import pandas as pd
# visualization libraries
import matplotlib.pyplot as plt
import seaborn as sns
# print the graphs in the notebook
%matplotlib inline
# set seaborn style to white
sns.set_style("white")
matplotlib.pyplot은 파이썬에서 데이터 시각화를 위해 널리 사용되는 라이브러리인 Matplotlib의 하위 모듈이다. plt라는 별칭을 사용하여 라이브러리에 접근할 수 있다. Matplotlib은 다양한 종류의 그래프를 생성하고 스타일을 지정하는 기능을 제공한다.
seaborn은 Matplotlib를 기반으로 한 파이썬 시각화 라이브러리이다. Seaborn은 Matplotlib보다 사용하기 쉬운 API와 간편한 스타일링 기능을 제공하여 데이터 시각화 작업을 보다 쉽게 수행할 수 있도록 도와준다. Seaborn은 통계 그래픽스와 관련된 다양한 고급 기능을 제공하여 데이터 분석 작업에 유용하게 활용된다. Matplotlib와 함께 사용되는 경우가 많아서 종종 함께 불러오게 된다.
%matplotlib inline은 주피터 노트북(Jupyter Notebook) 환경에서 matplotlib 라이브러리를 사용하여 그래프를 출력할 때 사용하는 매직 명령어이다. 이 명령어를 실행하면 주피터 노트북 셀에서 그래프를 생성하고 바로 출력할 수 있다. 일반적으로는 그래프를 따로 표시하지 않고도 노트북 셀에서 그래프를 확인할 수 있어 편리하다.
sns.set_style("white")은 Seaborn 라이브러리의 기본적인 스타일을 설정하는 메서드이다. 이 코드는 그래프의 배경과 플롯의 격자 라인을 흰색으로 설정한다. Seaborn은 다양한 스타일을 제공하며, 이를 통해 생성되는 그래프의 전반적인 모양을 변경할 수 있다. 다른 스타일 옵션에는 "darkgrid", "whitegrid", "dark", "white", "ticks" 등이 있다.
Q113. 'Unnamed: 0' Column 삭제하기
del df['Unnamed: 0']
df.head()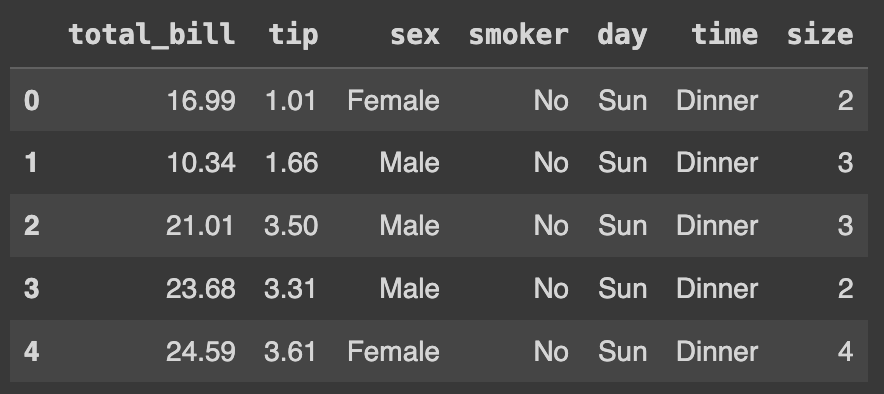
Q114. total_bill에 대해서 히스토그램 그리기
히스토그램(Histogram)은 주어진 데이터의 분포를 나타내는데 사용되는 그래프 종류 중 하나이다. 주로 연속형 데이터의 분포를 시각화할 때 사용되며, 데이터를 구간별로 나눠 각 구간에 속하는 데이터의 빈도를 막대로 표현한다.
bins는 데이터를 나눌 구간(bin)의 개수를 나타낸다. 이 값이 너무 작으면 데이터의 세부 분포를 파악하기 어려우며, 너무 크면 전체적인 분포를 파악하기 어려울 수 있다. 적절한 구간의 개수를 선택하는 것이 중요하다.
