Q80. Indicator을 삭제하고 First Tooltip 컬럼에서 신뢰구간에 해당하는 표현 지우기
# 'Indicator'라는 열을 삭제
df.drop('Indicator', axis=1, inplace=True)
# 'First Tooltip' 열의 각 값에서 "[" 문자를 기준으로 분할한 후 첫 번째 부분을 가져와서 float 형식으로 변환
df['First Tooltip'] = df['First Tooltip'].map(lambda x: float(x.split("[")[0]))
Ans = df
Ans.head()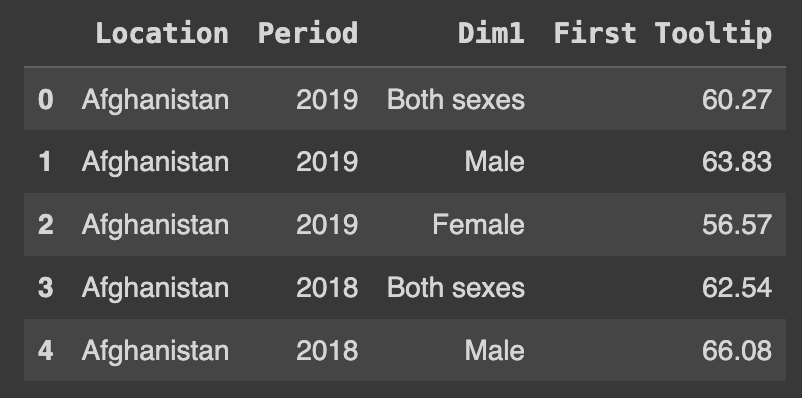
drop()함수는 행을 제거한다.
drop('컬럼_이름', axis=1)은 열을 제거한다.drop('컬럼_이름', axis=0)은 행을 제거한다.
Q81. 년도가 2015년 이상, Dim1이 Both sexes인 케이스만 추출하기
# Period가 2015 이상이고 Dim1이 'Both sexes'인 경우를 동시에 충족하는 행만 선택하여 새로운 DataFrame인 target에 할당
target = df[(df.Period >= 2015) & (df.Dim1 == 'Both sexes')]
Ans = target
Ans.head()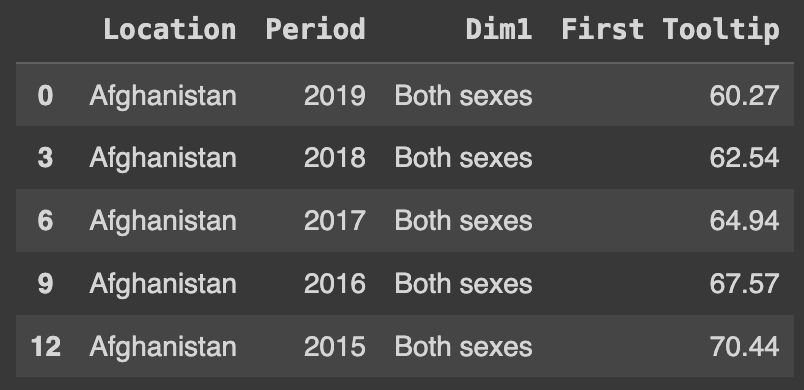
Q82. 84번 문제에서 추출한 데이터로 아래와 같이 나라에 따른 년도별 사망률을 데이터 프레임화 하기
Ans = target.pivot(index='Location', columns='Period', values='First Tooltip')
Ans.head()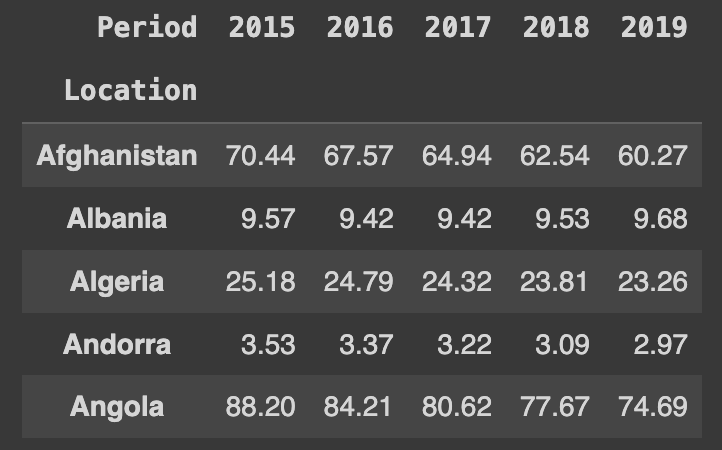
pivot()함수를 사용하여 DataFrame을 재구성하여 데이터를 쉽게 분석할 수 있다.
- 이 함수는
index,columns,values를 지정하여 어떻게 데이터를 재구성할지 지정한다.- 여기서
index는 새로운 행 인덱스가 될 열을,columns는 새로운 열 인덱스가 될 열을,values는 새로운 데이터로 사용될 열을 지정한다.
