Q126. Column명을 아래와 같이 변경하기
# 1. sepal_length
# 2. sepal_width
# 3. petal_length
# 4. petal_width
# 5. class데이터프레임의 열 이름을 변경하거나 특정 열에 접근할 때는 df.colums 명령어를 사용하면 된다.
df.columns = ['sepal_length','sepal_width', 'petal_length', 'petal_width', 'class']
df.head()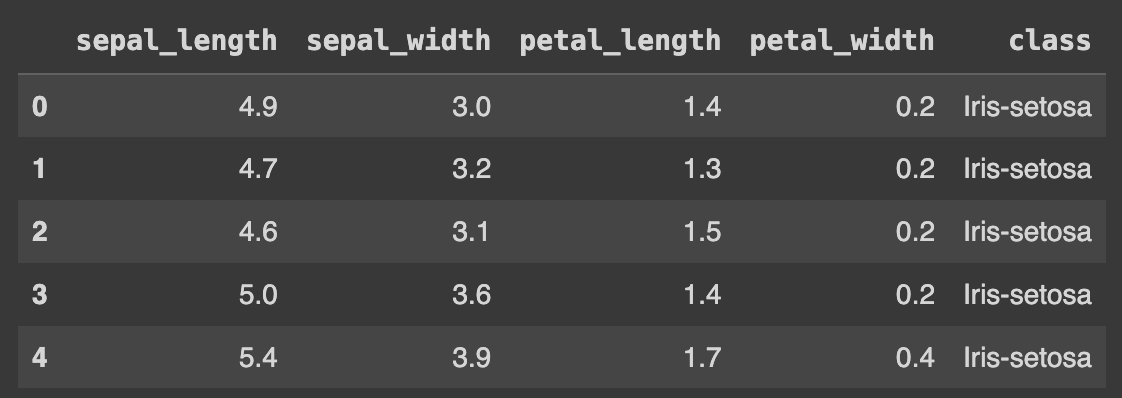
Q127. Column별 NA값이 존재하는지 확인하기
df.isnull().sum()
# 결과값:
# speal_length 0
# sepal_width 0
# petal_length 0
# petal_width 0
# class 0
# dtype: int64
df.isnull()은 데이터프레임(df)의 각 원소가 결측값인지 여부를 나타내는 불리언(boolean) 값으로 구성된 동일한 모양(shape)의 데이터프레임을 반환한다.
sum()은 불리언 값에서 True는 1로, False는 0으로 처리하여 각 열의 결측값 개수를 더한다.
결과적으로df.isnull().sum()은 각 열에 대한 결측값의 총합을 반환한다.