ttbill = sns.histplot(df.total_bill);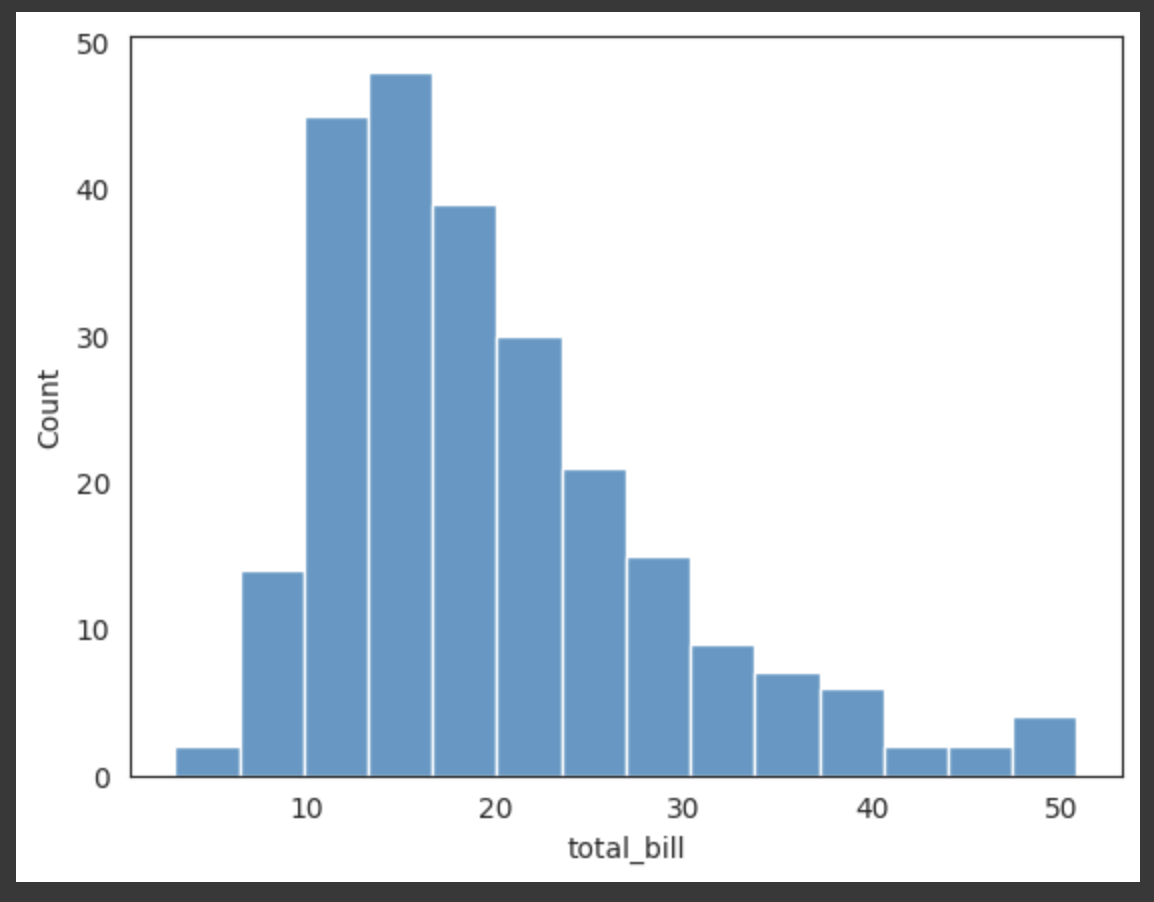
ttbill = sns.histplot(df.total_bill);
# set lables and titles
ttbill.set(xlabel='Value', ylabel='Frequency', title="Total Bill");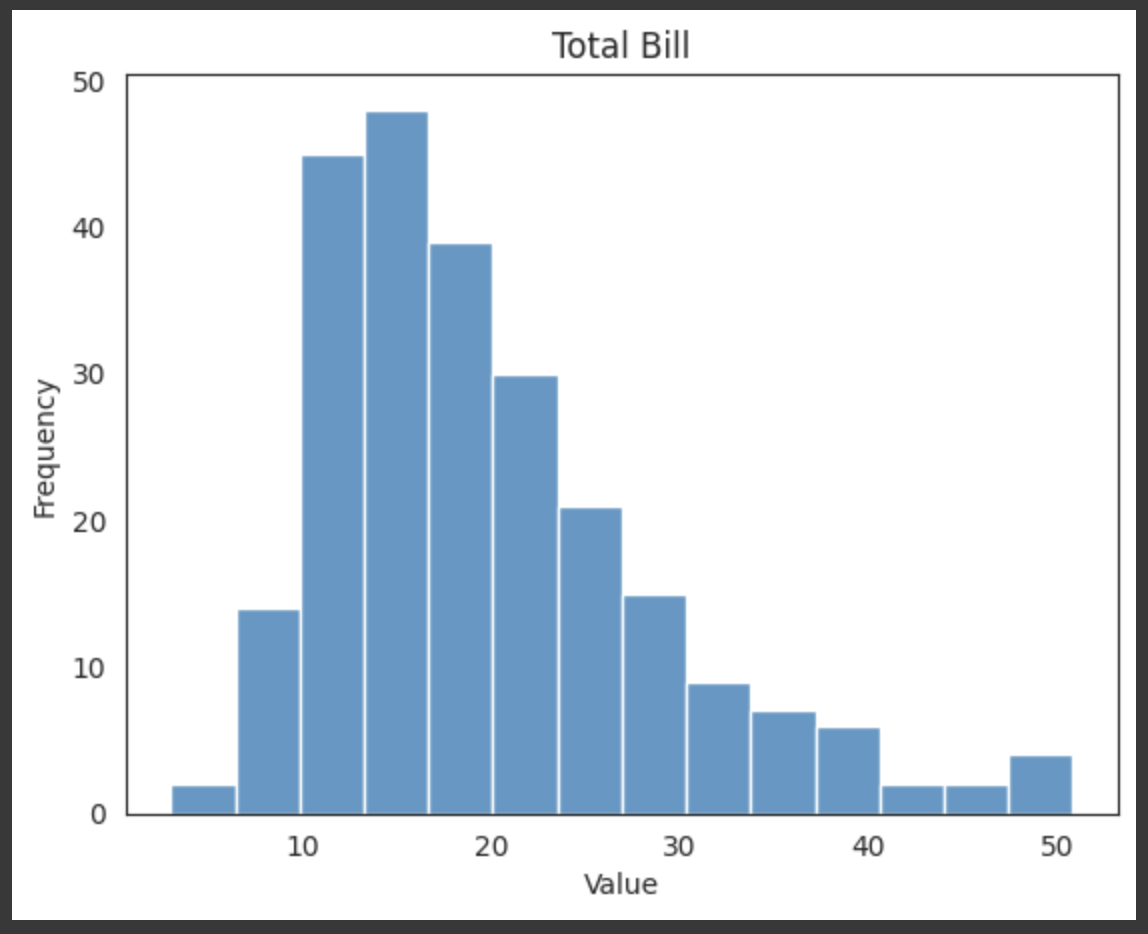
set() 메서드는 Matplotlib 그림 객체의 여러 속성을 한 번에 설정하기 위해 사용된다. xlabel, ylabel, title과 같은 인수를 사용하여 x축 레이블, y축 레이블, 제목을 설정할 수 있습니다.