이렇게 지정된 열들을 기준으로 데이터가 재배치됩니다.pivot(index='새로운 행 인덱스가 될 열 이름', columns='새로운 열 인덱스가 될 열 이름', values='새로운 데이터로 사용될 열 이름')
Q83. Dim1에 따른 년도별 사망비율의 평균 구하기
Ans = df.pivot_table(index='Dim1', columns='Period', values='First Tooltip', aggfunc='mean')
Ans.iloc[:,:4]
pivot_table()함수는pivot()함수와 유사하지만, 데이터가 중복되는 경우에 대한 처리를 수행할 수 있다.
aggfunc은 집계 함수를 지정하는 매개변수로 이 매개변수를 사용하여 데이터를 집계할 때 사용할 함수를 지정할 수 있다. 기본적으로 aggfunc은 평균을 계산(aggfunc='mean')한다. 따라서 aggfunc 매개변수를 지정하지 않으면 mean이 기본값으로 사용된다.
- 다른 집계 함수를 사용하려면 해당 함수의 이름을 문자열로 지정하면 됩니다. 예를 들어, aggfunc='sum'은 데이터를 합산하고, aggfunc='max'는 데이터의 최댓값을 반환합니다.
pivot(index='새로운 행 인덱스가 될 열 이름', columns='새로운 열 인덱스가 될 열 이름', values='새로운 데이터로 사용될 열 이름', aggfunc='집계 함수')
Q84. 데이터에서 한국 KOR 데이터만 추출하기
kr = df[df.Country=='KOR']
Ans = kr
Ans.head()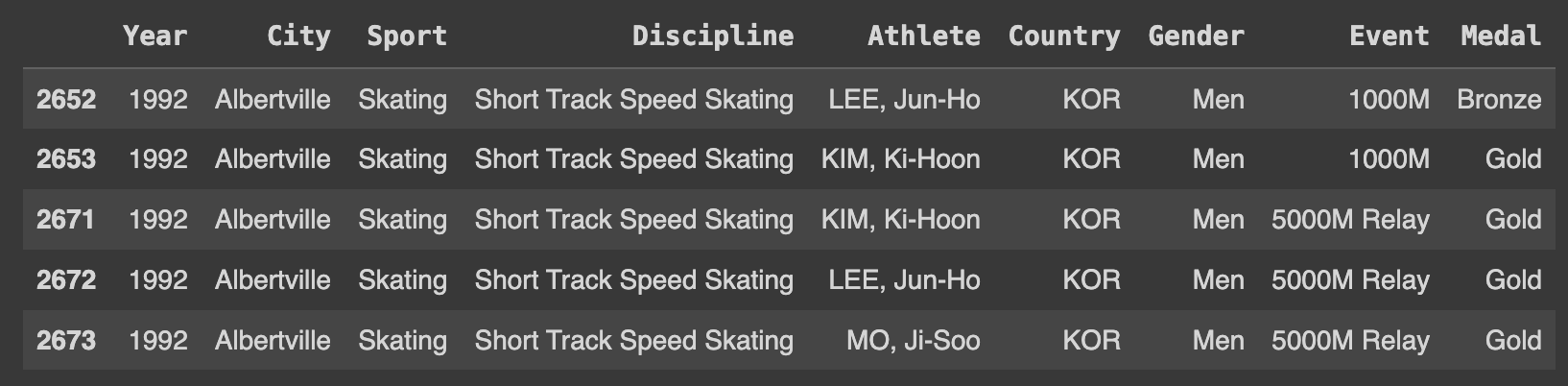
Q85. 한국 올림픽 메달리스트 데이터에서 년도에 따른 medal 갯수를 데이터프레임화 하기
Ans = kr.pivot_table(index='Year',columns='Medal',aggfunc='size').fillna(0)
Ans.head()각 연도별 메달의 수를 표시하는 데에는 특정 값이 필요하지 않다. 따라서 피벗 테이블을 생성할 때 aggfunc='size'를 사용하여 각 그룹에서의 크기를 측정할 수 있다. 이렇게 함으로써 각 연도별로 메달의 수가 어떻게 분포되어 있는지를 파악할 수 있다.
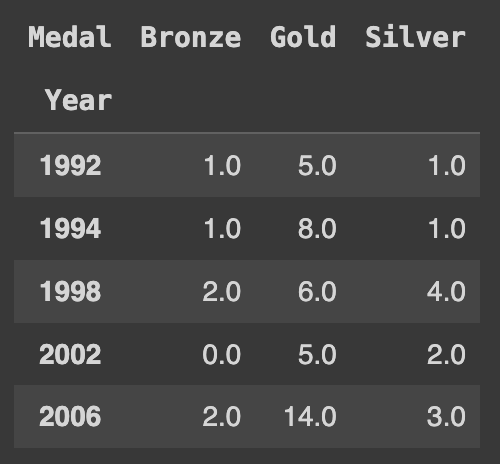
메달 종류의 순서를 고치고 싶다면, 피벗 테이블을 생성한 후에 선택적으로 열의 순서를 지정할 수 있다. 예를 들어, 'Gold', 'Silver', 'Bronze' 순서로 열을 선택하고 싶다면 아래와 같이 코드를 작성하면 된다.
