 환경에서는 독립적으로 패키지와 라이브러리를 관리할 수 있다
10.개발언어 사용자 분석
1. 개발언어 사용자 분석을 통한 업계 트렌드 파악 개발 언어 트렌드가 왜 중요할까? 개발 언어 트렌드를 주시하는 것은 데이터 분석가에게 매우 중요하다. 우선적으로, 최신 언어와 도구를 이용하면 최신 기술과 동향을 따라갈 수 있다. 데이터 분석은 빠르게 진화하고
11.개발언어 사용자 분석 - EDA
1. 데이터 불러오기 1) Pandas 라이브러리를 사용하여 CSV 파일을 불러와 데이터프레임으로 저장 2) 데이터프레임에 대한 간단한 요약 정보 데이터프레임의 구조와 각 열의 데이터 타입, 그리고 결측치 여부 등을 확인할 때 사용한다. info 함수가 반환하는
12.개발언어 사용자 분석 - 데이터 시각화
1. 데이터 시각화 > koreanize_matplotlib는 한글 폰트를 사용하여 Matplotlib 그래프의 한글 텍스트를 보기 좋게 만들어주는 라이브러리이다. 이를 통해 한글을 포함한 그래프를 손쉽게 작성할 수 있다. 만약 matplotlib가 설치되어 있지
13.개발언어 사용자 분석 - 데이터 시각화 2
6)plt.barh():tick_label 매개변수: 막대 그래프의 각 막대에 대한 레이블을 지정한다.enumerate() 함수는 주어진 시퀀스(리스트, 튜플, 문자열 등)의 각 요소에 대해 인덱스와 값을 순회하면서 반복하는 파이썬 내장 함수이다.이 함수는 보통 for
14.개발언어 사용자 분석 - 데이터 시각화 3
11) np.linspace() 함수는 NumPy에서 사용되는 함수 중 하나로, 지정된 범위 내에서 등간격으로 일정 개수의 값을 생성한다.np.linspace(0, 1, len(unique_devtypes))와 같이 사용하면 0부터 1까지의 범위에서 len(unique
15.개발언어 사용자 분석 - 데이터 시각화 4