Q115. total_bill과 tip에 대해서 jointplot 그리기
jointplot()함수는 Seaborn 라이브러리에서 제공하는 함수로, 두 변수 간의 관계를 시각화하는 데 사용됩니다. 이 함수는 가운데에는 산점도(Scatter plot)가 그려지고, x축과 y축에는 각각의 변수에 대한 히스토그램을 함께 보여준다. 이렇게 하면 두 변수의 분포와 상관 관계를 한눈에 확인할 수 있다.sns.jointplot(x='x축 데이터', y='y축 데이터', data=데이터프레임, kind='scatter')
kind매개변수에는 'scatter' 외에도 'reg'(회귀선이 있는 산점도), 'hex'(육각형 산점도), 'kde'(커널 밀도 및 히스토그램) 등의 다양한 옵션이 있다.
sns.jointplot(x ="total_bill", y ="tip", data = df);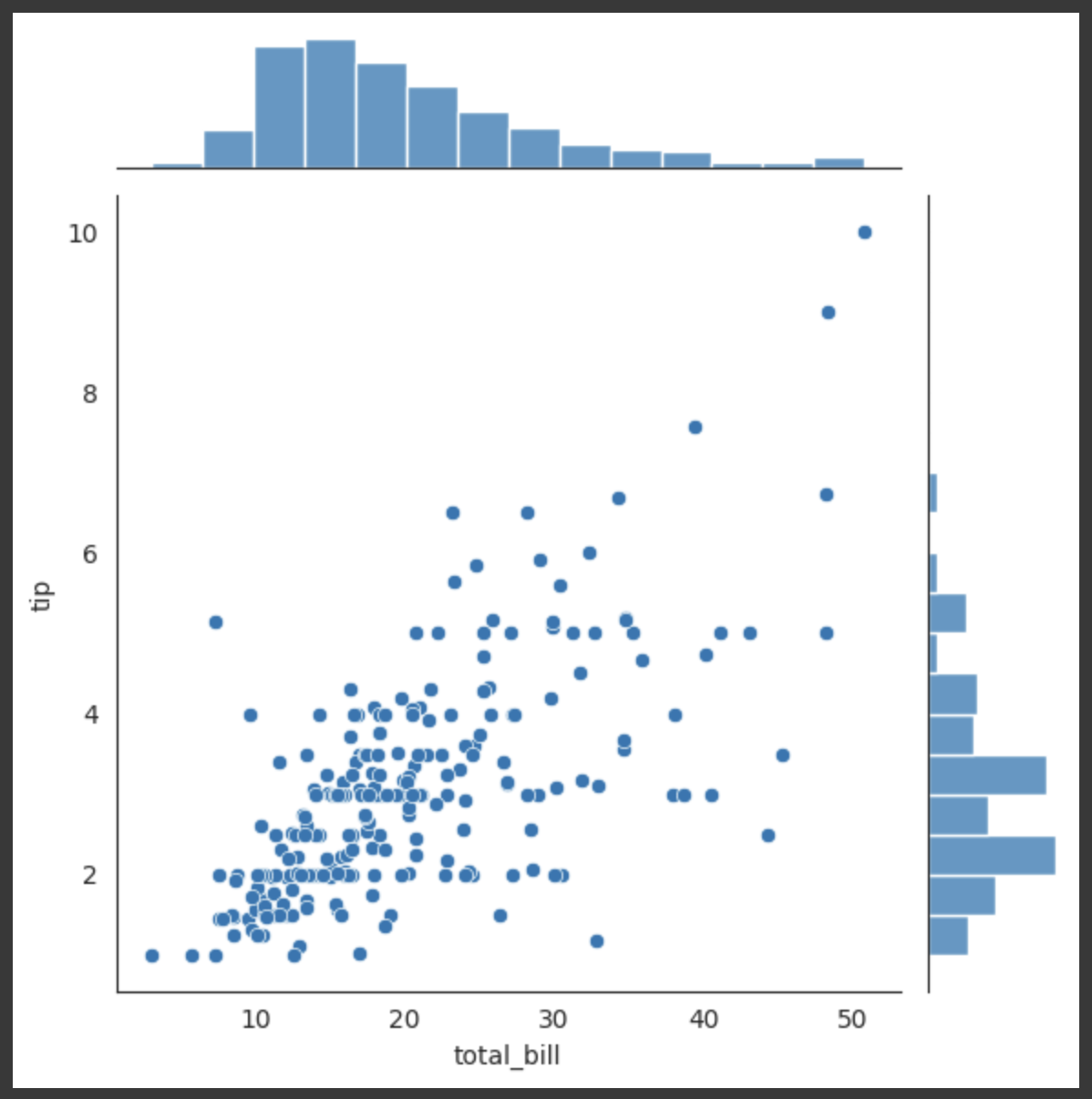
Q116. 모든 연속성 변수에 대해서 pairplot 그리기
pairplot함수는 Seaborn 라이브러리에서 제공하는 함수 중 하나로, 데이터셋의 모든 변수 쌍 간의 관계를 시각화하는 데 사용된다. 이를 통해 변수들 간의 상관 관계 및 분포를 한 눈에 파악할 수 있다.