Ans[['Gold', 'Silver', 'Bronze']]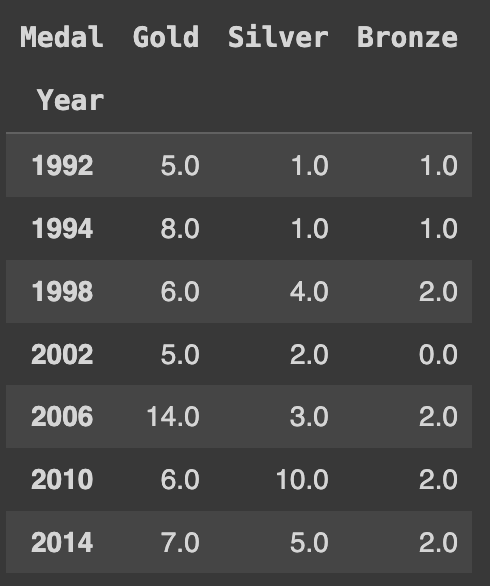
Q86. 전체 데이터에서 sport 종류에 따른 성별수 구하기
Ans = df.pivot_table(index='Sport', columns='Gender', aggfunc='size')
Ans.head()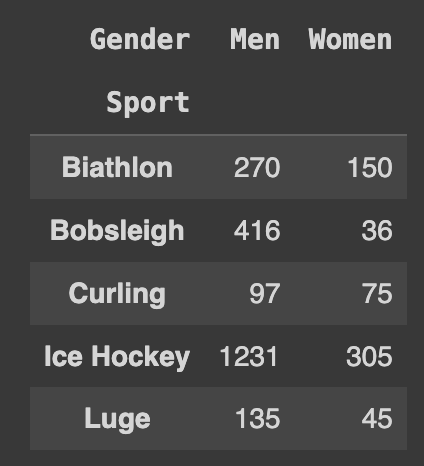
Q87. 전체 데이터에서 Discipline 종류에 따른 Medal 수 구하기
Ans = df.pivot_table(index='Discipline', columns='Medal', aggfunc='size')
Ans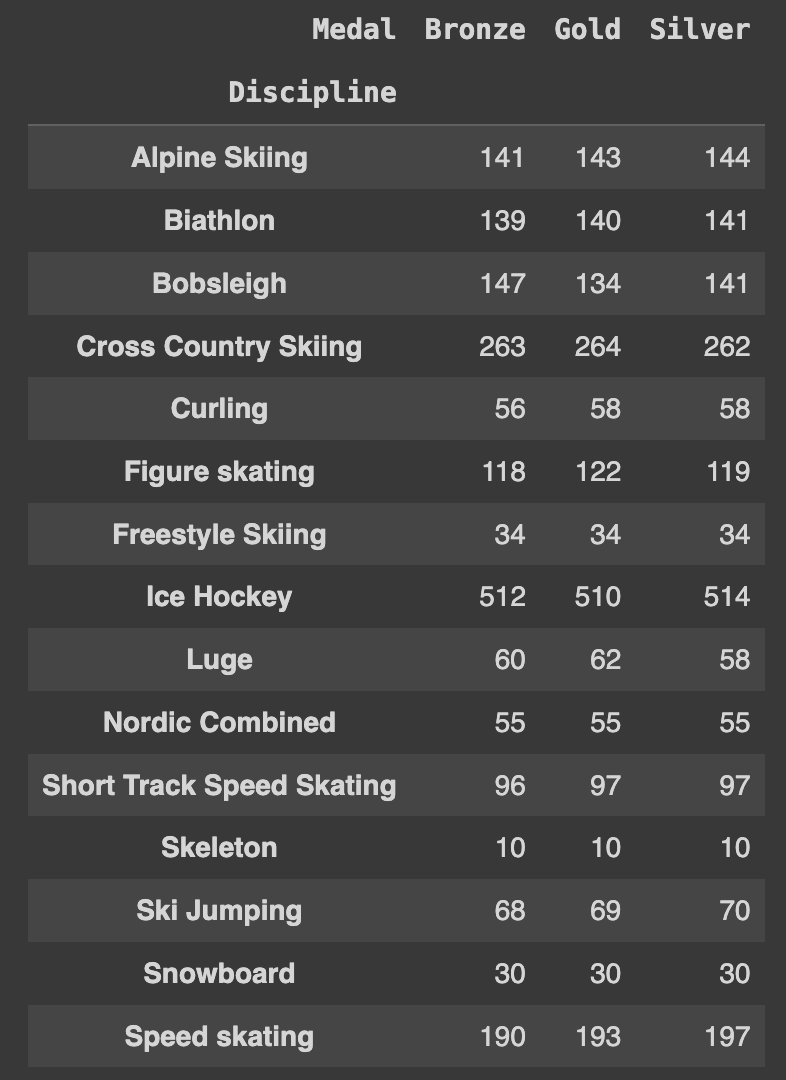

거북선통통통통