16)상자 그림(boxplot)은 데이터의 분포를 시각화하는 데 사용되는 효과적인 도구이다. 상자 그림은 데이터의 중앙값, 사분위수, 이상치 등을 표시하여 데이터의 대략적인 분포를 파악할 수 있도록 도와준다.showfliers 매개변수: 상자 그림(boxplot)에서
16.축구선수 이적시장 분석 - 기초 통계값
head(n)는 데이터프레임의 상위 n개의 열만 보여주는 기능이다. 기본 설정 값은 5로 n에 아무 값도 지정하지 않으면 상위 5개 열이 노출된다. 평균, 중앙값, 최빈값 비교 정규분포 그래프를 사용해 데이터의 구성과 대표값을 파악합니다. Left skew
17.Appendix. Matplotlib
1. Matplotlib 소개 Matplotlib은 파이썬에서 데이터 시각화를 위해서 가장 많이 쓰이는 라이브러리이다. 다양한 유형의 그래프와 plot을 생성해서 데이터를 시각화할 수 있고 데이터 분석 결과를 보여줄 때 매우 유용한 도구이다. > 참고:  1.2 스택 바 차트 (Stacked Bar Chart) 1.3 그룹 바 차트 (Grouped Bar Chart) 1.4 서브 플롯 (Subplot) : pwd 명령어Prompt 명령어 (윈도우 cmd): cd ,Python 함수: os.getcwd() (import os 이후 사용 가능)/ (슬래쉬)를 활용한 path 입력 방법이다. 이 상태 그대로 read_c
22.Appendix. 데이터 정보 확인
object: 기본적인 연속형, 범주형 데이터가 아닌 데이터들을 표현 (대부분 string<문자열>인 경우가 많다)int: 정수형 데이터float: 실수형 데이터datetime: 날짜형 데이터category: 범주형 데이터예시:예시:\*return_count 등의
23.Appendix. 데이터 나누기
path_or_buf: 저장할 경로sep: 구분자, default는 ','이다.index: index를 첫 컬럼으로 저장할지 말지 결정function (함수)를 사용하는 이유:코드의 재사용을 위해 사용def를 통해서 만들 수 있음변수(parameter) 전달(a)와 같