- 보통 pairplot 함수를 사용할 때는 데이터프레임의 모든 열을 대상으로 하며, 각 열의 조합에 대한 산점도가 그려진다. 이렇게 함으로써 데이터셋 내의 각 변수가 다른 변수들과 어떻게 관련되어 있는지를 시각적으로 파악할 수 있다.
sns.pairplot(data=데이터프레임)
sns.pairplot(df);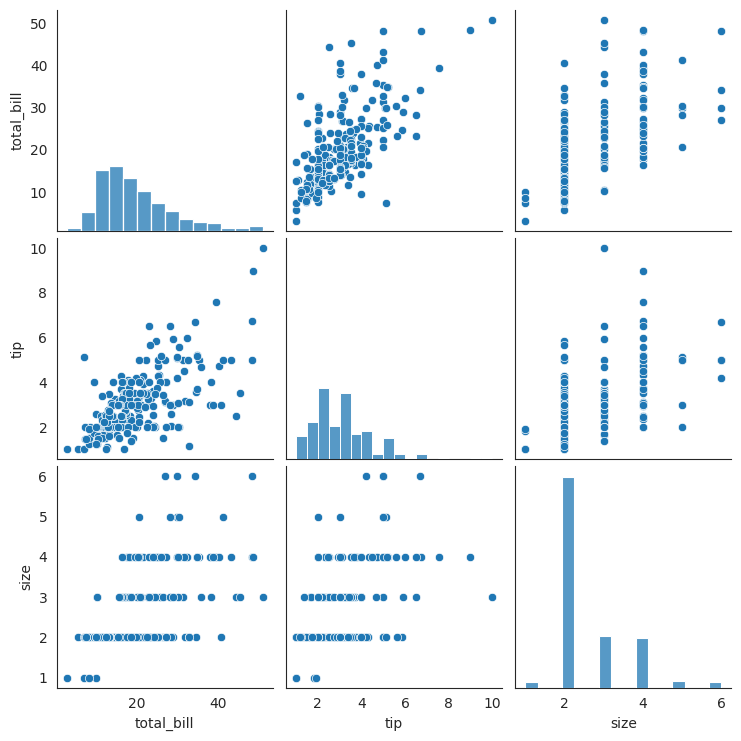
Q117. day에 따라 total_bill의 관계를 파악하기 위한 stripplot 그리기
stripplot함수는 Seaborn 라이브러리에서 제공하는 함수 중 하나로, 주어진 카테고리형 변수에 따라 연속형 변수의 분포를 시각화하는 데 사용된다. 각 카테고리별로 점들을 나타내어 분포를 보여줍니다.
- 일반적으로 stripplot은 카테고리형 변수를 x 또는 y 축으로 설정하고, 연속형 변수를 다른 축에 설정하여 사용된다. 이를 통해 카테고리 간 연속형 변수의 분포를 비교할 수 있다.
sns.stripplot(x="카테고리형 변수", y="연속형 변수", data=데이터프레임)
sns.stripplot(x = "day", y = "total_bill", data = df);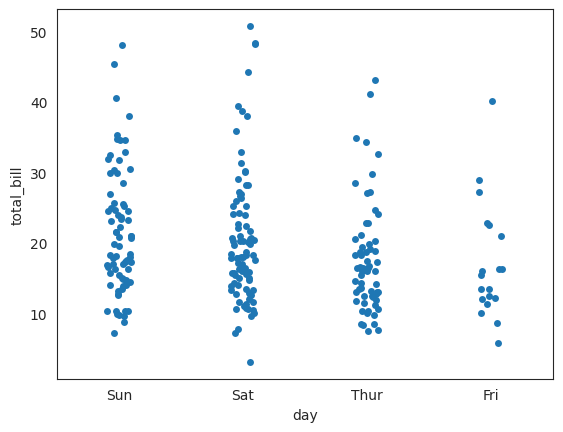
sns.stripplot(x = "day", y = "total_bill", data = df, hue='day');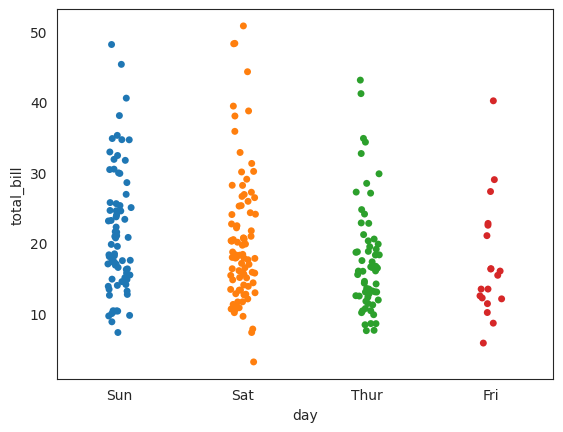
Q118. day와 성별에 따라 tip의 관계를 파악하기 위한 stripplot 그리기 (x축 - tip, y축 - day)
sns.stripplot(x = "tip", y = "day", hue = "sex", data = df);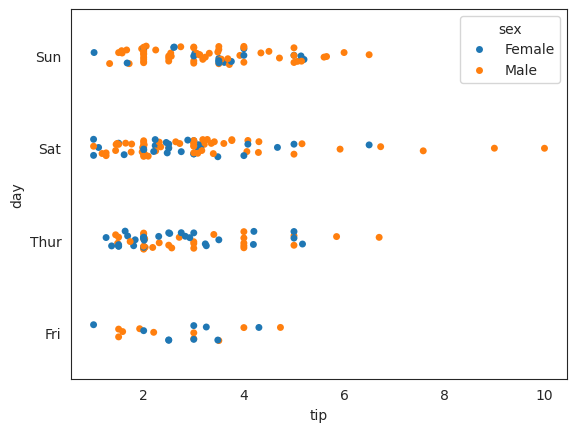
Q119. day와 time에 따라 total_bill의 관계를 파악하기 위한 boxplot 그리기 (x축 - day, y축 - total_bill)
boxplot함수는 Seaborn 라이브러리에서 제공하는 함수 중 하나로, 연속형 변수의 분포를 시각화하는 데 사용된다. 주어진 변수의 중앙값, 사분위수, 이상치 등을 표시하여 데이터의 분포를 파악할 수 있다.