Q128. 'petal_length'의 10번째부터 29번째 행의 값을 NaN으로 변환하기
df.iloc[9:29,2] = np.nan # petal_length는 2번째 컬럼에 있음
df.head(30)
# print(df.petal_length.isnull().sum())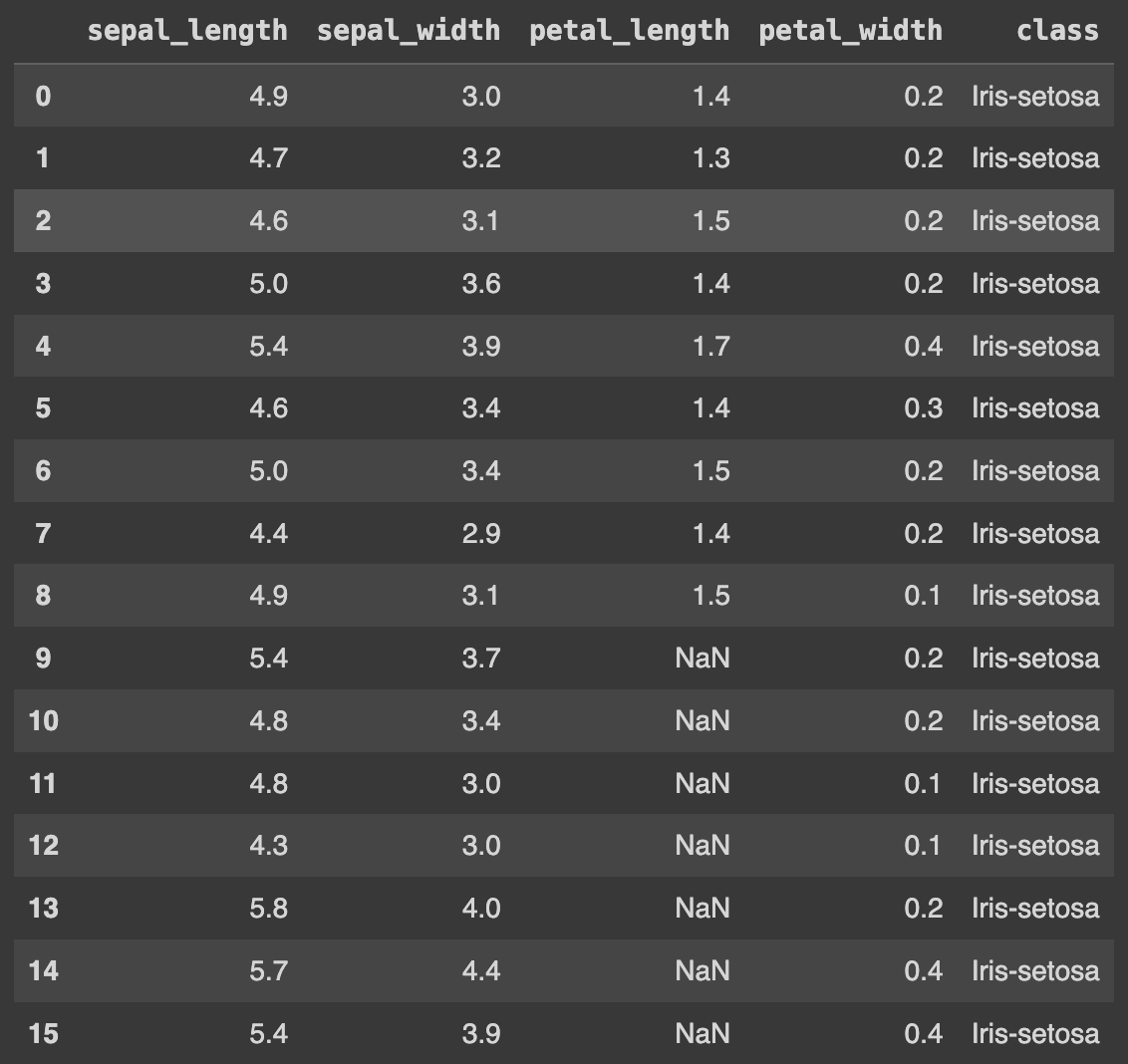
df.iloc[9:29, 2] = np.nan: 이 부분은 데이터프레임(df)의 10번째 행(인덱스 9)부터 30번째 행(인덱스 29 전까지)까지의 범위에 해당하는 행들의 "petal_length" 열(인덱스 2)에 NumPy의 np.nan을 할당한다. 이는 해당 범위 내의 행들의 "petal_length" 값을 결측값으로 설정하는 것을 의미한다.
Q129. Nan값을 다시 1로 채워 넣기
df.petal_length.fillna(1, inplace=True)
print(df.petal_length.isnull().sum())df.petal_length.fillna(1, inplace=True): 이 부분은 데이터프레임(df)의 "petal_length" 열에 있는 결측값을 1로 채운다. fillna(1)은 결측값을 1로 대체하는 메서드이다. inplace=True는 결과를 원래 데이터프레임에 반영하도록 지정한다. 따라서, "petal_length" 열의 결측값이 모두 1로 대체된다.