24.Appendix. 상관계수와 상관관계

pandas의 상관계수는 'pearson', 'kendall', 'spearman' 세가지 알고리즘을 선택할 수 있다.default로 피어슨 상관계수를 사용한다.분자는 x, y 각각의 값이 평균에 비해서 어느 정도인지를 곱해준다. 즉, 특정 x의 값이 평균 X의 값보다
25.Appendix. Heatmap으로 상관계수 시각화
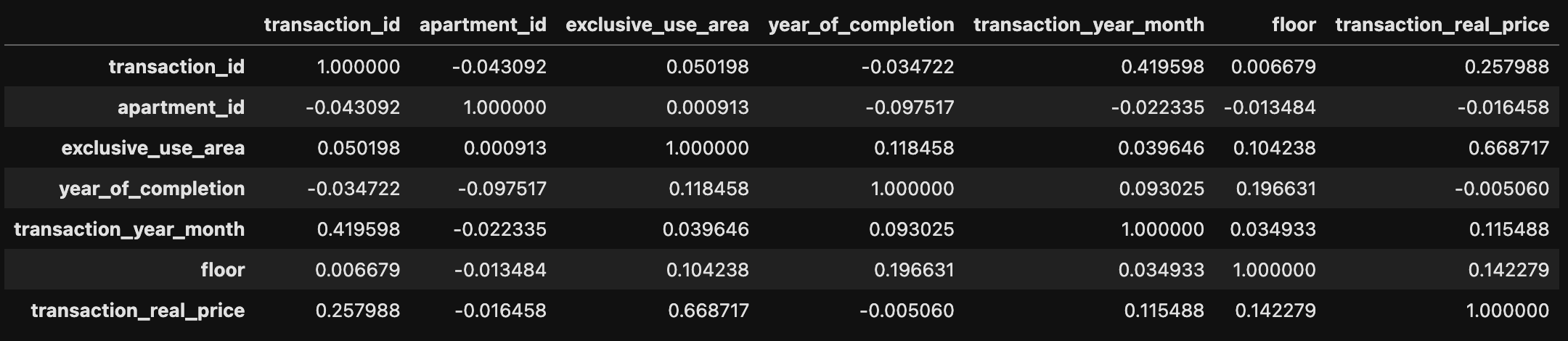
data: heatmap을 그릴 데이터vmin: 최소값vmax: 최댓값camp: 그림을 그릴 색조합annot: 데이터 표기 (bool)fmt: 표기 데이터의 형식시계열 데이터는 시간 순서에 따른 데이터 포인트의 연속으로 구성된 데이터이다. 각 데이터 포인트는 특정 시간
26.Appendix. 수치형 데이터 집합 범주 확인
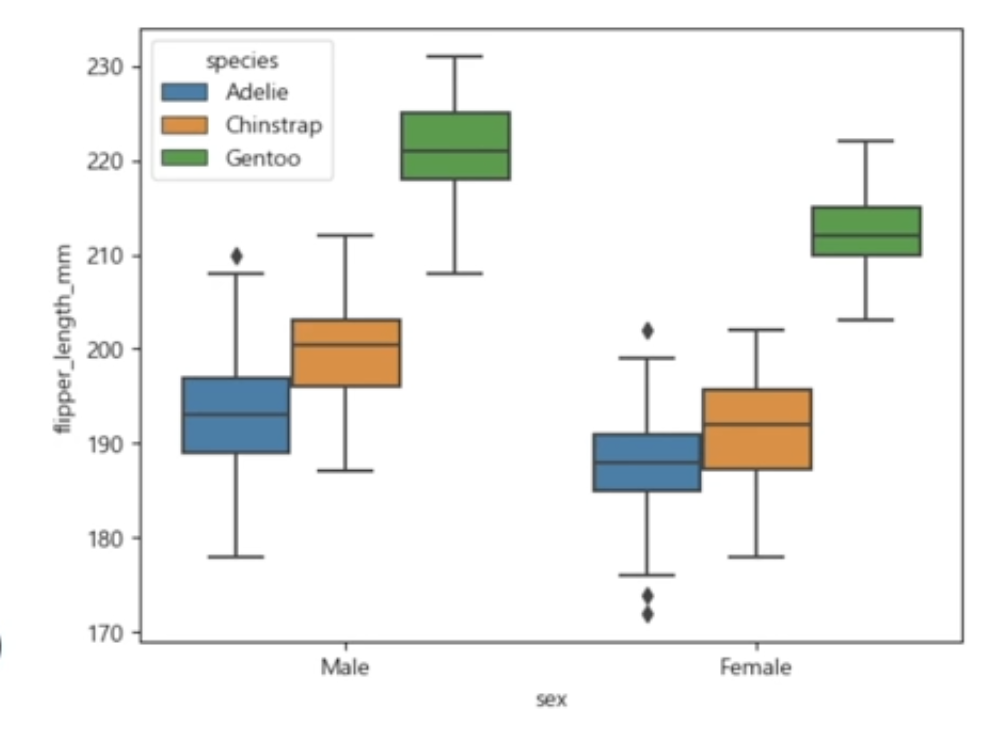
data: 사용할 데이터x, y: x와 y축hue: 종류sym: symboldocs에 특별히 나와있지 않음앞에 색 (r, b 등)뒤에 모양 (s: 네모, o: 동그라미, +: + 모양)
27.Appendix. Scatterplot
1. Scatterplot 1.1 seaborn.scatterplot > data: 적용할 데이터 x, y: x, y축 값 hue: 색상 나눌 값 size: 사이즈 정할 값 sizes: 사이즈의 범주 legend: 범례 확인 표 유무 1.2 plotly.expr
28.Appendix. Folium 라이브러리
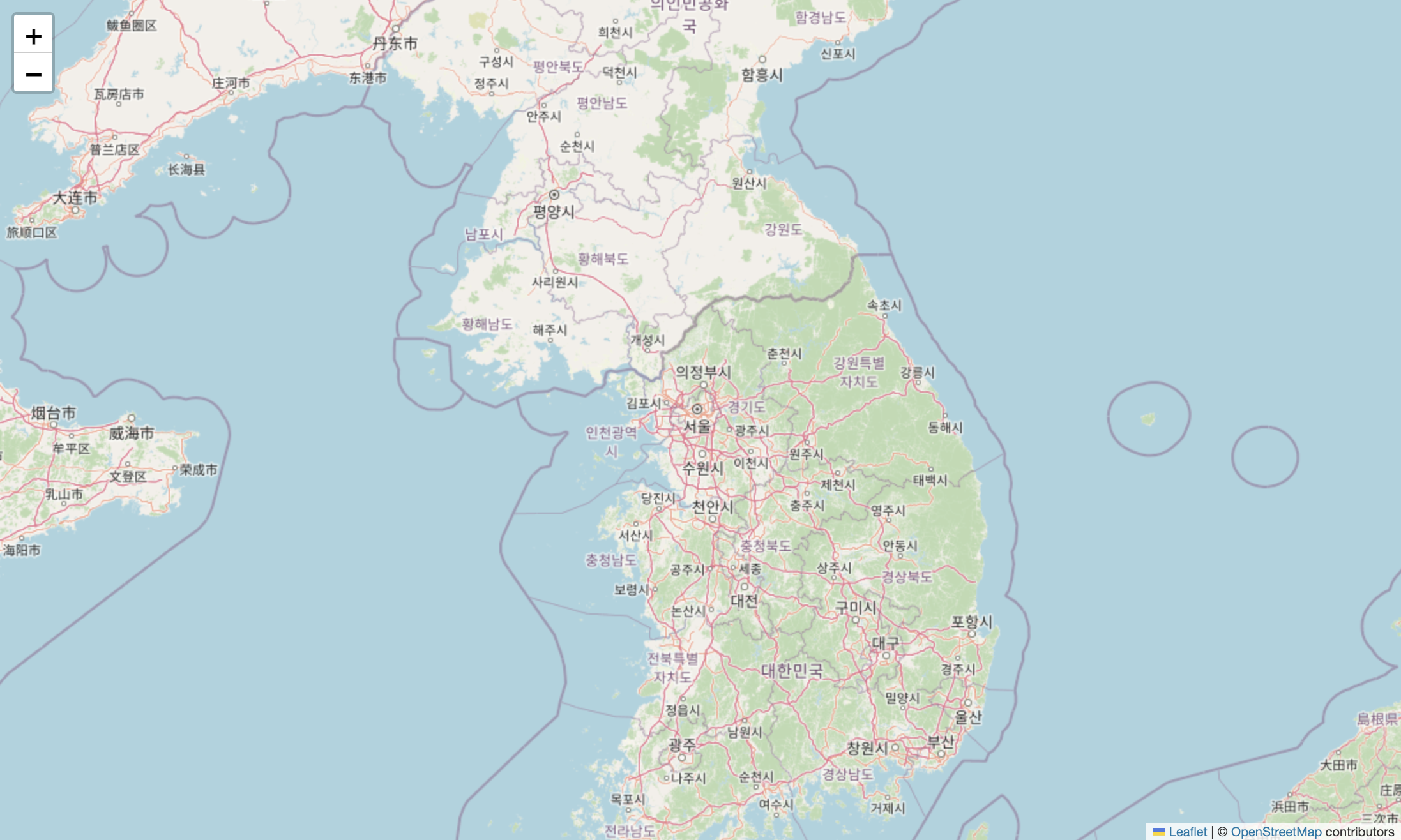
지도를 그리는 역할 location에 좌표를 써 넣으면 됨특정 위치에 동그라미를 그려줌location: 그릴 원심의 위치radius: 원의 크키popup: 마우스를 올려놨을 때(hover) 나오는 팝업의 메시지CircleMarker는 말 그대로 그림만 그려주고 아무곳에