- 일반적으로 boxplot은 하나 또는 여러 연속형 변수를 카테고리형 변수에 따라 비교하는 데 사용된다. 카테고리별로 연속형 변수의 분포를 비교하고 이상치를 확인할 수 있다.
sns.boxplot(x="카테고리형 변수", y="연속형 변수", hue="구분할 변수", data=데이터프레임)
hue매개변수는 카테고리별로 다른 색상으로 데이터를 분리하여 시각화할 때 사용된다.- 상자의 중앙값은 변수의 중앙값을 나타내며, 상자의 상단과 하단은 해당 변수의 사분위수 범위를 나타낸다. 이상치(Outlier)는 일반적으로 상자 바깥에 점으로 표시된다.
sns.boxplot(x = "day", y = "total_bill", hue = "time", data = df);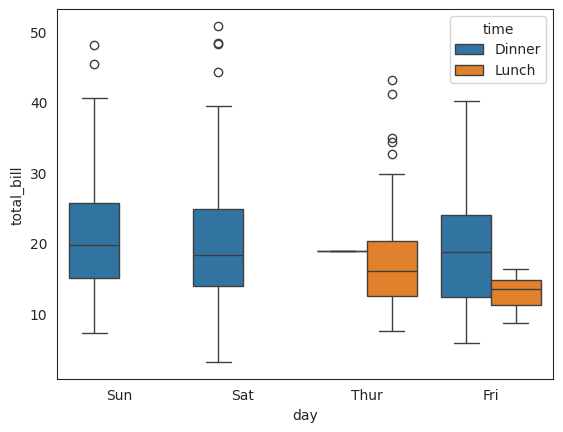
상자 그림은 데이터의 분포를 자세히 이해하기 어렵다. 특히, 데이터의 밀집도나 분포의 형태를 파악하는 데는 한계가 있다. 이를 보완하기 위해서는 히스토그램이나 커널 밀도 추정 그래프와 같은 다른 시각화 기법을 활용할 수 있다.
Q120. 저녁(Dinner)과 점심(Lunch)을 기준으로 한 팁 값에 대해 두 개의 히스토그램 생성하기
# better seaborn style
sns.set(style="ticks") # ticks 옵션은 x축과 y축의 땡땡땡 선들
plt.grid(True)
# creates FacetGrid
g = sns.FacetGrid(df, col="time")
g.map(plt.hist, "tip");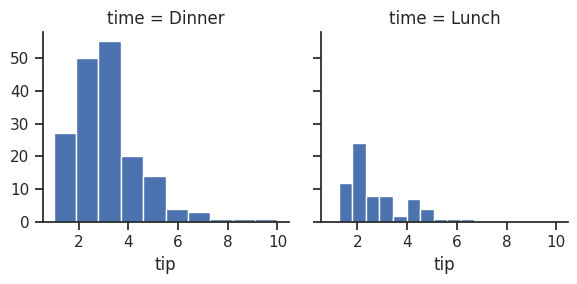
sns.set() 함수는 seaborn의 기본 설정을 변경하는 데 사용된다.style은 그래프의 스타일을 설정하는 매개변수이다.
- 여기서
style="time"으로, "ticks" 스타일을 사용하겠다는 것을 의미한다. "ticks" 스타일은 그래프의 눈금에 눈금선을 표시한다.
plt.grid()함수는 그래프에 격자를 표시하는 데 사용된다.True를 전달하면 격자가 표시되고,False를 전달하면 격자가 표시되지 않는다.
sns.FacetGrid()함수는 다중 서브플롯 그리드를 생성하는 데 사용된다.
여기서 df는 데이터프레임을 나타내며, col="time"은 그리드의 열(column)을 설정하는 매개변수이다. "time" 컬럼에 따라 다른 서브플롯이 생성된다.
map() 메서드는 FacetGrid 객체에 지정된 함수를 매핑한다. 여기서는 plt.hist 함수를 사용하여 히스토그램을 그린다. 두 번째 인수인 "tip"은 데이터프레임의 열(column) 이름을 나타내며, 해당 열의 데이터를 기반으로 히스토그램을 생성한다. FacetGrid에서 생성된 서브플롯마다 해당 함수가 실행된다.