Q130. Class 컬럼을 삭제하기
# df = df[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']]
del df['class']
df.head()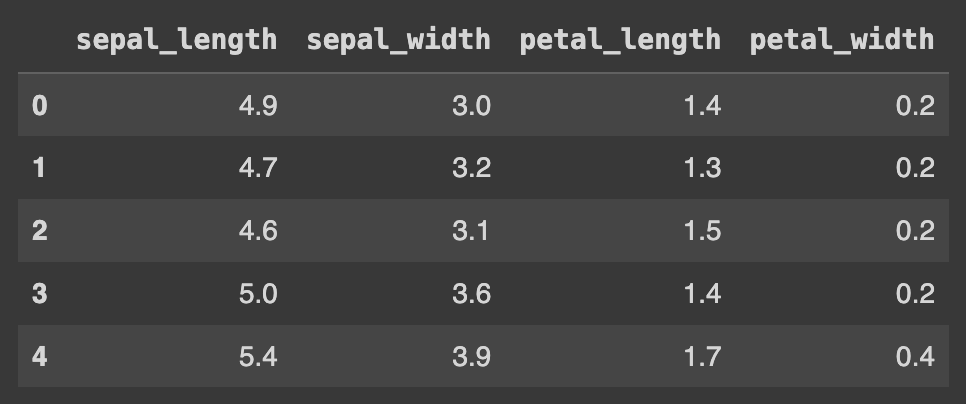
특정 컬럼을 삭제하는 대신 해당 컬럼을 재할당하여 변경하는 것은 데이터를 보다 유연하게 다룰 수 있다. 컬럼을 삭제하면 해당 정보를 완전히 잃게 되지만, 재할당하면 필요에 따라 원래 데이터를 사용할 수 있다. 데이터를 보존하면서도 필요한 정보를 조작하고 수정할 수 있어서 유용하다.
Q131. 3개의 행에 대해서 모두 Nan값으로 변경하기
df.iloc[0:3,:] = np.nan
df.head()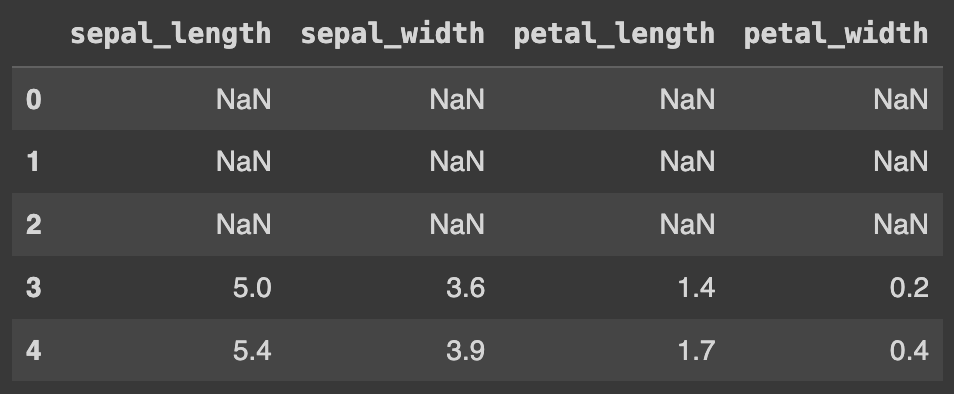
Q132. NaN을 가지고 있는 행 삭제하기
df = df.dropna(how='any')
df.head()`dropna()` 메서드는 데이터프레임에서 결측값을 포함한 행(row)이나 열(column)을 삭제하는 데 사용된다. 기본적으로는 결측값을 포함한 행이 모두 삭제된다.
df.dropna(axis=1): 이는 데이터프레임(df)에서 결측값을 포함한 열(column)을 삭제한다.
여기서 df.dropna(how='any')는 데이터프레임(df)에서 결측값이 있는 행(row)을 제거하는 메서드이다. how='any'는 결측값이 행에 하나라도 있는 경우 해당 행을 삭제하라는 것을 의미한다. 즉, 결측값이 하나라도 존재하는 행을 제거하고, 나머지 행들을 반환한다.
131번 문제에서 NaN 값이 있던 0, 1, 2번째 행들은 삭제가 되고 3번째 행들부터 출력이 된걸 확인할 수 있다.
Q133. index를 다시 0부터 시작할 수 있도록 수정하기
df = df.reset_index(drop = True)
df.head()
reset_index(drop=True)메서드는 데이터프레임의 인덱스(index)를 다시 설정하고, 기존 인덱스를 삭제하는 역할을 한다. 이 메서드를 호출하면 기존 인덱스는 새로운 숫자로 이루어진 인덱스로 대체된다.
drop=True: 이 옵션은 기존 인덱스를 삭제하고 새로운 인덱스를 생성할 때, 기존의 인덱스를 데이터프레임의 일반적인 열로 추가하지 않도록 한다. 이 옵션을 사용하면 기존 인덱스가 데이터프레임에서 삭제된다.