29.Appendix. Broadcasting
차원이 작은 행렬 (또는 value)의 차원을 키워서 차원이 큰 행렬에 맞춰서 계산한다.예시 1:다음과 같이 계산을 하면 list에서는 오류가 나지만, np.array 또는 pd.Series(pd.DataFrame)에서는 \[3, 4, 5]로 값이 나온다.아래와 같이
30.Appendix. 새로운 데이터 불러와서 확인
index, columns: 인덱스, 컬럼의 이름을 바꿈 dict 형태로 기입left, right: 합칠 데이터 프레임how: 합칠 방식inner: 양 쪽 다 있는 경우에만 합침outer: 양 쪽 중 하나만 있는 경우에 합침 (만약 없는 쪽에 df의 값들을 np.nan
31.결측치 처리
DataFrame 기준으로 np.nan, python 기준으로 None, JSON 기준으로 null 등 결측치 상태 그대로 두고 진행한다.많은 양의 데이터에서 계절성, 추세 등 시계열 분석할 때 사용 가능하지만 대부분의 알고리즘이 결측치를 처리 못하는 경우가 있음결측치
32.Appendix. 샘플링 기법
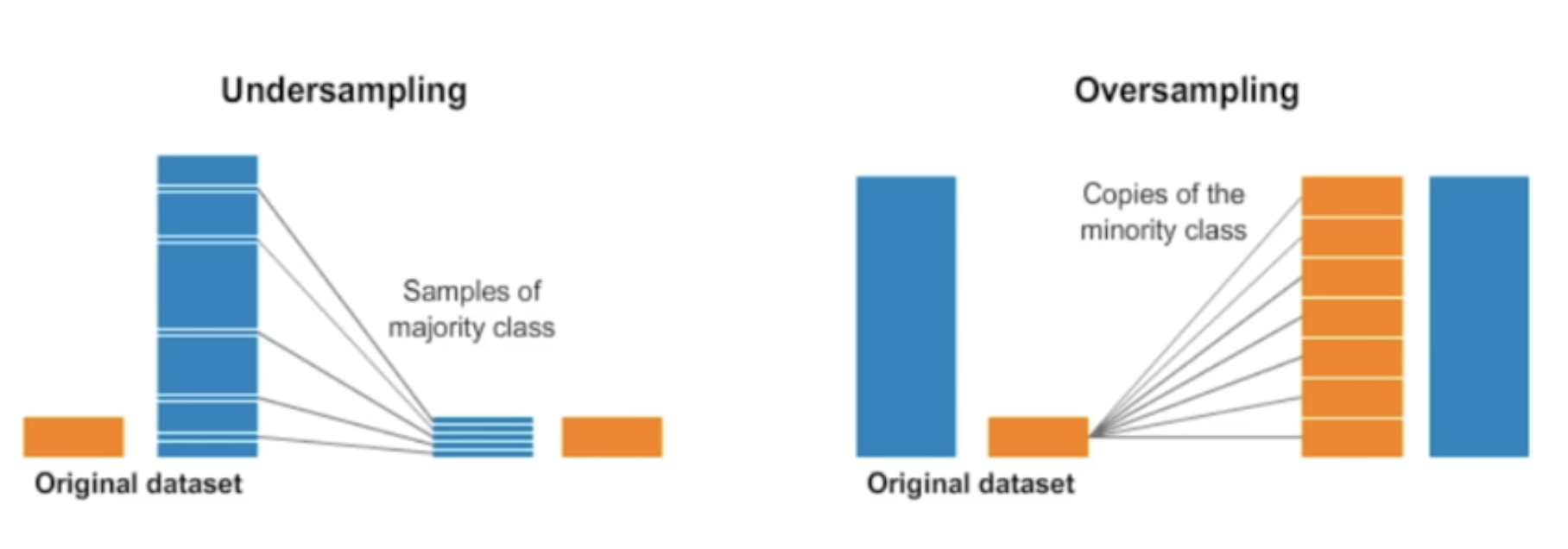
오버샘플링(Oversampling)은 소수 클래스의 샘플 수를 증가시켜서 데이터셋 클래스의 균형을 조절하는 방법이다.이를 통해서 소수 클래스의 정보를 더 많이 활용하게 되어서 모델이 더 정확하게 학습되거나 더욱 다양하게 데이터를 활용할 수 있는 장점이 있다.언더샘플링(
33.RFM (Recency, Frequency, Monetary Value)
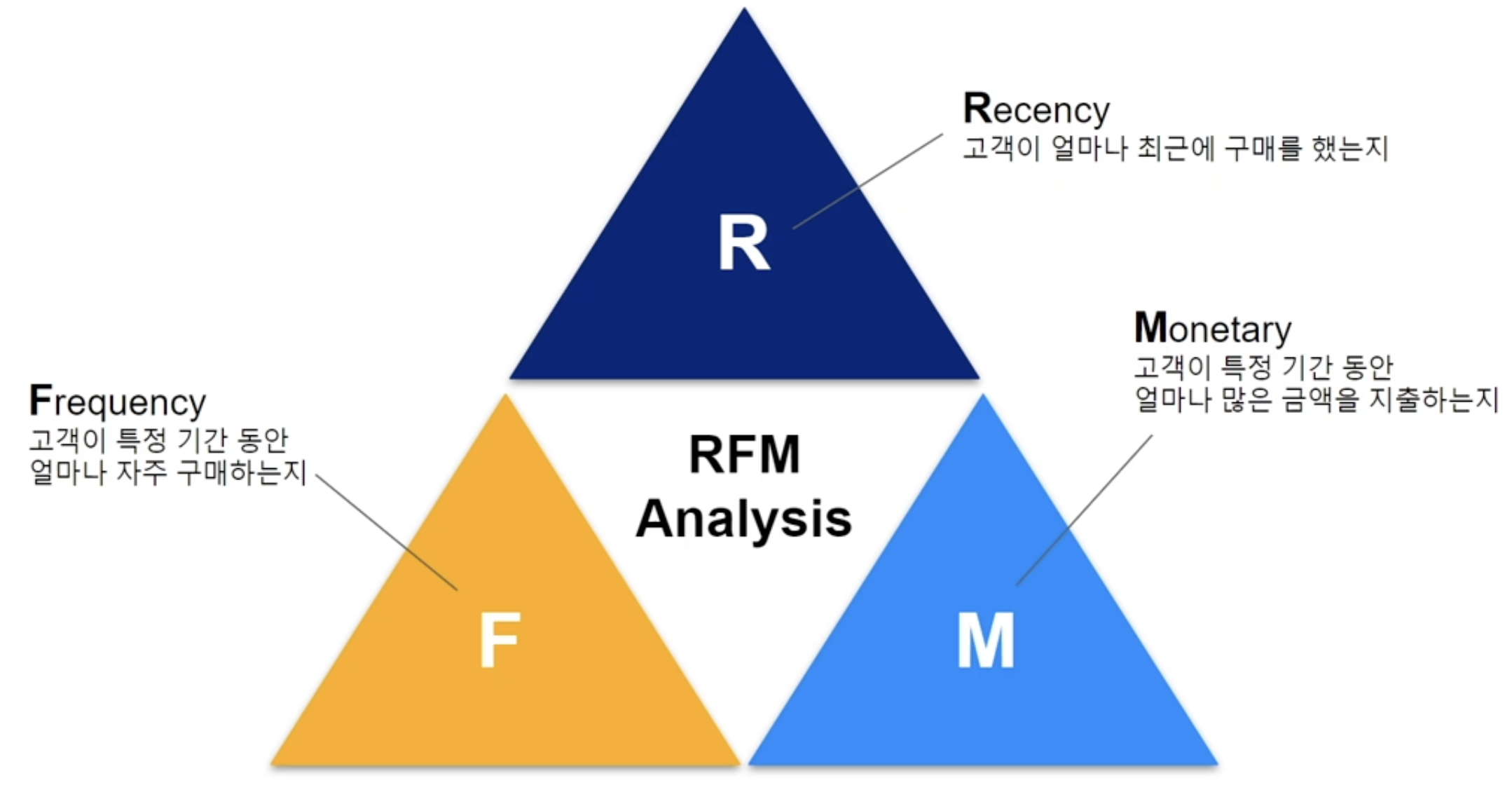
RFM 분석은 고객 세분화, CRM 등에 활용되는 마케팅 기법 중 하나로, Recency, Frequency, Monetary 요소를 기반으로 고객을 세분화하고 그룹화하는 방법을 제공한다. 이를 통해 고객을 명확하게 이해하고, 타겟팅 및 마케팅 전략 최적화에 활용할 수