Q121. 남성과 여성을 대상으로 한 두 개의 산점도 그래프 생성하기. (이 그래프들은 전체 청구 금액(total_bill)과 팁(tip) 간의 관계를 보여주며, 흡연자와 비흡연자로 구분되어야 함)
g = sns.FacetGrid(df, col="sex", hue="smoker")
g.map(plt.scatter, "total_bill", "tip", alpha =.7) # alpha는 투명도
g.add_legend(); # legend(범례) 추가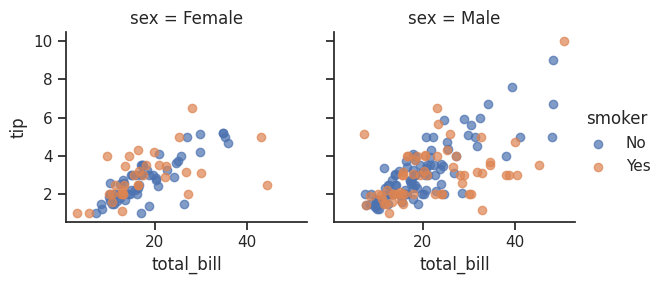
sns.FacetGrid(df, col="sex", hue="smoker"): 이 부분은 FacetGrid 객체를 생성한다. FacetGrid는 데이터를 여러 서브 플롯으로 나누어 그릴 때 유용한 그리드를 제공한다. 여기서 df는 데이터프레임을 나타내며, col="sex"는 "sex" 열 값을 기준으로 서브 플롯을 열별로 생성하고, hue="smoker"는 "smoker" 열의 값을 기준으로 색상을 구분한다.
g.map(plt.scatter, "total_bill", "tip", alpha=.7): 이 부분은 FacetGrid에 데이터를 삽입하고 시각화하는 역할을 한다. plt.scatter는 산점도를 그리는 함수이며, "total_bill"을 x축으로, "tip"을 y축으로 사용한다. alpha=.7는 각 점의 투명도를 설정하는 인자로, 0에서 1 사이의 값을 가진다. 값이 작을수록 투명해지고, 값이 클수록 불투명해진다.
add_legend()메서드는 FacetGrid에 범례(legend)를 추가하는 데 사용된다. 이 때,hue매개변수로 지정된 변수에 대한 범례가 생성된다.
Q122. PassengerId를 인덱스로 설정하기
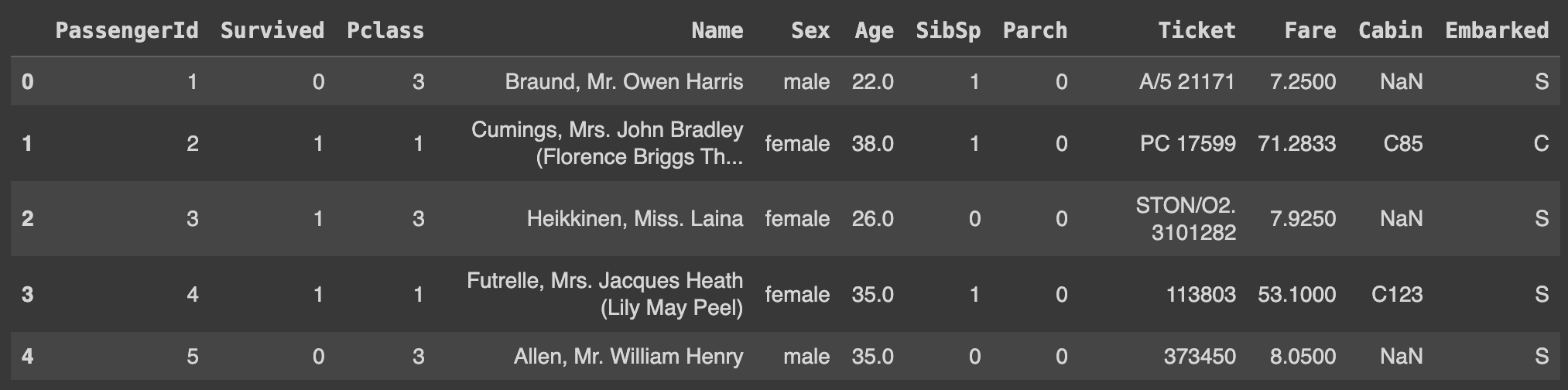
df.set_index('PassengerId', inplace=True)
df.head()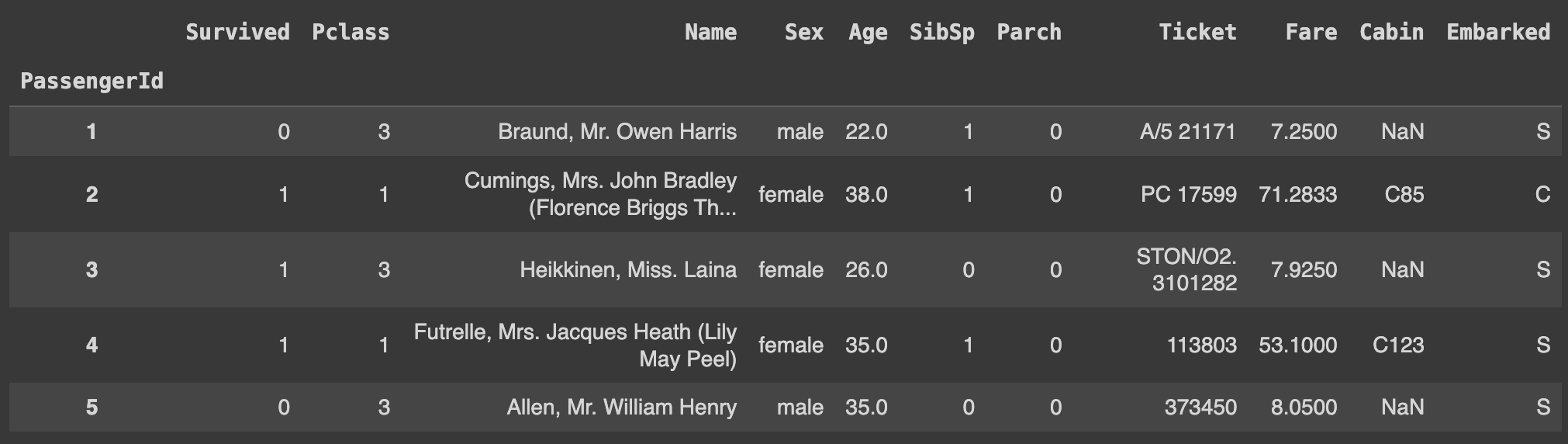
Q123. 남성과 여성의 비율을 나타내는 파이 차트 생성하기
# sum the instances of males and females
males = (df['Sex'] == 'male').sum()
females = (df['Sex'] == 'female').sum()
# put them into a list called proportions
proportions = [males, females]
# Create a pie chart
plt.pie(
# using proportions
proportions,
# with the labels being officer names
labels = ['Males', 'Females'],
# with no shadows
shadow = False,
# with colors
colors = ['blue','red'],