34.CLTV (Customer Lifetime Value)
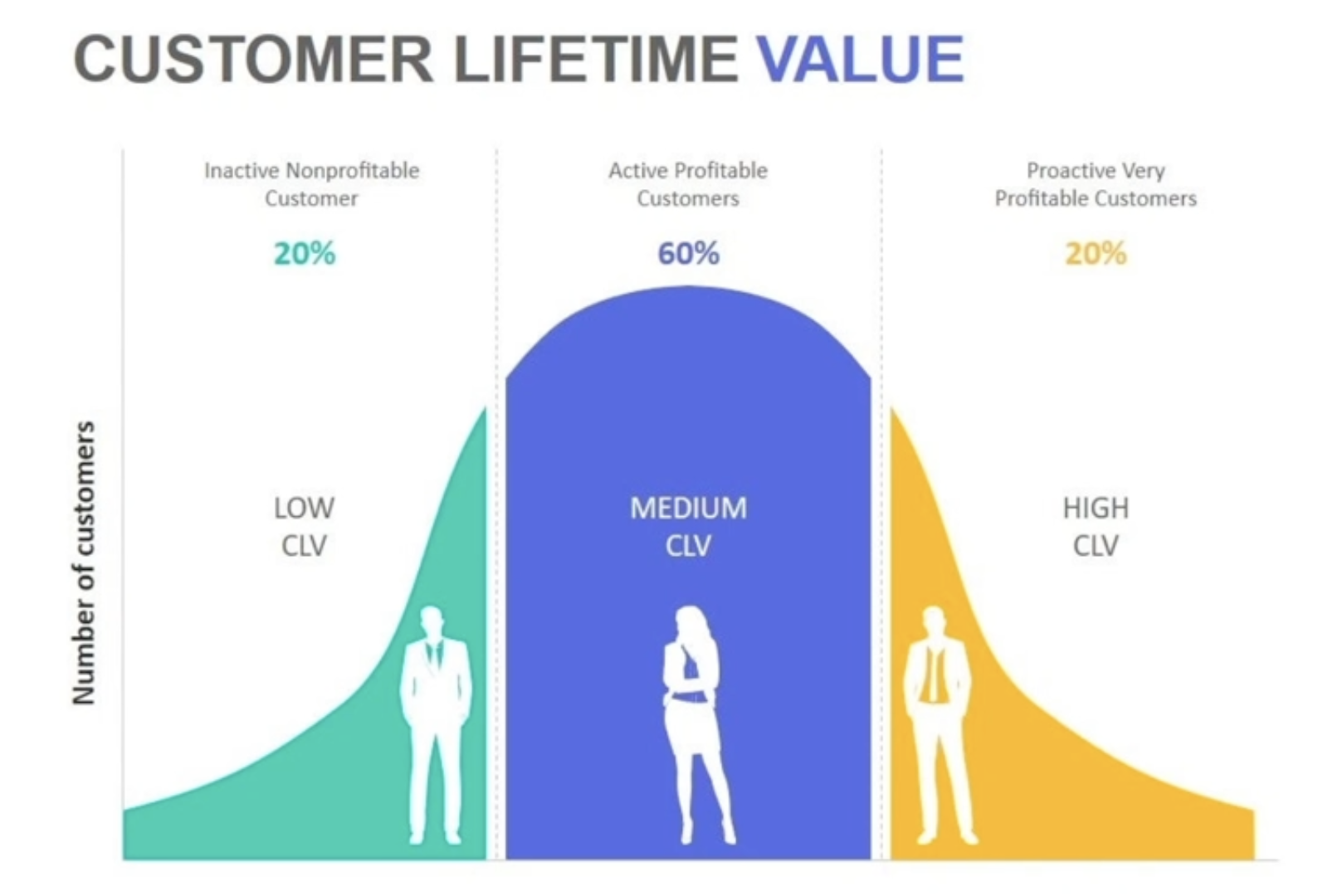
CLTV(Customer Lifetime Value)는 고객 한 명에게서 기대할 수 있는 총 수익을 나타내는 지표이다. 사업자는 이를 통해 고객의 가치를 평가하고, 맞춤형 마케팅 전략을 수립할 수 있다.예를 들어, 한 고객이 n년 동안 n번 구매를 했고 그 과정에서 n
35.K-means Clustering
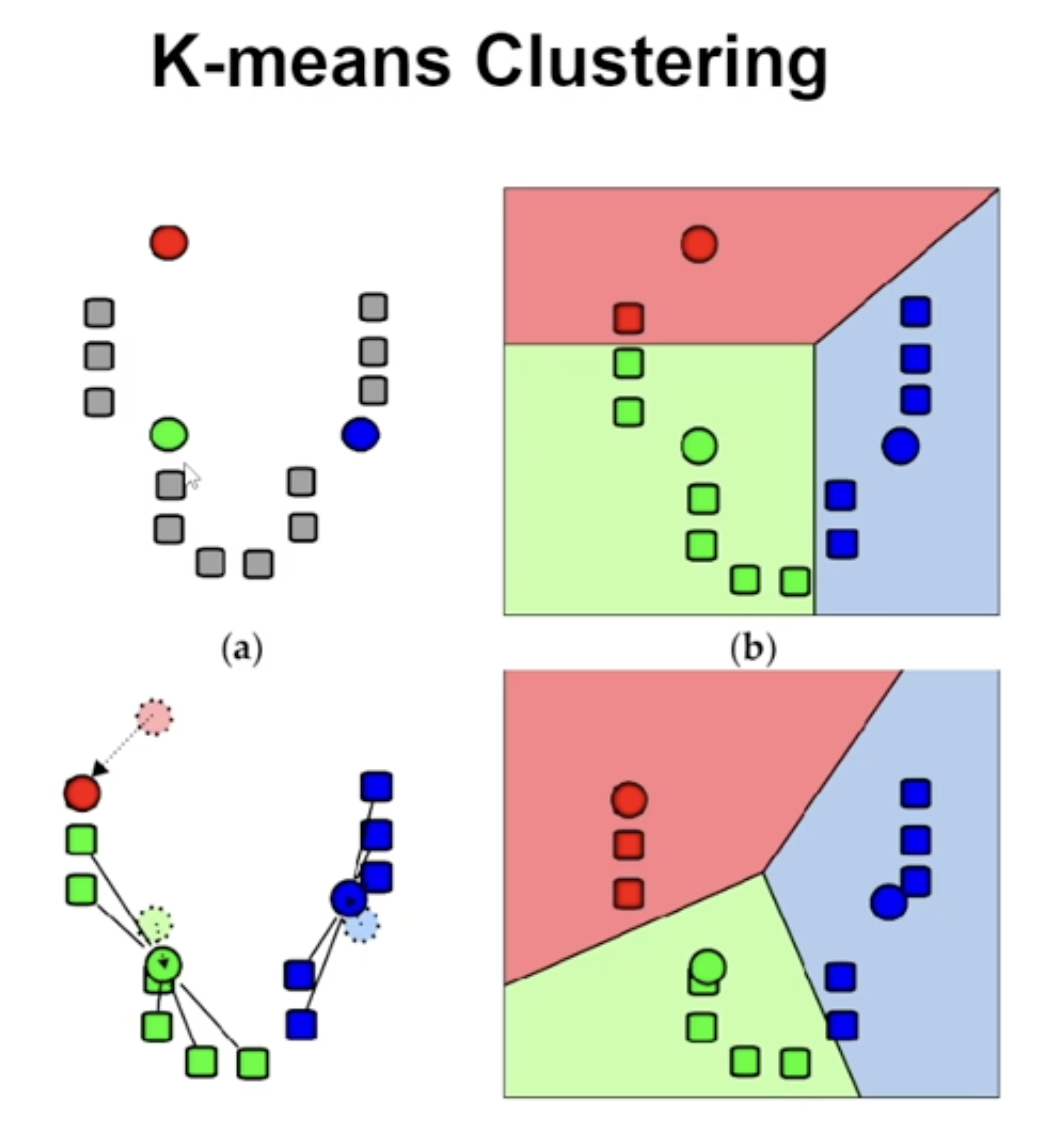
위의 그래프를 보면 A 등급에 속해있는 데이터들이 큰 값 그대로 표시되고 작은 값들은 작게 표시가 되었기 때문에 패턴을 정확히 파악하기가 힘들다. 따라서 아래와 같이 로그 스케일링을 하면 더 정확한 패턴을 파악할 수 있다.K-means 클러스터링은 비지도 학습 알고리즘
36.lifetimes 패키지
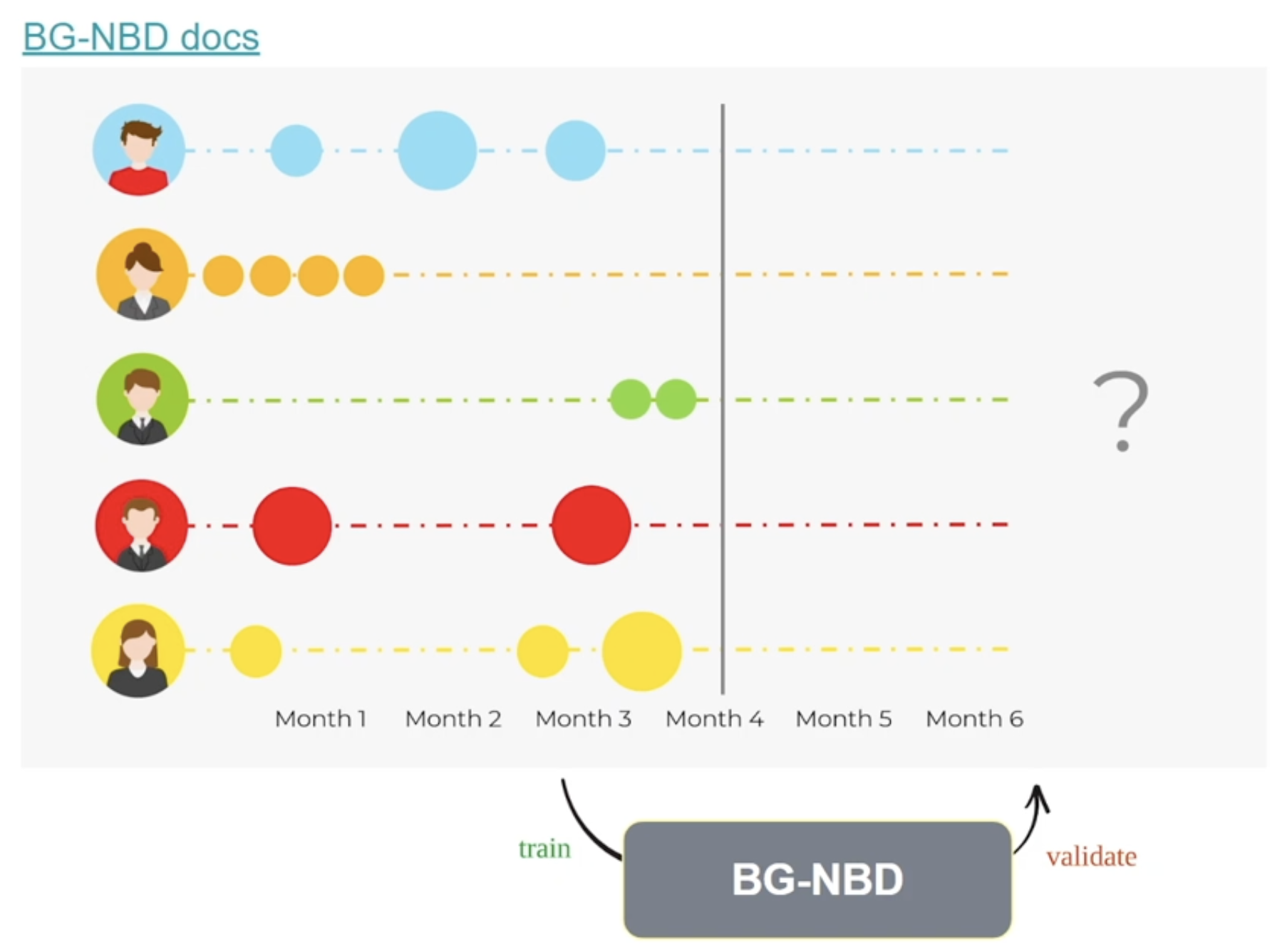
lifetimes는 파이썬 오픈소스 라이브러리로, 고객 생애 가치(CLTV)와 고객 로열티 관련 데이터를 분석하고 모델링할 때 사용된다. 이 패키지를 통해 CRM 관련 기법과 지표를 쉽게 구할 수 있다.BG/NBD(Beta Geometric Negative Binomi
37.웹 데이터 수집 - Selenium
1. Selenium 웹 브라우저 자동화 도구 파이썬 코드를 이용해서 웹 브라우저를 제어 웹 페이지 열기, 텍스트 입력, 클릭 등 웹사이트 테스팅 데이터 수집 1.1 Selenium 필요한 이유 싼 주유소 찾기 (오피넷 페이지)의 URL 정보가 바뀌지 않는다. 따
38.웹페이지 구성
1. 웹페이지의 구성 HTML, CSS, JavaScript는 웹 개발의 세 가지 주요 언어로 각각 다른 역할을 한다. > 웹페이지 = 컨테이너 하우스 > 컨테이너 하우스(구조)가 있다 != 도로명 주소지가 있다 HTML: 웹 페이지의 구조와 콘텐츠를 정의한다.