# with one slide exploded out
explode = (0.15 , 0),
# with the start angle at 90%
startangle = 90,
# with the percent listed as a fraction
autopct = '%1.1f%%'
)
# View the plot drop above
plt.axis('equal')
# Set labels
plt.title("Sex Proportion")
# View the plot
plt.tight_layout() # 공백 여백을 없애기
plt.show() # 그래프 출력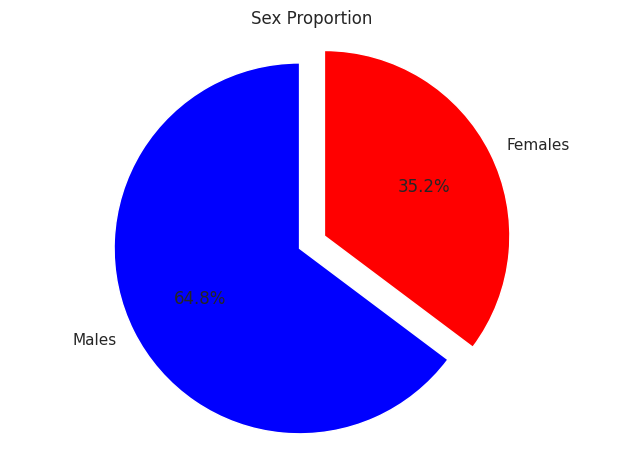
plt.pie()함수는 파이 차트를 그리는 함수이다. 이 함수를 통해 각 범주의 비율을 시각적으로 표현할 수 있다.
proportions: 각 부분의 크기를 결정하는 값들의 리스트이다. 이 값들은 전체의 비율을 나타낸다.labels: 각 부분에 대한 이름(라벨)을 나타내는 리스트이다.shadow: 부분들의 그림자를 표시할지 여부를 결정하는 매개변수이다. True로 설정하면 그림자가 표시된다.colors: 각 부분에 대한 색상을 지정하는 리스트이다.explode: 특정 부분이 돌출되도록 만드는 매개변수이다. 이것은 파이 차트에서 특정 부분을 강조하고자 할 때 사용된다.startangle: 부분들이 시작되는 각도를 설정하는 매개변수이다. 이것은 파이 차트의 시작 각도를 조절하는 데 사용된다.autopct: 각 부분에 대한 퍼센트 값을 어떻게 표시할지 지정하는 서식 문자열이다. 예를 들어 '%1.1f%%'는 소수점 한 자리까지의 퍼센트 값을 표시한다.
plt.axis('equal'): 차트의 가로세로 비율을 동일하게 설정한다. 이것은 파이 차트를 그리는 데 필요하다.
plt.title(): 차트에 제목을 추가한다.
plt.tight_layout(): 그래프의 레이아웃을 최적화하여 여백을 최소화합니다.
plt.show(): 그래프를 화면에 표시한다.
males = (df['Sex'] == 'male').sum()
females = (df['Sex'] == 'female').sum()
# put them into a list called proportions
proportions = [males, females]
# Create a pie chart
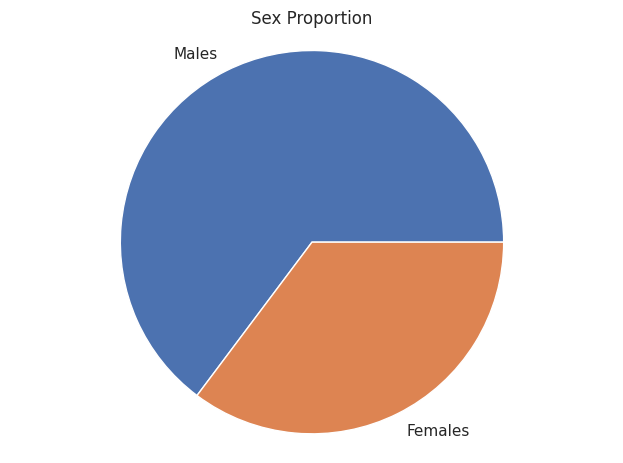
plt.pie(
# using proportions
proportions,
# with the labels being officer names
labels = ['Males', 'Females'])
plt.axis('equal')
# Set labels
plt.title("Sex Proportion")
# View the plot
plt.tight_layout()
plt.show()별 다른 옵션을 설정하지 않으면 다음과 같은 파이 차트가 생성된다.