39.HTML (HyperText Markup Language)
1. HTML HTML은 문서(웹페이지)의 구조를 나타내는 마크업 언어다. 1.1 HTML의 배경 창시자: 팀 버너스-리 (Tim Berners-Lee) 영국의 컴퓨터 과학자, 웹의 아버지 URL, HTTP, HTML 최초 설계와 구현 기원 HTML은 1990년
40.HTML로 이력서 만들기
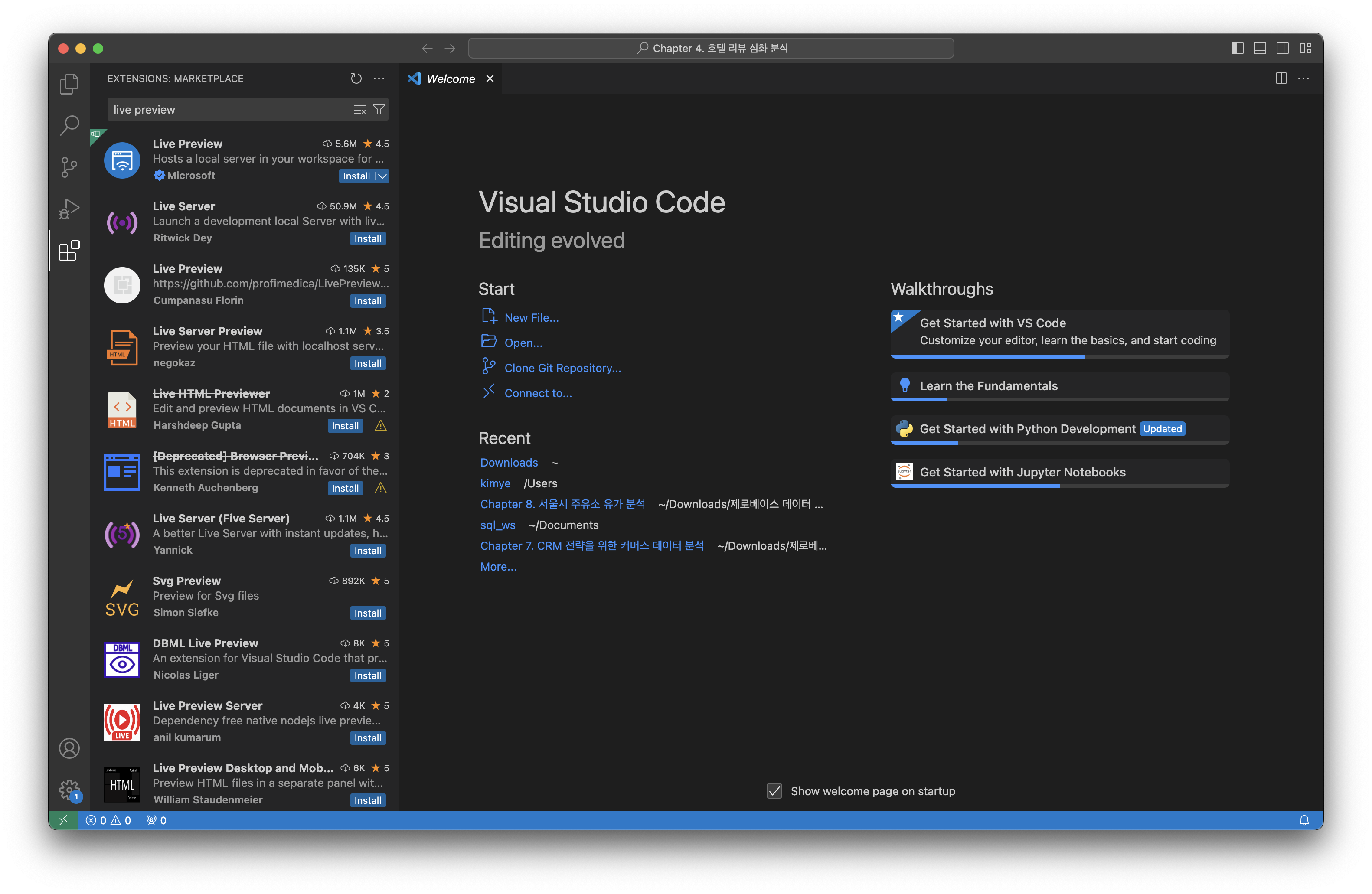
1) VS Code 실행2) 왼쪽 패널에서 확장자 클릭3) 검색창에 Live Preview 입력4) Live Preview 확장자 설치Live Preview 확장자는 HTML 파일을 라이브로 VSCode 내에서 미리보기가 가능하다.