Q124. 지불한 요금(Fare)과 나이(Age)를 나타내는 산점도 생성하기 (그래프의 색상은 성별에 따라 달라져야 함)
# creates the plot using
lm = sns.lmplot(x='Age', y='Fare', data=df, hue='Sex', fit_reg=False)
# set title
lm.set(title='Fare x Age')
# get the axes object and tweak it
axes = lm.axes
axes[0,0].set_ylim(-5,)
axes[0,0].set_xlim(-5,85) # -5에서 85까지의 x축 설정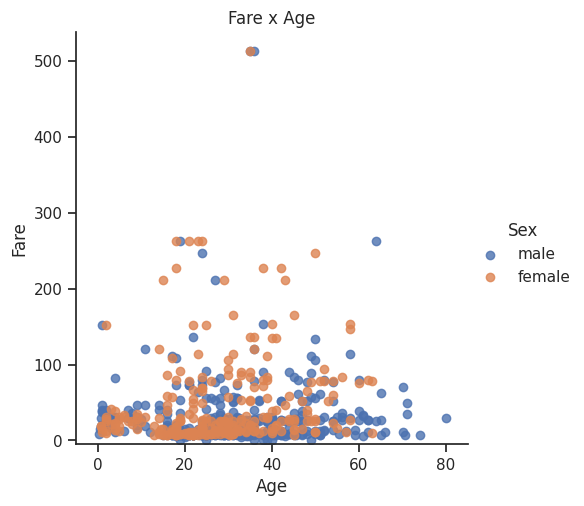
lmplot()함수는 선형 회귀 모델을 사용하여 두 변수 간의 관계를 시각화한다. 기본적으로 산점도와 함께 선형 회귀 직선을 플롯한다. 이를 통해 변수 간의 선형 관계를 시각적으로 검토할 수 있다.
x: x축에 표시할 열의 이름이나 위치이다.y: y축에 표시할 열의 이름이나 위치이다.data: 사용할 데이터프레임이다.hue: 데이터를 색상으로 구분할 열의 이름이다.fit_reg: 회귀선 표시 여부를 제어하는 매개변수이다. 기본값은 True이며, 선형 회귀 직선을 표시한다.scatter_kws: 산점도의 특성을 제어하는 추가 키워드 인수를 설정할 수 있는 딕셔너리이다.line_kws: 회귀선의 특성을 제어하는 추가 키워드 인수를 설정할 수 있는 딕셔너리이다.
lmplot()함수로 생성한 lm 객체의 axes 속성을 사용하여 lmplot() 그래프의 축을 가져올 수 있다. axes 속성은 2차원 배열 형태로, 첫 번째 차원은 행(row)을, 두 번째 차원은 열(column)을 나타낸다.
예를 들어, axes[0, 0]은 첫 번째 행의 첫 번째 열에 해당하는 축을 나타낸다. 이러한 축을 통해 그래프의 범위를 설정할 수 있다.
set_ylim()메서드는 y축의 범위를 설정한다. 이를 통해 플롯의 y축의 최소 및 최대값을 지정할 수 있다.set_xlim()메서드는 x축의 범위를 설정한다. 이를 통해 플롯의 x축의 최소 및 최대값을 지정할 수 있다.
이 예제에서는 y축의 최소값을 -5로, x축의 최소값을 -5로, x축의 최대값을 85로 설정하고 있습니다.
fit_reg=True로 설정하면, lmplot() 함수는 산점도에 선형 회귀 모델을 적합시켜 선형 회귀 선을 그린다.
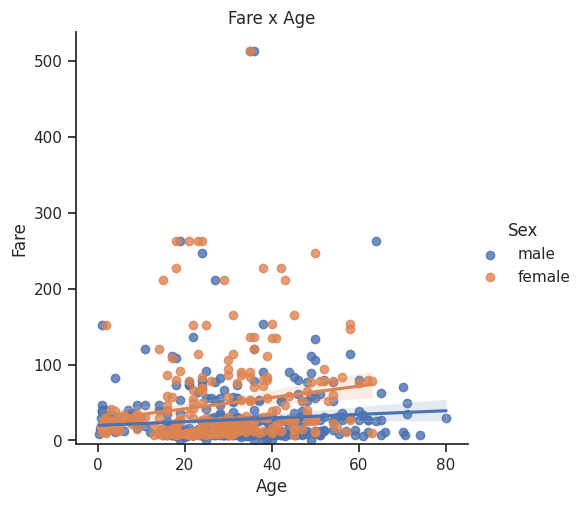
위의 이미지와 같이 Female과 Male의 회귀선을 그린다.
Q125. 지불한 요금(Fare)에 대한 히스토그램 생성하기
import numpy as np
# sort the values from the top to the least value and slice the first 5 items
df2 = df.Fare.sort_values(ascending=False)
# df3 = df.Fare
# create bins interval using numpy
binsVal = np.arange(0,600,10) # 0부터 600까지의 숫자를 10 간격으로 생성하여 배열로 반환
binsVal
# create the plot
plt.hist(df3, bins=binsVal)
# Set the title and labels
plt.xlabel('Fare')
plt.ylabel('Frequency')
plt.title('Fare Payed Histrogram')
# show the plot
plt.show()np.arange(0, 600, 10)은 0부터 600까지의 숫자를 10 간격으로 생성하는 NumPy 배열을 생성한다. 여기서 0은 시작 값, 600은 종료 값, 10은 간격을 의미한다. 따라서 이 코드는 0부터 600까지의 숫자 중 10 간격으로 숫자를 생성하여 배열로 반환한다.