41.CSS (Cascading Style Sheets)

CSS는 HTML, XML 등의 마크업 언어로 작성된 문서를 꾸미는 스타일링 언어로 웹 페이지의 레이아웃, 폰트, 색상, 간격 등을 제어한다.인라인 스타일은 HTML 태그 내의 style 속성을 사용한다.우선순위가 가장 높으며 해당 요소에만 적용된다.대부분의 HTML
42.개발자 도구
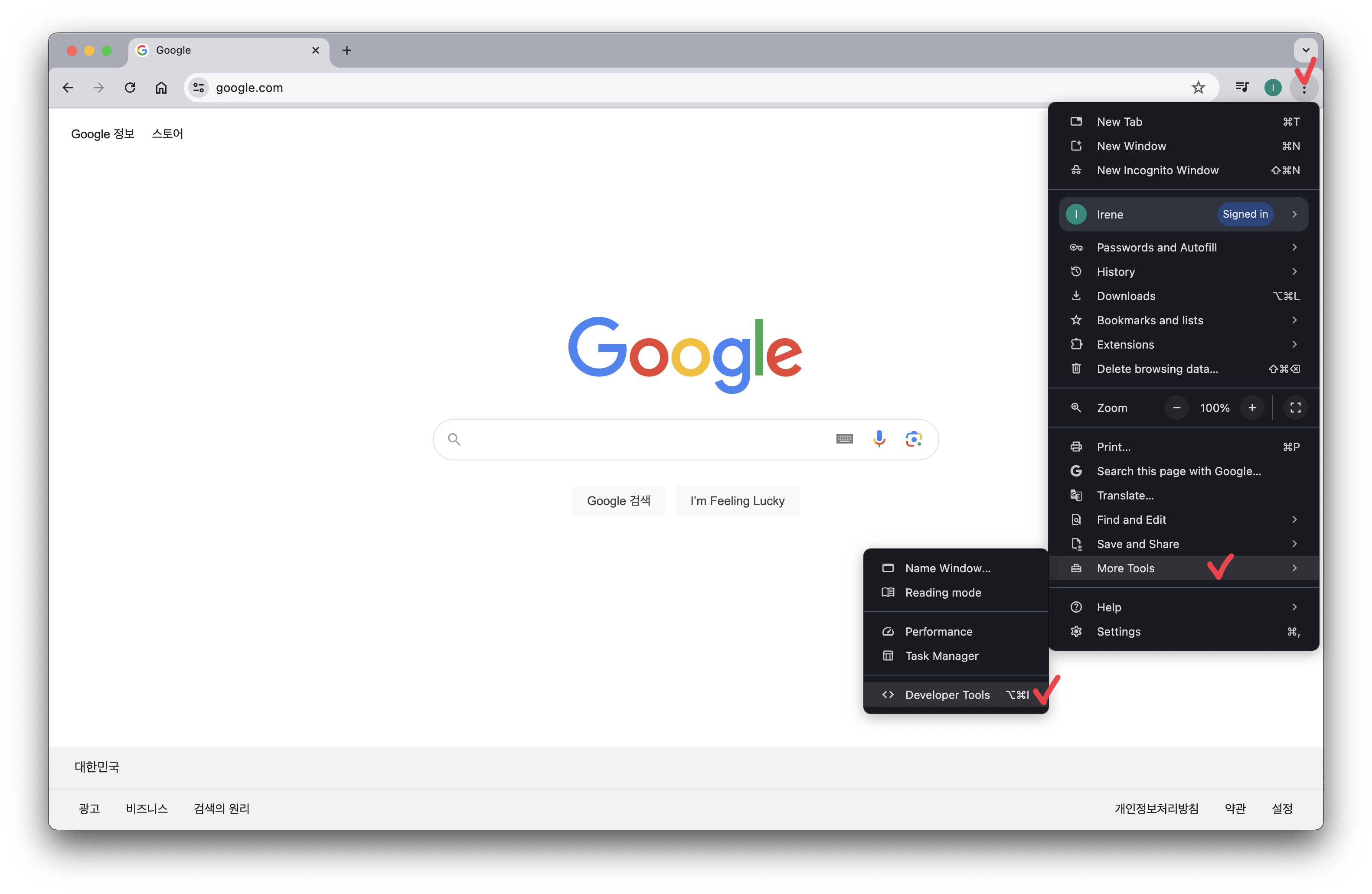
웹 브라우저에는 웹 페이지의 작동 원리를 이해하고 디버깅할 수 있는 내장 도구가 포함되어 있다. 크롬, 파이어폭스, 사파리, 엣지 등 주요 브라우저는 모두 개발자 도구(DevTools)를 제공한다. 이 도구들의 UI나 기능에는 약간의 차이가 있을 수 있지만, 기본적인
43.CSS로 이력서 꾸미기
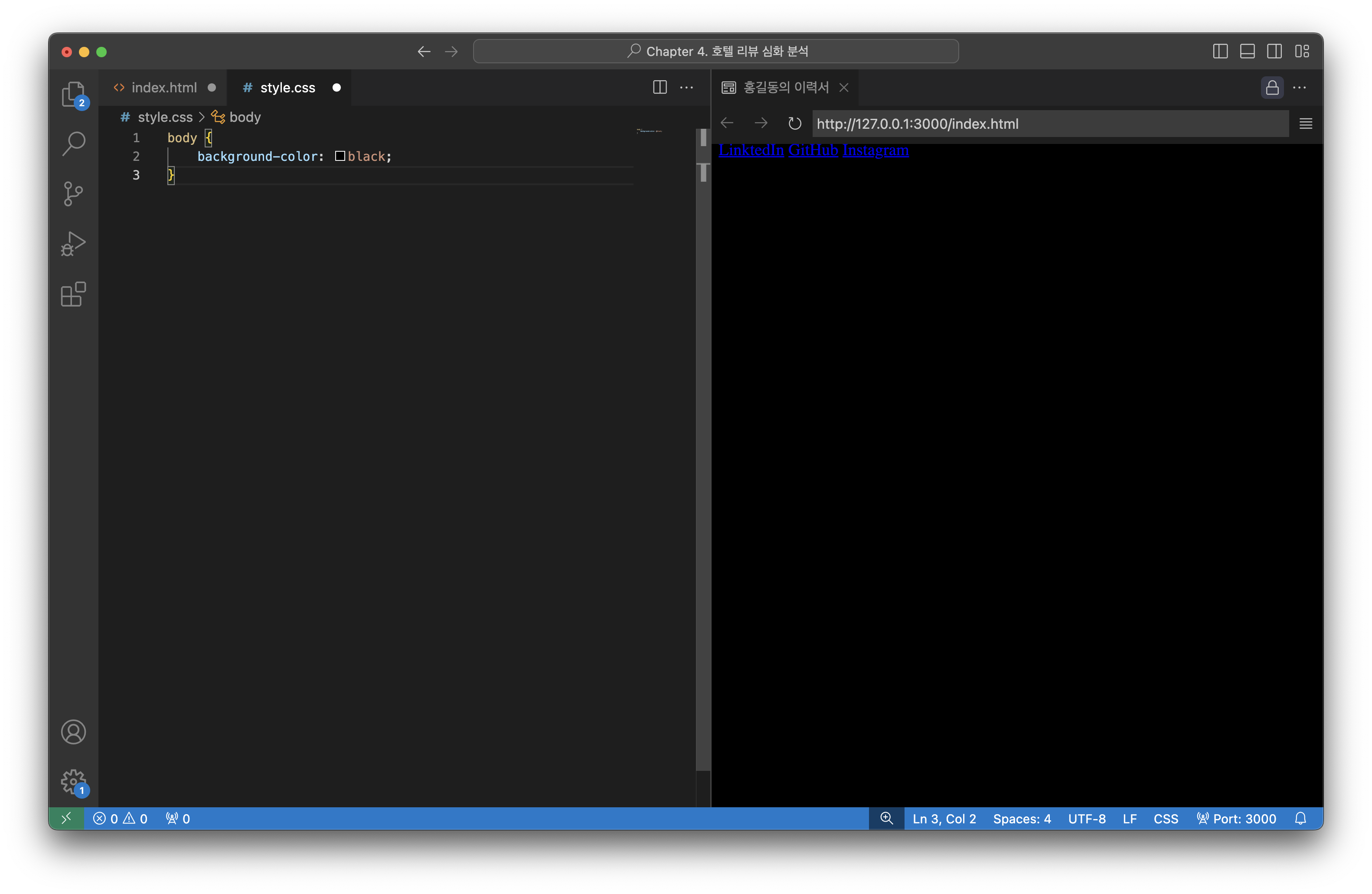
1) css 파일 생성2) HTML 파일의 <head> 섹션에 아래와 같이 CSS 파일 연결3) CSS 파일에 아래와 같이 내용 작성하여 배경이 검정색으로 표시되는지 확인4) 오른쪽 창 Line Preview에서 링크 복사5) 구글 크롬 열어서 복사한 링크 붙여넣
44.선택자 (Selector)
1. 선택자 (Selector) CSS 선택자는 HTML 문서의 요소를 선택하여 스타일을 적용할 수 있도록 하는 방법이다. 선택자는 다양한 유형이 있으며, 각 선택자는 특정 기준에 따라 요소를 선택한다. 1.1 일반 선택자 (Type Selector) 일반 선택자
45.웹페이지 배포하기
직접 서버를 구축하고 관리제어력 높으나 관리가 복잡 (서버 유지보수, 보안 등)Apache나 Nginx 같은 웹 서버 소프트웨어 사용이미 구축되어있는 서버를 일정기간, 원하는 만큼 빌려서 사용확장성과 관리 편의성이 뛰어나지만 비용이 들 수 있음Amazon AWS, Mi
46.웹페이지의 동작 과정 (Feat. Python)
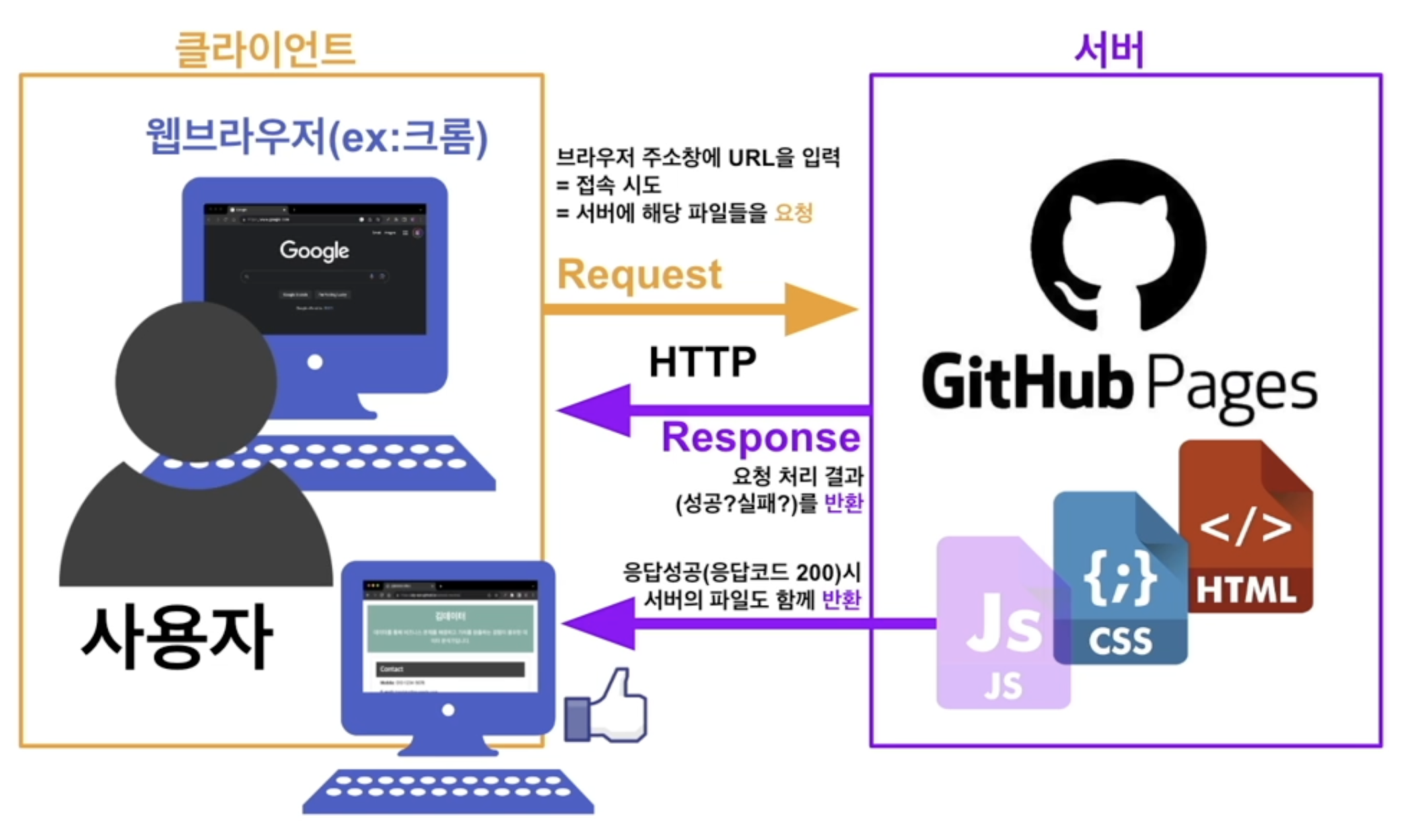
웹페이지가 동작하는 과정은 사용자가 웹 브라우저를 통해 웹사이트를 요청하고, 서버가 해당 요청을 처리하여 응답을 보내는 일련의 단계를 포함한다.URL은 웹 자원의 위치를 지정하는 문자열이다. 기본적인 구성 요소는 다음과 같다.HTTP: 데이터를 암호화하지 않고
47.Python HTTP Clients: Requests 라이브러리

Python HTTP Clients는 Python에서 웹 서버와 HTTP/HTTPS 프로토콜을 사용하여 데이터 송수신을 수행하는 도구이다. 이는 웹 스크래핑, API 호출, 웹 서비스 통신 등 다양한 용도로 활용된다.종류:1) requests:사용하기 쉽고 다양한 HT
48.Python HTML Parser: BeautifulSoup 라이브러리

1. Python HTML Parser 1.1 BeautifulSoup 사용하기 쉬움, 문서가 잘 작성되어 있고 커뮤니티 지원이 좋음. 깨진 HTML을 잘 처리할 수 있음 1.2 lxml 매우 빠르고, XPath 같은 고급 쿼리를 지원. 단, 문서가 비교적 부족